开源项目:optimum-quanto库介绍
项目地址:https://github.com/huggingface/optimum-quanto
官网介绍:https://huggingface.co/blog/quanto-introduction
量化是一种技术,通过使用低精度数据类型(如 8 位整数 (int8))而不是通常的 32 位浮点 (float32) 来表示深度学习模型的权重和激活,从而降低评估深度学习模型的计算和内存成本。
减少位数意味着生成的模型需要更少的内存存储,这对于在消费类设备上部署大型语言模型至关重要。 它还支持对较低位宽数据类型的特定优化,例如 CUDA 设备上的矩阵乘法, int8, float8.
许多开源库可用于量化 pytorch 深度学习模型,每个模型都提供非常强大的功能,但通常仅限于特定的模型配置和设备。
此外,尽管它们基于相同的设计原则,但不幸的是,它们经常彼此不兼容。
今天,我们很高兴地推出 quanto,这是 Optimum 的 PyTorch 量化后端。
它的设计考虑了多功能性和简单性:
- 所有功能在 EAGER 模式下可用(适用于不可追踪的模型),
- 量化模型可以放置在任何设备上(包括 CUDA 和 MPS),
- 自动插入量化和去量化存根,
- 自动插入量化的函数运算,
- 自动插入量化模块(请参阅下面的支持模块列表),
- 提供从 float 模型到 dynamic 到 static 量化模型的无缝工作流程,
- 与 PyTorch 和 🤗 Safetensors 兼容的序列化,weight_only
- CUDA 设备上的加速矩阵乘法(int8-int8、fp16-int4、bf16-int8、bf16-int4)、
- 支持 int2、int4、int8 和 float8 权重,
- 支持 int8 和 float8 激活。
最近的量化方法似乎专注于量化大型语言模型 (LLM),而 quanto 旨在为适用于任何模态的简单量化方案(线性量化、每组量化)提供极其简单的量化基元。
安装命令:
pip install optimum-quanto1、量化Hugging Face models
1.1 量化效果
基于官网发布的性能数据,综合评估可以发现量化前,bf16的性能与延时才是最佳的
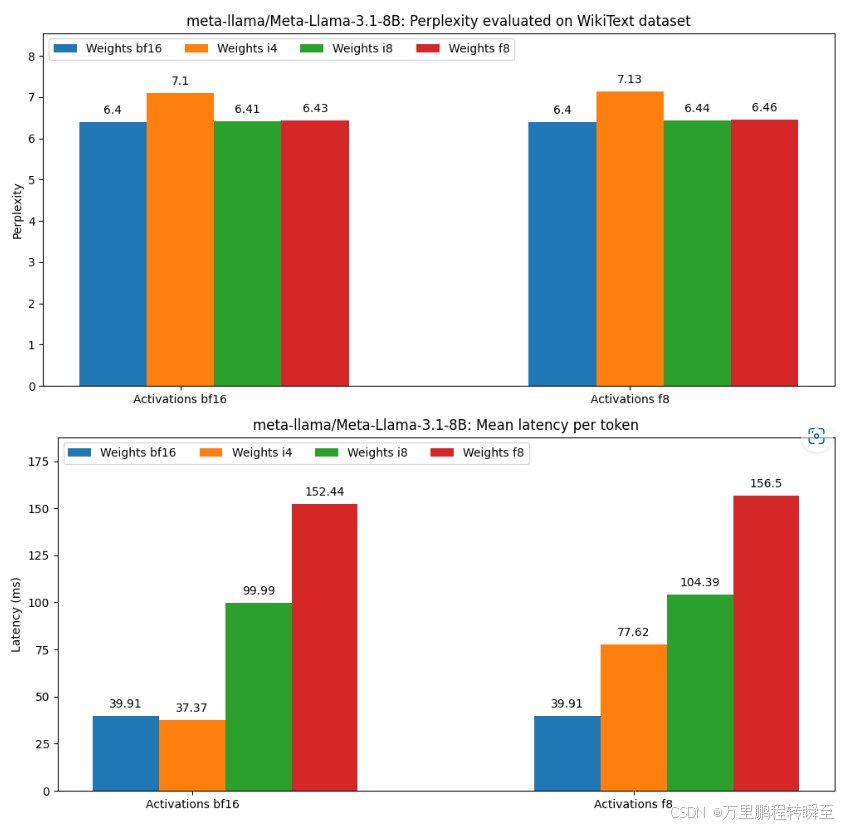
上图显示了在 NVIDIA A10 GPU 上测得的每个令牌的延迟,基于optimum-quanto得到的i4、i8量化模型并没有降低首token延时。只是在理论上降低了显存需求。
1.2 在transformers 库中使用
Quanto 无缝集成在 Hugging Face transformers 库中。您可以通过将 添加quantization_config配置项调用optimum-quanto库。 具体如下使用
from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfigmodel_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)quantization_config = QuantoConfig(weights="int8")quantized_model = AutoModelForCausalLM.from_pretrained(model_id,quantization_config= quantization_config
)目前,您需要使用最新版本的 accelerate 以确保集成完全兼容。更多信息可以参考:https://huggingface.co/blog/quanto-introduction
2.1 量化常规模型
2.1 常规api
量化常规的torch模型有以下步骤:
第一步 量化
将标准浮点模型转换为动态量化模型。
from optimum.quanto import quantize, qint8quantize(model, weights=qint8, activations=qint8)
在此阶段,仅修改模型的推理以动态量化权重。
第二步 校准
校准(如果激活未量化,则可选)
Quanto 支持校准模式,该模式允许记录激活范围,同时通过量化模型传递代表性样本。
from optimum.quanto import Calibrationwith Calibration(momentum=0.9):model(samples)
这会自动激活量化模块中激活的量化。
第三步 Quantization-Aware-Training
import torchmodel.train()
for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data).dequantize()loss = torch.nn.functional.nll_loss(output, target)loss.backward()optimizer.step()第四步 冻结整数权重
冻结模型时,其浮点权重将替换为量化权重。*
from optimum.quanto import freezefreeze(model)第五步 序列化量化模型
量化模型的权重可以序列化为 ,并保存到文件中。 和 (recommended) 均受支持。
为了重新加载这些权重,还需要存储量化的 模型量化图。
from safetensors.torch import save_file
import jsonsave_file(model.state_dict(), 'model.safetensors')from optimum.quanto import quantization_map
with open('quantization_map.json', w) as f:json.dump(quantization_map(model))
第六步 重新加载量化模型
import jsonfrom safetensors.torch import load_file
state_dict = load_file('model.safetensors')
with open('quantization_map.json', r) as f:quantization_map = json.load(f)# Create an empty model from your modeling code and requantize it
with torch.device('meta'):new_model = """创建一个模型结构"""
requantize(new_model, state_dict, quantization_map, device=torch.device('cuda'))2.2 官方案例
https://github.com/huggingface/optimum-quanto/blob/main/examples/vision/image-classification/mnist/quantize_mnist_model.py
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.import argparse
import time
from tempfile import NamedTemporaryFileimport torch
import torch.nn.functional as F
from accelerate import init_empty_weights
from safetensors.torch import load_file, save_file
from torchvision import datasets, transforms
from transformers import AutoConfig, AutoModelfrom optimum.quanto import (Calibration,QTensor,freeze,qfloat8,qint4,qint8,quantization_map,quantize,requantize,
)def test(model, device, test_loader):model.to(device)model.eval()test_loss = 0correct = 0with torch.no_grad():start = time.time()for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)if isinstance(output, QTensor):output = output.dequantize()test_loss += F.nll_loss(output, target, reduction="sum").item() # sum up batch losspred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probabilitycorrect += pred.eq(target.view_as(pred)).sum().item()end = time.time()test_loss /= len(test_loader.dataset)print("\nTest set evaluated in {:.2f} s: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n".format(end - start, test_loss, correct, len(test_loader.dataset), 100.0 * correct / len(test_loader.dataset)))def train(log_interval, model, device, train_loader, optimizer, epoch):model.to(device)model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)if isinstance(output, QTensor):output = output.dequantize()loss = F.nll_loss(output, target)loss.backward()optimizer.step()if batch_idx % log_interval == 0:print("Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(epoch,batch_idx * len(data),len(train_loader.dataset),100.0 * batch_idx / len(train_loader),loss.item(),))def keyword_to_itype(k):return {"none": None, "int4": qint4, "int8": qint8, "float8": qfloat8}[k]def main():# Training settingsparser = argparse.ArgumentParser(description="PyTorch MNIST Example")parser.add_argument("--batch-size", type=int, default=250, metavar="N", help="input batch size for testing (default: 250)")parser.add_argument("--seed", type=int, default=1, metavar="S", help="random seed (default: 1)")parser.add_argument("--model", type=str, default="dacorvo/mnist-mlp", help="The name of the trained Model.")parser.add_argument("--weights", type=str, default="int8", choices=["int4", "int8", "float8"])parser.add_argument("--activations", type=str, default="int8", choices=["none", "int8", "float8"])parser.add_argument("--device", type=str, default=None, help="The device to use for evaluation.")args = parser.parse_args()torch.manual_seed(args.seed)if args.device is None:if torch.cuda.is_available():device = torch.device("cuda")elif torch.backends.mps.is_available():device = torch.device("mps")elif torch.xpu.is_available():device = torch.device("xpu")else:device = torch.device("cpu")else:device = torch.device(args.device)dataset_kwargs = {"batch_size": args.batch_size}if torch.cuda.is_available() or torch.xpu.is_available():backend_kwargs = {"num_workers": 1, "pin_memory": True, "shuffle": True}dataset_kwargs.update(backend_kwargs)transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,)),transforms.Lambda(lambda x: torch.flatten(x)),])dataset1 = datasets.MNIST("./data", train=True, download=True, transform=transform)train_loader = torch.utils.data.DataLoader(dataset1, **dataset_kwargs)dataset2 = datasets.MNIST("./data", train=False, download=True, transform=transform)test_loader = torch.utils.data.DataLoader(dataset2, **dataset_kwargs)model = AutoModel.from_pretrained(args.model, trust_remote_code=True)model.eval()print("Float model")test(model, device, test_loader)weights = keyword_to_itype(args.weights)activations = keyword_to_itype(args.activations)quantize(model, weights=weights, activations=activations)if activations is not None:print("Calibrating ...")with Calibration():test(model, device, test_loader)print(f"Quantized model (w: {args.weights}, a: {args.activations})")test(model, device, test_loader)print("Tuning quantized model for one epoch")optimizer = torch.optim.Adadelta(model.parameters(), lr=0.5)train(50, model, device, train_loader, optimizer, 1)print("Quantized tuned model")test(model, device, test_loader)print("Quantized frozen model")freeze(model)test(model, device, test_loader)# Serialize model to a state_dict, save it to disk and reload itwith NamedTemporaryFile() as tmp_file:save_file(model.state_dict(), tmp_file.name)state_dict = load_file(tmp_file.name)model_reloaded = AutoModel.from_pretrained(args.model, trust_remote_code=True)# Create an empty modelconfig = AutoConfig.from_pretrained(args.model, trust_remote_code=True)with init_empty_weights():model_reloaded = AutoModel.from_config(config, trust_remote_code=True)# Requantize it using the serialized state_dictrequantize(model_reloaded, state_dict, quantization_map(model), device)print("Serialized quantized model")test(model_reloaded, device, test_loader)if __name__ == "__main__":main()
2.3 博主实测
import torch
import torchvision
from torch import nn, optim
from torchvision import transforms, models
from torch.autograd import Variable
from torch.utils.data import DataLoader
import timm
from torchvision.transforms import transforms
from tqdm import tqdm
from torch.amp import GradScaler
from torch.amp import autocast
from copy import deepcopy
def train(model):train_loss = 0.train_acc = 0.n=0d_len=0pbar= tqdm(total=len(train_loader),desc='Train: ')for batch_x, batch_y in train_loader:batch_x, batch_y = Variable(batch_x).to(device), Variable(batch_y).to(device)# print(batch_x.shape,batch_y.shape)optimizer.zero_grad() # 梯度置0d_len+=batch_x.shape[0]if train_amp:#混合精度运算作用域with autocast(device_type='cuda'):out = model(batch_x) # 前向传播loss = loss_func(out, batch_y) # 计算loss#将梯度进行相应的缩放scaler.scale(loss).backward() # 返向传播#设置优化器计步scaler.step(optimizer)#更新尺度scaler.update()else:out = model(batch_x) # 前向传播loss = loss_func(out, batch_y) # 计算loss loss.backward()optimizer.step()# ------计算loss,acctrain_loss += loss.item()# torch.max(out, 1) 指第一维最大值,返回[最大值,最大值索引]pred = torch.max(out, 1)[1]train_correct = (pred == batch_y).sum()train_acc += train_correct.item()n += batch_y.shape[0]pbar.update(1)pbar.set_postfix({'loss': '%.4f' % (train_loss / n),'train acc': '%.3f' % (train_acc / n),'dlen':d_len})pbar.close()print('Train Loss: {:.6f}, Acc: {:.6f}'.format(train_loss / (len(train_data)), train_acc / (len(train_data))) ,batch_x.shape)def eval(model):model.eval()eval_loss = 0.eval_acc = 0.n=0d_len=0pbar= tqdm(total=len(test_loader),desc='Test: ')for batch_x, batch_y in test_loader:# 测试阶段不需要保存梯度信息with torch.no_grad():batch_x, batch_y = Variable(batch_x).to(device), Variable(batch_y).to(device)if train_amp:with autocast(device_type='cuda'):out = model(batch_x)loss = loss_func(out, batch_y)else:out = model(batch_x)loss = loss_func(out, batch_y)eval_loss += loss.item()pred = torch.max(out, 1)[1]num_correct = (pred == batch_y).sum()eval_acc += num_correct.item()d_len+=batch_x.shape[0]n+=1pbar.update(1)pbar.set_postfix({'loss': '%.4f' % (eval_loss / n),'eval acc': '%.3f' % (eval_acc / d_len),'dlen':d_len})pbar.close()print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(test_data)), eval_acc / (len(test_data))))transform_train=transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225))])# 数据预处理
transform_test = transforms.Compose([transforms.Resize(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])# 加载CIFAR-100数据集
train_data = torchvision.datasets.CIFAR100(root=r'D:/datasets/CIFAR-100', train=True, download=True, transform=transform_train)
train_loader = DataLoader(train_data, batch_size=200, shuffle=True)
test_data = torchvision.datasets.CIFAR100(root=r'D:/datasets/CIFAR-100', train=False, download=True, transform=transform_test)
test_loader = DataLoader(test_data, batch_size=200, shuffle=False)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = timm.create_model('resnet18', pretrained=True, num_classes=100).to(device)
#model = Net().to(device)from optimum.quanto import quantize, qint8,qint4,qint2,Calibration,freeze
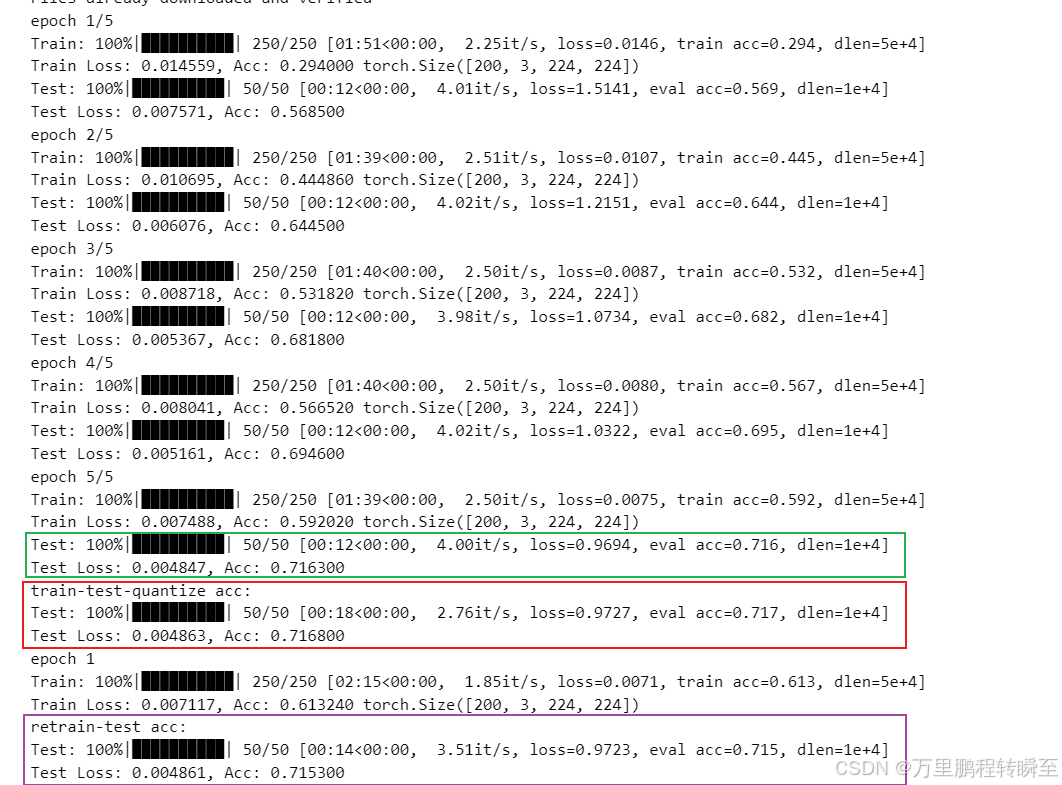
if __name__=="__main__":train_amp = True # EPOCH = 5optimizer = torch.optim.Adam(filter(lambda p : p.requires_grad, model.parameters()),lr=0.001)loss_func = torch.nn.CrossEntropyLoss()scaler = GradScaler()for epoch in range(EPOCH):print('epoch {}/{}'.format(epoch + 1,EPOCH))# training-----------------------------train(model)# evaluation--------------------------------eval(model)keys=list(model.state_dict().keys())key=keys[0]#print('train:',model.state_dict()[key].dtype,model.state_dict()[key][:,0,0,0])model4qat=deepcopy(model)#量化后的模型不支持amp训练train_amp = False # #将模型进行量化quantize(model4qat, weights=qint8, activations=qint8)print('train-test-quantize acc:')with Calibration(momentum=0.9):eval(model4qat)for epoch in range(1):print('epoch {}'.format(epoch + 1))# training-----------------------------train(model4qat)print('retrain-test acc:')eval(model4qat)from optimum.quanto import freezemodel_qat4freeze=deepcopy(model4qat)freeze(model_qat4freeze)# 参数key name发生了变化keys=list(model_qat4freeze.state_dict().keys())key=keys[0]print(model_qat4freeze)print('freeze-test acc:')eval(model_qat4freeze) #Test Loss: 0.004861, Acc: 0.715300
常规训练后量化后的模型精度如红框所示,为71.68%与量化前的71.63%基本一样。同时为了防止量化后模型精度下降,还进行了一个epoch的训练,虽然训练精度有所上升,但测试精度有轻微下降

量化后的模型结构如下所示,可以看到conv、linear相关的layer被替换为optimum-quanto库中的层
ResNet((conv1): QConv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act1): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): BasicBlock((conv1): QConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(drop_block): Identity()(act1): ReLU(inplace=True)(aa): Identity()(conv2): QConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act2): ReLU(inplace=True))(1): BasicBlock((conv1): QConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(drop_block): Identity()(act1): ReLU(inplace=True)(aa): Identity()(conv2): QConv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
...(global_pool): SelectAdaptivePool2d(pool_type=avg, flatten=Flatten(start_dim=1, end_dim=-1))(fc): QLinear(in_features=512, out_features=100, bias=True)
)
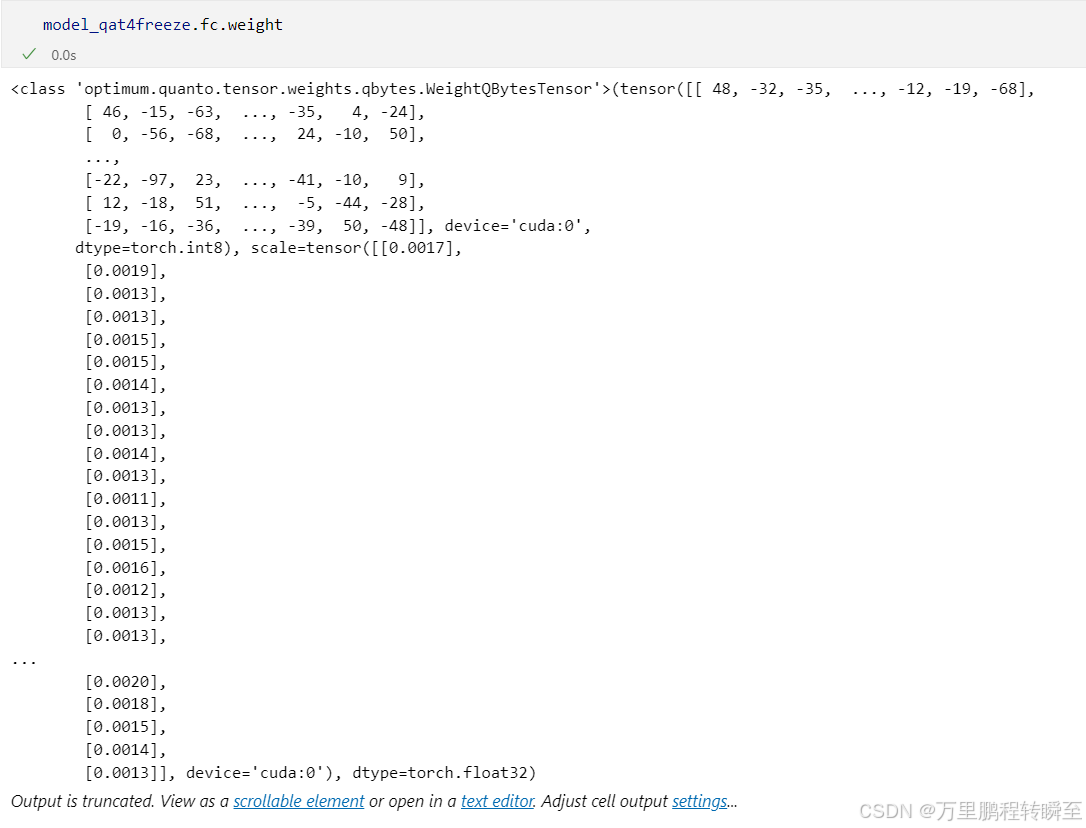
对模型权重进行输出测试,可以发现是int8格式的权重,scale是float
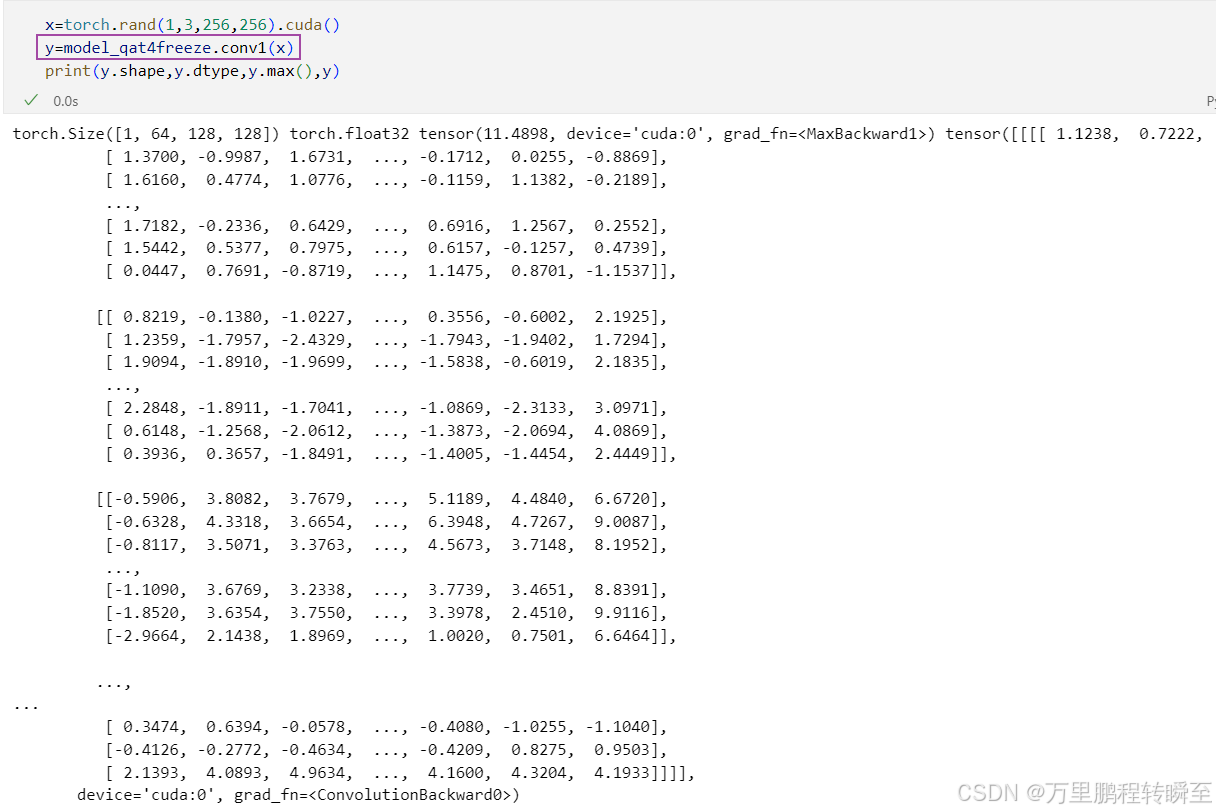
取模型中单独layer进行forward,可以发现输出的是flaot类型。
3、代码深入
在optimum.quanto库中,模型量化以quantize(model, weights=qint8, activations=qint8)为入口,自动将可量化训练layer替换为Qlayer(含量化与反量化操作)
3.1 量化操作链
在quantize=》_quantize_submodule=》quantize_module
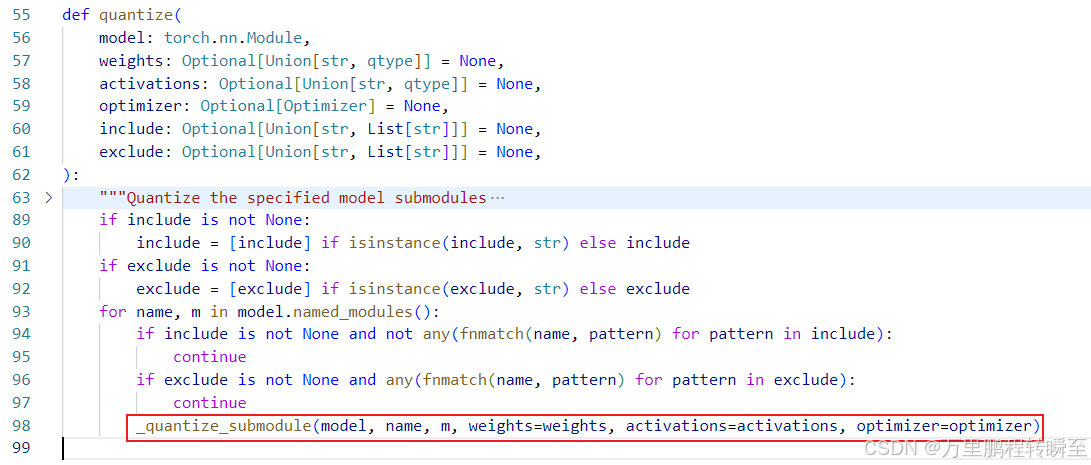
最终在quantize_module函数中,调用 qcls.from_module将原始layer替换为qlayer
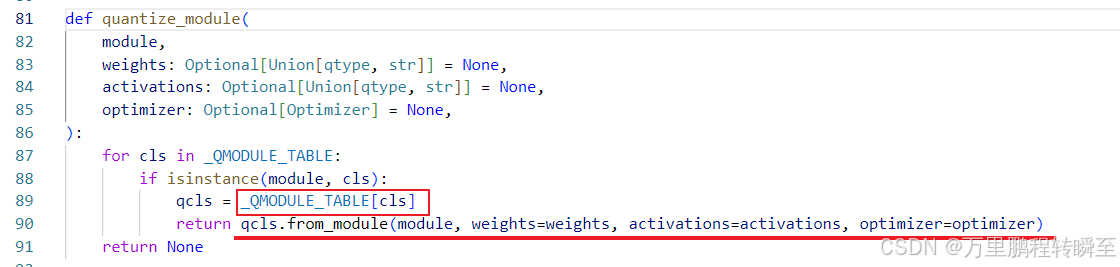
通过对源码追溯,可以发现支持对conv2d、Layernorm、linear的量化

3.2 QModuleMixin
在optimum-quanto中的实现,所有的qlayer均继承自QModuleMixin, torch.nn.Conv2d,基于qcreate属性完成属性初始化。
@register_qmodule(torch.nn.Conv2d)
class QConv2d(QModuleMixin, torch.nn.Conv2d):@classmethoddef qcreate(cls,module,weights: qtype,activations: Optional[qtype] = None,optimizer: Optional[Optimizer] = None,device: Optional[torch.device] = None,):return cls(in_channels=module.in_channels,out_channels=module.out_channels,kernel_size=module.kernel_size,stride=module.stride,padding=module.padding,dilation=module.dilation,groups=module.groups,bias=module.bias is not None,padding_mode=module.padding_mode,dtype=module.weight.dtype,device=device,weights=weights,activations=activations,optimizer=optimizer,)def forward(self, input: torch.Tensor) -> torch.Tensor:return self._conv_forward(input, self.qweight, self.bias)
在QModuleMixin中,可以跟量化直接相关的属性weight_qtype、activation_qtype、input_scale、output_scale。同时可以发现,关于输入输出的量化是基于hook实现的。此外,可以发现weight_group_size的值默认为最大值128,根据输入通道的变化,控制为32的倍数(只针对非int8量化有效)。
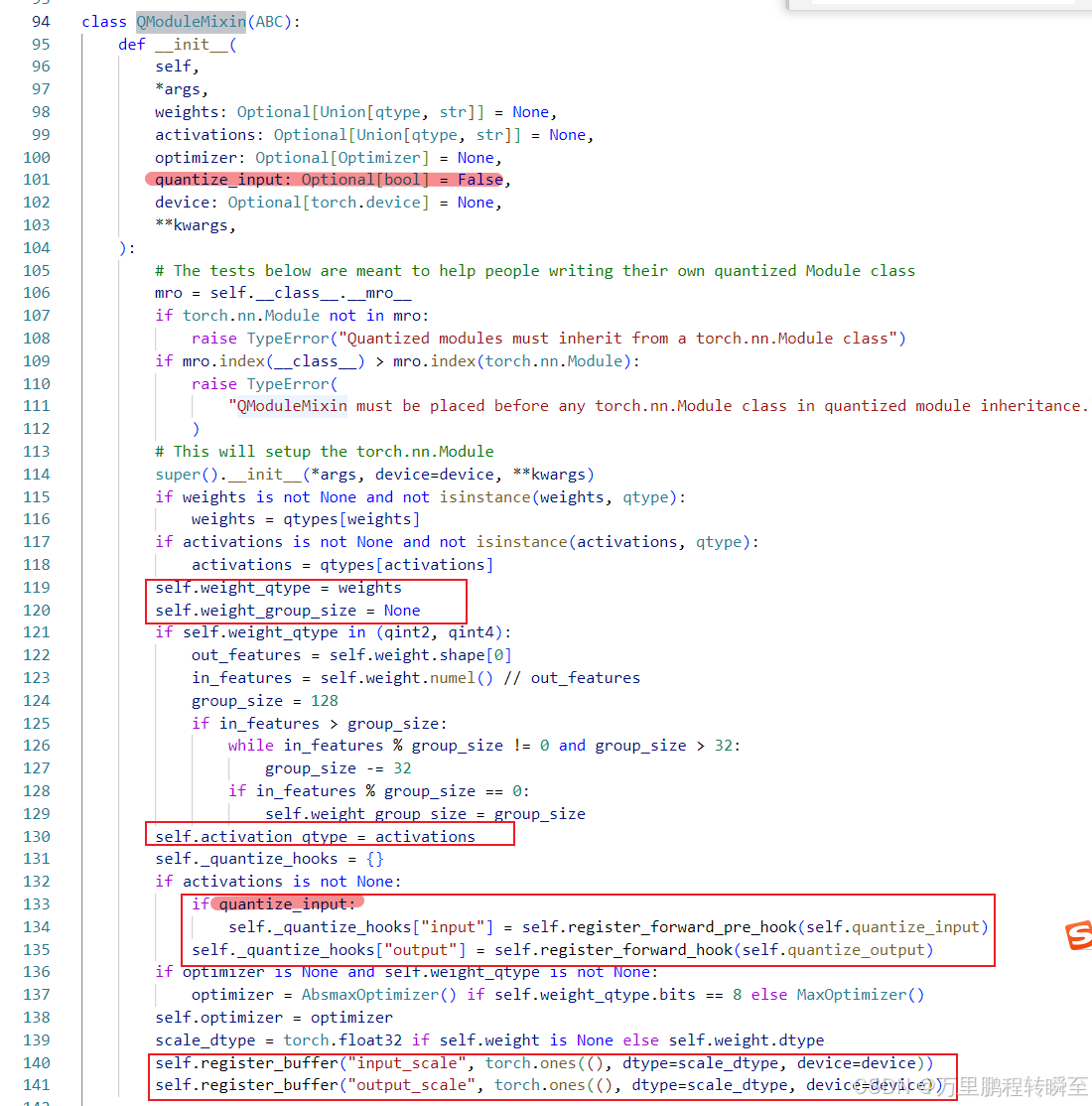
输入输出的量化 均基于quantize_activation函数实现
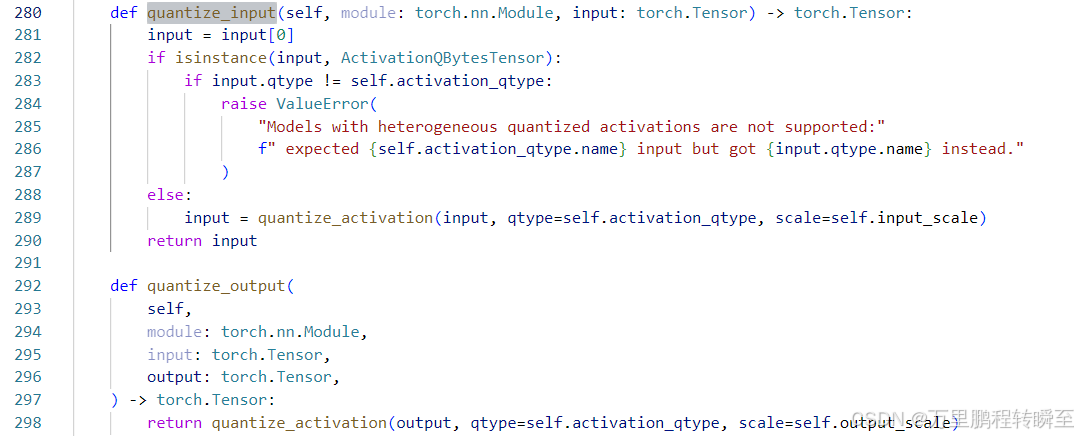
通过追溯可以定位到是基于torch.ops.quanto.quantize_symmetric函数实现量化
权重的量化 基于qweight属性调用self.optimizer与quantize_weight进行实现。如AbsmaxOptimizer用于计算出数据的scale。 如果是MaxOptimizer的话,会返回scale与zero_point
# zero_point为none
class AbsmaxOptimizer(SymmetricOptimizer): def optimize(self, base: torch.Tensor, qtype: qtype, axis: Optional[int] = None) -> Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]:base = torch.abs(base)if axis is None:rmax = torch.max(base)else:dim = list(range(1, base.ndim)) if (axis == 0) else list(range(0, base.ndim - 1))rmax = torch.amax(torch.abs(base), dim=dim, keepdim=True)return rmax / qtype.qmaxclass MaxOptimizer(AffineOptimizer):def optimize(self, base: torch.Tensor, qtype: qtype, axis: int) -> Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]:dim = list(range(1, base.ndim)) if (axis == 0) else list(range(0, base.ndim - 1))rmin = torch.amin(base, dim=dim, keepdim=True)rmax = torch.amax(base, dim=dim, keepdim=True)qmin = -(2 ** (qtype.bits - 1))qmax = 2 ** (qtype.bits - 1) - 1scale = (rmax - rmin) / (qmax - qmin)shift = -rminreturn scale, shift
quantize_weight在底层基于WeightsQBitsQuantizer类实现权重量化,核心操作为torch.ops.quanto.quantize_affine函数,具体如下。其中shift为量化后数据的0点。
class WeightsQBitsQuantizer(Function):@staticmethoddef forward(ctx,base: torch.Tensor,qtype: qtype,axis: int,group_size: int,scale: torch.Tensor,shift: torch.Tensor,optimized: bool,):if qtype not in (qint2, qint4):raise ValueError("WeightQBitsTensor can only be of qint2 or qint4 qtype")if axis not in (0, -1):raise ValueError("WeightQBitsTensor axis parameter must be 0 (first axis) or -1 (last axis)")size = base.size()stride = base.stride()data = torch.ops.quanto.quantize_affine(base, bits=qtype.bits, axis=axis, group_size=group_size, scale=scale, shift=shift)if optimized:return WeightQBitsTensor.create(qtype, axis, group_size, size, stride, data, scale, shift)return WeightQBitsTensor(qtype, axis, group_size, size, stride, data, scale, shift)@staticmethoddef backward(ctx, gO):# For autograd, quantization is a no-opreturn gO, None, None, None, None, None, None