[MySQL]1-MySQL结构与运行原理
目录
官网文档
逻辑架构🌟
InnoDB引擎
数据结构🌟
页结构
生命周期
查询状态🌟
查询执行流程
1. 解析与预处理
2. 查询优化器
3. 执行计划生成
4. 执行SQL
数据写入顺序🌟
1. 写入 Undo Log,实现原子性的关键
2. 修改 Buffer Pool,配置innodb_flush_method=O_DIRECT 绕过OS缓存以减少文件系统缓存带来的额外开销
3. 写入 Redo Log Buffer 并刷盘,实现持久性以确保数据一致性和完整性
4. Binlog 刷盘,用于主从复制、增量备份和数据恢复等
5. 给事务打上 Commit 标签,标明事务结束,Redolog同步。用于重启后数据恢复
MySQL能处理的优化类型
MySQL查询优化器的局限性
资料引用
官网文档
逻辑架构🌟
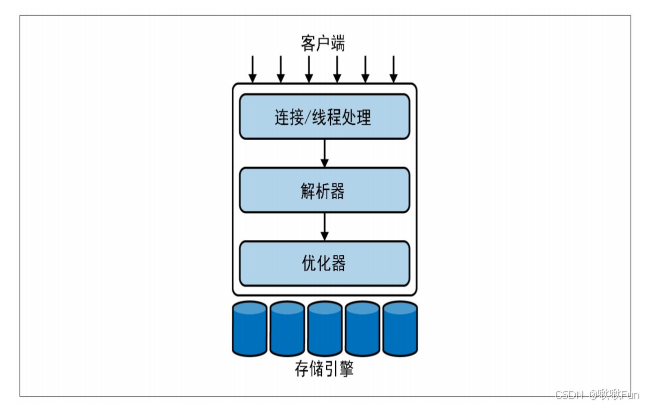
InnoDB引擎
- InnoDB
数据结构🌟
页结构

生命周期
查询状态🌟

查询执行流程
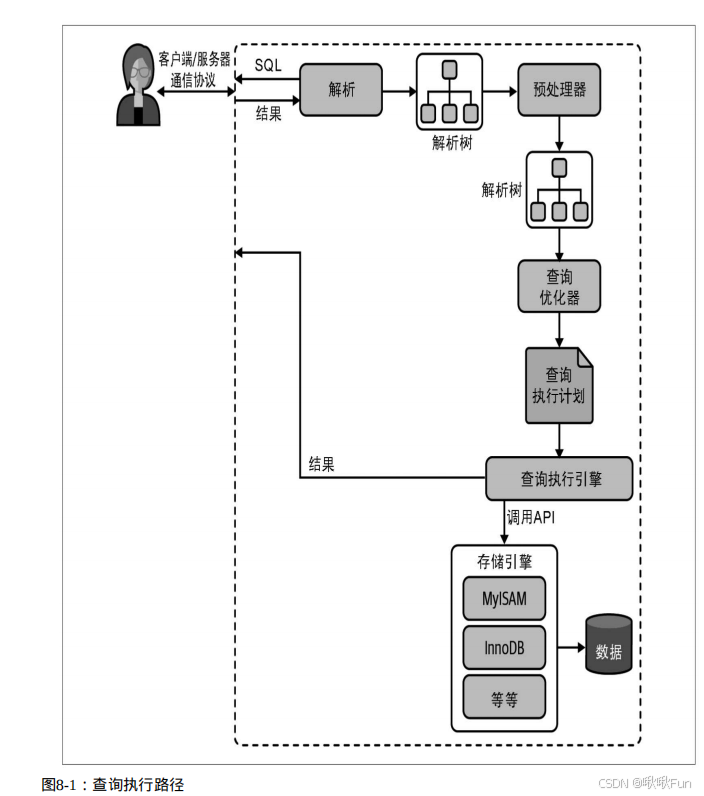
1. 解析与预处理
- 词法分析:此阶段的功能是将输入的SQL字符串分解成一系列有意义的标记(tokens),这些标记构成了SQL语句的基本组成部分。
- 语法分析:根据SQL语法规则构建抽象语法树(Abstract Syntax Tree, AST)。如果SQL语句不符合MySQL的语法规则,则会在这一阶段抛出错误。
- 语义分析:检查SQL语句的正确性,例如表名、列名是否存在,确保没有歧义等。此外,还会验证用户是否有权限执行该操作。
2. 查询优化器
- 索引选择:优化器评估不同索引的有效性,决定是否使用索引以及使用哪种类型的索引。
- 表连接顺序:在多表查询的情况下,确定以哪个表作为基准表,并定义表之间的连接顺序。
- 排序策略:如果查询涉及到排序操作,优化器会选择最有效的排序方法。
3. 执行计划生成
4. 执行SQL
- 读取数据:根据执行计划中的指示,从磁盘或缓存中检索所需的数据行。
- 表连接:如果是多表查询,则依据执行计划指定的方式执行表间的连接操作。
- 排序与分组:如果有ORDER BY或GROUP BY子句,则需按要求对结果集进行排序或分组。
- 过滤数据:运用WHERE子句中的条件表达式筛选符合条件的数据记录。
数据写入顺序🌟
MySQL 数据写入顺序是一个复杂的过程,涉及到多个日志和缓存机制的协调工作,以确保事务的ACID特性(原子性、一致性、隔离性和持久性)
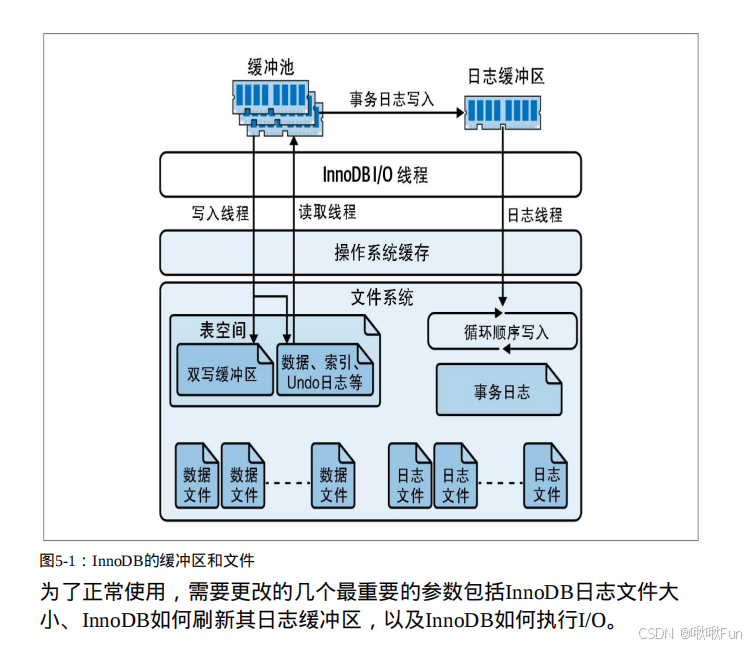
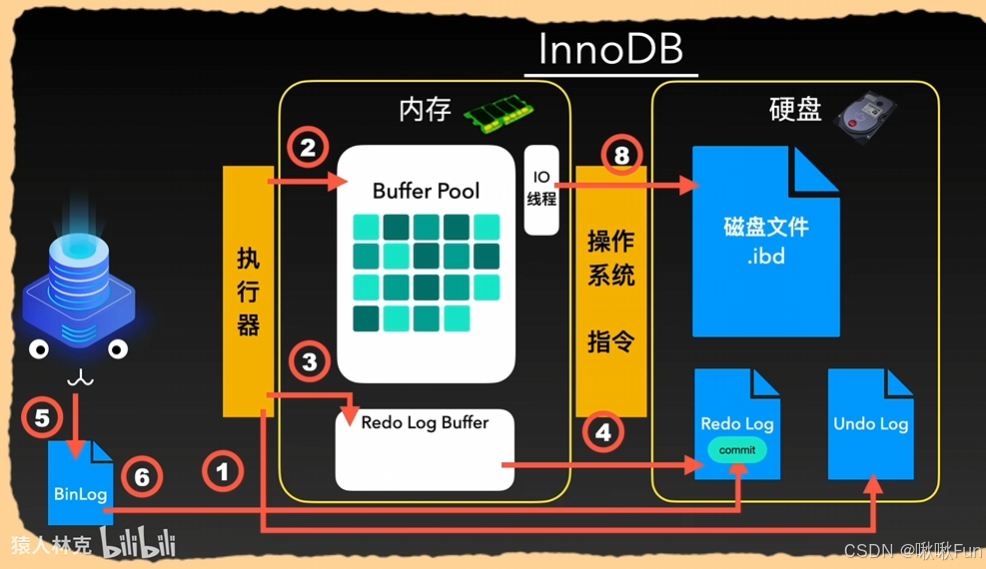
1. 写入 Undo Log,实现原子性的关键
在 MySQL 中,当执行一个更新或插入操作时,首先会生成 Undo Log。这是为了支持事务的回滚操作,同时也是实现事务原子性(Atomicity)的关键部分。Undo Log 记录了数据修改前的状态,使得如果事务失败或者被显式回滚,数据库可以利用这些日志将数据恢复到修改之前的状态。
2. 修改 Buffer Pool,配置innodb_flush_method=O_DIRECT 绕过OS缓存以减少文件系统缓存带来的额外开销
MySQL 将修改的数据页加载到 Buffer Pool 中。Buffer Pool 是 InnoDB 存储引擎用来缓存数据页的一个内存区域。所有对数据的实际修改都会先在这个内存区域中进行,而不是直接写入磁盘。这种设计极大地提高了读写性能,因为内存访问速度远高于磁盘访问速度。值得注意的是,此时的数据页被称为“脏页”(Dirty Page),意味着它们已经被修改但尚未写入磁盘。
通常情况下,MySQL 的写入操作会利用操作系统的页面缓存来提高效率,除非明确设置了 innodb_flush_method=O_DIRECT 参数以绕过 OS 缓存,O_DIRECT通常用于特定高性能需求场景下减少文件系统缓存带来的额外开销。
3. 写入 Redo Log Buffer 并刷盘,实现持久性以确保数据一致性和完整性
为了保证事务的持久性(Durability),MySQL 还需要将更改记录到 Redo Log 中。Redo Log 是一种物理日志,它记录了对数据库的所有修改信息,MySQL重启后会从Redo Log中恢复数据。每次事务提交时,MySQL 都会将相关的 Redo Log 从 Redo Log Buffer 写入到磁盘上的 Redo Log 文件中。通过这种方式,即使系统发生故障,也可以通过 Redo Log 恢复未完成的事务,确保数据的一致性和完整性。
具体的刷盘策略由参数 innodb_flush_log_at_trx_commit 控制,它可以设置为 0、1 或 2,分别代表不同的安全性和性能权衡。例如,当该值设为 1 时,每次事务提交都会立即将 Redo Log 刷入磁盘,这是最安全但也可能是最慢的选择;而设置为 2 则允许一定的延迟,仅将日志写入 OS 缓存而非立即同步到磁盘上,从而提升性能但稍微降低了数据安全性。
4. Binlog 刷盘,用于主从复制、增量备份和数据恢复等
对于开启了二进制日志(Binlog)功能的 MySQL 实例来说,在完成上述步骤之后还需要处理 Binlog 的写入问题。Binlog 是一种逻辑日志,主要用于记录所有的 DDL 和 DML 操作,广泛应用于主从复制、增量备份及数据恢复等领域。与 Redo Log 不同,Binlog 是按事务顺序追加写入的,并且可以通过工具如 mysqlbinlog 查看其内容。
根据 sync_binlog 参数的不同配置,MySQL 可能会在每个事务提交后立刻将 Binlog 同步到磁盘,也可能累积一定数量后再统一执行 fsync 操作。这种灵活性让用户能够在性能与可靠性之间找到平衡点。
5. 给事务打上 Commit 标签,标明事务结束,Redolog同步。用于重启后数据恢复
最后,在确认所有必要的日志都已经正确写入并持久化之后,MySQL 会给当前事务打上 Commit 标签。这意味着事务正式结束,其结果已经成为数据库状态的一部分。同时,这一状态也会被反映到相应的 Redo Log 中,以便在系统重启后能够准确地恢复已完成的事务记录。
综上所述,MySQL 的数据写入流程不仅包含了 Undo Log、Buffer Pool、Redo Log 和 Binlog 等多个组件之间的交互,还涉及到了多种参数调整的可能性,以满足不同应用场景下的性能与可靠性的需求。在整个过程中,MySQL 始终致力于保障事务的 ACID 特性,从而为用户提供稳定高效的服务体验。
MySQL能处理的优化类型



MySQL查询优化器的局限性

资料引用
B站《猿人林克》MySQL系列
《高性能MySQL》