TorchRec - PyTorch生态下的推荐系统解决方案 [官方文档翻译]
本文翻译整理自:
https://pytorch.org/torchrec/overview.html
文章目录
- TorchRec
- 为什么选择TorchRec?
- TorchRec 高级架构
- TorchRec的并行策略:模型并行
- 表格嵌入
- 相关内容
- TorchRec 概念
- JaggedTensor
- KeyedJaggedTensor
- 规划器
- EmbeddingTables的划分
- 使用TorchRec分片模块进行分布式训练
- 分布式模型并行
- 优化器
- 推理
- 相关链接
- 设置 TorchRec
- 系统要求
- 版本兼容性
- 安装
- 运行一个简单的 TorchRec 示例
TorchRec
TorchRec 是 PyTorch 推荐系统库,旨在提供创建最先进个性化模型的常用原语以及通往生产的路径。TorchRec 在许多 Meta 生产推荐系统模型中得到了广泛应用,用于训练和推理工作流程。
为什么选择TorchRec?
TorchRec旨在解决构建、扩展和部署大规模、大规模推荐系统模型所面临的独特挑战,而这并不是常规PyTorch的关注焦点。更具体地说,TorchRec为通用推荐系统提供了以下基本功能:
- 专用组件:TorchRec提供了简单、专用的模块,这些模块在编写推荐系统时很常见,重点在于嵌入表
- 高级分片技术:TorchRec提供了灵活且可定制的分片方法,用于处理大规模嵌入表:行分片、列分片、表分片等。TorchRec可以自动确定针对设备拓扑的最佳计划,以实现高效的训练和内存平衡
- 分布式训练:虽然PyTorch支持基本的分布式训练,但TorchRec通过为推荐系统的大规模扩展专门设计的更复杂的模型并行技术扩展了这些功能
- 极致优化:TorchRec的训练和推理组件在FBGEMM之上进行了极致优化。毕竟,TorchRec为Meta的一些最大的推荐系统模型提供了动力
- 无缝部署路径:TorchRec提供了简单的API,用于将训练好的模型转换为推理模型,并将其加载到C++环境中以实现最优推理模型
- 与PyTorch生态系统集成:TorchRec建立在PyTorch之上,这意味着它可以无缝地与现有的PyTorch代码、工具和工作流程集成。这使得开发者可以在利用推荐系统的高级功能的同时,利用现有的知识和代码库。作为PyTorch生态系统的一部分,TorchRec受益于PyTorch的强大社区支持、持续更新和改进。
TorchRec 高级架构
在本节中,您将了解TorchRec的高级架构,它旨在利用PyTorch优化大规模推荐系统。您将学习TorchRec如何使用模型并行性将复杂模型分布在多个GPU上,从而增强内存管理和GPU利用率,以及了解TorchRec的基本组件和分片策略。
实际上,TorchRec提供了并行原语,允许混合数据并行性/模型并行性、嵌入表分片、规划器生成分片计划、流水线训练等功能。
TorchRec的并行策略:模型并行
随着现代深度学习模型的规模不断扩大,分布式深度学习已成为成功训练模型所需的时间内的必要条件。在这个范式下,已经开发出两种主要方法:数据并行和模型并行。TorchRec专注于后者,用于嵌入表的分片。
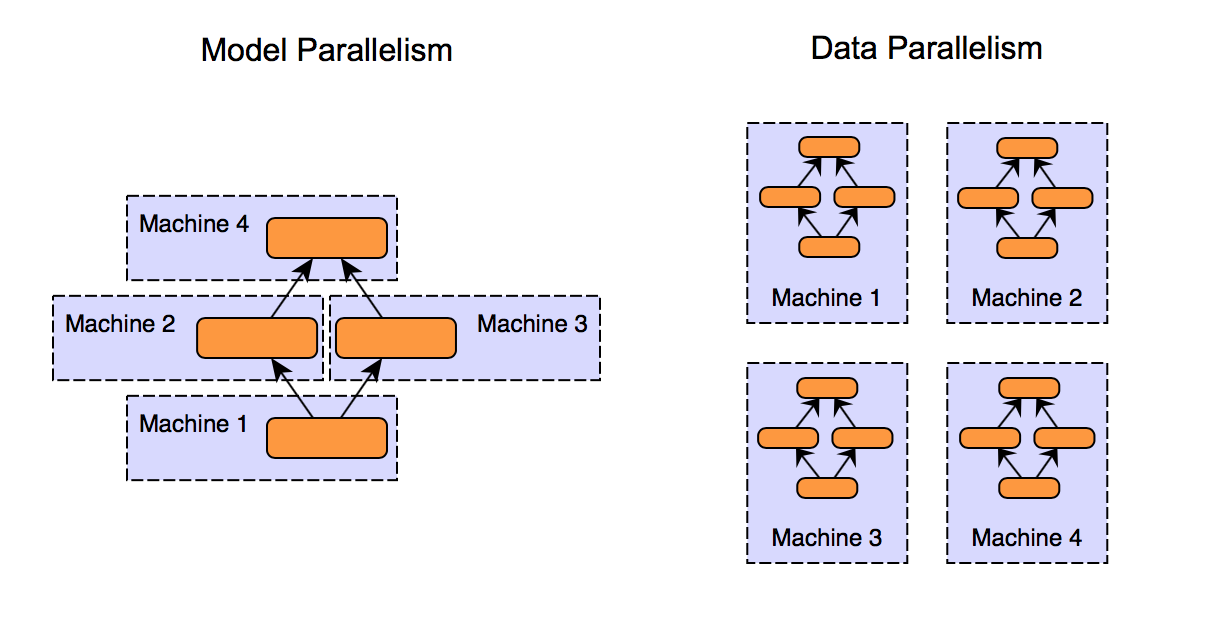
图1、模型并行和数据并行方法的比较
如图所示,模型并行和数据并行是两种在多个GPU之间分配工作负载的方法。
- 模型并行
- 将模型划分为多个段,并将它们分布到多个GPU上
- 每个段独立处理数据
- 适用于不适合单个GPU的大型模型
- 数据并行
- 在每个GPU上分配整个模型的副本
- 每个GPU处理数据的一个子集,并贡献到整体计算中
- 适用于适合单个GPU但需要处理大型数据集的模型
- 模型并行的优势
- 优化了大型模型的内存使用和计算效率
- 特别适用于具有大型嵌入表的推荐系统
- 使DLRM型架构中的嵌入并行计算成为可能
表格嵌入
为了使TorchRec能够确定要推荐的内容,我们需要能够表示实体及其关系,这正是嵌入所用的目的。嵌入是在高维空间中用于表示复杂数据(如词语、图像或用户)意义的实数向量。嵌入表是将多个嵌入聚合到一个矩阵中的集合。最常见的情况下,嵌入表表示为一个维度为(B, N)的二维矩阵。
- B 代表表中存储的嵌入数量
- N 代表每个嵌入的维度数。
每个B也可以被称为一个ID(代表诸如电影标题、用户、广告等信息),当访问一个ID时,我们会得到一个对应的嵌入向量,其大小为嵌入维度N。
还有对嵌入池化的选择,通常我们会在给定特征上查找多行,这引发了一个问题:我们应该如何处理多个嵌入向量的查找。池化是一种常见的技术,其中我们将嵌入向量结合起来,通常是通过行求和或平均值,以产生一个嵌入向量。这是PyTorch的nn.Embedding和nn.EmbeddingBag之间的主要区别。
PyTorch通过nn.Embedding和nn.EmbeddingBag来表示嵌入。在构建这些模块的基础上,TorchRec引入了EmbeddingCollection和EmbeddingBagCollection,这些是相应PyTorch模块的集合。这种扩展使TorchRec能够批量处理表格,并在单个内核调用中对多个嵌入进行查找,从而提高效率。
以下是描述嵌入在推荐模型训练过程中使用的端到端流程图的示例:
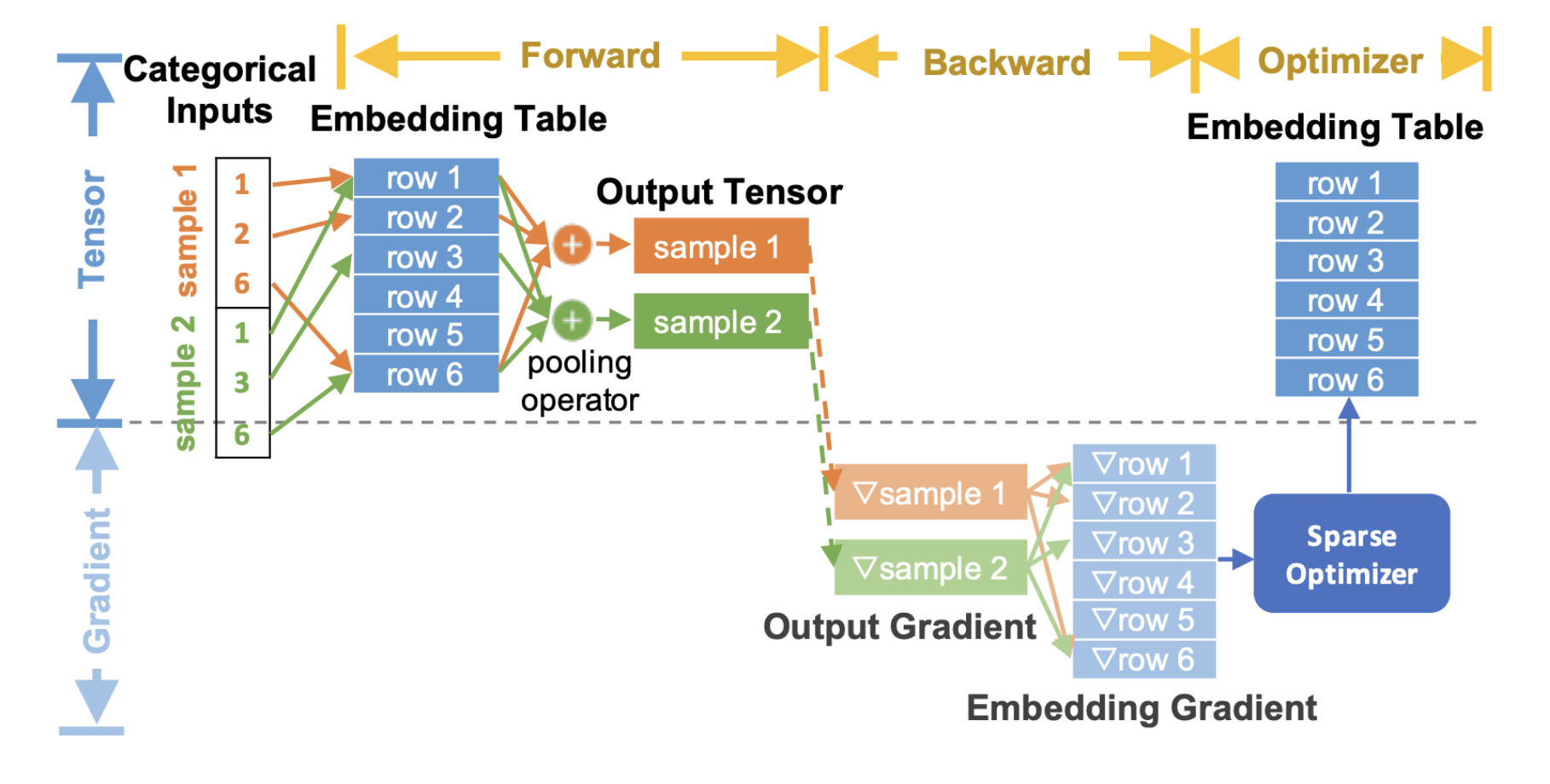
图2、TorchRec端到端嵌入流程
在上面的图中,我们展示了TorchRec端到端嵌入查找过程的一般情况,- 在前向传播中执行嵌入查找和池化
- 在反向传播中计算输出查找的梯度,并将它们传递给优化器以更新嵌入表
注意,这里将嵌入梯度灰色显示,因为我们并没有完全将这些梯度物质化到内存中,而是将它们与优化器更新融合。这导致了显著的内存减少,我们将在优化器概念部分中详细说明。
我们建议您查阅TorchRec概念页面,以了解如何从头到尾理解一切的基本原理。它包含了大量有用信息,可以帮助您充分利用TorchRec。
相关内容
- 什么是分布式数据并行(DDP)教程
TorchRec 概念
在本节中,我们将学习TorchRec的关键概念,TorchRec旨在使用PyTorch优化大规模推荐系统。我们将详细了解每个概念的工作原理,并回顾它们如何在TorchRec的其余部分中使用。
TorchRec的模块具有特定的输入/输出数据类型,以高效地表示稀疏特征,包括:
- JaggedTensor:围绕长度/偏移量和值张量的包装器,用于单个稀疏特征。
- KeyedJaggedTensor:高效地表示多个稀疏特征,可以将其视为多个
JaggedTensor。 - KeyedTensor:围绕
torch.Tensor的包装器,允许通过键访问张量值。
为了实现高性能和效率,标准的torch.Tensor在表示稀疏数据时非常低效。TorchRec引入了这些新的数据类型,因为它们提供了高效存储和表示稀疏输入数据的能力。正如您稍后将会看到的,KeyedJaggedTensor使得在分布式环境中传递输入数据非常高效,这导致了TorchRec提供的关键性能优势之一。
在端到端训练循环中,TorchRec包含以下主要组件:
- Planner:接收嵌入表配置、环境设置,并为模型生成优化的分片计划。
- Sharder:根据分片计划对模型进行分片,包括数据并行、表级、行级、表级-行级、列级和表级-列级分片策略。
- DistributedModelParallel:结合Sharder、优化器,并提供了一种在分布式方式中训练模型的方法。
JaggedTensor
JaggedTensor 表示通过长度、值和偏移量来表示稀疏特征。它被称为“锯齿状”是因为它可以高效地表示具有可变长度序列的数据。相比之下,标准的 torch.Tensor 假设每个序列都具有相同的长度,但在现实世界的数据中往往并非如此。JaggedTensor 便于表示这种数据,而不需要填充,使其非常高效。
关键组件:
Lengths:一个表示每个实体元素数量的整数列表。Offsets:一个表示每个序列在扁平化值张量中起始索引的整数列表。这些提供了一个与长度不同的选择。Values:一个包含每个实体的实际值的1D张量,存储在连续的位置。
下面是一个简单的示例,演示了每个组件将如何看起来:
# User interactions:
# - User 1 interacted with 2 items
# - User 2 interacted with 3 items
# - User 3 interacted with 1 item
lengths = [2, 3, 1]
offsets = [0, 2, 5] # Starting index of each user's interactions
values = torch.Tensor([101, 102, 201, 202, 203, 301]) # Item IDs interacted with
jt = JaggedTensor(lengths=lengths, values=values)
# OR
jt = JaggedTensor(offsets=offsets, values=values)
KeyedJaggedTensor
KeyedJaggedTensor 通过引入键(通常是特征名称)来扩展 JaggedTensor 的功能,用于标记不同的特征组,例如用户特征和项目特征。这是在 EmbeddingBagCollection 和 EmbeddingCollection 的 forward 方法中使用的数据类型,因为它们用于在表中表示多个特征。
KeyedJaggedTensor 有一个隐含的批次大小,即特征数除以 lengths 张量的长度。下面的示例中批次大小为 2。与 JaggedTensor 类似,offsets 和 lengths 函数以相同的方式工作。您还可以通过访问 KeyedJaggedTensor 中的键来访问某个特征的长度的 lengths、offsets 和 values。
keys = ["user_features", "item_features"]
# Lengths of interactions:
# - User features: 2 users, with 2 and 3 interactions respectively
# - Item features: 2 items, with 1 and 2 interactions respectively
lengths = [2, 3, 1, 2]
values = torch.Tensor([11, 12, 21, 22, 23, 101, 102, 201])
# Create a KeyedJaggedTensor
kjt = KeyedJaggedTensor(keys=keys, lengths=lengths, values=values)
# Access the features by key
print(kjt["user_features"])
# Outputs user features
print(kjt["item_features"])
规划器
TorchRec 规划器帮助确定模型的最佳分片配置。它评估多种分片嵌入表的方案,以优化性能。规划器执行以下操作:
- 评估硬件的内存约束。
- 根据内存获取操作,如嵌入查找,估计计算需求。
- 解决与数据相关的因素。
- 考虑其他硬件具体因素,如带宽,以生成最优的分片计划。
为确保准确考虑这些因素,规划器可以整合嵌入表、约束、硬件信息和拓扑结构等相关数据,以帮助生成最优计划。
EmbeddingTables的划分
TorchRec分片器为各种用例提供了多种分片策略,我们概述了一些分片策略及其工作原理,以及它们的优点和局限性。通常,我们建议使用TorchRec规划器为您生成分片计划,因为它将为您的模型中的每个嵌入表找到最佳的分片策略。
每种分片策略决定了如何进行表分割,是否应该切割表以及如何切割,是否保留一个或几个表的副本,等等。从分片结果中得到的表的每一部分,无论是整个嵌入表还是其一部分,都被称为分片。
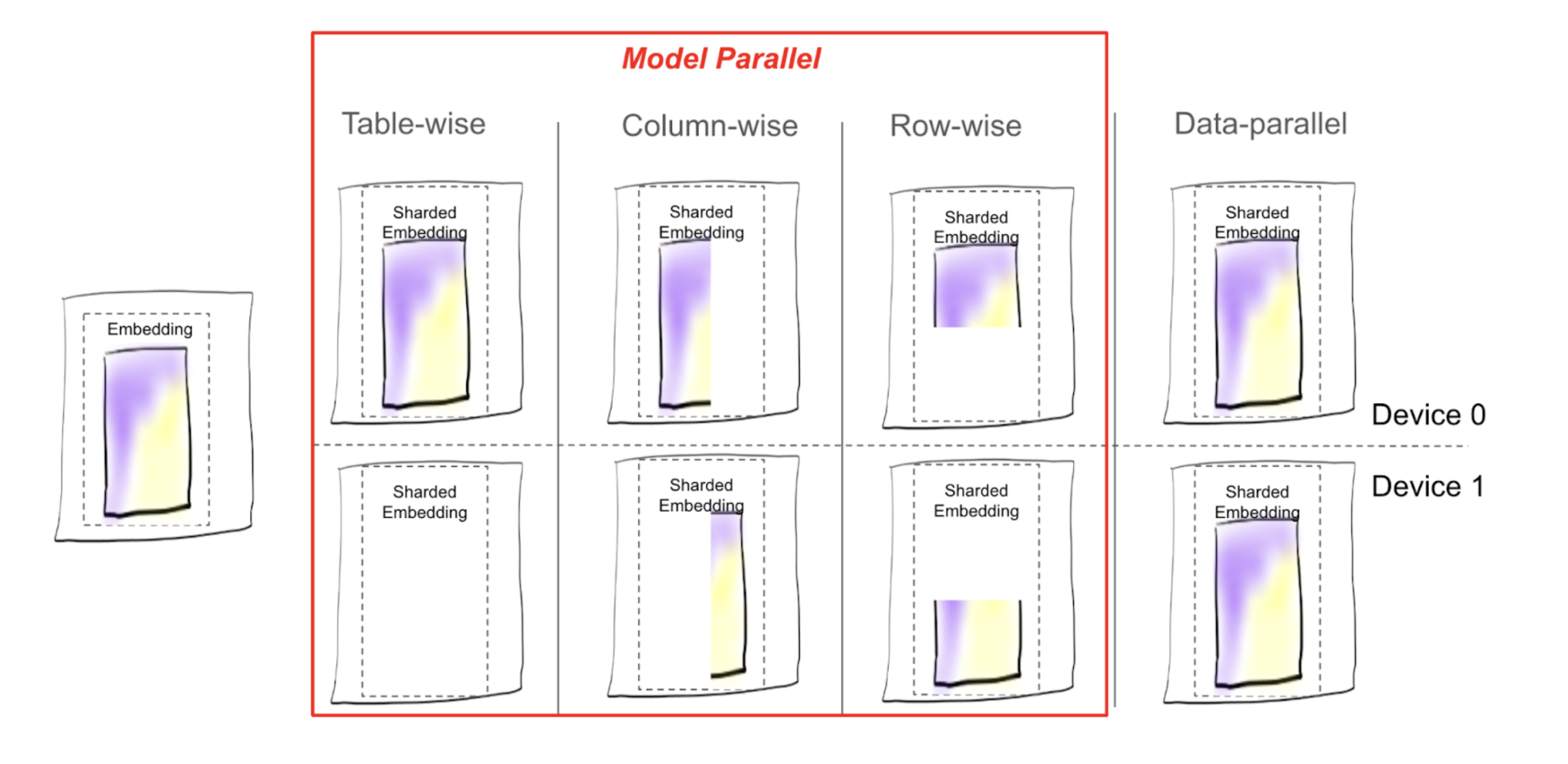
图1:展示TorchRec提供的不同分片方案下表分片的位置
以下是TorchRec中所有可用的分片类型列表:
- 表式(TW):正如其名所示,嵌入表作为一个整体放置在一个rank上。
- 列式(CW):表沿
emb_dim维度分割,例如,emb_dim=256分割成4个分片:[64, 64, 64, 64]。 - 行式(RW):表沿
hash_size维度分割,通常均匀分配到所有rank上。 - 表式-行式(TWRW):表放置在一个主机上,在该主机上的rank之间行式分割。
- 网格分片(GS):表进行列式分片,每个列式分片在该主机上以TWRW方式放置。
- 数据并行(DP):每个rank保留表的副本。
一旦分片,模块将被转换为自身的分片版本,在TorchRec中称为ShardedEmbeddingCollection和ShardedEmbeddingBagCollection。这些模块处理输入数据的通信、嵌入查找和梯度。
使用TorchRec分片模块进行分布式训练
在众多分片策略中,我们如何确定使用哪一种?每种分片方案都有相应的成本,结合模型大小和GPU数量,可以确定哪种分片策略最适合该模型。
在不进行分片的情况下,每个GPU保留嵌入表(DP)的副本,主要成本在于计算,即每个GPU在正向传播中查找其内存中的嵌入向量,并在反向传播中更新梯度。
进行分片后,会增加通信成本:每个GPU需要向其他GPU请求嵌入向量查找,并通信计算出的梯度。这通常被称为“all2all”通信。在TorchRec中,对于给定GPU上的输入数据,我们确定每个数据部分的嵌入分片位于何处,并将其发送到目标GPU。然后,该目标GPU将嵌入向量返回到原始GPU。在反向传播中,梯度被发送回目标GPU,并使用优化器相应地更新分片。
如上所述,分片需要我们通信输入数据和嵌入查找。TorchRec通过三个主要阶段来处理这个问题,我们将称之为用于TorchRec模型训练和推理的分片嵌入模块正向传播:
- 特征all2all/输入分布(
input_dist)- 将输入数据(以
KeyedJaggedTensor的形式)通信到包含相关嵌入表分片适当设备的设备
- 将输入数据(以
- 嵌入查找
- 在特征all2all交换后形成的新的输入数据上查找嵌入
- 嵌入all2all/输出分布(
output_dist)- 将嵌入查找数据通信回请求它的适当设备(根据设备接收到的输入数据)
- 反向传播执行相同的操作,但顺序相反。
以下图表展示了其工作原理:
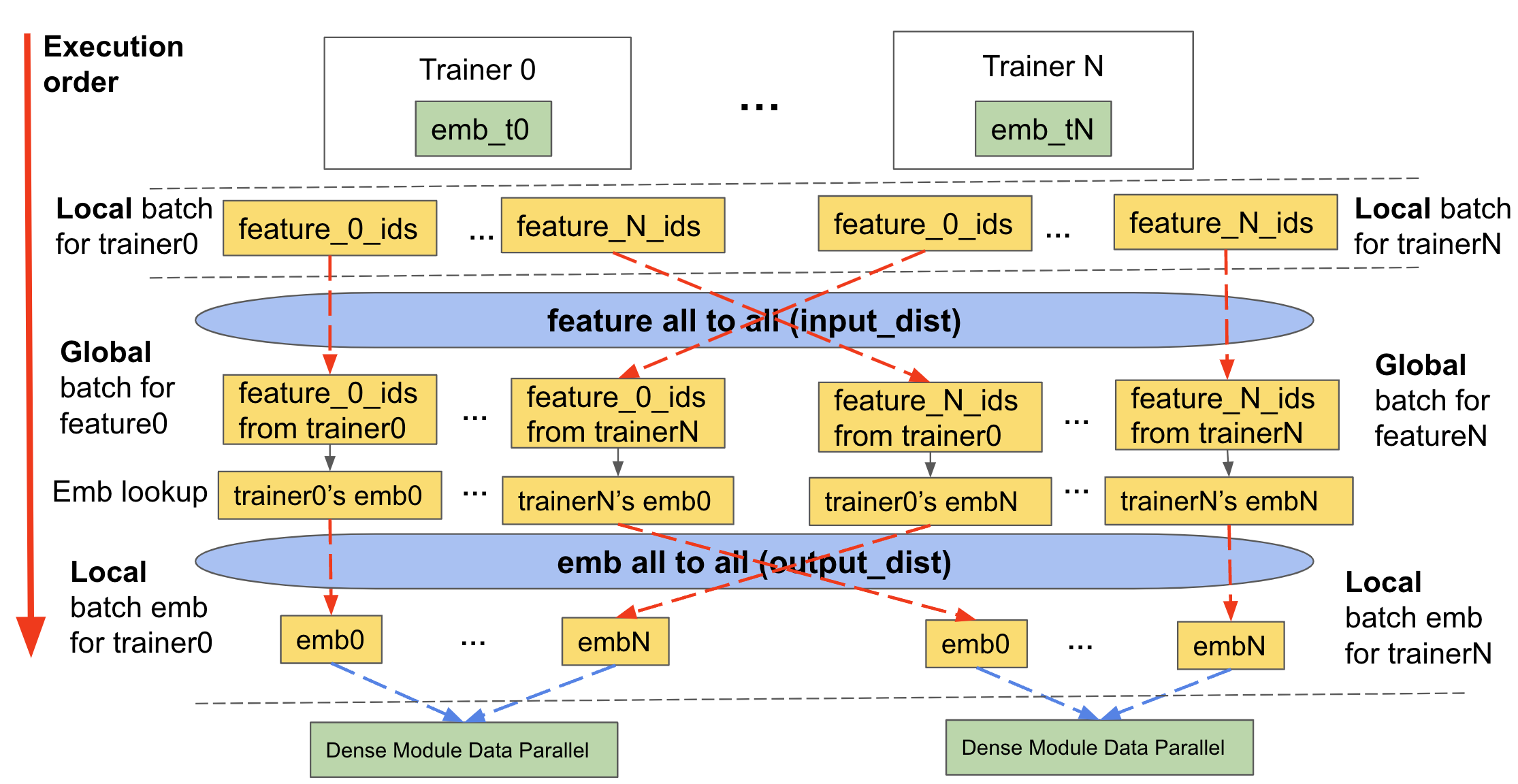
图2:分片TorchRec模块的前向传播,包括input_dist、lookup和output_dist
分布式模型并行
上述所有内容最终汇聚成TorchRec用于分片和集成计划的入口点。从高层次来看,DistributedModelParallel执行以下操作:
- 通过设置进程组和分配设备类型来初始化环境。
- 如果没有提供分片器,将使用默认的分片器,默认包括
EmbeddingBagCollectionSharder。 - 接受提供的分片计划,如果没有提供,则生成一个。
- 创建模块的分片版本,并用它们替换原始模块,例如,将
EmbeddingCollection转换为ShardedEmbeddingCollection。 - 默认情况下,将
DistributedModelParallel包装在DistributedDataParallel中,使模块既支持模型并行也支持数据并行。
优化器
TorchRec模块提供了一个无缝的API,用于融合训练中的反向传播和优化器步骤,从而在性能上提供了显著优化,并减少了内存使用,同时还提供了将不同的优化器分配给不同的模型参数的粒度。
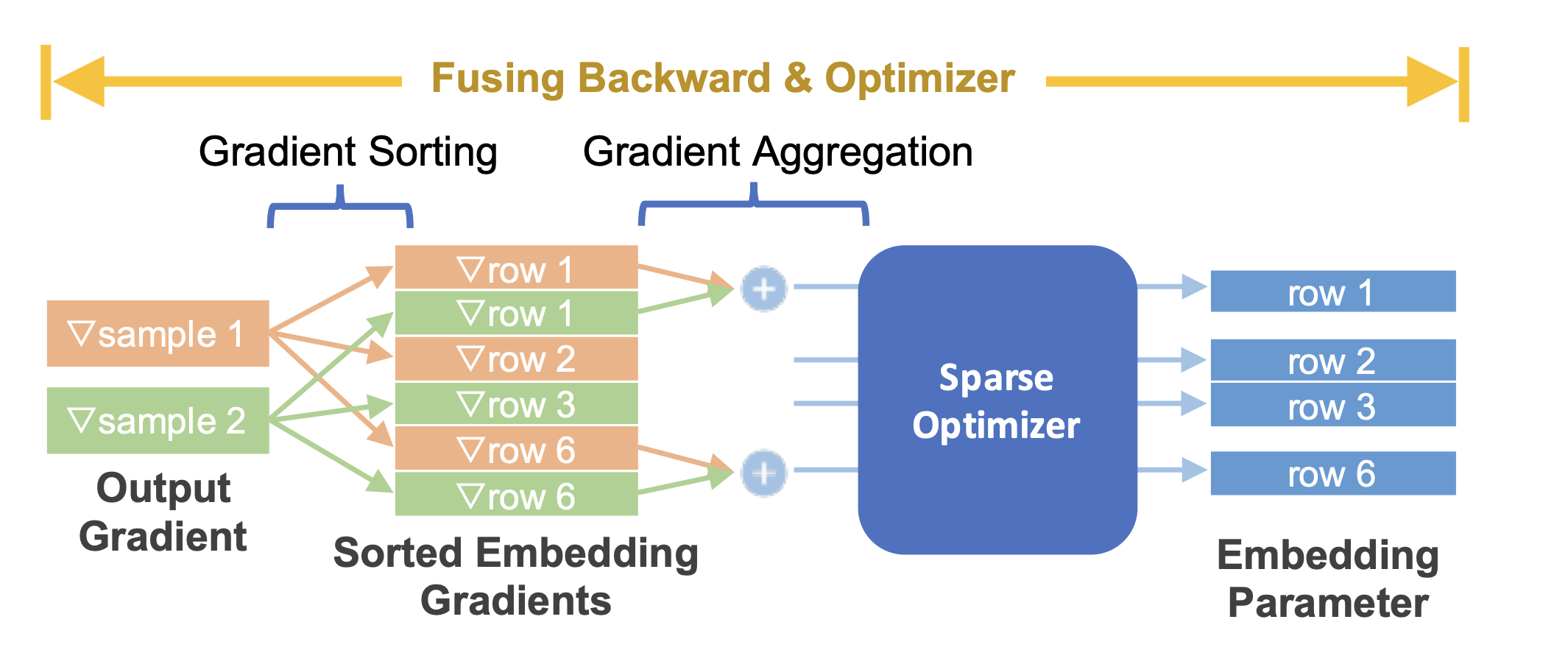
图3:融合嵌入反向传播与稀疏优化器
推理
推理环境与训练不同,它们对性能和模型大小非常敏感。TorchRec推理优化的两个关键差异如下:
- 量化:推理模型进行量化以降低延迟并减小模型大小。这种优化使我们能够尽可能少地使用设备进行推理以最小化延迟。
- C++环境:为了进一步降低延迟,模型在C++环境中运行。
TorchRec提供以下功能将TorchRec模型转换为推理就绪状态:
- 量化模型的API,包括与FBGEMM TBE自动优化的优化
- 分片嵌入以支持分布式推理
- 将模型编译为TorchScript(与C++兼容)
相关链接
- 使用这些概念的TorchRec交互式笔记本
设置 TorchRec
在本节中,我们将:
- 了解使用 TorchRec 的要求
- 设置一个集成 TorchRec 的环境
- 运行基本的 TorchRec 代码
系统要求
TorchRec 通常只在 AWS Linux 上进行测试,并应在类似环境中正常工作。以下展示了目前测试过的兼容性矩阵:
| Python 版本 | 3.9, 3.10, 3.11, 3.12 |
|---|---|
| 计算平台 | CPU, CUDA 11.8, CUDA 12.1, CUDA 12.4 |
除了这些要求之外,TorchRec 的核心依赖项是 PyTorch 和 FBGEMM。如果您的系统通常与这两个库兼容,那么它应该足够用于 TorchRec。
- PyTorch 要求
- FBGEMM 要求
版本兼容性
TorchRec 和 FBGEMM 具有匹配的版本号,这些版本号在发布时一起进行测试:
- TorchRec 1.0 与 FBGEMM 1.0 兼容
- TorchRec 0.8 与 FBGEMM 0.8 兼容
- TorchRec 0.8 可能与 FBGEMM 0.7 不兼容
此外,TorchRec 和 FBGEMM 仅在 PyTorch 有新版本发布时才会发布。因此,TorchRec 和 FBGEMM 的特定版本应与特定的 PyTorch 版本相对应:
- TorchRec 1.0 与 PyTorch 2.5 兼容
- TorchRec 0.8 与 PyTorch 2.4 兼容
- TorchRec 0.8 可能与 PyTorch 2.3 不兼容
安装
以下以CUDA 12.1为例展示安装过程。对于CPU,CUDA 11.8或CUDA 12.4,分别将cu121替换为cpu、cu118或cu124。
通过pytorch.org稳定安装
pip install torch --index-url https://download.pytorch.org/whl/cu121
pip install fbgemm-gpu --index-url https://download.pytorch.org/whl/cu121
pip install torchmetrics==1.0.3
pip install torchrec --index-url https://download.pytorch.org/whl/cu121
运行一个简单的 TorchRec 示例
现在我们已经正确设置了 TorchRec,让我们来运行一些 TorchRec 代码!下面,我们将使用 TorchRec 数据类型 KeyedJaggedTensor 和 EmbeddingBagCollection 运行一个简单的正向传播:
import torchimport torchrec
from torchrec.sparse.jagged_tensor import JaggedTensor, KeyedJaggedTensorebc = torchrec.EmbeddingBagCollection(device="cpu",tables=[torchrec.EmbeddingBagConfig(name="product_table",embedding_dim=16,num_embeddings=4096,feature_names=["product"],pooling=torchrec.PoolingType.SUM,),torchrec.EmbeddingBagConfig(name="user_table",embedding_dim=16,num_embeddings=4096,feature_names=["user"],pooling=torchrec.PoolingType.SUM,)]
)product_jt = JaggedTensor(values=torch.tensor([1, 2, 1, 5]), lengths=torch.tensor([3, 1])
)
user_jt = JaggedTensor(values=torch.tensor([2, 3, 4, 1]), lengths=torch.tensor([2, 2]))# Q1: How many batches are there, and which values are in the first batch for product_jt and user_jt?
kjt = KeyedJaggedTensor.from_jt_dict({"product": product_jt, "user": user_jt})print("Call EmbeddingBagCollection Forward: ", ebc(kjt))
python torchrec_example.py
2025-04-26(六)