YOLO V8的Anchor-Free、解耦头(Decoupled Head)、损失函数定义(含Varifocal Loss)
YOLOv8 的 Anchor-Free 设计摒弃了传统 YOLO 系列中依赖预定义锚框(Anchor Boxes)的机制,转而直接预测目标的中心点和边界框尺寸。这种设计简化了模型结构,降低了超参数调优的复杂度提升了检测速度和精度。以下是其核心实现原理和关键技术细节。
1. Anchor-Based vs. Anchor-Free 的区别
| 特性 | Anchor-Based (YOLOv3-v5) | Anchor-Free (YOLOv8) |
|---|---|---|
| 预测方式 | 基于预定义锚框预测偏移量和尺寸调整 | 直接预测目标中心点偏移和边界框尺寸 |
| 超参数依赖 | 需要人工设计或聚类生成锚框尺寸 | 无需锚框,完全端到端 |
| 计算复杂度 | 每个位置预测多个锚框,计算量大 | 每个位置预测单个目标,计算更高效 |
| 小目标检测 | 依赖锚框尺寸匹配,可能漏检 | 通过多尺度特征融合直接优化,鲁棒性更强 |
2. YOLOv8 的 Anchor-Free 核心设计
(1) 中心点预测(Center Prediction)
- 直接预测目标中心点:
YOLOv8 的每个输出特征图位置负责预测一个目标的中心点。对于输入图像被划分为 S×S 的网格,每个网格预测目标的中心点偏移量 (Δx,Δy),最终中心点坐标为:
(2) 边界框尺寸预测(Box Size Prediction)
- 直接预测宽高:
模型直接输出边界框的宽度和高度 (w,h),无需通过锚框缩放。公式为: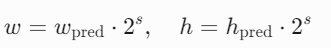
其中 s 是当前特征图相对于输入图像的下采样倍数(如 8, 16, 32),![]() 是网络输出的原始值(通过指数函数处理)。
是网络输出的原始值(通过指数函数处理)。
关于anchor free还进一步涉及“中心点邻近区域 + 动态IoU匹配+任务对齐[Task Alignment]”,参见:
YOLO V8中的“中心点邻近区域 + 动态IoU匹配“-CSDN博客
(3) 解耦头(Decoupled Head)
- 分类与回归任务分离:
YOLO v8 使用解耦的检测头,将分类(Class)和回归(Box)任务分开处理。具体结构如下:
# 示例代码(简化版解耦头)
class DecoupledHead(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
# 分类分支
self.cls_convs = nn.Sequential(
Conv(in_channels, 256), # 通道数调整
Conv(256, 256),
)
self.cls_pred = nn.Conv2d(256, num_classes, kernel_size=1)
# 回归分支
self.reg_convs = nn.Sequential(
Conv(in_channels, 256),
Conv(256, 256),
)
self.reg_pred = nn.Conv2d(256, 4, kernel_size=1) # 4: dx, dy, w, h
def forward(self, x):
cls_feat = self.cls_convs(x)
cls_out = self.cls_pred(cls_feat) # [B, num_classes, H, W]
reg_feat = self.reg_convs(x)
reg_out = self.reg_pred(reg_feat) # [B, 4, H, W]
return cls_out, reg_out优势:避免分类和回归任务之间的特征干扰,提升精度。
* Anchor-Free 的优势与挑战
优势
-
简化模型:无需设计锚框尺寸,减少超参数调优。
-
端到端优化:直接学习目标位置和尺寸,避免锚框带来的归纳偏置。
-
对小目标更友好:通过多尺度特征融合直接优化,避免锚框尺寸不匹配问题。
挑战
-
密集:同一网格内多个目标可能产生预测冲突,需依赖非极大值抑制(NMS)后处理。
-
训练稳定性:直接预测中心点和尺寸对初始化敏感,需谨慎设计损失函数。
3. 多尺度预测与特征融合
YOLOv8 通过 特征金字塔网络(FPN) 和 路径聚合网络(PAN) 实现多尺度预测:
- FPN: 自上而下传递高层语义特征,增强小目标检测。
- PAN: 自下而上传递低层细节特征,提升定位精度。
- 输出层:在 3 个不同尺度的特征图上进行预测(如 80x80, 40x40, 20x20),分别负责检测小、中、大目标。
4. 损失函数设计
YOLOv8 的损失函数由2部分组成:
1. 分类损失(Class Loss)
使用 Varifocal Loss(改进版 Focal Loss),动态调整正负样本权重,解决类别不平衡问题.
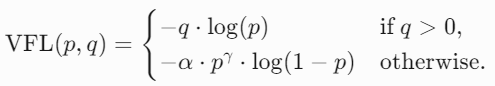
- q 是目标得分(如 IoU),p 是预测概率。
Varifocal Loss 是目标检测中用于解决类别不平衡问题的损失函数,由微软在 2020年 提出(论文《Varifocal Loss: A Learning Signal for Dense Object Detection》)。它是对 Focal Loss 的改进,特别适用于密集目标检测任务(如YOLO系列),通过动态调整正负样本权重,提升模型对困难样本(如小目标、遮挡目标)的检测能力。
1. 核心思想
(1) 问题背景
- 类别不平衡:目标检测中负样本(背景)远多于正样本(目标),传统交叉熵损失(Cross Entropy)会因负样本主导梯度而降低模型对正样本的学习能力。
- Focal Loss的局限:
Focal Loss 通过降低易分类样本(高置信度)的损失权重来缓解类别不平衡,但对正样本的优化仍不够精细,尤其对密集目标的预测质量(如IoU)缺乏敏感度。
(2) Varifocal Loss的改进
- 正样本权重动态调整:
对正样本的损失加权时,不再仅依赖度(仅依赖置信度会导致模型过度关注低质量(低 IoU)的正样本,因为即使预测框与真实框的 IoU 很低(如 0.3),只要分类置信度 p 高,损失权重仍然会被降低),而是结合预测框与真实框的 IoU(目标质量分数),使模型更关注高IoU的正样本。 - 非对称加权策略:
正样本使用 IoU-aware权重,负样本沿用类似Focal Loss的 置信度抑制权重,形成非对称加权。
2. 数学公式与推导
(1) 定义符号
p:模型预测的类别概率(经过Sigmoid后的值,范围[0,1])。
q:真实标签的目标质量分数(如预测框与真实框的IoU,范围[0,1])。对于负样本,q=0。
(2) Varifocal Loss公式

(3) 关键特性
-
IoU样本加权:
-
正样本损失与预测质量(IoU)直接关联,鼓励模型提升高质量预测的置信度。
-
非对称性:
-
正负样本采用不同加权策略,避免传统Focal Loss对正样本的过度抑制。
3. 与Focal Loss的对比
| 特性 | Focal Loss | Varifocal Loss |
|---|---|---|
| 正样本加权 | 使用固定 α \ gamma ) | 动态加权,权重=目标质量 q (IoU) |
| 负样本加权 | (1−p)^γ 抑制易分类负样本 | 类似Focal Loss,但允许调整 α |
| 优化目标 | 缓解类别不平衡 | 同时缓解类别不平衡,提升预测质量(IoU) |
| 适用场景 | 通用目标检测 | 密集目标检测(如YOLO系列) |
2. 边界框损失(Box Loss)
YOLO v8 使用 DFL Loss + CIoU Loss 联合优化边界框:
DFL Loss:用于预测边界框的坐标分布(中心点和宽高)。
CIoU Loss:进一步优化边界框的整体位置和形状。
A) 使用 CIoU Loss,同时优化重叠区域、中心点距离和宽高比。

B) DFL LOSS(Distribution Focal Loss)
在传统目标检测(如YOLOv3-v5)中,边界框回归通常直接预测坐标偏移量(如中心点 x,y 和宽高 w,h),并采用 Smooth L1 Loss 或 IoU-based Loss 进行优化。然而,这种方法存在以下问题:
坐标值的离散性:
真实框坐标是连续的,但模型输出是离散的浮点数,导致回归目标与预测之间存在量化误差。
- 难样本优化不足:
直接回归对极端值(如超大或超小目标)敏感,模型难以学习到准确的偏移量。 - 缺乏不确定性建模:
无法表达边界框预测的置信度分布(例如,模型对某一边界框的预测是否确定)。
DFL Loss将边界框坐标的预测视为 概率分布,通过预测离散化的概率值来间接回归连续坐标。具体来说: 离散化坐标空间: 将坐标值范围离散化为 n 个区间(如 n=16),模型预测每个区间对应的概率。 概率分布到坐标值的转换: 通过加权求和离散区间的参考值,得到最终的连续坐标值。 DFL通过Focal Loss的思想,强化对高概率区间的学习,抑制低概率区间的干扰。
数学公式与实现步骤:
(1) 离散化坐标表示
假设需要预测的坐标值(如中心点 y )范围为 [ymin,ymax],将其离散化为 n 个区间:
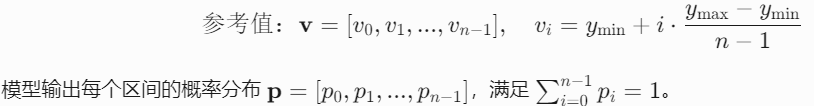
(2) 从分布到坐标值的计算
最终坐标值通过加权求和得到:
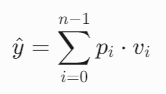
(3) DFL Loss定义

DFL Loss vs 传统回归方法
| 特性 | 传统回归(如Smooth L1) | DFL Loss |
|---|---|---|
| 预测形式 | 直接输出坐标值 | 输出离散区间的概率分布 |
| 目标表示 | 连续值 | 概率分布 |
| 误差敏感性 | 对极端值敏感 | 通过分布建模降低离群点影响 |
| 不确定性建模 | 无法表达置信度 | 概率分布隐含不确定性 |
| 小目标检测 | 易受量化误差影响 | 离散化分布缓解误差 |