每日一题——字符串的排列
字符串的排列
- 题目
- 输入描述
- 输出描述
- 示例
- 题解
- 思路
- 代码实现
- 代码解释
- 时间复杂度和空间复杂度
- 讨论
题目
给定一个字符串,打印出该字符串中字符的所有排列。可以以任意顺序返回这些排列结果。
输入描述
输入一个字符串,长度不超过10,字符只包括大小写字母。
输出描述
返回该字符串的所有排列。
示例
示例 1
输入:
"ab"
输出:
["ab", "ba"]
返回 ["ba", "ab"] 也是正确的。
示例 2
输入:
"aab"
输出:
["aab", "aba", "baa"]
示例 3
输入:
"abc"
输出:
["abc", "acb", "bac", "bca", "cab", "cba"]
示例 4
输入:
""
输出:
[""]
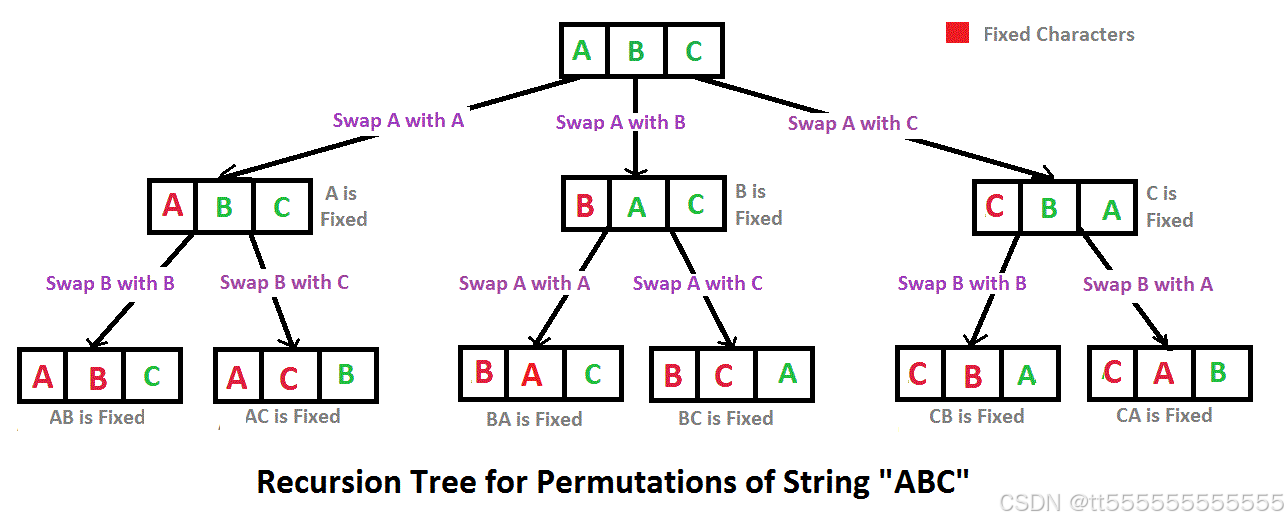
题解
思路
我们需要找到字符串的所有排列,并且排列中每个字符的顺序必须是唯一的。为了解决这个问题,我们可以使用回溯算法来生成所有的排列。
-
排序: 首先对字符串进行排序,这样可以方便地避免重复排列。例如,如果输入字符串是
"aab",通过排序可以得到"aab",这将有助于在后续生成排列时,能够识别并跳过重复的排列。 -
回溯算法: 我们通过递归和回溯来生成排列。每次从剩下的字符中选择一个,放入当前的排列中,递归直到排列完成。使用一个标记数组
used[]来记录哪些字符已经被使用过。 -
剪枝: 当字符重复且还未被使用时,我们需要跳过这个字符,以避免生成重复的排列。
代码实现
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdbool.h>
// 排序函数:使用冒泡排序对字符数组进行排序
void sort(char* num, int numLen) {
// 外层循环控制排序的轮数
for (int i = 0; i < numLen - 1; i++) {
// 内层循环进行相邻元素的比较和交换
for (int j = 0; j < numLen - i - 1; j++) {
// 如果当前元素大于下一个元素,则交换它们
if (num[j] > num[j + 1]) {
char temp = num[j];
num[j] = num[j + 1];
num[j + 1] = temp;
}
}
}
}
// 回溯函数:生成字符串的所有全排列
void backtrack(char* num, int len, char** result, int* returnSize,
int* returnColumnSizes, char* path, int pathLen, bool* used) {
// 如果当前排列的长度等于字符串的长度,说明一个排列已生成
if (pathLen == len) {
// 为当前排列分配内存
result[*returnSize] = (char*)malloc(sizeof(char) * (len + 1));
// 将当前排列复制到结果数组中
for (int i = 0; i < len; i++) {
result[*returnSize][i] = path[i];
}
result[*returnSize][len] = '\0'; // 添加字符串终止符
// 设置当前排列的列大小
returnColumnSizes[*returnSize] = len;
// 增加已生成排列的数量
(*returnSize)++;
return;
}
// 遍历每个字符,尝试放入当前排列中
for (int i = 0; i < len; i++) {
// 如果该元素已经被使用过,或者它是重复字符且前一个字符未被使用
if (used[i] || (i > 0 && used[i - 1] == 0 && num[i] == num[i - 1])) {
continue; // 跳过当前字符
}
// 标记该元素已使用
used[i] = 1;
// 将该字符加入当前排列
path[pathLen] = num[i];
// 递归调用,继续选择下一个字符
backtrack(num, len, result, returnSize, returnColumnSizes, path, pathLen + 1, used);
// 回溯,撤销选择
used[i] = 0;
}
}
// 主函数:返回字符串的所有排列
char** Permutation(char* str, int* returnSize) {
// 获取字符串的长度
int len = strlen(str);
// 对字符串进行排序,确保重复字符相邻
sort(str, len);
// 为结果分配内存,预分配足够大的空间
char** result = (char**)malloc(sizeof(char*) * 1000000);
int* returnColumnSizes = (int*)malloc(sizeof(int) * 1000000);
*returnSize = 0; // 初始化返回结果的大小为0
// 用于保存当前排列的路径
char* path = (char*)malloc(sizeof(char) * len);
// 用于标记哪些字符已经被使用
bool* used = (bool*)calloc(len, sizeof(bool));
// 调用回溯函数生成排列
backtrack(str, len, result, returnSize, returnColumnSizes, path, 0, used);
// 释放临时内存
free(path);
free(used);
return result;
}
代码解释
-
sort()函数: 用于对输入字符串进行排序。排序后的字符串可以确保我们在生成排列时跳过重复字符。
-
backtrack()函数: 这是回溯的核心函数。它通过递归生成所有的排列。
- 每次选择一个未被使用的字符,并将其加入当前排列中。
- 当排列长度达到字符串长度时,将当前排列加入结果中。
- 使用
used[]数组来避免重复字符的选择。
-
Permutation()函数: 这是主函数,负责初始化必要的变量,调用回溯函数,并返回结果。
时间复杂度和空间复杂度
- 时间复杂度: 生成所有排列的时间复杂度为
O
(
n
!
)
O(n!)
O(n!),因为对于长度为
n的字符串,排列总数为n!。 - 空间复杂度: 需要存储所有的排列结果,所以空间复杂度为 O ( n ! ) O(n!) O(n!)。
讨论
这个问题的关键在于回溯算法的应用,同时需要注意剪枝策略来避免生成重复的排列。通过对字符串进行排序和合理的剪枝,能够有效地减少不必要的计算。另外,数组大小设置为1000000,我觉得有点恐怖,其实很正常,因为给的案例最长9个字符。9!=362880,所以内存设置为一百万才能满足要求。整体难度和之前差不多,主要还是改成字符串格式是,另外最后要补充’\0’。