Day2:强化学习之TD learning
一、梯度下降
1.为什么要用梯度下降
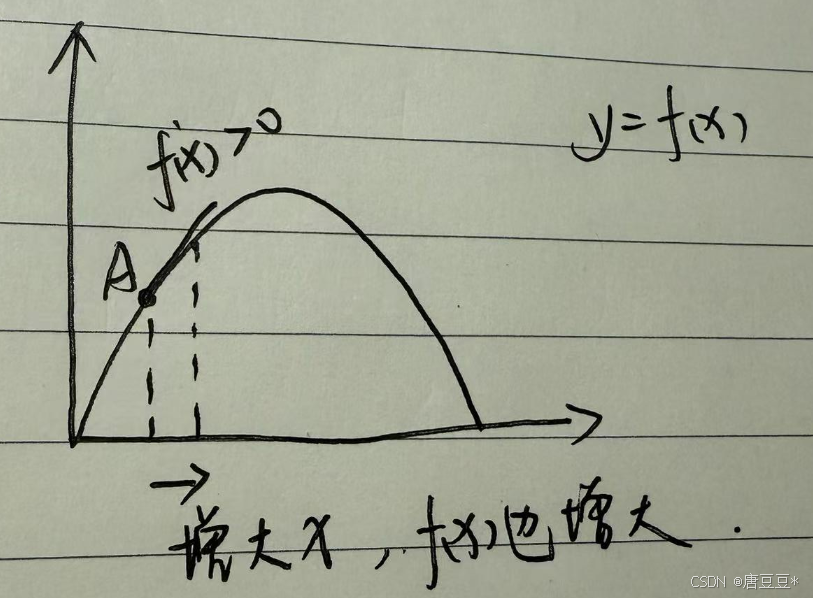
梯度的方向是函数上升最快的方向,沿着梯度方向对参数做更新,就可以使的目标函数增大。
如图所示,对于函数y=f(x), 在A点的导数是大于零的,也就是增大x,f(x)也会增大。所以,我们沿着梯度方向前进,就可以找到目标函数的最大值。
而我们的进行神经网络学习的时候,目标让预测值与真实值的误差之和最小,也就是是MSE(平均平方误差)最小:
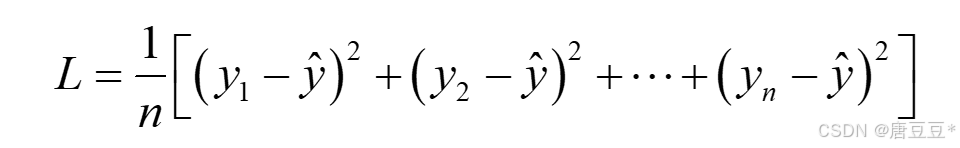
由于我们的优化目标是最小化目标函数(损失函数),所以是沿着梯度的负方向更新参数,也就是梯度下降。
2.梯度下降的参数更新方法:
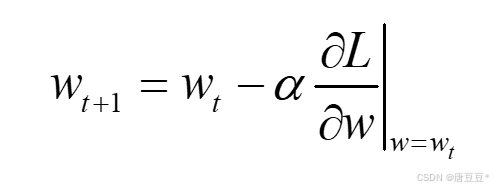
其中,α为学习率。
二、DQN
1.动作价值函数和最优动作价值函数
动作价值函数:Ut是一个随机变量,其随机性来源于t时刻之后的所有状态和动作,为了消除t时刻之后的所有状态和动作影响,对Ut求条件期望,就可以获得动作价值函数,消除st+1.和at+1及其之后所有状态动作影响。
![]()
最优动作价值函数: 已知st和at,回报ut的期望的最大值。可以消除策略的影响。
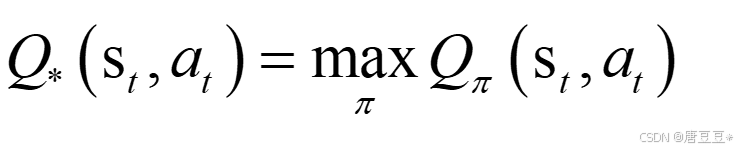
2.DQN:Deep Q network,深度Q网络
1)DQN的作用:DQN在这里主要是用来预测Q(s,a;w),使它尽量接近![]()
2)输入与输出:DQN的输入使状态s,输出使离散动作空间中的每个动作的Q 值。有几个动作,输出就是几维的向量。
3)梯度:在训练DQN时,需要对DQN关于神经网络参数w求梯度:
![]()
4) 梯度优化:
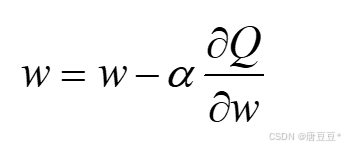
三、TD Learning(Temporal difference, 时间差分)
理论上,根据DQN需要有整个过程的真实值后,才能进行反向传播优化,但采用TD算法,可以在只有部分真实值的时候,对w进行优化。也就是用部分真实结果+部分预测结果看作新的结果(TD目标),对之前的预测模型进行优化。由于其中包含部分真实数据,所以相较于之前的预测结果会更加接近真实值。
四、用TD训练DQN(这个是具体的用法)
1.观测st和at;
2.计算DQN的预测值:
![]()
3.环境给出st+1和rt
4.计算TD目标:
![]()
5.计算TD误差:
![]()
6.更新参数
![]()
根据这个方法,可以采用在每一个动作之后,更新参数w,也可以在完成一个回合后进行对应的参数更新。
~*后续如果开始编写程序了,再进行代码补充,目前先完成概念学习~
学习资料:《深度强化学习》,作者王树森、黎彧君、张志华。
学习视频:【王树森】深度强化学习(DRL)_哔哩哔哩_bilibili