【默子速报】DeepSeek新模型 Prover-V2 报告解读
炸裂,太炸裂了,五一不放假是吧?!
默子加班加点的肝解读!
首先是,Deepseek今天下午显示毫无预兆的在HF上发布了最新的Prover-V2参数
直接让一群人瞬间热血沸腾,想要看看Deepseek又干了什么大事。
可打开界面一看,啥说明也没有,就一个纯模型参数上传了上去。
不过还好,默子写了个自动脚本在蹲守,只要Deepseek一发报告。默子就秒知道(指20秒)
所以Deepseek一发报告,默子这第一时间来给大家更新了!
那就让大家跟着默子来一起看看这Deepseek到底更新了什么吧!
前排说明:如果是在等R2或者是V4的朋友可以开溜了,这次更新的是数学证明模型Prover-V2,专注于数学解题的,不是我们了解到那个传统的推理模型。
但,有耐心的朋友不妨继续看看,这个V2可能比大家想的还要更有意思,说不定还会成为R2或V4封神的奠基石!
前言
随着大语言模型(LLMs)推理能力的飞跃发展,数学问题求解成为其研究重点之一。
然而,自然语言推理与形式定理证明之间仍存在结构性鸿沟。自然语言中的推理更偏向启发式、经验性、片段化,难以直接映射到形式证明系统如 Lean、Coq 等所要求的严密逻辑流程。
因此,如何将语言模型的非正式思维迁移到可验证的数学证明结构,是当前自动定理证明研究的关键挑战。
为此,DeepSeek-Prover-V2提出了一套从自然语言出发,经由子目标分解,最终构建形式证明的完整训练与推理流程。
DeepSeek-Prover-V2 的核心架构包含两个关键模型:
- DeepSeek-V3:用于自然语言推理与子目标生成(proof sketch + subgoals)。
- Prover-7B / 671B:用于形式化子目标求解与最终证明生成。
核心思想是在 DeepSeek-V3 的高阶自然语言建模能力基础上,生成可编译至 Lean 4 的中间步骤(subgoals),再由优化后的 7B 模型递归求解每一步子命题,最终组合成完整的定理证明。

这一“先非正式再形式化”的过程被称为**“冷启动递归定理证明框架”**,
可能是标志着自动定理证明迈向结构层级更明确、更高效的路径。
方法详解
子目标驱动的递归定理证明
人类数学家常通过引入中间引理或子命题(lemma)来分解复杂定理的证明过程。
DeepSeek-Prover-V2 模拟这种人类策略,采用 DeepSeek-V3 生成自然语言的推理草图,并同步转译为 Lean 语言表示的子目标。
每个子目标以 Lean 的 have … := sorry 形式呈现,表示“当前推理到此,需要接下来的步骤来完成证明”。

接着,系统递归性地调用一个训练有素的轻量化 7B 模型,尝试解决每一个 sorry 所对应的子命题。此过程构建出一个基于子目标链的证明树。所有子目标被解出后,即可拼接为完整定理的形式化证明。
DeepSeek-Prover-V2 的核心技术管线依赖两个模型的协作:
一个负责将原始定理自然语言化和子目标分解(DeepSeek-V3),
另一个负责子目标的形式求解(7B Prover)。
这种设计的关键意义在于,它首次系统性实现了从自然语言推理链条(chain-of-thought, CoT)到 Lean 形式语言的端到端迁移,统一了自然与形式两个领域的建模流程。
冷启动数据构建与训练策略
传统基于正式语料的定理证明模型训练,常受限于数据稀疏性与奖励信号匮乏。
为此,该项目引入“冷启动训练”策略,
即从 DeepSeek-V3 所生成但无法一体求解的定理入手,
提取其已成功分解并解决的子目标序列,
将之拼合为新的全局形式证明,再附以推理草图,作为冷启动样本。
如此构建的高质量**“非正式-正式”**配对数据为模型提供了稠密而结构丰富的学习信号。
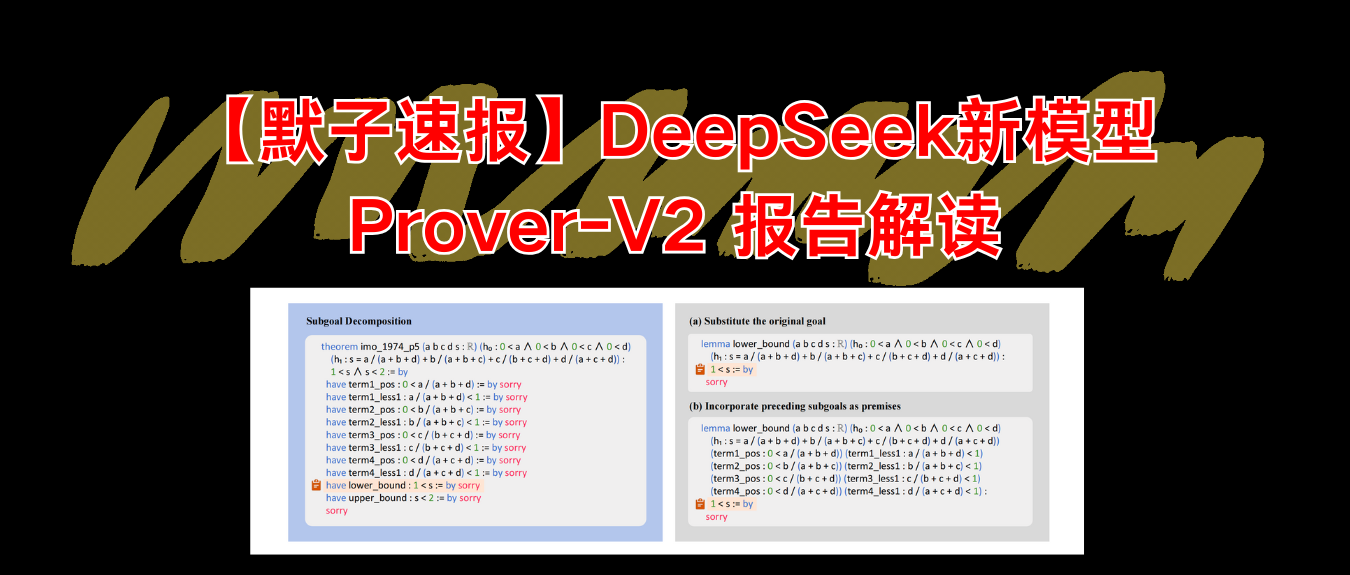
子目标课程学习
为增强训练效率与样本梯度控制,Deepseek设计了一个以子目标为核心的课程学习机制。
系统生成两种子目标:一种只替换原命题(图3左),另一种加入前置条件作为前提(图3右)。

这两种变体分别对应浅层与深层的证明任务,
并被动态安排到 expert iteration 训练周期中,从而实现由浅入深的学习进展。
这种课程学习机制类似于强化学习中的 curriculum RL,
并在架构上受到 AlphaProof 体系的启发,
目标是训练一个具备 IMO 级别推理能力的定理证明体。
强化学习与结构一致性奖励
最后还是采用 GRPO(Group Relative Policy Optimization)方法,
利用 Lean 验证反馈(通过/失败)作为二元奖励。
同时引入结构一致性惩罚,强制模型输出与子目标结构对齐,
提升复杂问题的推理稳定性与一致性。
实验评估与结果分析
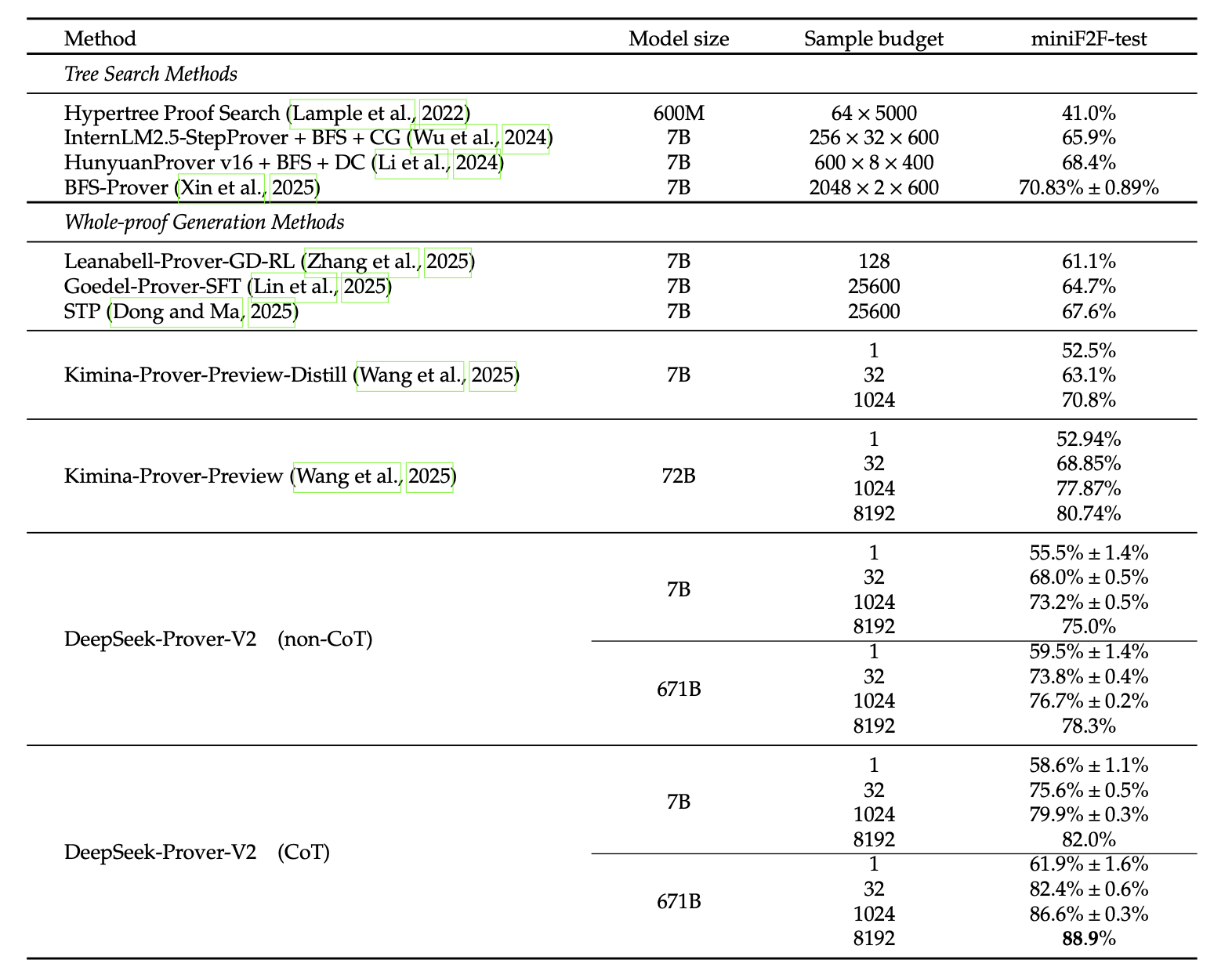
这波Deepseek可能是是真的爆杀!MiniF2F点准确率直接在过往模型基础上提高10个百分点!
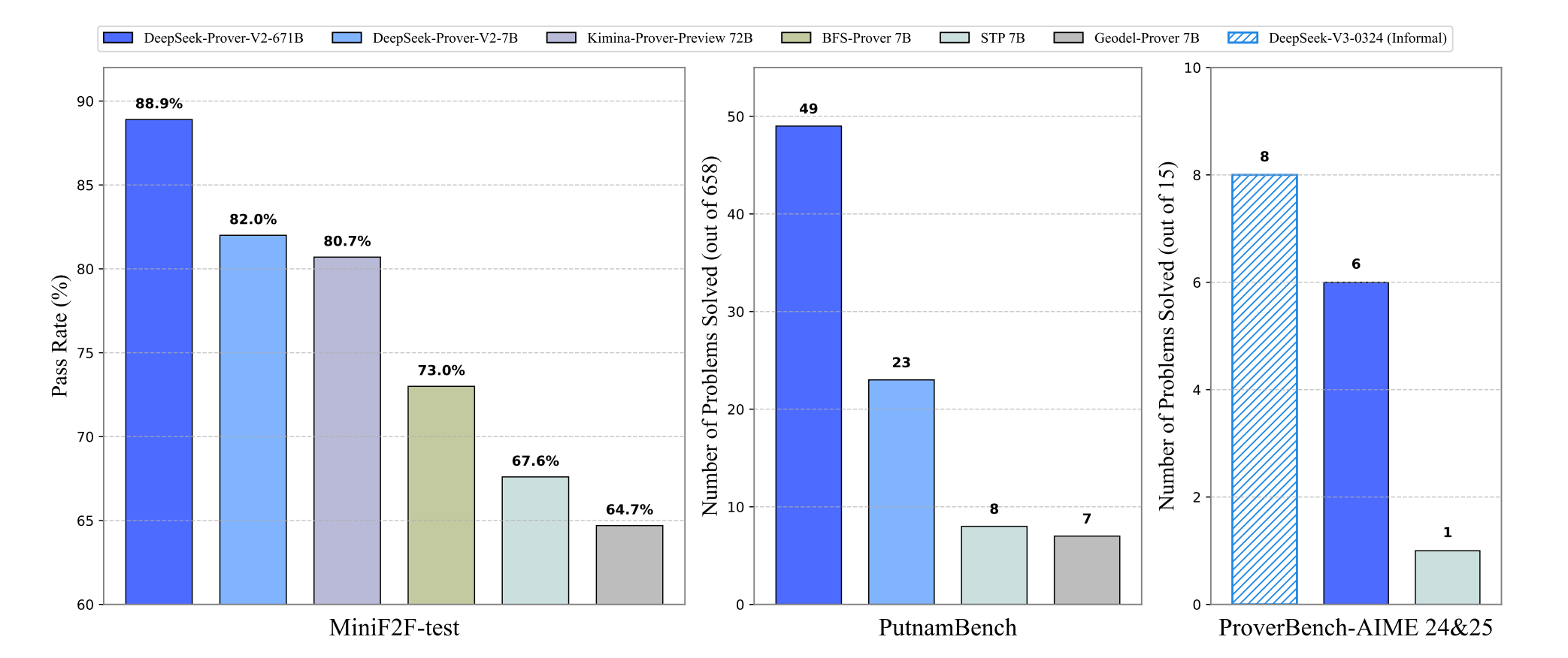
4.1 MiniF2F
- 671B(CoT):Pass@8192 = 88.9%,刷新当前 SOTA。
- 7B(CoT):Pass@8192 = 82.0%,优于所有开源小模型。
4.2 ProofNet(大学教材级)
- 671B(CoT):Pass@1024 = 37.1%
- 7B(non-CoT):为主力参与 curriculum 学习,表现稳定。
4.3 PutnamBench(本科竞赛题)
- 671B(CoT):49/658,较前作提升显著。
- 7B 解出 13 道 671B 未解题,展示独特 Lean 策略偏好。
4.4 CombiBench(组合数学)
- 671B(CoT):12/100
- 表明即便组合问题不是训练主干,模型也具迁移能力。
4.5 ProverBench(新构建)
- 含 325 道题,覆盖 AIME 竞赛题及教材内容。
- AIME 24-25:DeepSeek-V3(自然语言)解出 8/15;671B(形式证明)解出 6/15。
这种性能提升主要归因于 CoT prompting 策略:相比直接预测答案的 non-CoT 模式,带有中间推理步骤的 CoT 模式在模型理解与构造逻辑链方面更具优势。
# 新的基准
同时,为推进定理证明研究,Deepseek还构建了一个包含 325 道题目的新基准集 ProverBench。
该集合包含 15 道来自 AIME 24 和 25 届竞赛的精选题目,
以及 310 道来自高中教材与本科课程的题目。覆盖内容广泛,涵盖以下数学领域:
| 学科 | 题量 |
|---|---|
| 数论 | 40 |
| 初等代数 | 30 |
| 线性代数 | 50 |
| 抽象代数 | 40 |
| 微积分 | 90 |
| 实分析 | 30 |
| 复分析 | 10 |
| 泛函分析 | 10 |
| 概率论 | 10 |
在 AIME 问题上,DeepSeek-V3 模型以自然语言模式解决 8/15,
而 DeepSeek-Prover-V2-671B 能在提供正确答案的条件下构造出 6/15 的完整形式证明。
这一结果表明,自然语言推理与形式化建模之间的性能差距正逐步缩小。
结论与未来展望
DeepSeek-Prover-V2 构建了一条完整的“语言-子目标-形式化-验证”链路,
突破了 LLM 只擅长自然语言推理的限制,将其能力扩展到了 Lean 这类严格验证系统。
通过冷启动数据与子目标课程学习的结合,模型实现了在多种数学场景下的泛化能力突破。
更为重要的是,默子认为该系统可能只是 DeepSeek 更大布局中的一步。
在 DeepSeek-V3 已具备自然语言数学推理能力的基础上,V2 的形式化能力构建很可能是为 DeepSeek R2 或 V4 引入更强数学引擎的铺垫。
这预示着未来的通用大模型将在形式语言处理、结构推理、严密验证等高层任务上具备更强竞争力。
最终目标直指国际数学奥林匹克(IMO)级别的数学难题求解与验证系统,一个真正意义上的“类人”形式化数学助手。
第一时间解读,难免会有纰漏,欢迎各位大佬批评指正!
默子要早睡去啦,大家也晚安!
五一快乐!
关注默子,带你天天AI早睡