推理能力:五一模型大放送
--->更多内容,请移步“鲁班秘笈”!!<---
近日人工智能领域迎来了一波密集的模型发布潮,多家科技巨头和研究机构相继推出了具有突破性特点的AI模型。这些新模型在参数规模、计算效率、多模态能力以及推理能力等方面都展现出显著进步,反映了AI技术在不同应用场景的专业化发展趋势。

微软的Phi-4-Reasoning系列
LLM在数学问题解决、算法规划或编码等推理密集型任务上的有效性仍受到模型大小、训练方法和推理时能力的限制。表现良好的通用NLP基准模型往往缺乏构建多步推理链或反思中间问题解决状态的能力。
4月30日,微软推出了Phi-4推理系列,包括三个模型——Phi-4-reasoning、Phi-4-reasoning-plus和Phi-4-mini-reasoning。这些模型源自Phi-4基础版(14B参数),专门训练用于处理数学、科学领域和软件相关问题解决中的复杂推理任务。每个变体都解决了计算效率和输出精度之间的不同权衡。

Phi-4-reasoning模型基于Phi-4架构构建,针对模型行为和训练方案进行了有针对性的改进:
-
结构化监督微调(SFT):精心策划了超过140万个提示,重点关注"边界"案例——处于Phi-4能力边缘的问题,强调多步推理而非事实回忆
-
思维链格式:为促进结构化推理,模型被训练使用显式<think>标签生成输出,鼓励推理过程和最终答案之间的分离。
-
扩展上下文处理:修改了RoPE基频以支持32K令牌上下文窗口,允许更深入的解决方案痕迹,特别适用于多轮或长格式问题格式。
-
强化学习(Phi-4-reasoning-plus):使用群体相对策略优化(GRPO),Phi-4-reasoning-plus在约6,400个以数学为重点的问题集上进一步精炼。设计了奖励函数以偏好正确、简洁和结构良好的输出,同时惩罚冗长、重复和格式违规。
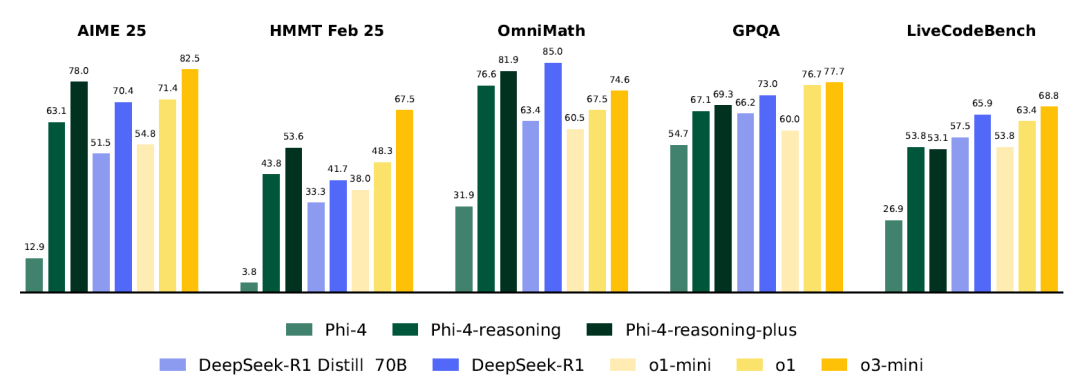
在广泛的推理基准测试中,Phi-4-reasoning-plus不仅在特定领域评估中表现出色,而且很好地泛化到规划和组合问题,如TSP和3SAT,尽管在这些领域没有明确训练。在指令遵循(IFEval)和长上下文QA(FlenQA)方面也观察到性能提升,表明思维链公式改善了更广泛的模型效用。
重要的是,微软报告了AIME 2025等敏感数据集在50多次生成运行中的完整方差分布,揭示Phi-4-reasoning-plus的性能一致性与o3-mini等模型相当甚至有些领域还超过

Qwen2.5-Omni-3B
4月30日,阿里巴巴发布了Qwen2.5-Omni-3B模型,作为Qwen2.5-Omni系列的轻量级变体。该模型仅有3B参数,却能提供接近7B参数模型的性能表现,最大的亮点在于其显著降低的内存占用——在处理长序列(约25,000个token)时,VRAM消耗减少了超过50%。
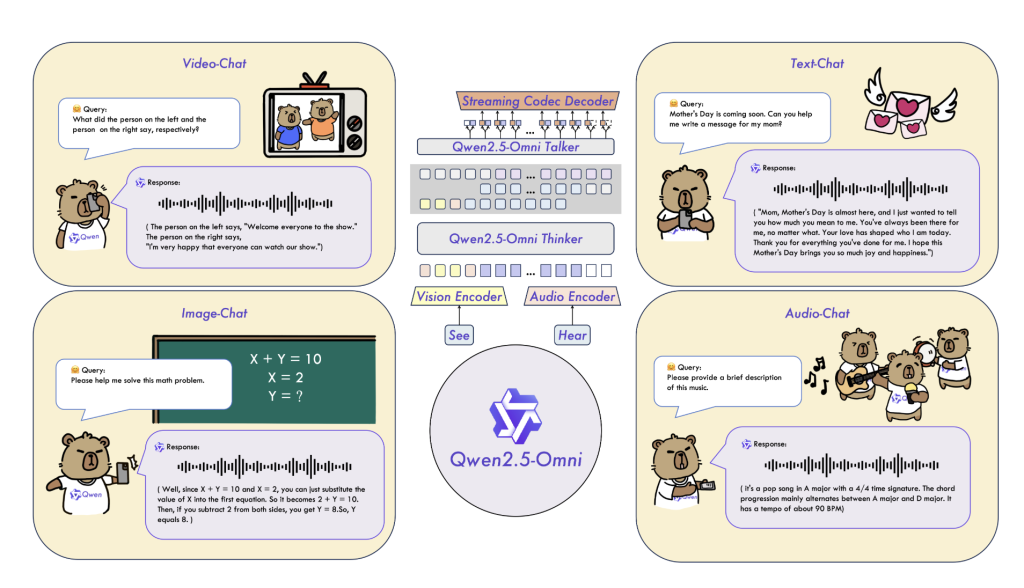
Qwen2.5-Omni-3B采用基于Transformer的架构,支持跨文本、图像和音视频输入的多模态理解。该模型沿袭了其7B对应版本的设计理念,采用模块化方法,通过共享的Transformer主干网络统一各种模态特定的输入编码器。这种设计使其能够在保持多模态理解能力的同时,大幅降低计算资源需求。
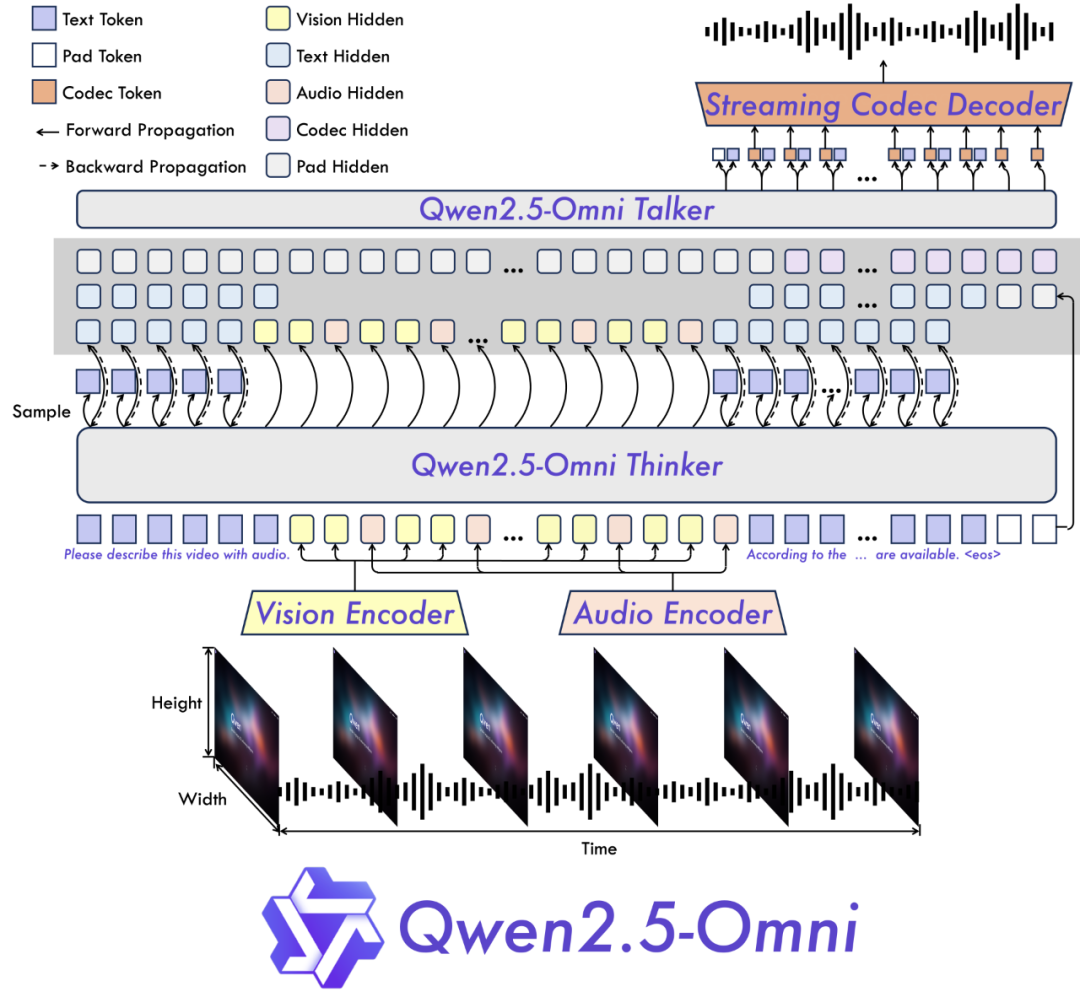
核心特性包括:
-
内存足迹优化:专为24GB GPU运行而优化,使其兼容广泛可用的消费级硬件(如NVIDIA RTX 4090)。
-
长文本处理能力:能够高效处理长序列,特别适用于文档级推理和视频转录分析等任务。
-
多模态流式处理:支持长达30秒的实时音频和视频对话,具有稳定的延迟和最小的输出漂移。
-
多语言支持和语音生成:保留了与7B模型相当的自然语音输出能力,音质清晰度和音调保真度相近。
据ModelScope和Hugging Face上的信息,Qwen2.5-Omni-3B在多个多模态基准测试中表现接近7B变体。内部评估显示,在涉及视觉问答、音频说明和视频理解的任务中,它保留了较大模型90%以上的理解能力。
在长文本任务中,该模型能够稳定处理长达25,000个token的序列,适用于需要文档级合成或时间线感知推理的应用。在基于语音的交互中,模型能够在30秒的剪辑中生成一致且自然的输出,保持与输入内容的一致性并最小化延迟,这对交互式系统和人机界面至关重要。

DeepSeek-Prover-V2
5月1日,DeepSeek-AI发布了DeepSeek-Prover-V2,这是一个专为形式定理证明设计的开源大型语言模型。形式数学推理作为人工智能的专业子领域,要求严格的逻辑一致性。形式定理证明依赖于每一步都被完全描述、精确且可由计算系统验证。
对于AI系统,特别是大型语言模型来说,这是一个特别具有挑战性的任务。语言模型通常擅长产生连贯的自然语言响应,但通常缺乏生成可验证的形式证明的严谨性。当前语言模型无法弥合非形式和形式推理之间的概念鸿沟,这成为一个主要问题。
DeepSeek-Prover-V2的核心方法是利用子目标分解和强化学习。该团队的方法使用DeepSeek-V3将复杂定理分解为可管理的子目标,每个子目标都转化为Lean 4中的"have"语句,并带有表示证明不完整的占位符。这些子目标随后传递给一个7B大小的证明模型,完成每个证明步骤。

一旦所有步骤解决,它们被合成为一个完整的Lean证明,并与由DeepSeek-V3生成的原始自然语言推理配对,形成强化学习的丰富冷启动数据集。重要的是,该模型的训练完全从合成数据引导,没有使用人工注释的证明步骤。
冷启动流程从提示DeepSeek-V3创建自然语言证明草图开始。这些草图被转化为带有未解决部分的形式定理语句。一个关键创新在于使用7B证明器递归解决每个子目标,在保持形式严谨性的同时降低计算成本。研究人员构建了一个课程学习框架,随着时间增加训练任务的复杂性。
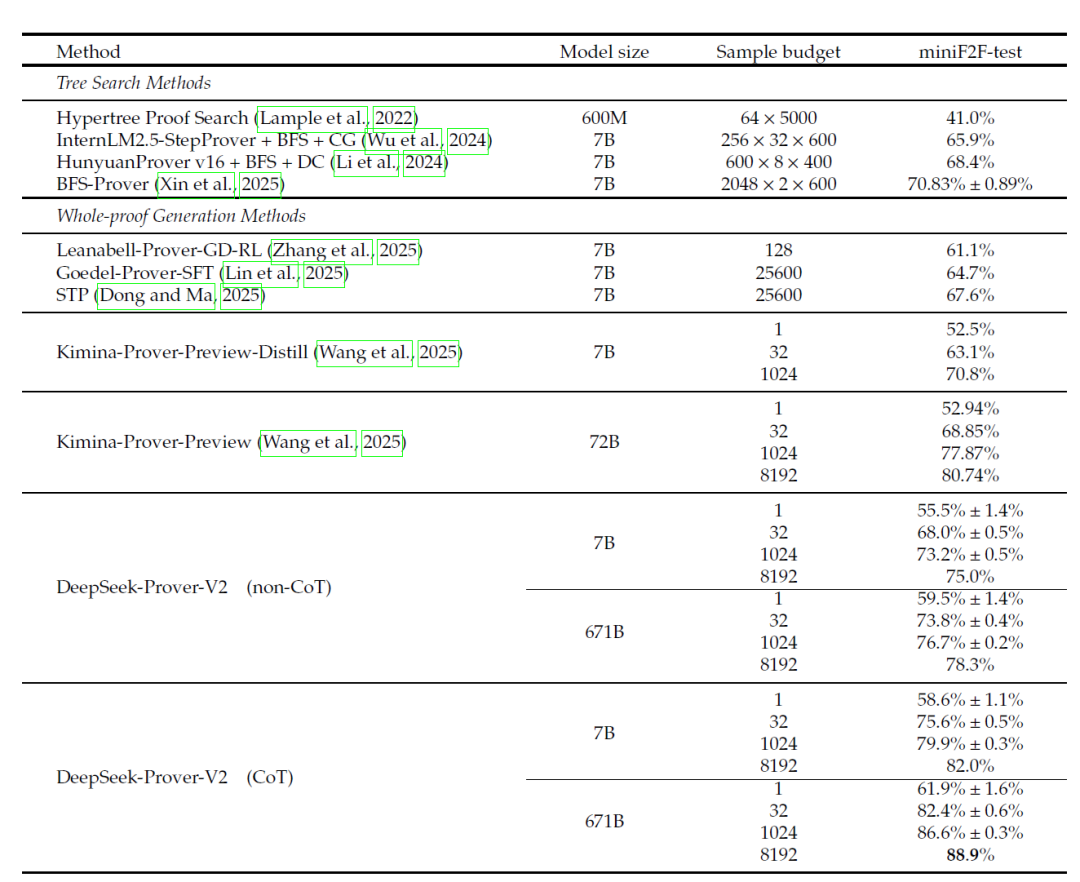
在MiniF2F测试基准上,该模型以高采样(Pass@8192)实现了88.9%的通过率,相比之下,Kimina-Prover为82.0%,Geodel-Prover为64.7%。它还解决了PutnamBench中658个问题中的49个,这是一个包含具有挑战性数学任务的平台。
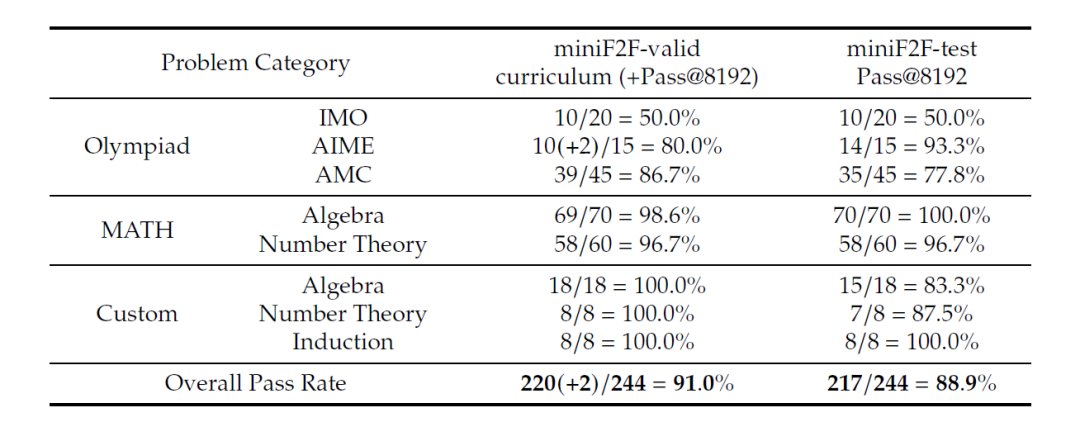
在新引入的ProverBench数据集上,该模型解决了2024年和2025年美国邀请数学考试(AIME)比赛中15个问题中的6个。