spark和Hadoop之间的对比与联系
Spark和Hadoop是两个广泛应用于大数据处理领域的开源框架,它们在设计理念、性能特点、适用场景以及功能上都有显著的联系和区别。
1. 联系:
- 共同目标:两者都旨在处理大规模数据,支持分布式计算,并且可以运行在集群环境中。
- 协同工作:Spark可以运行在Hadoop的生态系统中,利用Hadoop的分布式文件系统(HDFS)进行数据存储,并通过YARN进行资源调度。
- 兼容性:Spark可以作为Hadoop的一个组件集成到Hadoop集群中,从而扩展Hadoop的功能。
Hadoop Vs Apache Spark PowerPoint Prese… collidu.com
2. 区别:
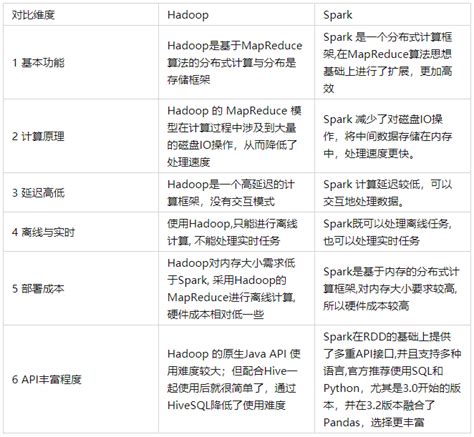
- 设计理念:
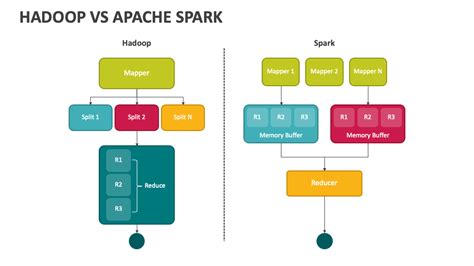
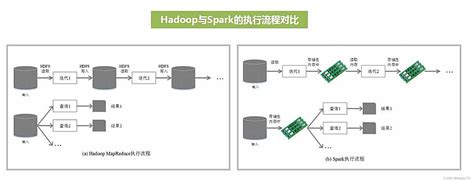
- Hadoop基于磁盘存储,采用批处理模型,强调高容错性和低成本。
- Spark基于内存计算,支持迭代式计算和实时处理,性能更快。
Spark(23)-Spark设计及Spark基本运行原理简介以及与Hadoop的对比_spark23-CSDN博客
- 性能差异:
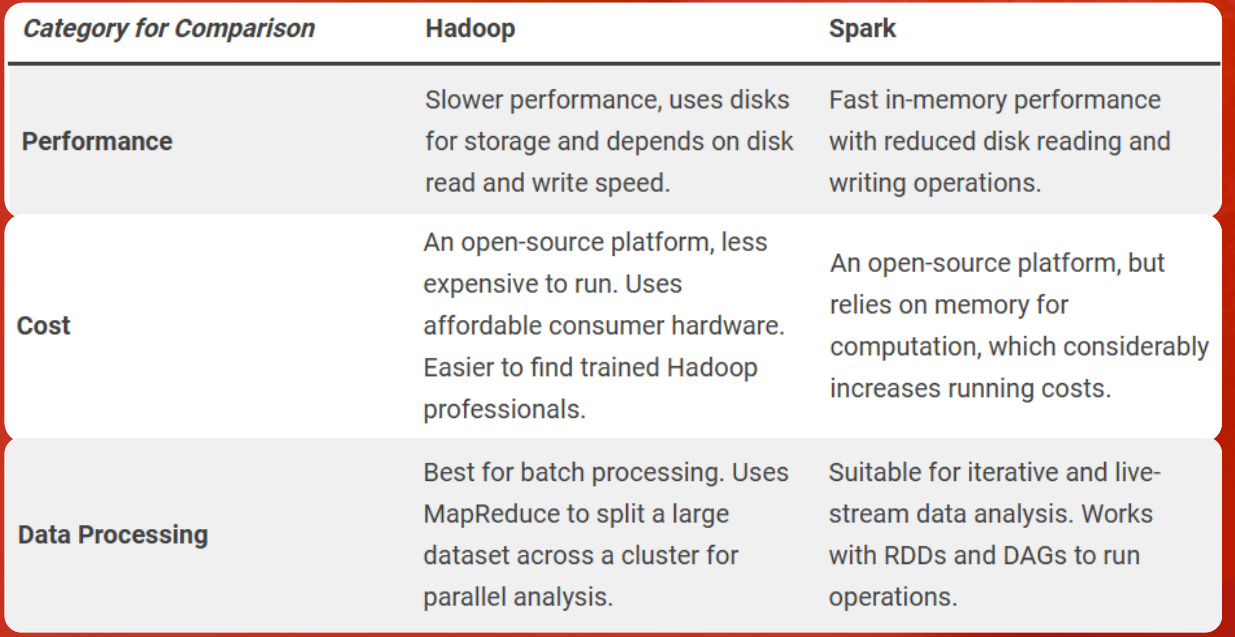
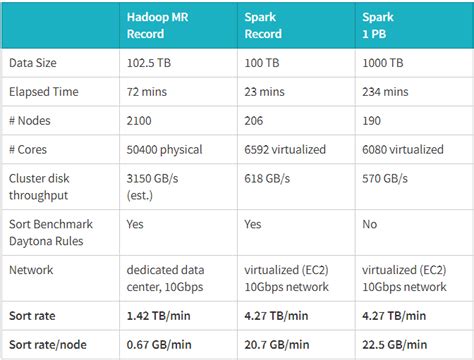
- Hadoop依赖磁盘I/O操作,适合批处理任务,但速度较慢。
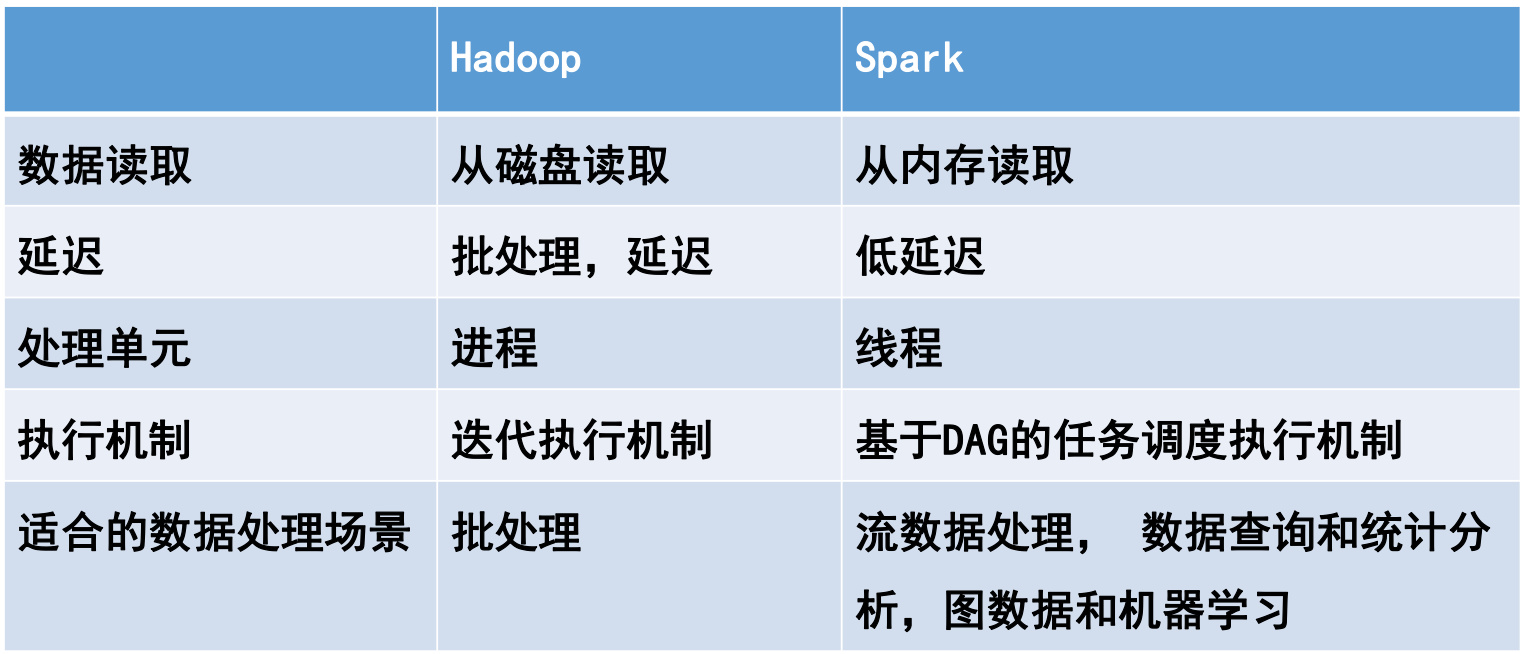
- Spark将中间结果存储在内存中,减少了磁盘I/O操作,因此在迭代计算和实时处理方面表现更优。
- Hadoop依赖磁盘I/O操作,适合批处理任务,但速度较慢。
Spark与Hadoop对比 | geosmart.io
- 编程模型:
- Hadoop主要使用MapReduce编程模型,任务分为Map和Reduce两个阶段,完成后结束。
- Spark采用RDD(弹性分布式数据集)和DataFrame等高级抽象,支持更灵活的计算模型,如批处理、流处理、机器学习和图计算。
Hadoop和大数据、S… bilibili.com
- 适用场景:
- Hadoop更适合需要高容错性和低成本的批处理任务,例如离线数据分析和ETL(提取、转换、加载)。
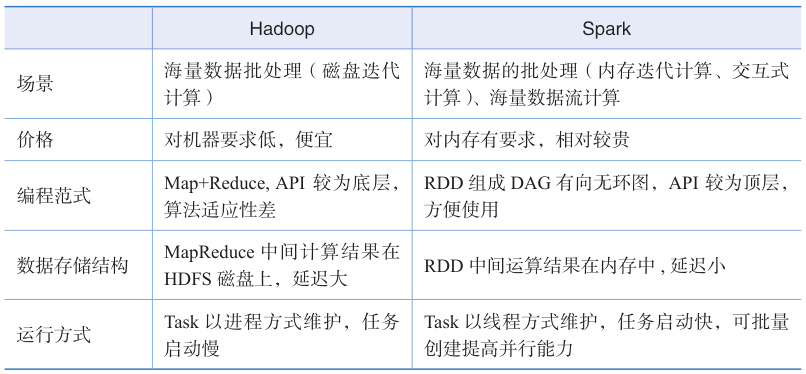
- Spark则更适合需要快速迭代和实时处理的场景,如机器学习、流数据分析和交互式查询。
- Hadoop更适合需要高容错性和低成本的批处理任务,例如离线数据分析和ETL(提取、转换、加载)。

大数据hadoop和spark怎么选择?_大数据spar…
- 容错机制:
- Hadoop通过HDFS的复制机制实现容错。
- Spark通过RDD的血统链(Lineage)和Checkpoint机制保证容错性。
深入浅出Spark(1)什么是Spark - 知乎
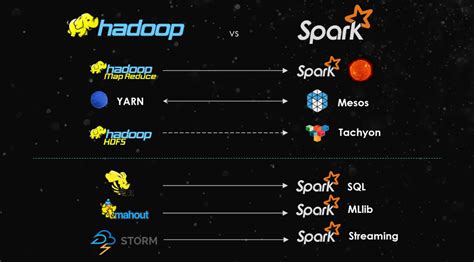
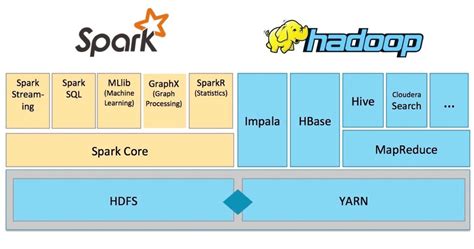
- 生态系统:
- Hadoop拥有丰富的生态系统,包括HDFS、YARN、MapReduce、Hive、Pig等工具。
- Spark也有自己的生态系统,包括Spark SQL、Spark Streaming、MLlib、GraphX等工具。
Spark 和 Hadoop 的区别有哪些? - 知乎
3. 总结:
- 优势互补:Hadoop适合批处理和离线数据存储,而Spark更适合实时处理和迭代计算。因此,在实际应用中,两者往往结合使用,以发挥各自的优势。
- 成本与效率:Hadoop的成本较低,但速度较慢;Spark的速度更快,但对内存要求较高。
- 灵活性与易用性:Spark提供了更丰富的API和更灵活的数据处理方式,适合复杂的数据分析任务。

Hadoop vs Spark: A Comparative Study| Data Science Certifications
综上,Spark和Hadoop虽然在某些方面存在竞争关系,但它们在大数据处理领域中各有优势,并且可以通过协同工作形成强大的解决方案。选择哪一个框架取决于具体的应用场景和需求。