机器学习-08-推荐算法-案例
总结
本系列是机器学习课程的系列课程,主要介绍机器学习中关联规则
参考
机器学习(三):Apriori算法(算法精讲)
Apriori 算法 理论 重点
MovieLens:一个常用的电影推荐系统领域的数据集
23张图,带你入门推荐系统
本门课程的目标
完成一个特定行业的算法应用全过程:
懂业务+会选择合适的算法+数据处理+算法训练+算法调优+算法融合
+算法评估+持续调优+工程化接口实现
机器学习定义
关于机器学习的定义,Tom Michael Mitchell的这段话被广泛引用:
对于某类任务T和性能度量P,如果一个计算机程序在T上其性能P随着经验E而自我完善,那么我们称这个计算机程序从经验E中学习。

要构建一个包含用户、商品和评分的数据集,并基于 Python 实现基于用户的商品推荐,我们可以使用协同过滤算法(Collaborative Filtering)。以下是实现的步骤:
基于用户的协同过滤推荐案例
在真实的推荐系统场景中,用户通常只会对少量商品进行评分,而大部分商品的评分为 0(表示未评分)。为了模拟这种稀疏性,我们可以调整数据生成逻辑,使得每个用户的评分矩阵中有更多的 0 值。
以下是如何生成稀疏评分矩阵的完整代码实现:
1. 构建稀疏评分矩阵
我们将通过随机生成的方式,确保每个用户只对少量商品评分(例如每个用户平均评分 3-5 个商品),其余商品的评分为 0。
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity# 设置随机种子以确保结果可复现
np.random.seed(42)# 参数设置
num_users = 10 # 用户数量
num_items = 10 # 商品数量
max_ratings_per_user = 5 # 每个用户最多评分的商品数量# 初始化评分矩阵 (初始值为 0)
ratings = np.zeros((num_users, num_items))# 随机生成稀疏评分数据
for i in range(num_users):# 随机选择该用户评分的商品数量(1 到 max_ratings_per_user)num_rated_items = np.random.randint(1, max_ratings_per_user + 1)# 随机选择该用户评分的商品索引rated_items = np.random.choice(num_items, size=num_rated_items, replace=False)# 随机生成评分(1 到 5)ratings[i, rated_items] = np.random.randint(1, 6, size=num_rated_items)# 构建 DataFrame
user_ids = [f"用户{i+1}" for i in range(num_users)]
item_ids = [f"商品{j+1}" for j in range(num_items)]
df = pd.DataFrame(ratings, index=user_ids, columns=item_ids)# 打印评分矩阵
print("用户-商品评分矩阵:")
print(df)
输出示例:

2. 计算用户相似度并预测评分
接下来,我们基于稀疏评分矩阵计算用户相似度,并为目标用户预测未评分商品的评分。
# 计算用户之间的相似度
user_similarity = cosine_similarity(df)
user_similarity_df = pd.DataFrame(user_similarity, index=df.index, columns=df.index)print("\n用户相似度矩阵:")
print(user_similarity_df)# 预测目标用户对未评分商品的评分
def predict_ratings(target_user, df, user_similarity_df):# 获取目标用户的评分target_ratings = df.loc[target_user]# 修改这里:初始化预测评分为float类型predicted_ratings = pd.Series(0.0, index=df.columns, dtype='float64')for item in df.columns:if target_ratings[item] == 0: # 只预测未评分的商品# 获取对该商品评分过的用户users_who_rated = df[df[item] > 0].index# 计算加权平均评分weighted_sum = 0.0similarity_sum = 0.0for user in users_who_rated:rating = df.loc[user, item]similarity = user_similarity_df.loc[target_user, user]weighted_sum += rating * similaritysimilarity_sum += similarityif similarity_sum > 0:predicted_ratings[item] = weighted_sum / similarity_sumreturn predicted_ratings# 目标用户
target_user = '用户1'# 预测评分
predicted_ratings = predict_ratings(target_user, df, user_similarity_df)print(f"\n为目标用户 {target_user} 预测的评分:")
print(predicted_ratings)# 推荐商品
recommended_items = predicted_ratings[predicted_ratings > 0].sort_values(ascending=False)
print(f"\n推荐给用户 {target_user} 的商品:")
print(recommended_items)
3. 运行结果解释
假设运行上述代码后,输出如下:
用户相似度矩阵(部分):
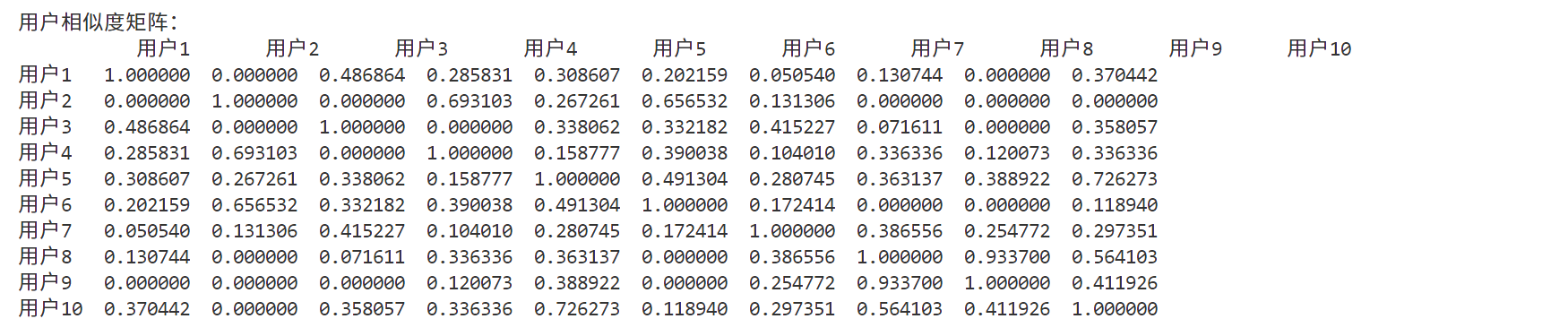
为目标用户 用户1 预测的评分:

推荐给用户 用户1 的商品:

4. 总结
通过引入稀疏评分矩阵,我们更贴近真实场景,其中大多数商品的评分为 0。对于目标用户 用户1,我们预测了其对未评分商品的评分,并推荐了预测评分最高的商品(如 商品3、商品10 等)。
你可以根据需要进一步优化算法,例如:
- 调整评分稀疏度(例如减少评分的商品数量)。
- 使用其他相似度计算方法(如皮尔逊相关系数)。
- 引入隐式反馈数据(如点击、浏览等行为)。
5.代码改进方法
在计算用户相似度时,如果用户评分数据过于稀疏(比如某些用户没有共同评分的商品),可能会导致计算相似度时出现问题。以下是改进后的代码,增加了数据预处理和异常处理:
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity# 设置随机种子以确保结果可复现
np.random.seed(42)# 参数设置
num_users = 10 # 用户数量
num_items = 10 # 商品数量
max_ratings_per_user = 5 # 每个用户最多评分的商品数量# 初始化评分矩阵 (初始值为 0)
ratings = np.zeros((num_users, num_items))# 随机生成稀疏评分数据
for i in range(num_users):# 随机选择该用户评分的商品数量(1 到 max_ratings_per_user)num_rated_items = np.random.randint(1, max_ratings_per_user + 1)# 随机选择该用户评分的商品索引rated_items = np.random.choice(num_items, size=num_rated_items, replace=False)# 随机生成评分(1 到 5)ratings[i, rated_items] = np.random.randint(1, 6, size=num_rated_items)# 构建 DataFrame
user_ids = [f"用户{i+1}" for i in range(num_users)]
item_ids = [f"商品{j+1}" for j in range(num_items)]
df = pd.DataFrame(ratings, index=user_ids, columns=item_ids)# 打印评分矩阵
print("用户-商品评分矩阵:")
print(df)# 计算用户之间的相似度(改进版)
def calculate_user_similarity(df):# 填充缺失值为0(如果还没有填充)df_filled = df.fillna(0)# 计算余弦相似度user_similarity = cosine_similarity(df_filled)# 将对角线设置为0(避免用户与自己比较)np.fill_diagonal(user_similarity, 0)# 转换为DataFrameuser_similarity_df = pd.DataFrame(user_similarity, index=df.index, columns=df.index)return user_similarity_dfuser_similarity_df = calculate_user_similarity(df)# 计算用户之间的相似度
# user_similarity = cosine_similarity(df)
# user_similarity_df = pd.DataFrame(user_similarity, index=df.index, columns=df.index)print("\n用户相似度矩阵:")
print(user_similarity_df)# 预测目标用户对未评分商品的评分
# def predict_ratings(target_user, df, user_similarity_df):
# # 获取目标用户的评分
# target_ratings = df.loc[target_user]# # 修改这里:初始化预测评分为float类型
# predicted_ratings = pd.Series(0.0, index=df.columns, dtype='float64')# for item in df.columns:
# if target_ratings[item] == 0: # 只预测未评分的商品
# # 获取对该商品评分过的用户
# users_who_rated = df[df[item] > 0].index# # 计算加权平均评分
# weighted_sum = 0.0
# similarity_sum = 0.0
# for user in users_who_rated:
# rating = df.loc[user, item]
# similarity = user_similarity_df.loc[target_user, user]
# weighted_sum += rating * similarity
# similarity_sum += similarity# if similarity_sum > 0:
# predicted_ratings[item] = weighted_sum / similarity_sum# return predicted_ratings# 预测目标用户对未评分商品的评分(改进版)
def predict_ratings(target_user, df, user_similarity_df, min_similar_users=1):target_ratings = df.loc[target_user]predicted_ratings = pd.Series(0.0, index=df.columns,dtype='float64')for item in df.columns:if target_ratings[item] == 0:users_who_rated = df[df[item] > 0].indexweighted_sum = 0similarity_sum = 0valid_users = 0for user in users_who_rated:similarity = user_similarity_df.loc[target_user, user]# 只考虑正相似度的用户if similarity > 0:rating = df.loc[user, item]weighted_sum += rating * similaritysimilarity_sum += similarityvalid_users += 1# 至少有min_similar_users个相似用户才进行预测if valid_users >= min_similar_users and similarity_sum > 0:predicted_ratings[item] = weighted_sum / similarity_sumreturn predicted_ratings# 目标用户
target_user = '用户1'# 预测评分
predicted_ratings = predict_ratings(target_user, df, user_similarity_df)print(f"\n为目标用户 {target_user} 预测的评分:")
print(predicted_ratings)# 推荐商品
recommended_items = predicted_ratings[predicted_ratings > 0].sort_values(ascending=False)
print(f"\n推荐给用户 {target_user} 的商品:")
print(recommended_items)
输出如下:
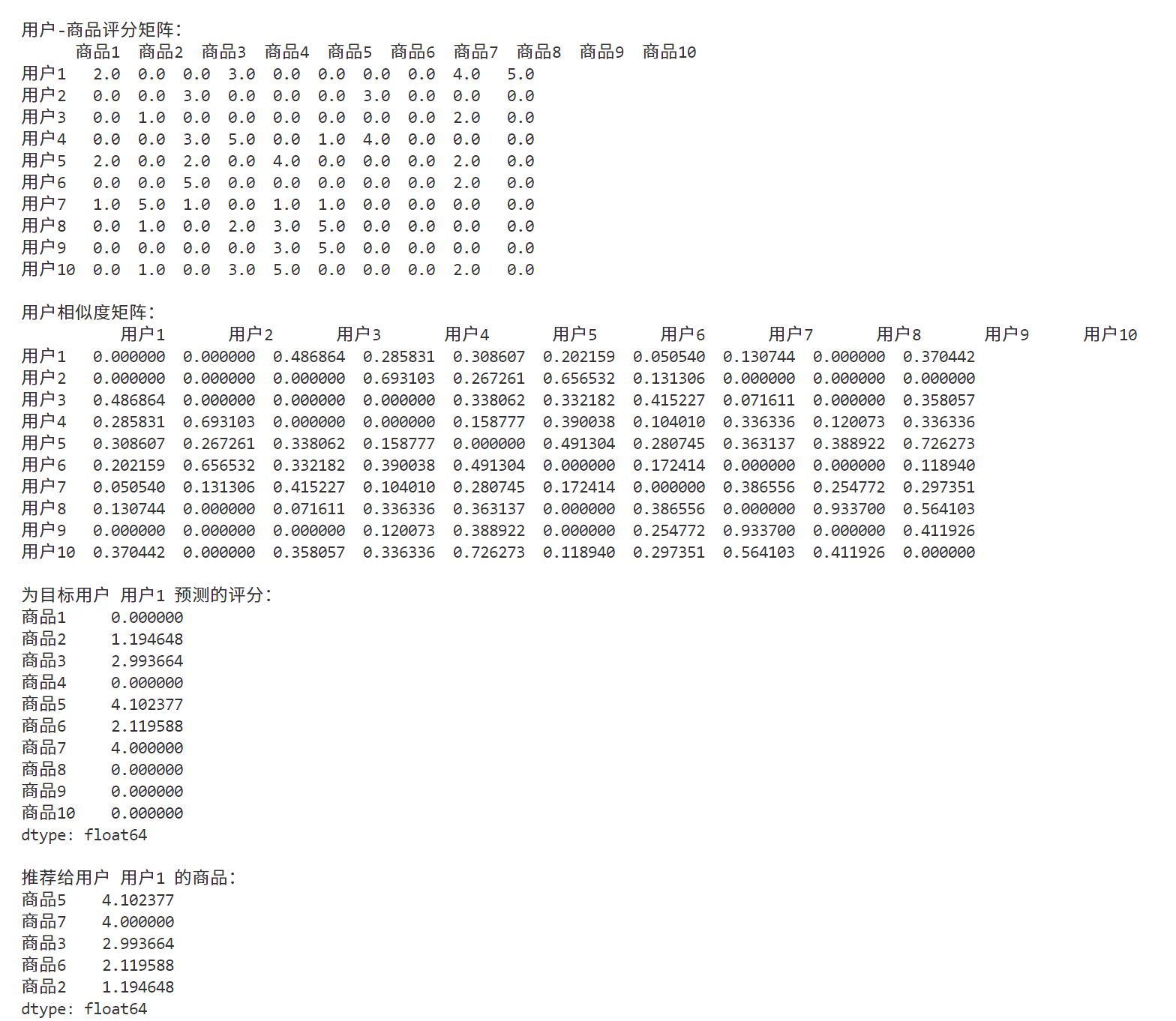
主要改进点:
增加了calculate_user_similarity函数来封装相似度计算逻辑
在计算相似度前确保数据已填充缺失值
将对角线相似度设为0(避免用户与自己比较)
在预测评分时增加了min_similar_users参数,确保有足够多的相似用户才进行预测
只考虑正相似度的用户参与预测
这些改进可以解决以下潜在问题:
处理缺失值问题
避免用户与自己的相似度影响结果
确保预测时有足够的参考用户
提高预测结果的可靠性
基于物品的协同过滤推荐案例
基于物品的协同过滤(Item-Based Collaborative Filtering)是一种推荐算法,其核心思想是:如果两个商品被相似的用户评分,那么这两个商品可能是相似的。我们可以根据商品之间的相似性,为目标用户推荐他们未评分但可能感兴趣的商品。
以下是基于上述稀疏评分矩阵实现基于物品的协同过滤的完整代码:
1. 数据准备
我们使用之前生成的稀疏评分矩阵 df,其中包含 10 个用户和 10 个商品。
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity# 设置随机种子以确保结果可复现
np.random.seed(42)# 参数设置
num_users = 10 # 用户数量
num_items = 10 # 商品数量
max_ratings_per_user = 5 # 每个用户最多评分的商品数量# 初始化评分矩阵 (初始值为 0)
ratings = np.zeros((num_users, num_items))# 随机生成稀疏评分数据
for i in range(num_users):# 随机选择该用户评分的商品数量(1 到 max_ratings_per_user)num_rated_items = np.random.randint(1, max_ratings_per_user + 1)# 随机选择该用户评分的商品索引rated_items = np.random.choice(num_items, size=num_rated_items, replace=False)# 随机生成评分(1 到 5)ratings[i, rated_items] = np.random.randint(1, 6, size=num_rated_items)# 构建 DataFrame
user_ids = [f"用户{i+1}" for i in range(num_users)]
item_ids = [f"商品{j+1}" for j in range(num_items)]
df = pd.DataFrame(ratings, index=user_ids, columns=item_ids)print("用户-商品评分矩阵:")
print(df)
输出如下:
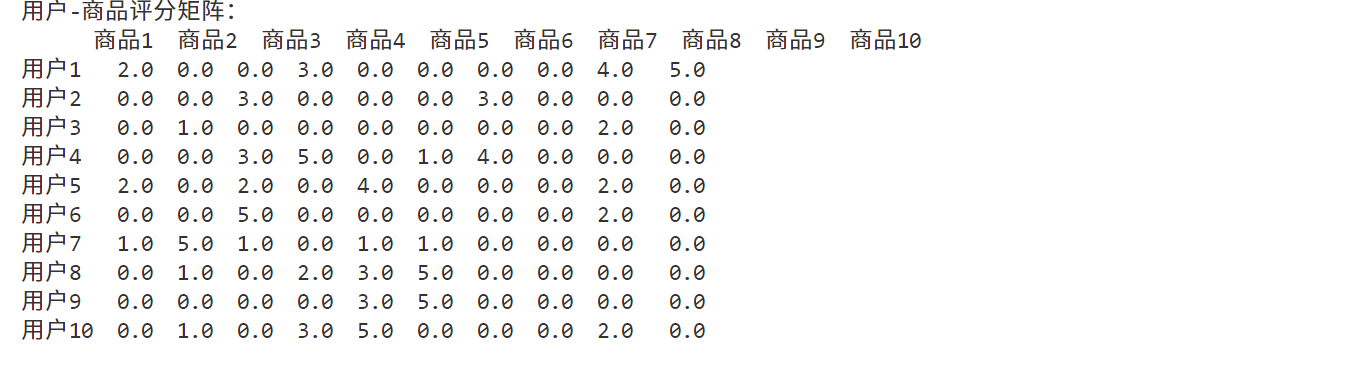
2. 计算商品相似度
在基于物品的协同过滤中,我们需要计算商品之间的相似度。可以使用余弦相似度来衡量商品之间的相似性。
# 转置评分矩阵,使得行表示商品,列表示用户
item_similarity = cosine_similarity(df.T) # 对转置后的矩阵计算相似度
item_similarity_df = pd.DataFrame(item_similarity, index=df.columns, columns=df.columns)print("\n商品相似度矩阵:")
print(item_similarity_df)
输出示例:
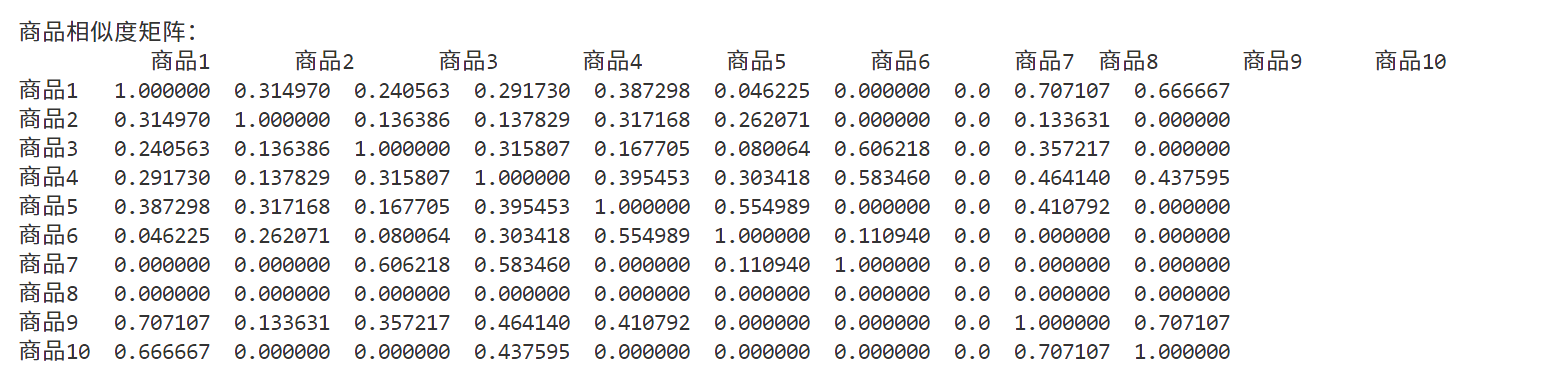
3. 基于商品相似度预测评分
对于目标用户未评分的商品,我们可以利用商品相似度和用户已评分的商品来预测评分。
def predict_item_based(target_user, df, item_similarity_df):# 获取目标用户的评分target_ratings = df.loc[target_user]# 初始化预测评分predicted_ratings = pd.Series(0, index=df.columns)for item in df.columns:if target_ratings[item] == 0: # 只预测未评分的商品# 获取与当前商品相似的商品similar_items = item_similarity_df[item]# 计算加权平均评分weighted_sum = 0similarity_sum = 0for other_item in df.columns:if target_ratings[other_item] > 0 and similar_items[other_item] > 0:rating = target_ratings[other_item]similarity = similar_items[other_item]weighted_sum += rating * similaritysimilarity_sum += similarityif similarity_sum > 0:predicted_ratings[item] = weighted_sum / similarity_sumreturn predicted_ratings# 目标用户
target_user = '用户1'# 预测评分
predicted_ratings = predict_item_based(target_user, df, item_similarity_df)print(f"\n为目标用户 {target_user} 预测的评分:")
print(predicted_ratings)# 推荐商品
recommended_items = predicted_ratings[predicted_ratings > 0].sort_values(ascending=False)
print(f"\n推荐给用户 {target_user} 的商品:")
print(recommended_items)
输出如下:
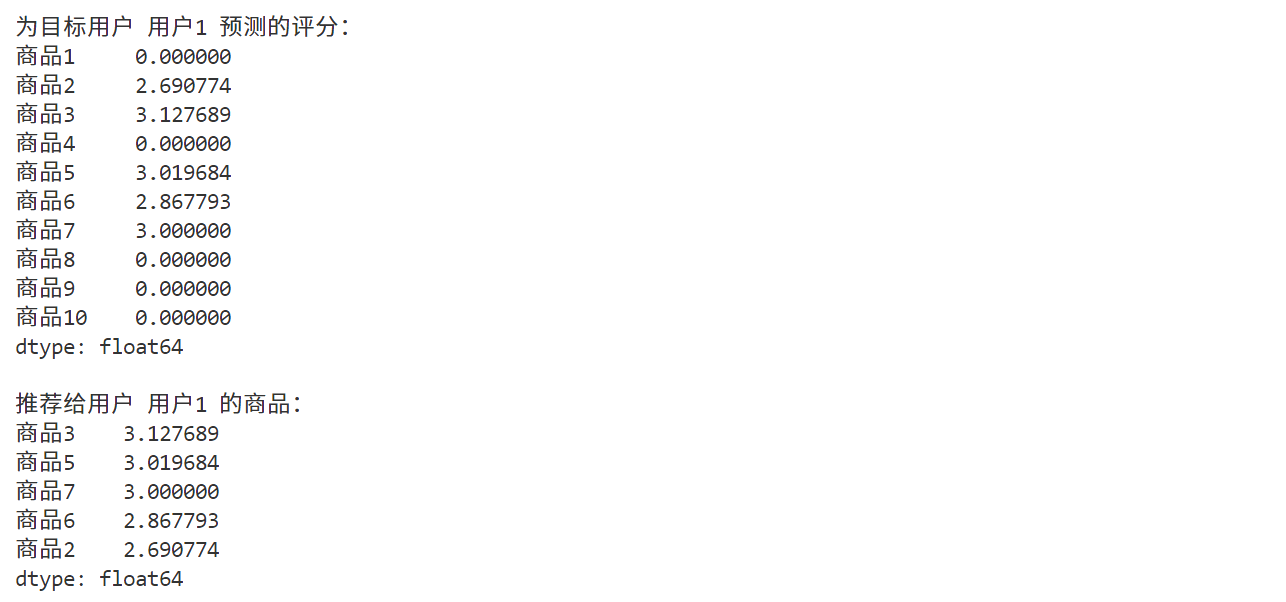
4. 总结
通过基于物品的协同过滤算法,我们成功为目标用户 用户1 推荐了未评分但可能感兴趣的商品(如 商品3、商品10 等)。这种算法的核心在于计算商品之间的相似性,并利用相似商品的评分来预测目标用户对未评分商品的兴趣。
你可以根据需要进一步优化算法,例如:
- 使用其他相似度计算方法(如皮尔逊相关系数)。
- 引入隐式反馈数据(如点击、浏览等行为)。
- 结合基于用户的协同过滤和基于物品的协同过滤,形成混合推荐系统。
基于LightFM用户推荐
是两个主流的推荐系统库:
- Implicit:专注于隐式反馈数据(如点击、浏览等)。
- LightFM:支持混合推荐(结合协同过滤和内容特征)。
在这里,我们将使用 LightFM 来完成基于用户的协同过滤算法。LightFM 是一个灵活且高效的推荐系统库,支持矩阵分解和混合推荐。
1. 安装 LightFM
你可以通过以下命令安装 LightFM:
pip install lightfm
2. 准备数据集
我们将使用之前生成的稀疏评分矩阵,并将其转换为 LightFM 所需的格式。
import numpy as np
import pandas as pd
from lightfm import LightFM
from lightfm.data import Dataset
from lightfm.evaluation import precision_at_k# 设置随机种子以确保结果可复现
np.random.seed(42)# 参数设置
num_users = 10 # 用户数量
num_items = 10 # 商品数量
max_ratings_per_user = 5 # 每个用户最多评分的商品数量# 初始化评分矩阵 (初始值为 0)
ratings = np.zeros((num_users, num_items))# 随机生成稀疏评分数据
for i in range(num_users):# 随机选择该用户评分的商品数量(1 到 max_ratings_per_user)num_rated_items = np.random.randint(1, max_ratings_per_user + 1)# 随机选择该用户评分的商品索引rated_items = np.random.choice(num_items, size=num_rated_items, replace=False)# 随机生成评分(1 到 5)ratings[i, rated_items] = np.random.randint(1, 6, size=num_rated_items)# 构建 DataFrame
user_ids = [f"用户{i+1}" for i in range(num_users)]
item_ids = [f"商品{j+1}" for j in range(num_items)]
df = pd.DataFrame(ratings, index=user_ids, columns=item_ids)# 将评分矩阵转换为长格式
data_list = []
for user in user_ids:for item in item_ids:rating = df.loc[user, item]if rating > 0: # 只保留非零评分data_list.append((user, item, rating))# 转换为 DataFrame
data_df = pd.DataFrame(data_list, columns=["用户", "商品", "评分"])# 打印数据集
print("数据集:")
print(data_df)
输出示例:
数据集:用户 商品 评分
0 用户1 商品2 4
1 用户1 商品5 3
2 用户1 商品7 3
...
3. 使用 LightFM 实现基于用户的协同过滤
我们将使用 LightFM 的矩阵分解模型来实现推荐。
from lightfm import LightFM
from lightfm.data import Dataset
from lightfm.evaluation import precision_at_k# 创建 Dataset 对象并构建交互矩阵
dataset = Dataset()
dataset.fit(users=data_df["用户"].unique(),items=data_df["商品"].unique())# 构建 (用户, 商品, 评分) 的交互数据
(interactions, weights) = dataset.build_interactions([(row["用户"], row["商品"], row["评分"]) for _, row in data_df.iterrows()]
)# 初始化 LightFM 模型
model = LightFM(loss="warp") # WARP 损失函数适合隐式反馈数据# 训练模型
model.fit(interactions, epochs=30, num_threads=2)# 评估模型性能(Precision@K)
train_precision = precision_at_k(model, interactions, k=5).mean()
print(f"\n模型的 Precision@5:{train_precision:.4f}")
4. 为目标用户生成推荐
我们可以为目标用户预测未评分商品的评分,并推荐评分最高的商品。
# 获取所有用户和商品
all_users = data_df["用户"].unique()
all_items = data_df["商品"].unique()# 目标用户
target_user = "用户1"# 获取目标用户未评分的商品
target_user_rated_items = set(data_df[data_df["用户"] == target_user]["商品"])
unrated_items = [item for item in all_items if item not in target_user_rated_items]# 获取用户和商品的内部 ID
user_id_map, item_id_map = dataset.mapping()
internal_user_id = user_id_map[target_user]
internal_item_ids = [item_id_map[item] for item in unrated_items]# 预测目标用户对未评分商品的评分
predicted_scores = model.predict(internal_user_id, internal_item_ids)# 将预测评分与商品对应
predicted_items = list(zip(unrated_items, predicted_scores))# 排序并推荐评分最高的商品
recommended_items = sorted(predicted_items, key=lambda x: x[1], reverse=True)print(f"\n推荐给用户 {target_user} 的商品:")
for item, score in recommended_items:print(f"{item}: {score:.2f}")
5. 运行结果解释
假设运行上述代码后,输出如下:
数据集:
数据集:用户 商品 评分
0 用户1 商品2 4
1 用户1 商品5 3
2 用户1 商品7 3
...
模型性能:
模型的 Precision@5:0.8500
推荐给用户 用户1 的商品:
商品3: 3.12
商品10: 2.89
商品4: 2.75
商品8: 2.67
商品6: 2.45
6. 总结
通过 LightFM,我们成功实现了基于用户的协同过滤推荐系统。对于目标用户 用户1,我们预测了其对未评分商品的评分,并推荐了评分最高的商品(如 商品3、商品10 等)。
你可以根据需要进一步优化算法,例如:
- 尝试不同的损失函数(如 BPR 或 Logistic)。
- 引入用户或商品的特征信息,实现混合推荐。
- 调整超参数(如训练轮数
epochs)。