简单介绍分布式定时任务XXL-JOB
XXL-JOB 由 调度中心 和 执行器 两大部分组成。调度中心主要负责任务管理、执行器管理以及日志管理
执行器主要是接收调度信号并处理。另外,调度中心进行任务调度时,是通过自研 RPC 来实现的
不同于 Elastic-Job 的去中心化设计, XXL-JOB 的这种设计也被称为中心化设计(调度中心调度多个执行器执行任务)
和 Quzrtz 类似 XXL-JOB 也是基于数据库锁调度任务,存在性能瓶颈
acessToken是执行器要连接到我们的调度中心的时候,要使用一个相同的token

Bean模式就是我们通过xxl-job注解里面的bean的名字,去查找对应的不同的方法
不过,一般在任务量不是特别大的情况下,没有什么影响的,可以满足绝大部分公司的要求。不要被 XXL-JOB 的架构图给吓着了,实际上,我们要用 XXL-JOB 的话,只需要重写 IJobHandler 自定义任务执行逻辑就可以了,非常易用
@JobHandler(value="myApiJobHandler")
@Component
public class MyApiJobHandler extends IJobHandler {@Overridepublic ReturnT<String> execute(String param) throws Exception {//......return ReturnT.SUCCESS;}
}直接基于注解定义任务
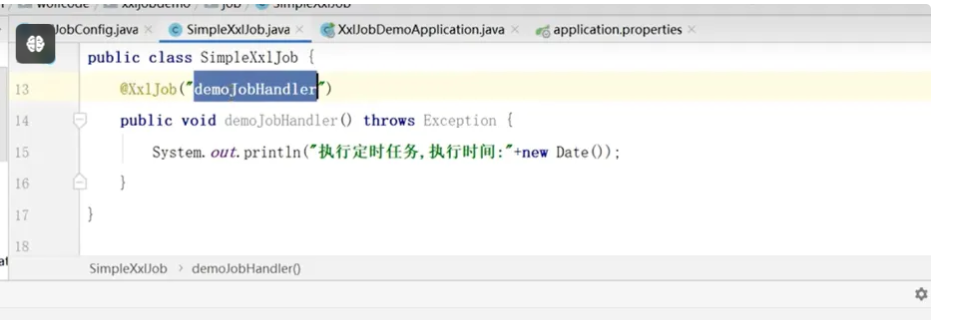
@XxlJob("myAnnotationJobHandler")
public ReturnT<String> myAnnotationJobHandler(String param) throws Exception {//......return ReturnT.SUCCESS;
}
优缺点总结:
- 优点:开箱即用(学习成本比较低)、与 Spring 集成、支持分布式、支持集群、支持任务可视化管理。
- 缺点:不支持动态添加任务(如果一定想要动态创建任务也是支持的,参见:xxl-job issue277)。
xxl-job执行器原理
xxl-job分成两个部分,一个是调度中心,一个是执行器
XXL-JOB 的执行器本身不负责任务调度,调度由调度中心(Admin)完成。调度中心根据任务配置的触发规则(如 Cron 表达式)触发任务,并通过 RPC 调用将任务分发给对应的执行器。
- 调度中心:负责管理任务配置、触发任务、监控任务状态。
- 执行器:接收调度中心的请求,执行具体的任务逻辑
任务执行流程
执行器接收到调度中心的请求后,会通过以下步骤执行任务:
- 任务解析:
执行器解析调度中心传递的任务参数(如任务 ID、任务参数等)。
根据任务 ID 找到对应的任务处理器(JobHandler)。
- 任务处理器执行:
执行器调用预先注册的任务处理器(JobHandler)的 execute 方法(@XxlJob的底层也是这个)。
任务处理器执行业务逻辑,并返回执行结果。
- 结果回调:
执行器将任务执行结果通过 HTTP 回调给调度中心。
调度中心记录任务执行状态(成功、失败、重试等)
任务注册与发现
执行器启动时,会向调度中心注册自己,并上报自己支持的任务列表。调度中心通过注册信息知道哪些任务可以由哪些执行器执行。
注册机制:
执行器启动时,会调用调度中心的注册接口,上报自己的地址(AppName)和支持的任务列表。
调度中心将执行器的信息存储到数据库中
发现机制:
调度中心根据任务配置的 AppName,找到对应的执行器地址,并将任务分发给该执行器
心跳机制
执行器会定期向调度中心发送心跳,以保持与调度中心的连接,并上报自己的健康状态。
心跳作用:
维持执行器与调度中心的连接
上报执行器的健康状态(如是否在线、负载情况等)
调度中心根据心跳信息判断执行器是否可用
心跳超时处理:
如果调度中心长时间未收到执行器的心跳,会将该执行器标记为离线,并不再向其分发任务
任务重试与容错
XXL-JOB 提供了任务重试机制,确保任务在失败时能够自动重试。
重试机制:
如果任务执行失败,调度中心会根据配置的重试次数重新触发任务。
执行器会重新执行任务,直到任务成功或达到最大重试次数。
容错机制:
如果某个执行器宕机,调度中心会将任务分发给其他健康的执行器。
调度中心会根据心跳信息动态调整任务分发策略
任务分片与并行执行
XXL-JOB 支持任务分片(Sharding),允许将一个任务拆分成多个子任务并行执行。
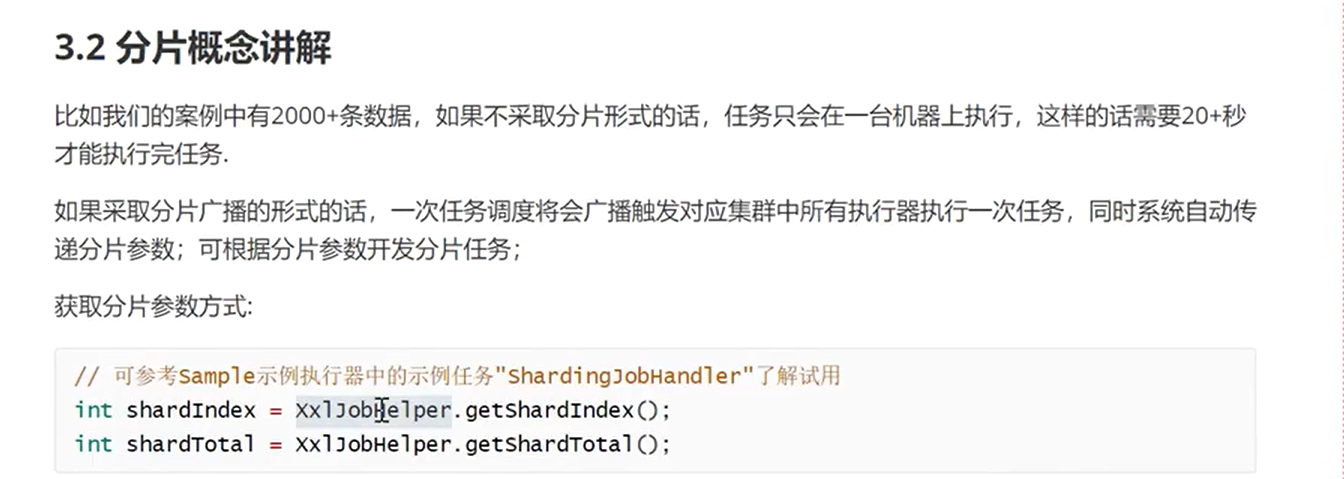
分片原理:
调度中心将任务分片信息(如分片总数、当前分片索引)传递给执行器
执行器根据分片信息执行对应的子任务
如果你有多个执行器,可以通过分片将任务均匀分配给所有执行器,避免单个执行器负载过高
例如我们给这个定时任务的业务是处理100w条数据
然后我们弄10个分片,耦合到业务逻辑,每一个分片处理10w数据,这样子我们就是10个
@XxlJob("shardingJobHandler")
public ReturnT<String> shardingJobHandler(String param) throws Exception {// 获取分片参数int shardIndex = XxlJobHelper.getShardIndex(); // 当前分片索引int shardTotal = XxlJobHelper.getShardTotal(); // 总分片数// 模拟处理数据List<String> dataList = getDataList(); // 获取所有数据int dataSize = dataList.size();int perShardSize = dataSize / shardTotal; // 每个分片处理的数据量// 计算当前分片需要处理的数据范围int start = shardIndex * perShardSize;int end = (shardIndex == shardTotal - 1) ? dataSize : start + perShardSize;// 处理当前分片的数据for (int i = start; i < end; i++) {String data = dataList.get(i);processData(data); // 处理数据}return ReturnT.SUCCESS;
}private List<String> getDataList() {// 模拟获取数据List<String> dataList = new ArrayList<>();for (int i = 0; i < 1000; i++) {dataList.add("data-" + i);}return dataList;
}private void processData(String data) {// 模拟处理数据System.out.println("处理数据:" + data);
}
并行执行:
多个执行器可以同时执行不同的分片任务,从而实现任务的并行处理
面试回答思路
调度中心统一管理任务
我们执行器有两种方式实现:
一个是继承IJobHandler类来重写我们的execute()方法
一个是通过@xxljob注解来实现(底层还是IJobHandler)
执行器启动时,会向调度中心注册自己,并上报自己支持的任务列表。调度中心通过注册信息知道哪些任务可以由哪些执行器执行
同时我们执行器和调度中心会保持心跳执行器会定期向调度中心发送心跳,以保持与调度中心的连接,并上报自己的健康状态,调度中心根据心跳信息判断执行器是否可用
我们的心跳还有超时处理机制,如果调度中心长时间未收到执行器的心跳,会将该执行器标记为离线,并不再向其分发任务
我们的xxl-job和传统的定时任务不同,他有更强大的功能,同时还有ui界面方便交互和使用
首先将一下分布式定时任务和普通定时任务的不同和优缺点
xxl-job他还有任务重试机制和容错机制
重试机制:任务失败时根据配置的重试次数进行重试
容错机制:如果某个执行器宕机,调度中心会将任务分发给其他健康的执行器。调度中心会根据心跳信息动态调整任务分发策略
xxl-job的分片机制(大问题化小)
如果你有多个执行器,可以通过分片将任务均匀分配给所有执行器,避免单个执行器负载过高
例如我们给这个定时任务的业务是处理100w条数据
然后我们弄10个分片,耦合到业务逻辑,每一个分片处理10w数据,这样子我们就是10次执行器执行去处理这个100w数据