大模型应用案例:主动提问式的 AI 面试官(接入 DeepSeek)
目录
核心逻辑
效果演示
技术选型
大模型应用开发框架:langchain-deepseek
UI 展示框架—streamlit
代码获取
后续改进想法
本文附带详细的视频讲解,欢迎小伙伴们来支持——
【代码宇宙017】大模型:主动提问式的 AI 面试官(接入 DeepSeek)_哔哩哔哩_bilibili
核心逻辑
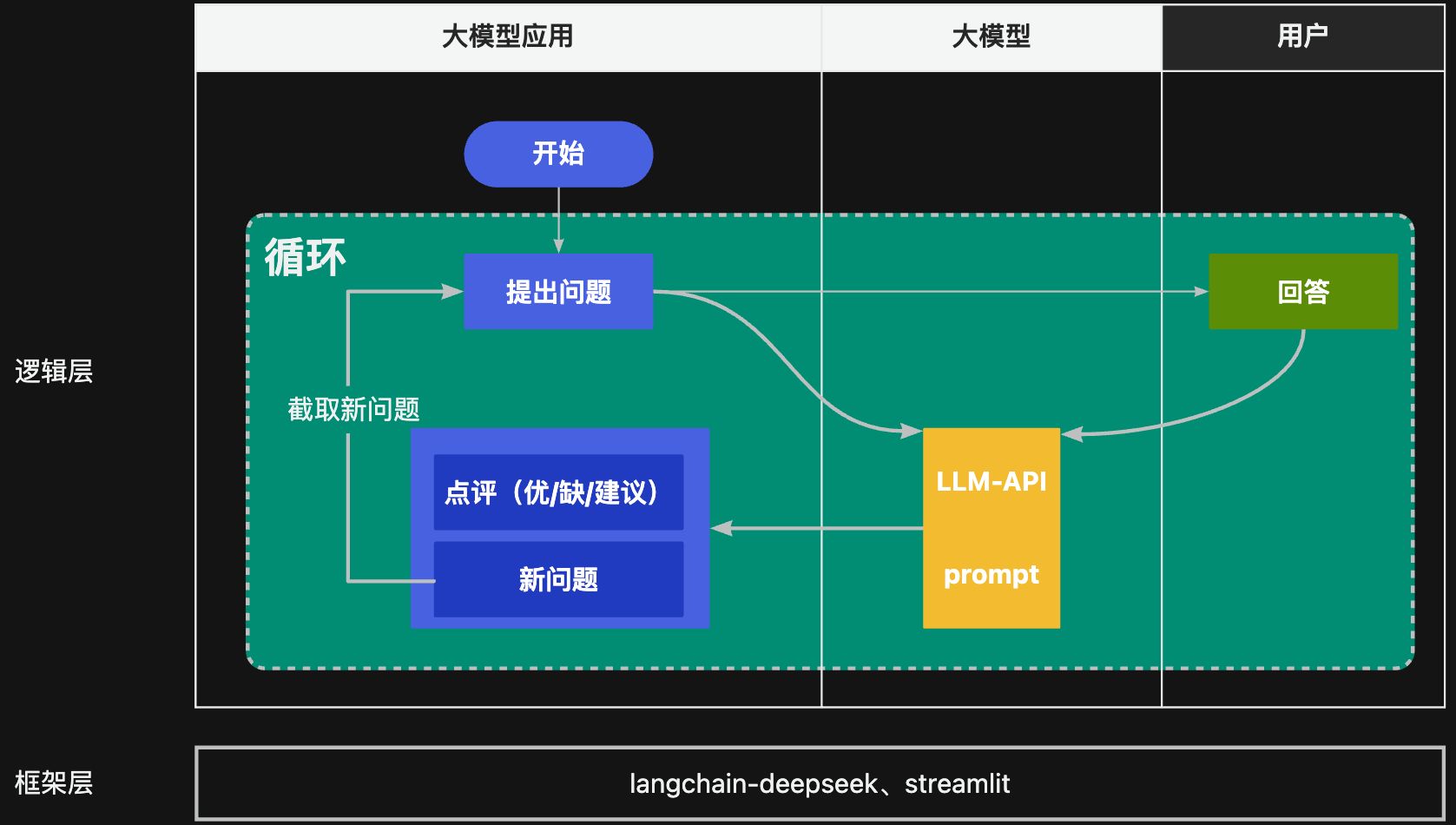
效果演示
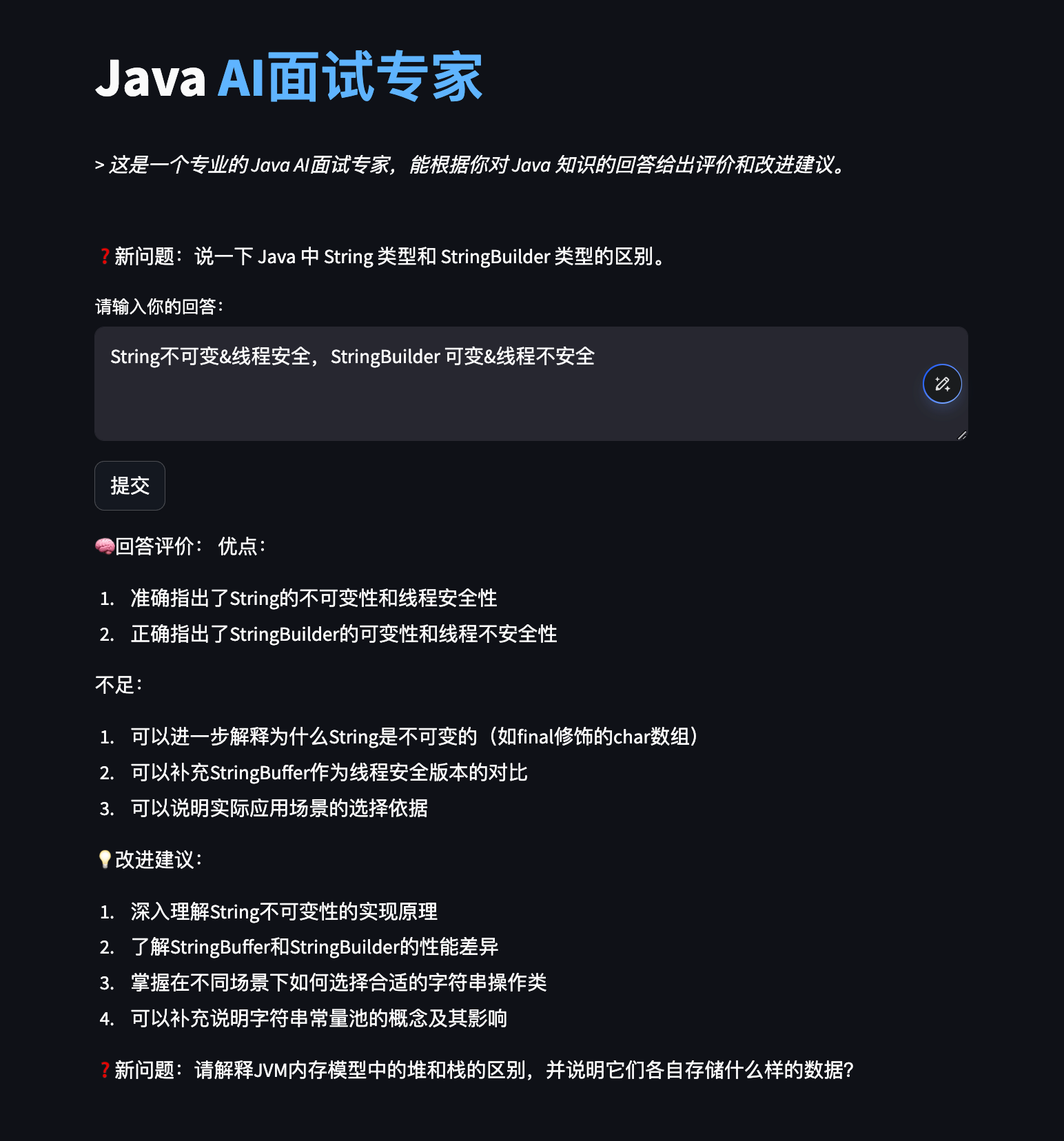
之后删除对话框内容,点击任意非输入框位置,即可展示新问题

技术选型
大模型应用开发框架:langchain-deepseek
LangChain 有许多聊天模型集成,允许您使用来自不同提供商的各种模型。
这些集成是以下两种类型之一:
- 官方模型:这些是 LangChain 和/或模型提供商官方支持的模型。你可以在
langchain-<provider>包中找到这些模型。 - 社区模型:有些模型主要由社区贡献和支持。您可以在
langchain-community包中找到这些模型。
LangChain 聊天模型的命名约定是在其类名前加上 “Chat” 前缀(例如,ChatOllama、ChatAnthropic、ChatOpenAI 等)。
LangChain 集成的大模型厂商清单
Chat models | 🦜️🔗 LangChain
ChatDeepSeek
ChatDeepSeek | 🦜️🔗 LangChain
依赖安装
pip install langchain-deepseek附加:LangChain 生态下的库安装
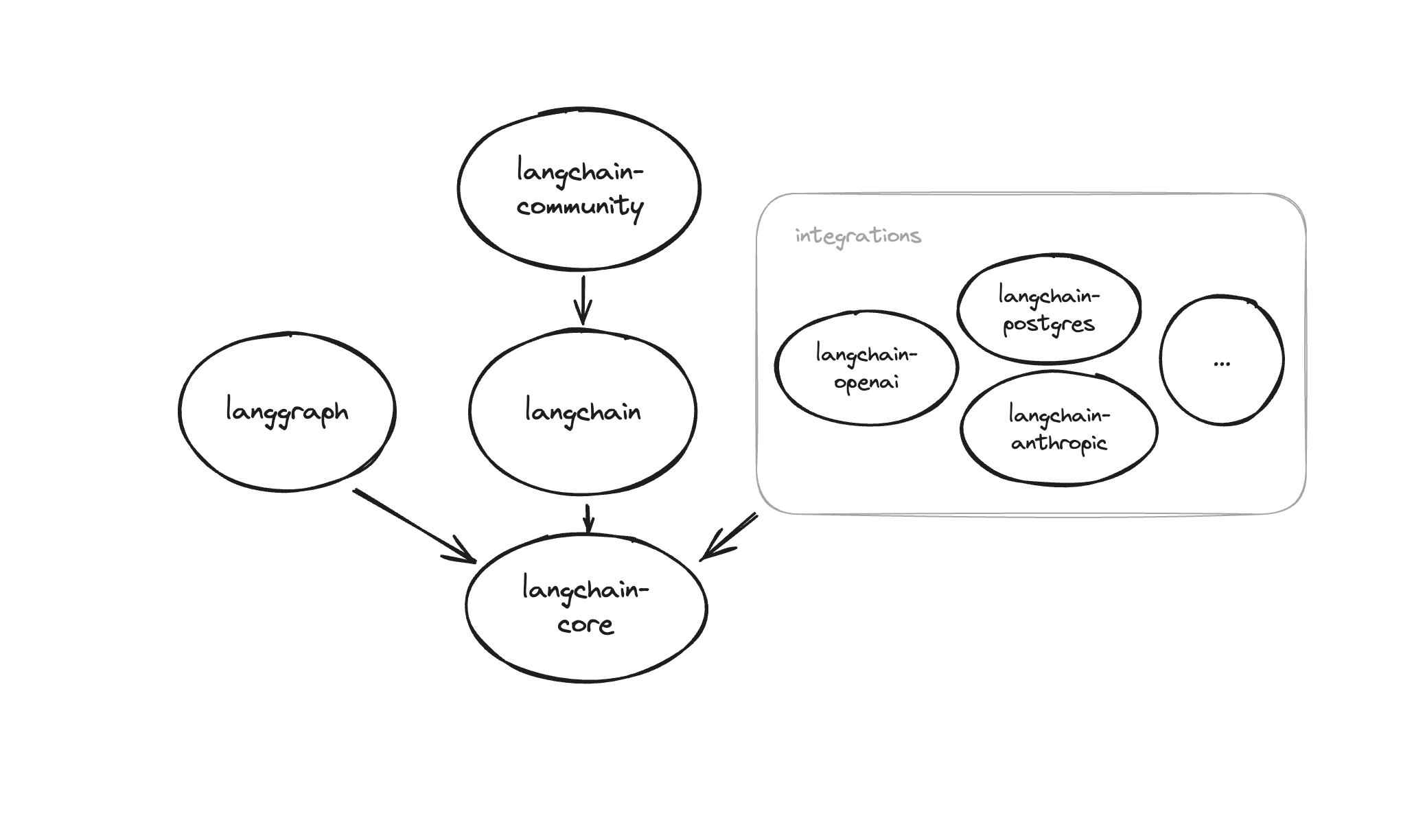
pip install langchain # 主 langchain 包pip install langchain-core # langchain-core 包包含 LangChain 生态系统其余部分使用的基本抽象,以及 LangChain 表达式语言。它由 langchain 自动安装,但也可以单独使用pip install langchain-openai # 某些集成(如 OpenAI 和 Anthropic)有自己的软件包pip install langchain-community # 任何尚未拆分到自己的包中的集成都将位于此包pip install langgraph # 是一个使用 LLM 构建有状态的多角色应用程序的库。它与 LangChain 无缝集成,但可以在没有 LangChain 的情况下使用pip install "langserve[all]" # 将 LangChain 可运行对象和链部署为 REST API,all 包含 client 和 serverpip install langchain-cli # LangChain CLI 可用于处理 LangChain 模板和其他 LangServe 项目pip install langsmith # 有助于代理评估和可观察性。调试性能不佳的 LLM 应用程序运行,评估代理轨迹,不依赖于langchain-core,如果需要,可以独立安装和使用pip install langchain-experimental # (选装)包含用于研究和实验用途的实验性 LangChain 代码UI 展示框架—streamlit
官网:API Reference - Streamlit Docs
Streamlit 是一款面向数据科学家和机器学习工程师的开源 Python 库,其设计目的是快速搭建数据应用程序,并且不需要具备前端开发的专业知识,提供了多种组件,如按钮、滑块、下拉框、文本输入框等,这些组件可以方便地集成到应用中,实现用户与数据的交互,支持多种数据可视化库,像 Matplotlib、Plotly、Altair 等,可在应用中轻松展示各种图表和图形。
这里用 streamlit 主要是因为目前简单的演示 demo 的前端搭建用它实现起来特别迅速,上述整个 AI 面试网站的开发加上后端和 ui 展示逻辑一共 100 行代码左右,另外现在 streamlit 对于 LLM 开发的支持也特别友好:
代码获取
需要代码的小伙伴可以在文章开头的视频里评论,我会私发过去(只快速写了一个 demo,代码不够优雅,所有就不直接贴出来了)
后续改进想法
- 目前还不支持简历的导入功能,后续可以加上
- 另外还有 RAG 能力之后也可以支持一下
- 目前还没有对大模型的提问进行去重统计和检测,可能会出现几次提问后又会问之前问过的问题,目前先增大大模型的创造力系数
- 目前用 streamlit 只能做一个简单的 demo 页面,做一个完整的定制化网站还得用前端技术栈
- 目前还不支持最终对答完展示整个 Q-A 历史清单,导出 MarkDown 或 pdf 能力,之后也可以加上让提问人能够保存每次的知识
- 目前还没法做到循序渐进提问问题,除非把这次提问的所有 Q-A 内容都加进去,但是那样次数多了之后会出现超出大模型上下文的情况,所有还需要考虑怎么实现
- 现在提问的内容有些简单,也可以增加进阶型的 Agent 来更适合有经验的面试者