Sql刷题日志(day8)
一、笔试
1、right:提取字符串右侧指定数量的字符
right(string,length)
/*string:要操作的字符串。length:要从右侧提取的字符数
*/2、curdate():返回当前日期,格式通常为 YYYY-MM-DD
二、面试
1、自变量是不良体验反馈,因变量是留存率,方法论是ABtest,二者相关性该注意什么?
需要注意可能存在幸存者偏差现象。
- 有些用户在有不良体验后会进行反馈,这种反馈在一定程度上可能解释了用户留存率下降的原因,但同时应该注意到,能进行反馈的用户通常是对平台有感情的用户,希望能通过反馈改善平台环境,继而留下来;
-
很多真正失望的用户可能一言不发便直接流失,所以可能出现不良反馈的数量减少但留存率却下降的情况。
2、AB Test有什么缺点?
- 所需样本量大,要有足够的样本
- 只适用于短期即时的验证
- 前期数据收集工作量大,后期维护成本高,ROI低
- AB测试受场景限制,一旦产品版本发布,无法增加和改变AB测试场景
3、AB测试在什么平台上进行?介绍一下主要步骤?
- AB测试可以在多种平台上进行,包括专业的AB测试平台如GrowthBook、火山引擎 A/B 测试平台、神策数据等,以及一些开源工具。
- 步骤参考day7
4、算法部门上线了新的推荐算法,在ab-test中败给了老算法,让你找出其中的原因,需要说出具体思路和框架
电商平台的商品推荐中,商品历经曝光、点击、加购物车、下单这一系列漏斗。应该分别比较两个算法推荐商品在各环节的转化率,并针对不同环节寻找原因。如果较老算法而言,新算法推的商品从曝光至点击的转化率很低,则应该从推荐推送客群的画像思考,说明推荐算法推送的商品并不适合推送的客群,以此为依据重新调整算法逻辑。
5、简要介绍AB测,并给出样本量计算公式
- 概念:A/B测试是建立在假设检验的基础上,通过单变量控制法,常用来检验新版本和旧版本之间是否存在显著性差异,是提升业务最有效、最实用的方法
- 步骤:1.现状分析并建立假设,2.设定目标并制定方案,3.设计与开发,4.流量的分配,5.收集并分析数据,6.得出结果,确定最终是否上线新版本 样本量计算:功效分析
- 样本量的计算是比较重要的内容,A/B 测试所需的时间 = 总样本量 / 每天可以得到的样本量。从公式就能看出来,样本量越小,意味着实验所进行的时间越短。另外,我们做 A/B 测试的目的,就是为了验证某种改变是否可以提升产品、业务,当然也可能出现某种改变会对产品、业务造成损害的情况,所以这就有一定的试错成本。那么,实验范围越小,样本量越小,试错成本就会越低。实践和理论上对样本量的需求,其实是一对矛盾。所以,我们就要在统计理论和实际业务场景这两者中间做一个平衡:在 A/B 测试中,既要保证样本量足够大,又要把实验控制在尽可能短的时间内。样本量的计算公式如下:
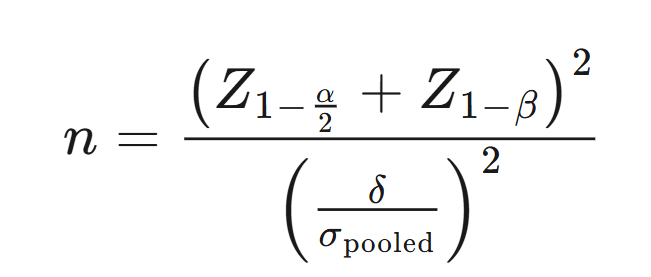
6、拼多多最近在测试两个不同的推荐算法,其中A比B好,从哪几个方面可以分析好的原因
A组用户下单转化率明显高于B组
- 正向指标增加:A组用户人均订单量增加、GMV提升、用户活跃时间更长、物品的收藏率和分享率更高、用户拉新拉活数量更多
- 负向指标减少:A组用户退款率下降、用户差评率降低
7、ABtest, 为了提高点击率,对界面进行了小幅度修改,有两个组 一组1000个人,有100个人点击,另一组1000个人,120人点击,怎么判断好不好
在比例类别指标的假设检验中,可以使用卡方检验方法。
- 进行假设,设H0为两组实验的点击率无明显差异,H1为第二组点击率要高于第一组
- 计算点击率
- A组1000人中有100人点击,则点击率为10%
- B组1000人中有120人点击,则点击率为12%
- 计算差异
- 差异 = 组B点击率 - 组A点击率 = 12% - 10% = 2%
- 统计显著性检验
- 使用Z值查找对应的P值。如果P值大于0.05,则功效不足;如果P值小于0.05,并且功效足够高,可以认为界面修改有效,显著提高了点击率。
8、选择AB实验的样本的时候,应该注意什么
选择AB实验的样本的时候,我们最要考虑的是样本量的选择,影响样本量选择通常有4个因素:显著性水平(α)、标准差(1 – β)、统计功效(μA-μB)、均值差异(σ)
- 显著性水平:显著性水平越低,对AB实验结果的要求也就越高,越需要更大的样本量来确保精度
- 标准差:标准差越小,代表两组差异的趋势越稳定。
- 统计功效:统计功效意味着避免犯二类错误的概率,统计功效越大,需要的样本量也越大
- 均值差异:如果真实值和测试值的均值差别巨大,也不太需要多少样本,就能达到统计显著 越容易观测到显著的统计结果
将这四个值带入样本计算量公式就能得到需要的样本量,通常有网站专门计算AB实验的样本量,所以只要搞清楚上面四个值,就能计算出你需要的样本量
9、怎么验证你的改进办法有没有效
- 常见的方法就是去关注一下关键性指标,因为大多数ABtest在确认做之前都会指定一些关键性指标,比如,点击率、留存率、复购率和转化率等等,所以在上线后就可以直接关注这些指标是否有提高,如果有就说明办法有效,如果没有提高就需要看看办法哪里出了问题。
- 其次也能够通过计算ROI来比对不同的方案。 对于 ROI 的计算,成本方面,每个实验组成本可以直接计算;对于收益方面,就要和对照组相比较,假定以总日活跃天(即 DAU 按日累计求和)作为收益指标,需要假设不做运营活动,DAU 会是多少,可以通过对照组计算,即: ● 实验组假设不做活动日活跃天 = 对照组日活跃天 * (实验组流量 / 对照组流量) ● 实验组收益 = 实验组日活跃天 - 实验组假设不做活动日活跃天。这样就可以量化出每个方案的 ROI。
10、A/B test场景问题,第一类错误,第二类错误具体是什么,你觉得哪个更严重
- 第一类错误:原假设正确但是拒绝原假设,弃真错误
- 第二类错误:原假设错误但是接受原假设,取伪错误
- 第一类错误更严重,由于报告了本来不存在的现象,则因此现象而衍生出的后续研究、应用的危害将是不可估量的。
11、DAU下降,如何分析?
两步分析法:定位问题+找到原因
- 首先定位问题原因,这里可以通过计算各个维度DAU的变动系数=(该维度下异常前DAU-该维度下异常后DAU)/该维度下异常前DAU,选出变动系数较大的前几个维度,对其进行分析。
- 然后可以从内部和外部进行分析,内部从产品(版本更新)、技术(卡顿,闪退)、运营(运营活动)分别沟通看是否能找到原因。外部从政策和竞品的角度找原因。