[Linux]物理地址到虚拟地址的转化
[Linux]物理地址到虚拟地址的转化
@水墨不写bug

文章目录
- 一、再次认识地址空间
- 二、页表
- 1、页表的结构设计
- 2、页表节省了空间,省在哪里?
- 3、页表的物理实现
一、再次认识地址空间
OS和磁盘交互的内存基本单位是4KB,这4KB通常被称为内存块。OS对内存管理的粒度精确到块——4KB为单位。而与之相对的,用户对内存管理的粒度精确到1byte。在物理内存上,每一个块都有自己的地址——逻辑块地址(Logical Block Address)。
这里的块,和文件数据存储的块的大小是相同的。OS管理的不是连续的物理内存,物理地址被划分为4KB为单位的块,OS通过管理这些块,间接管理内存。想要管理好这些块,需要先描述,再组织。在内核中,每一个块通过一个结构体来管理:
struct page {unsigned long flags; // 页状态标志位(核心字段)union {struct { // 页缓存/匿名页的通用字段struct list_head lru; // LRU链表(用于页回收)void *mapping; // 关联的地址空间(文件或匿名)pgoff_t index; // 页在映射中的偏移或交换槽索引unsigned long private;// 私有数据(用途因场景而异)};struct { // Slab分配器专用字段union {struct list_head slab_list;struct { // Partial页链表(用于slab)struct page *next;int pages; // 当前slab的剩余页数int pobjects; // 剩余对象数};};struct kmem_cache *slab_cache; // 所属的slab缓存void *freelist; // 空闲对象链表union {void *s_mem; // slab第一个对象的地址unsigned long counters; // 引用计数和状态};};// 其他联合体分支(如设备页、大页等)};atomic_t _refcount; // 引用计数atomic_t _mapcount; // 页表映射计数unsigned long compound_head; // 复合页(大页)的头页unsigned int compound_order; // 复合页的阶数(2^order页)// ... 其他体系结构相关字段
};
一整个物理内存,有4GB,共1048576个4KB,通过结构体数组来管理:
struct page memory[1048576];//每一个page都有下标
struct page内部都有哪些字段?分别有什么作用?
(1)_refcount-引用计数,表面这个page被多少个进程共享。如果多个进程共享这个page,一旦出现修改数据,需要进行写时拷贝。
(2)unsigned long flags-标记,32位标识,表面这个页的属性:是否有效,是否是脏页,是否被占用,是否被锁定。
(3)lru-将页连接到最近最少使用(LRU) 链表,用于页回收(如kswapd)。LRU_ACTIVE:活跃页链表(近期被访问过)。LRU_INACTIVE:非活跃页链表(候选回收页)。
内存中的4KB被称为页框。文件数据的4KB被称为页帧。
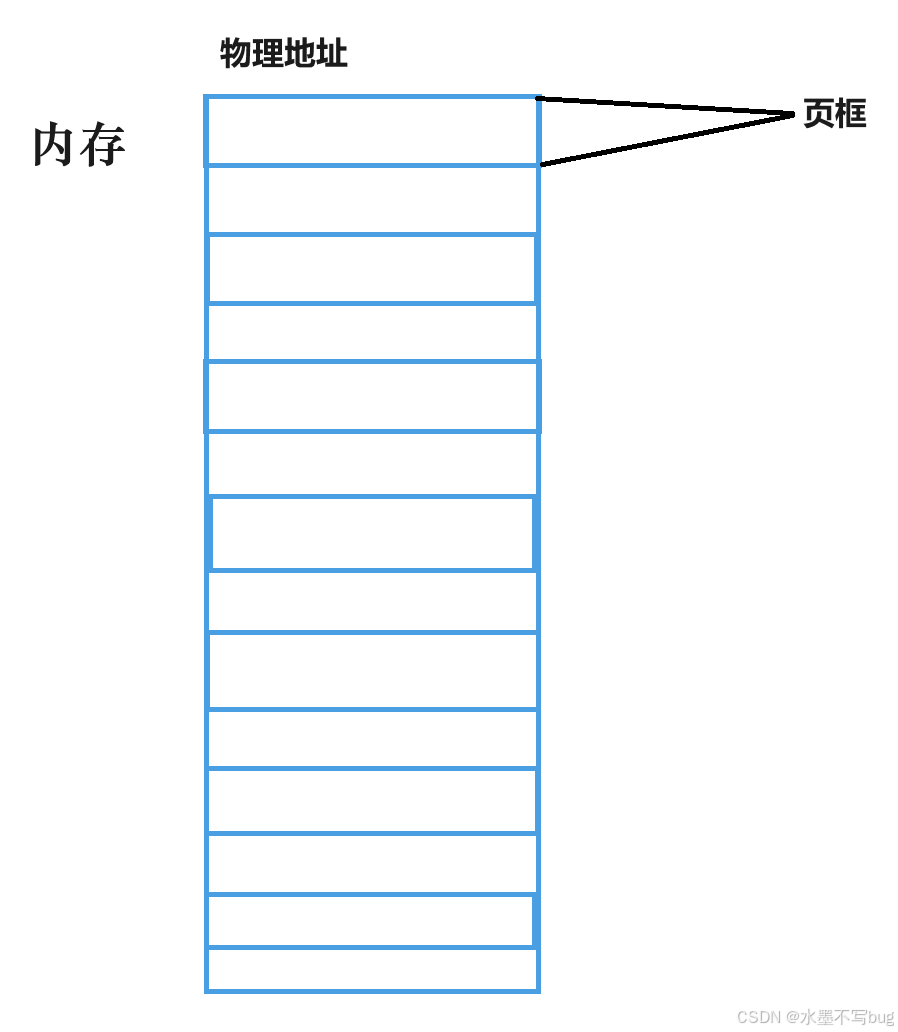
同时4KB的大小也方便了内存和磁盘进行存取以块为单位的文件数据。内存和磁盘进行IO的基本单位理所当然就是4KB。
考虑下面的这几个例子:
- (1)即使内存暂时只需要
1byte数据,OS也会直接把这1byte所在的4KB直接加载到内存。 - (2)父子进程对于只读数据,是共享的;对于任意一方修改了一个全局变量,会发生
写时拷贝。OS实际上不是仅仅拷贝了一个变量的大小,而是拷贝了这个变量所在的页框(4KB)。 - (3)malloc进行申请空间的时候–malloc(10),底层不是只申请了10字节空间,而是4KB,多余的空间就交给了malloc函数进行维护。
- (4)
共享内存的大小最好就是4KB(4096bytes),如果申请4097bytes,则实际申请了8KB,但是我们用户能够使用的大小仅仅是4097bytes—这就造成了空间的浪费。(OS保守起见,多申请的空间不给我们使用) - (5)page可作为文件的内核级缓冲区,是通过字典树来把page排序,使得存储在不同的page内的文件可以方便的恢复。
根据局部性原理:这个时间点使用了这1byte,在后续时间点很有可能会使用这1byte附近的数据。 对一个全局变量修改了,很有可能以后要对附近的数据进行修改。所以拷贝4KB是合理的。申请内存一次性申请4KB也是用到了池化思想,提高了效率
二、页表
1、页表的结构设计
页表是一个把进程虚拟地址转化为物理地址的结构。在x86体系下,物理地址有4GB(2的32次方),如果按照通常的一对一的映射,一个4字节的虚拟地址映射一个4字节的物理地址,一共需要的内存比实际拥有的内存还要多,这十分不合理。所以页表的映射不是简单的一对一映射。
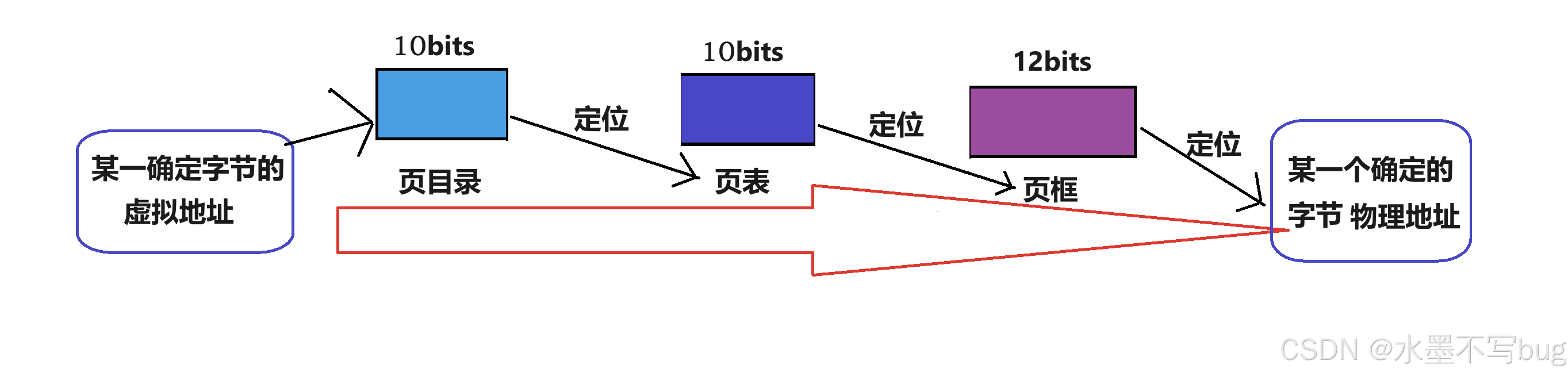
在x86体系结构下,一个虚拟地址有32位,这个虚拟地址被分为 10 + 10 + 12:
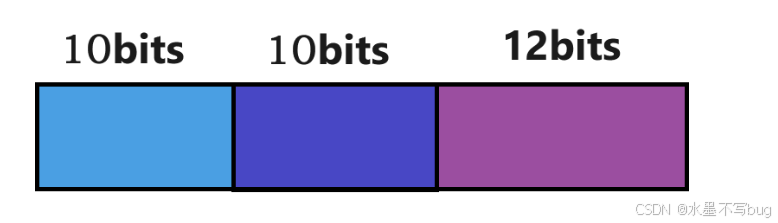
前10位 用于在页目录内部索引,中间10位用于在页表中索引,后12位用于在一个页框内偏移:
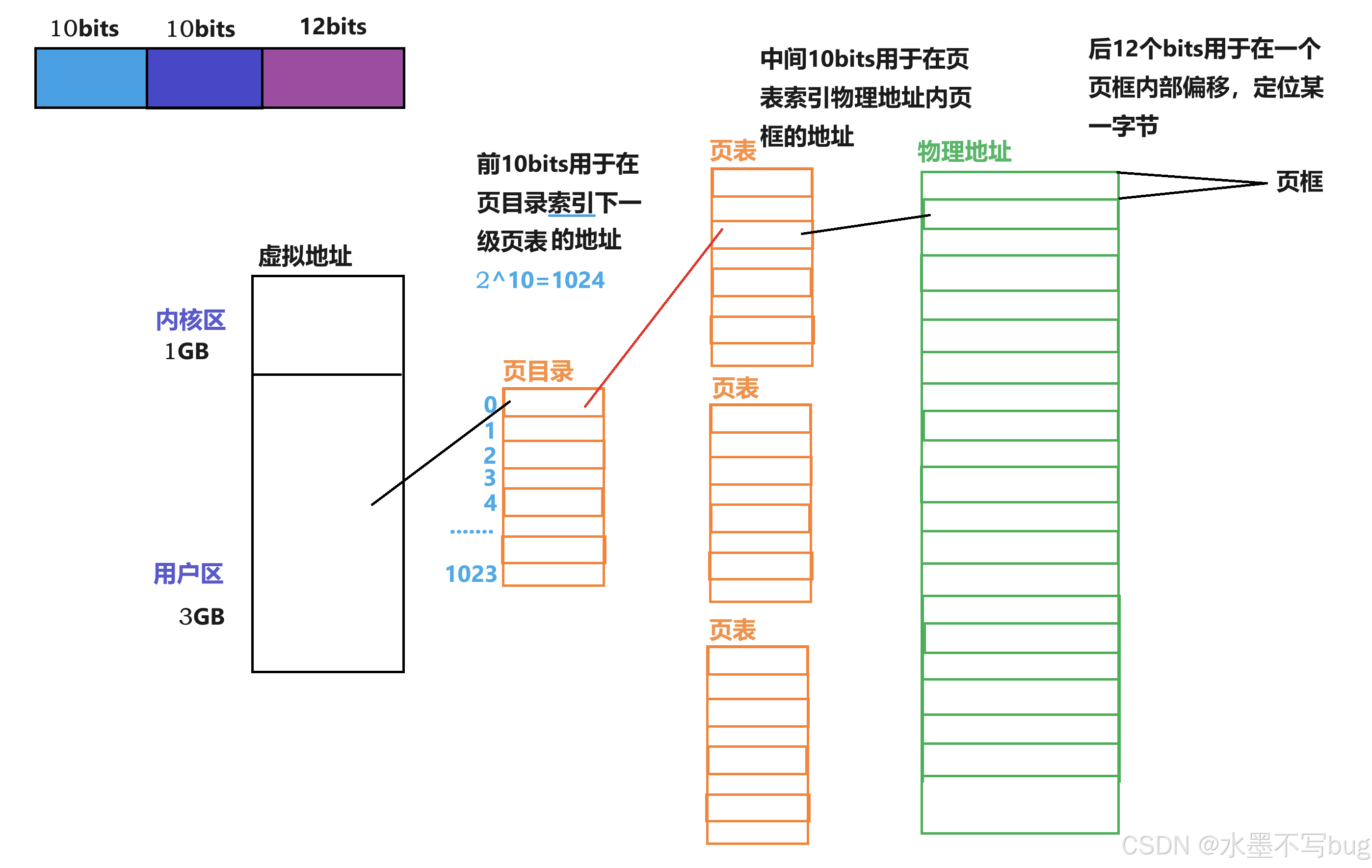
这样,我任何一个虚拟地址,都可以通过页表的机制,找到对应的虚拟地址!
在C/C++中,为什么只要获取一个变量的首地址就能够成功访问这个变量?
因为这个变量还有对应的类型。
访问一个变量,需要首先获取虚拟地址,通过上述的转换机制,把虚拟地址1字节转换到物理地址具体某字节的地址。此外,变量类型在语言层面就告诉了编译器,编译器会编译生成对应的汇编语句:
考虑下面这些语句:
int x = 1234;
int y = *(&x); // 通过首字节地址读取值//对应的汇编语句可能就是
mov eax, [0x1000] ; 从地址 0x1000 开始读取 4 字节到寄存器 eax
mov [0x2000], eax ; 将 eax 的值存储到地址 0x2000
mov eax, [0x1000]:处理器根据地址 0x1000 开始读取 4 字节(因为 eax 是 4 字节寄存器)。汇编层面会根据指令和寄存器的大小,自动决定读取的数据宽度。
2、页表节省了空间,省在哪里?
如果没有页表,直接一个物理地址对应一个虚拟地址这样映射,页表需要占用的空间就是(以x86为例,一个地址占用的空间为4bytes)(4+4)*4GB = 32GB,需要存储页表的空间就已经超过的整机的物理空间大小,显然不合理。
页表实际的大小为 页目录(4KB) + 所有页表(4KB * 1024):
4KB+4MB=4100KB = 4.00390625MB
通过上面的计算,实际上就可以通过近乎4MB的空间大小来实现整个页表结构。于是就把原来的32GB压缩到了4MB。
3、页表的物理实现
实际上CPU内部内置了MMU。MMU(内存管理单元,Memory Management Unit) 是计算机硬件中的一个核心组件,通常集成在 CPU 中,主要负责管理内存访问和地址转换。
上述的页表的转换流程就是MMU的工作流程。
CPU引入MMU后,读取指令、数据需要访问两次内存:首先通过PC指针读取下一条指针的虚拟地址,虚拟地址需要通过查询页表得到物理地址,然后访问该物理地址读取指令、数据。为了减少因为频繁查页表导致的CPU性能下降,MMU引入了TLB,TLB(Translation Lookaside Buffer)可翻译为“地址转换后援缓冲器”。TLB就是页表的Cache,其中存储了当前最可能(最近)被访问到的页表项,其内容是部分页表项的一个副本。只有在TLB无法完成地址翻译任务时,才会到内存中查询页表,这样就减少了页表查询导致的处理器性能下降。
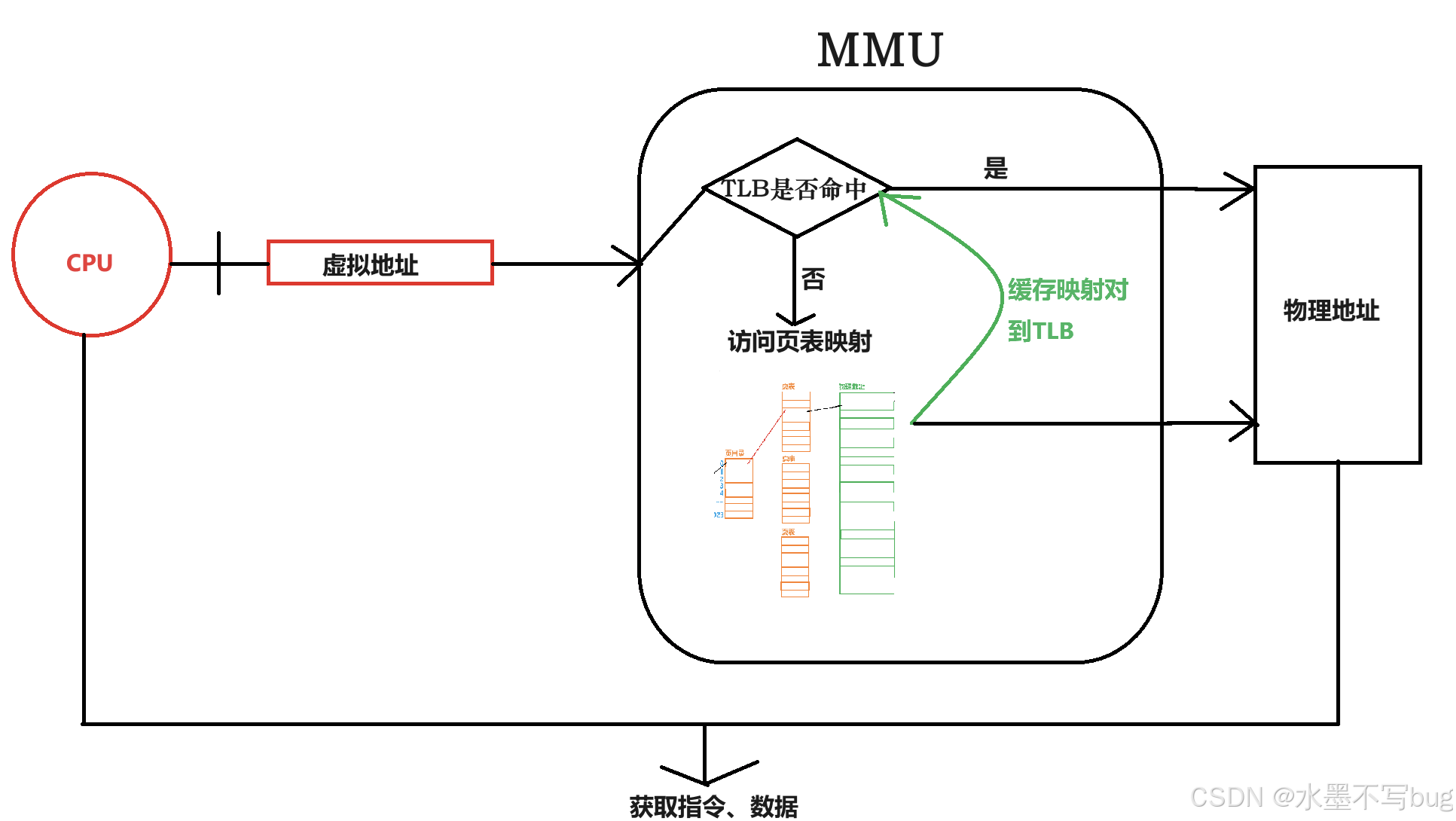
对整体过程而言: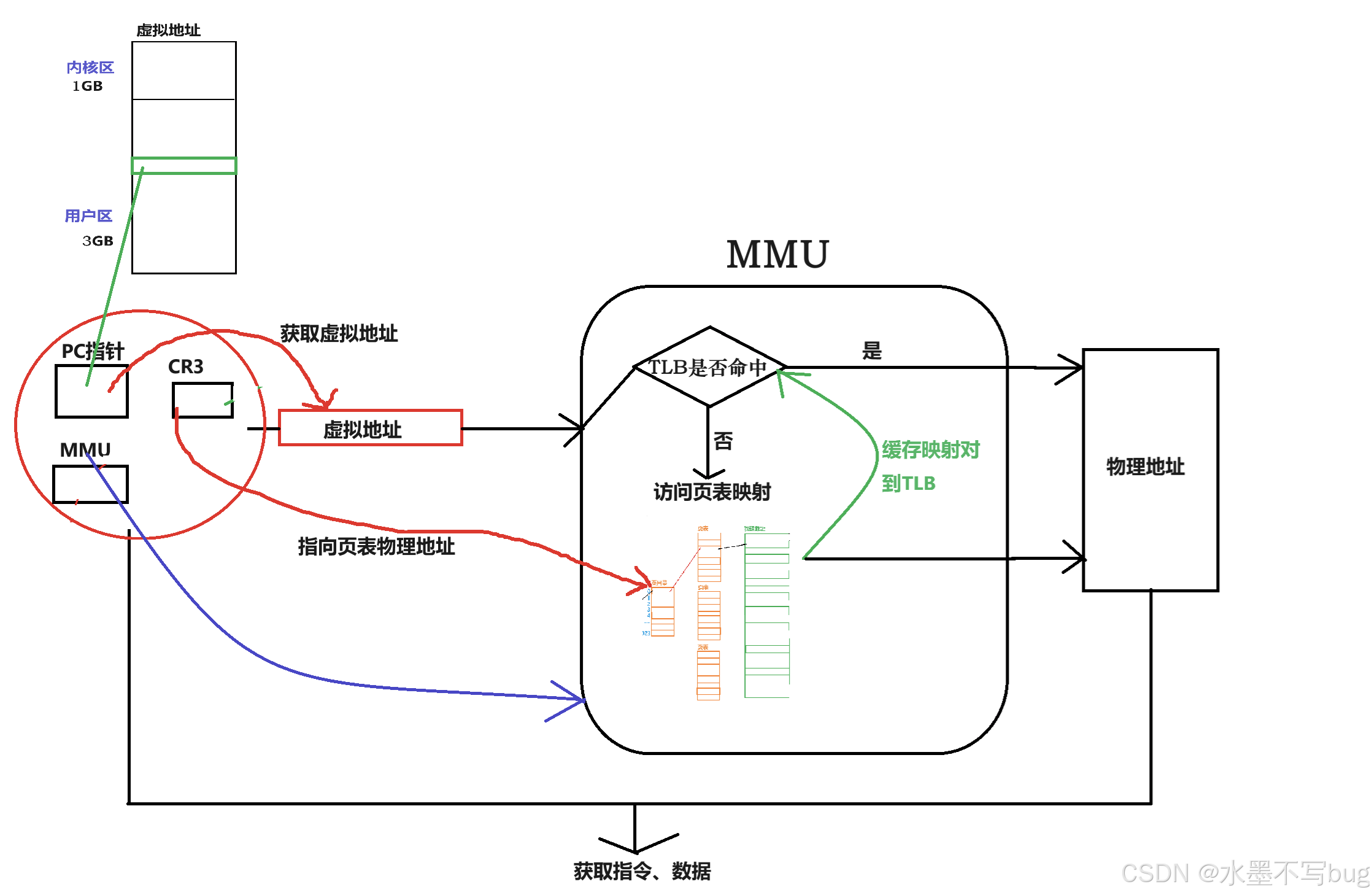
虚拟到物理地址转换的详细流程:
CPU通过PC指针获取下条指令的虚拟地址,访问MMU查询TLB里面是否已经缓存了此次虚拟到物理的映射?如果是,则转换结束;如果否,则需要访问页表。通过CR3寄存器获取页表物理地址,通过分级映射查找获取物理地址,并同时把此次访问的虚拟到物理的映射缓存到TLB,方便后续的再次映射(如果是循环逻辑,则后续访问都不需要再次查页表,十分高效)。
完~
