ViT-Adapter
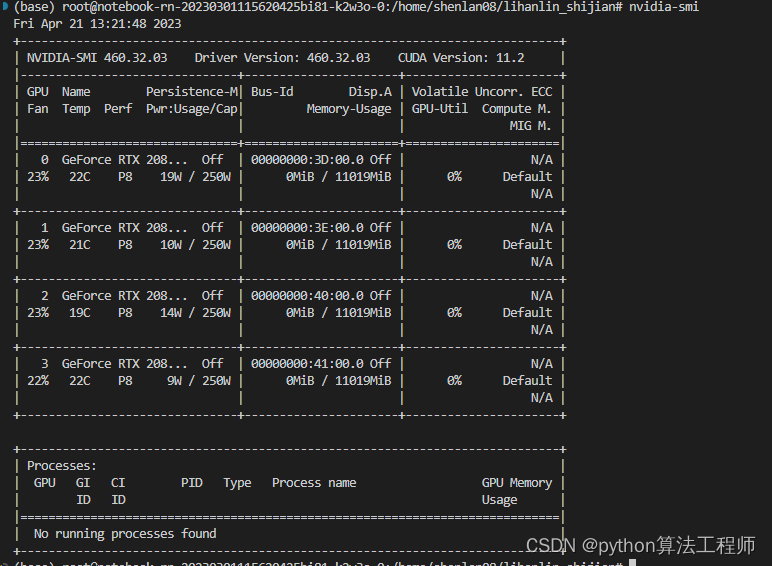
这次选用的环境是四张2080ti
cityspace数据集
有人跑通的案例
https://github.com/czczup/ViT-Adapter/tree/main/detection
这是一个训练一个分割器的 Python 脚本 train.py 的帮助文档。脚本接受一个参数 config,表示训练配置文件的路径。除此之外,还有一些可选参数。
–work-dir: 指定保存日志和模型的目录。
–load-from: 指定加载预训练模型的路径。
–resume-from: 指定恢复训练的模型的路径。
–no-validate: 是否在训练过程中不进行验证。
–gpus: 指定使用的 GPU 数量(仅适用于非分布式训练)。
–gpu-ids: 指定使用的 GPU ID(仅适用于非分布式训练)。
–seed: 指定随机种子。
–deterministic: 是否使用确定性选项来设置 CUDNN 后端。
–options: 已弃用,建议使用 --cfg-options。用于覆盖配置文件中的一些设置。
–cfg-options: 用于覆盖配置文件中的一些设置。
–launcher: 作业启动程序。
–local_rank: 用于指定分布式训练的进程的本地排名。
–auto-resume: 是否自动恢复最新的检查点。
这些参数可以通过在命令行中传递相应的选项来使用,例如:
python train.py config.yaml --work-dir ./logs --gpus 2
这将使用 config.yaml 文件进行训练,将日志和模型保存在 ./logs 目录中,并使用 2 个 GPU 进行训练。
ADE20k
ADE20K是一个大规模场景理解的图像语义分割数据集,包含超过20,000个图像和超过25,000个类别,是目前最大的公共场景理解数据集之一。该数据集的图像来自真实世界的场景,具有多样性和复杂性,可以用于训练和评估图像语义分割模型。ADE20K数据集不仅包含常见的物体和场景(例如人、车、家具、建筑),还包括一些不太常见的物体和场景(例如某些垃圾、病毒、奇怪的装置等等),因此对于图像语义分割模型的挑战性更高。
ADE20K数据集的图像均经过人工标注,每个像素都被标记为属于哪个类别,例如:人、车、树、天空等等。这些标注使得图像可以用于监督学习,例如训练深度学习模型进行图像语义分割任务。ADE20K数据集也是CVPR 2016的语义分割挑战赛的数据集之一,吸引了很多研究人员的关注。
Cityscapes
Introduction
Cityscapes is a large-scale database which focuses on semantic understanding of urban street scenes. It provides semantic, instance-wise, and dense pixel annotations for 30 classes grouped into 8 categories (flat surfaces, humans, vehicles, constructions, objects, nature, sky, and void). The dataset consists of around 5000 fine annotated images and 20000 coarse annotated ones. Data was captured in 50 cities during several months, daytimes, and good weather conditions. It was originally recorded as video so the frames were manually selected to have the following features: large number of dynamic objects, varying scene layout, and varying background.
Results and Models
Cityscapes val set
| Method | Backbone | Pretrain | BS | Lr schd | Crop | mIoU (SS/MS) | #Param | Config | Download |
|---|---|---|---|---|---|---|---|---|---|
| Mask2Former | ViT-Adapter-L | Mapillary | 16x1 | 80k | 896 | 84.9 / 85.8 | 571M | config | ckpt | log |
- Note that the Mapillary pretrained weights should be loaded by using
--cfg-options load_from=<pretrained_path>
Cityscapes test set
| Method | Backbone | Pretrain | BS | Lr schd | Crop | mIoU (SS/MS) | #Param | Config | Download |
|---|---|---|---|---|---|---|---|---|---|
| Mask2Former | ViT-Adapter-L | Mapillary | 16x1 | 80k | 896 | - / 85.2 | 571M | config | ckpt | log |
训练
To train ViT-Adapter-L + UperNet on ADE20k on a single node with 8 gpus run:
sh dist_train.sh configs/ade20k/upernet_beit_adapter_large_640_160k_ade20k_ss.py 8
评估
To evaluate ViT-Adapter-L + Mask2Former (896) on ADE20k val on a single node with 8 gpus run:
sh dist_test.sh configs/ade20k/mask2former_beit_adapter_large_896_80k_ade20k_ss.py /path/to/checkpoint_file 8 --eval mIoU
This should give
Summary:
±------±------±------+
| aAcc | mIoU | mAcc |
±------±------±------+
| 86.61 | 59.43 | 73.55 |
±------±------±------+
推理图片
CUDA_VISIBLE_DEVICES=0 python image_demo.py \
configs/ade20k/mask2former_beit_adapter_large_896_80k_ade20k_ss.py \
released/mask2former_beit_adapter_large_896_80k_ade20k.pth.tar \
data/ade/ADEChallengeData2016/images/validation/ADE_val_00000591.jpg \
--palette ade20k
结果将被保存在 demo/ADE_val_00000591.jpg.

推理视频
CUDA_VISIBLE_DEVICES=0 python video_demo.py demo.mp4 \
configs/ade20k/mask2former_beit_adapter_large_896_80k_ade20k_ss.py \
released/mask2former_beit_adapter_large_896_80k_ade20k.pth.tar \
--output-file results.mp4 \
--palette ade20k
model = dict(
pretrained=pretrained,
backbone=dict(
type='BEiTAdapter',
img_size=896,
patch_size=16,
embed_dim=1024,
depth=24,
num_heads=16,
mlp_ratio=4,
qkv_bias=True,
use_abs_pos_emb=False,
use_rel_pos_bias=True,
init_values=1e-6,
drop_path_rate=0.3,
conv_inplane=64,
n_points=4,
deform_num_heads=16,
cffn_ratio=0.25,
deform_ratio=0.5,
with_cp=True, # set with_cp=True to save memory
interaction_indexes=[[0, 5], [6, 11], [12, 17], [18, 23]],
),
decode_head=dict(
in_channels=[1024, 1024, 1024, 1024],
feat_channels=1024,
out_channels=1024,
num_queries=100,
pixel_decoder=dict(
type='MSDeformAttnPixelDecoder',
num_outs=3,
norm_cfg=dict(type='GN', num_groups=32),
act_cfg=dict(type='ReLU'),
encoder=dict(
type='DetrTransformerEncoder',
num_layers=6,
transformerlayers=dict(
type='BaseTransformerLayer',
attn_cfgs=dict(
type='MultiScaleDeformableAttention',
embed_dims=1024,
num_heads=32,
num_levels=3,
num_points=4,
im2col_step=64,
dropout=0.0,
batch_first=False,
norm_cfg=None,
init_cfg=None),
ffn_cfgs=dict(
type='FFN',
embed_dims=1024,
feedforward_channels=4096,
num_fcs=2,
ffn_drop=0.0,
with_cp=True, # set with_cp=True to save memory
act_cfg=dict(type='ReLU', inplace=True)),
operation_order=('self_attn', 'norm', 'ffn', 'norm')),
init_cfg=None),
positional_encoding=dict(
type='SinePositionalEncoding', num_feats=512, normalize=True),
init_cfg=None),
positional_encoding=dict(
type='SinePositionalEncoding', num_feats=512, normalize=True),
transformer_decoder=dict(
type='DetrTransformerDecoder',
return_intermediate=True,
num_layers=9,
transformerlayers=dict(
type='DetrTransformerDecoderLayer',
attn_cfgs=dict(
type='MultiheadAttention',
embed_dims=1024,
num_heads=32,
attn_drop=0.0,
proj_drop=0.0,
dropout_layer=None,
batch_first=False),
ffn_cfgs=dict(
embed_dims=1024,
feedforward_channels=4096,
num_fcs=2,
act_cfg=dict(type='ReLU', inplace=True),
ffn_drop=0.0,
dropout_layer=None,
with_cp=True, # set with_cp=True to save memory
add_identity=True),
feedforward_channels=4096,
operation_order=('cross_attn', 'norm', 'self_attn', 'norm',
'ffn', 'norm')),
init_cfg=None)
),
test_cfg=dict(mode='slide', crop_size=crop_size, stride=(512, 512))
)
这段代码是一个用于图像分割的模型的配置文件,采用了 BEiT(Bottleneck Transformers for Visual Recognition)作为主干网络,并使用了 MSDeformAttnPixelDecoder 构建解码头,以及 DetrTransformerEncoder 和 DetrTransformerDecoder 作为编码器和解码器。
具体来说,这个模型的配置包括以下几个部分:
- 预训练模型的路径和是否进行预训练。
- 使用 BEiTAdapter 作为主干网络,其中包括图像尺寸、patch 大小、嵌入维度、深度、头数、MLP 比率、是否使用绝对位置编码、是否使用相对位置偏置等参数。
- 使用 MSDeformAttnPixelDecoder 作为解码头,其中包括输出通道数、查询数、像素解码器、位置编码器等参数。
- 使用 DetrTransformerEncoder 作为编码器,其中包括层数、Transformer 层中的注意力机制和前馈网络等参数。
- 使用 DetrTransformerDecoder 作为解码器,其中包括层数、Transformer 层中的注意力机制和前馈网络等参数。
- 模型测试时的配置,包括模式、裁剪大小、步长等参数。
需要注意的是,这段代码中还涉及到一些特殊的技术,如 deformable convolution 和 multi-scale deformable attention 等,这些都是用于提高模型性能的技术。
核心代码
BEiTAdapter核心组成两个部分:Beit和adapter
class BEiTAdapter(BEiT):
def __init__(self, pretrain_size=224, conv_inplane=64, n_points=4, deform_num_heads=6,
init_values=0., cffn_ratio=0.25, deform_ratio=1.0, with_cffn=True,
interaction_indexes=None, add_vit_feature=True, with_cp=False, *args, **kwargs):
super().__init__(init_values=init_values, with_cp=with_cp, *args, **kwargs)
# self.num_classes = 80
# self.cls_token = None
self.num_block = len(self.blocks)
self.pretrain_size = (pretrain_size, pretrain_size)
self.flags = [i for i in range(-1, self.num_block, self.num_block // 4)][1:]
self.interaction_indexes = interaction_indexes
self.add_vit_feature = add_vit_feature
embed_dim = self.embed_dim
self.level_embed = add_parameter(self,paddle.zeros((3, embed_dim)))
self.spm = SpatialPriorModule(inplanes=conv_inplane, embed_dim=embed_dim, with_cp=False)
self.interactions = nn.Sequential(*[
InteractionBlockWithCls(dim=embed_dim, num_heads=deform_num_heads, n_points=n_points,
init_values=init_values, drop_path=self.drop_path_rate,
norm_layer=self.norm_layer, with_cffn=with_cffn,
cffn_ratio=cffn_ratio, deform_ratio=deform_ratio,
extra_extractor=True if i == len(interaction_indexes) - 1 else False,
with_cp=with_cp)
for i in range(len(interaction_indexes))
])
self.up = nn.Conv2DTranspose(embed_dim, embed_dim, 2, 2)
self.norm1 = nn.SyncBatchNorm(embed_dim)
self.norm2 = nn.SyncBatchNorm(embed_dim)
self.norm3 = nn.SyncBatchNorm(embed_dim)
self.norm4 = nn.SyncBatchNorm(embed_dim)
self.feat_channels = [1024, 1024, 1024, 1024]
self.up.apply(self._init_weights)
self.spm.apply(self._init_weights)
self.interactions.apply(self._init_weights)
self.apply(self._init_deform_weights)
normal_(self.level_embed)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_ = nn.initializer.TruncatedNormal(std=.02)
trunc_normal_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias)
elif isinstance(m, nn.LayerNorm) or isinstance(m, nn.BatchNorm2D):
zeros_(m.bias)
ones_(m.weight)
elif isinstance(m, nn.Conv2D) or isinstance(m, nn.Conv2DTranspose):
fan_out = m._kernel_size[0] * m._kernel_size[1] * m._out_channels
fan_out //= m._groups
norm = nn.initializer.Normal(0,math.sqrt(2.0 / fan_out))
norm(m.weight)
if m.bias is not None:
zeros_(m.bias)
def _get_pos_embed(self, pos_embed, H, W):
pos_embed = pos_embed.reshape((
1, self.pretrain_size[0] // 16, self.pretrain_size[1] // 16, -1)).transpose((0, 3, 1, 2))
pos_embed = F.interpolate(pos_embed, size=(H, W), mode='bicubic', align_corners=False).\
reshape((1, -1, H * W)).transpose((0, 2, 1))
return pos_embed
def _init_deform_weights(self, m):
if isinstance(m, MSDeformAttn):
m._reset_parameters()
def _add_level_embed(self, c2, c3, c4):
c2 = c2 + self.level_embed[0]
c3 = c3 + self.level_embed[1]
c4 = c4 + self.level_embed[2]
return c2, c3, c4
def forward(self, x):
"""
前向传播的过程分解为BeIT和Adapter两个部分
"""
deform_inputs1, deform_inputs2 = deform_inputs(x)
# SPM forward
c1, c2, c3, c4 = self.spm(x)
c2, c3, c4 = self._add_level_embed(c2, c3, c4)
c = paddle.concat([c2, c3, c4], axis=1)
# Patch Embedding forward
x, H, W = self.patch_embed(x)
bs, n, dim = x.shape
cls = self.cls_token.expand((bs, -1, -1)) # stole cls_tokens impl from Phil Wang, thanks
if self.pos_embed is not None:
pos_embed = self._get_pos_embed(self.pos_embed, H, W)
x = x + pos_embed
x = self.pos_drop(x)
# Interaction
outs = list()
for i, layer in enumerate(self.interactions):
indexes = self.interaction_indexes[i]
x, c, cls = layer(x, c, cls, self.blocks[indexes[0]:indexes[-1] + 1],
deform_inputs1, deform_inputs2, H, W)
outs.append(x.transpose([0, 2, 1]).reshape((bs, dim, H, W)))
# Split & Reshape
c2 = c[:, 0:c2.shape[1], :]
c3 = c[:, c2.shape[1]:c2.shape[1] + c3.shape[1], :]
c4 = c[:, c2.shape[1] + c3.shape[1]:, :]
c2 = c2.transpose([0, 2, 1]).reshape([bs, dim, H * 2, W * 2])
c3 = c3.transpose([0, 2, 1]).reshape([bs, dim, H, W])
c4 = c4.transpose([0, 2, 1]).reshape([bs, dim, H // 2, W // 2])
c1 = self.up(c2) + c1
if self.add_vit_feature:
x1, x2, x3, x4 = outs
x1 = F.interpolate(x1, scale_factor=4, mode='bilinear', align_corners=False)
x2 = F.interpolate(x2, scale_factor=2, mode='bilinear', align_corners=False)
x4 = F.interpolate(x4, scale_factor=0.5, mode='bilinear', align_corners=False)
c1, c2, c3, c4 = c1 + x1, c2 + x2, c3 + x3, c4 + x4
# Final Norm
f1 = self.norm1(c1)
f2 = self.norm2(c2)
f3 = self.norm3(c3)
f4 = self.norm4(c4)
return [f1, f2, f3, f4]
百度飞桨的实现方式
这段代码实现了一个名为 BEiTAdapter 的类,继承自 BEiT(Bottleneck Transformers for Visual Recognition),并添加了一些适应性模块,以提高模型的感受野和准确性。
该类的主要方法是 forward(),它实现了 BEiTAdapter 的前向传播过程。该过程分为两个部分:BEiT 的部分和 Adapter 的部分。BEiT 的部分使用 BEiT 的结构对输入的图像进行特征提取。Adapter 的部分则包括一些适应性模块,如 SpatialPriorModule、InteractionBlockWithCls 和 MSDeformAttn 等,以增强 BEiT 的性能。最终,BEiTAdapter 输出了四个特征图,分别对应输入图像的不同尺度。
总之,BEiTAdapter 是一种高效、准确且灵活的图像分类模型结构,可以适应各种具体的视觉任务,并在多个基准数据集上取得了优秀的表现。
base beit.py
BEiT (Bert-Enhanced Image Transformer) 是一种基于注意力机制的视觉语言预训练模型,由微软亚洲研究院提出。与传统的视觉模型不同,BEiT 可以同时处理图像和文本信息,从而将视觉和语言信息结合起来,提高视觉任务的性能。
BEiT 的核心思想是将自然语言处理模型中常用的 Transformer 架构应用于图像领域。具体来说,BEiT 首先将图像分成一系列的块,然后使用 Transformer 模型对每个块进行特征提取和编码。同时,BEiT 还引入了类似于 BERT 的预训练任务,通过大规模的无监督预训练来学习图像和文本信息的联合表示,从而提高模型的泛化能力。
与传统的视觉模型相比,BEiT 在多个视觉任务上取得了非常好的性能表现,包括图像分类、目标检测和语义分割等。同时,BEiT 的设计思想也启发了更多基于 Transformer 的视觉模型的发展,例如 DeiT、ViT 等。
# --------------------------------------------------------
# BEIT: BERT Pre-Training of Image Transformers (https://arxiv.org/abs/2106.08254)
# Github source: https://github.com/microsoft/unilm/tree/master/beit
# Copyright (c) 2021 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# By Hangbo Bao
# Based on timm, mmseg, setr, xcit and swin code bases
# https://github.com/rwightman/pytorch-image-models/tree/master/timm
# https://github.com/fudan-zvg/SETR
# https://github.com/facebookresearch/xcit/
# https://github.com/microsoft/Swin-Transformer
# --------------------------------------------------------'
import math
from functools import partial
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as cp
from mmcv_custom import load_checkpoint
from mmseg.models.builder import BACKBONES
from mmseg.utils import get_root_logger
from timm.models.layers import drop_path, to_2tuple, trunc_normal_
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of
residual blocks)."""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
def extra_repr(self) -> str:
return 'p={}'.format(self.drop_prob)
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None,
act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
# x = self.drop(x)
# commit this for the original BERT implement
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None,
attn_drop=0., proj_drop=0., window_size=None, attn_head_dim=None):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
if attn_head_dim is not None:
head_dim = attn_head_dim
all_head_dim = head_dim * self.num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, all_head_dim * 3, bias=False)
if qkv_bias:
self.q_bias = nn.Parameter(torch.zeros(all_head_dim))
self.v_bias = nn.Parameter(torch.zeros(all_head_dim))
else:
self.q_bias = None
self.v_bias = None
if window_size:
self.window_size = window_size
self.num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
self.relative_position_bias_table = nn.Parameter(
torch.zeros(self.num_relative_distance, num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# cls to token & token 2 cls & cls to cls
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(window_size[0])
coords_w = torch.arange(window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += window_size[1] - 1
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
relative_position_index = \
torch.zeros(size=(window_size[0] * window_size[1] + 1,) * 2, dtype=relative_coords.dtype)
relative_position_index[1:, 1:] = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
relative_position_index[0, 0:] = self.num_relative_distance - 3
relative_position_index[0:, 0] = self.num_relative_distance - 2
relative_position_index[0, 0] = self.num_relative_distance - 1
self.register_buffer("relative_position_index", relative_position_index)
# trunc_normal_(self.relative_position_bias_table, std=.0)
else:
self.window_size = None
self.relative_position_bias_table = None
self.relative_position_index = None
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(all_head_dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, rel_pos_bias=None):
B, N, C = x.shape
qkv_bias = None
if self.q_bias is not None:
qkv_bias = torch.cat((self.q_bias, torch.zeros_like(self.v_bias, requires_grad=False), self.v_bias))
# qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
qkv = qkv.reshape(B, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
if self.relative_position_bias_table is not None:
relative_position_bias = \
self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1] + 1,
self.window_size[0] * self.window_size[1] + 1, -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
# relative_position_bias = relative_position_bias[:, 1:, 1:]
attn = attn + relative_position_bias.unsqueeze(0)
if rel_pos_bias is not None:
attn = attn + rel_pos_bias
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., init_values=None, act_layer=nn.GELU, norm_layer=nn.LayerNorm,
window_size=None, attn_head_dim=None, with_cp=False):
super().__init__()
self.with_cp = with_cp
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, window_size=window_size, attn_head_dim=attn_head_dim)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
if init_values is not None:
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
else:
self.gamma_1, self.gamma_2 = None, None
def forward(self, x, H, W, rel_pos_bias=None):
def _inner_forward(x):
if self.gamma_1 is None:
x = x + self.drop_path(self.attn(self.norm1(x), rel_pos_bias=rel_pos_bias))
x = x + self.drop_path(self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x), rel_pos_bias=rel_pos_bias))
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))
return x
if self.with_cp and x.requires_grad:
x = cp.checkpoint(_inner_forward, x)
else:
x = _inner_forward(x)
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.patch_shape = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x, **kwargs):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
# assert H == self.img_size[0] and W == self.img_size[1], \
# f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x)
Hp, Wp = x.shape[2], x.shape[3]
x = x.flatten(2).transpose(1, 2)
return x, Hp, Wp
class HybridEmbed(nn.Module):
""" CNN Feature Map Embedding
Extract feature map from CNN, flatten, project to embedding dim.
"""
def __init__(self, backbone, img_size=224, feature_size=None, in_chans=3, embed_dim=768):
super().__init__()
assert isinstance(backbone, nn.Module)
img_size = to_2tuple(img_size)
self.img_size = img_size
self.backbone = backbone
if feature_size is None:
with torch.no_grad():
# FIXME this is hacky, but most reliable way of determining the exact dim of the output feature
# map for all networks, the feature metadata has reliable channel and stride info, but using
# stride to calc feature dim requires info about padding of each stage that isn't captured.
training = backbone.training
if training:
backbone.eval()
o = self.backbone(torch.zeros(1, in_chans, img_size[0], img_size[1]))[-1]
feature_size = o.shape[-2:]
feature_dim = o.shape[1]
backbone.train(training)
else:
feature_size = to_2tuple(feature_size)
feature_dim = self.backbone.feature_info.channels()[-1]
self.num_patches = feature_size[0] * feature_size[1]
self.proj = nn.Linear(feature_dim, embed_dim)
def forward(self, x):
x = self.backbone(x)[-1]
x = x.flatten(2).transpose(1, 2)
x = self.proj(x)
return x
class RelativePositionBias(nn.Module):
def __init__(self, window_size, num_heads):
super().__init__()
self.window_size = window_size
self.num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
self.relative_position_bias_table = nn.Parameter(
torch.zeros(self.num_relative_distance, num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# cls to token & token 2 cls & cls to cls
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(window_size[0])
coords_w = torch.arange(window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += window_size[1] - 1
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
relative_position_index = \
torch.zeros(size=(window_size[0] * window_size[1] + 1,) * 2, dtype=relative_coords.dtype)
relative_position_index[1:, 1:] = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
relative_position_index[0, 0:] = self.num_relative_distance - 3
relative_position_index[0:, 0] = self.num_relative_distance - 2
relative_position_index[0, 0] = self.num_relative_distance - 1
self.register_buffer("relative_position_index", relative_position_index)
# trunc_normal_(self.relative_position_bias_table, std=.02)
def forward(self):
relative_position_bias = \
self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1] + 1,
self.window_size[0] * self.window_size[1] + 1, -1) # Wh*Ww,Wh*Ww,nH
return relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
@BACKBONES.register_module()
class BEiT(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=512, patch_size=16, in_chans=3, num_classes=80, embed_dim=768,
depth=12, num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., hybrid_backbone=None, norm_layer=None,
init_values=None, use_checkpoint=False, use_abs_pos_emb=False, use_rel_pos_bias=True,
use_shared_rel_pos_bias=False, pretrained=None, with_cp=False):
super().__init__()
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
self.norm_layer = norm_layer
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.drop_path_rate = drop_path_rate
if hybrid_backbone is not None:
self.patch_embed = HybridEmbed(
hybrid_backbone, img_size=img_size, in_chans=in_chans, embed_dim=embed_dim)
else:
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# self.mask_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
if use_abs_pos_emb:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
else:
self.pos_embed = None
self.pos_drop = nn.Dropout(p=drop_rate)
if use_shared_rel_pos_bias:
self.rel_pos_bias = RelativePositionBias(window_size=self.patch_embed.patch_shape, num_heads=num_heads)
else:
self.rel_pos_bias = None
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.use_rel_pos_bias = use_rel_pos_bias
self.use_checkpoint = use_checkpoint
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, with_cp=with_cp,
init_values=init_values, window_size=self.patch_embed.patch_shape if use_rel_pos_bias else None)
for i in range(depth)])
# if self.pos_embed is not None:
# trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
self.init_weights(pretrained)
# self.fix_init_weight()
def init_weights(self, pretrained=None):
"""Initialize the weights in backbone.
Args:
pretrained (str, optional): Path to pre-trained weights.
Defaults to None.
"""
# pretrained = 'pretrained/beit_large_patch16_512_pt22k_ft22kto1k.pth'
if isinstance(pretrained, str):
logger = get_root_logger()
load_checkpoint(self, pretrained, strict=False, logger=logger)
def fix_init_weight(self):
def rescale(param, layer_id):
param.div_(math.sqrt(2.0 * layer_id))
for layer_id, layer in enumerate(self.blocks):
rescale(layer.attn.proj.weight.data, layer_id + 1)
rescale(layer.mlp.fc2.weight.data, layer_id + 1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def get_num_layers(self):
return len(self.blocks)

base uniperceiver.py
这是一个实现自注意力机制的PyTorch模块。主要包括以下几个部分:
-
初始化函数:定义了模块的参数,包括输入特征的维度、注意力头数、是否使用偏置、注意力和投影的dropout率。
-
前向函数:实现了自注意力机制的计算过程。具体来说,它将输入特征张量x映射到查询、键、值矩阵上,并将它们按头数分开。然后,它计算每个位置与其他位置的注意力分数,并将注意力分数与值矩阵相乘得到输出。最后,它使用一个全连接层进行投影。
-
两个辅助函数:window_partition和window_reverse。它们分别用于将输入特征张量划分成小块和将小块恢复成原始形状。
总的来说,这是一个非常简洁而高效的自注意力机制实现,可以用于处理长序列的NLP和CV任务。值得注意的是,这个实现没有考虑窗口化处理,因此对于长序列,可能需要使用更高效的窗口化自注意力实现。
import logging
import math
import torch
import torch.nn.functional as F
import torch.utils.checkpoint as cp
from mmcv.runner import load_checkpoint
from mmseg.utils import get_root_logger
from timm.models.layers import DropPath
from torch import nn
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.in_proj = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.out_proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, H, W):
B, N, C = x.shape
qkv = self.in_proj(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.out_proj(x)
x = self.proj_drop(x)
return x
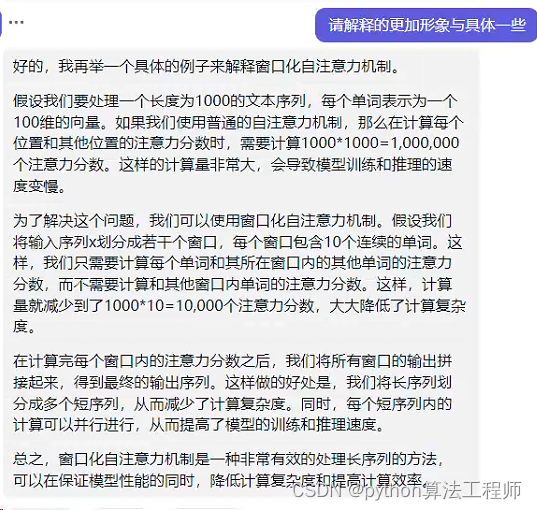
这是一个实现窗口自注意力机制的PyTorch模块。主要包括以下几个部分:
-
初始化函数:定义了模块的参数,包括输入特征的维度、注意力头数、是否使用偏置、注意力和投影的dropout率以及窗口大小。
-
前向函数:实现了窗口自注意力机制的计算过程。具体来说,它将输入特征张量x按照窗口大小划分成若干个小块,并将每个小块展开成一个向量。然后,它使用一个全连接层将每个向量映射到三个矩阵(查询、键、值)上,并将它们分别按头数和窗口大小分开。接着,它计算每个位置与窗口内其他位置的注意力分数,并将注意力分数与值矩阵相乘得到输出。最后,它将输出张量恢复成原始形状,并使用一个全连接层进行投影。
-
两个辅助函数:window_partition和window_reverse。它们分别用于将输入特征张量划分成小块和将小块恢复成原始形状。
总的来说,这是一个非常简洁而高效的窗口自注意力机制实现,可以用于处理长序列的NLP和CV任务。
class WindowedAttention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0., window_size=14):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.in_proj = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.out_proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.window_size = window_size
def forward(self, x, H, W):
B, N, C = x.shape
N_ = self.window_size * self.window_size
H_ = math.ceil(H / self.window_size) * self.window_size
W_ = math.ceil(W / self.window_size) * self.window_size
x = x.view(B, H, W, C)
x = F.pad(x, [0, 0, 0, W_ - W, 0, H_ - H])
x = window_partition(x, window_size=self.window_size) # nW*B, window_size, window_size, C
x = x.view(-1, N_, C)
qkv = self.in_proj(x).view(-1, N_, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale # [B, L, num_head, N_, N_]
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn) # [B, L, num_head, N_, N_]
x = (attn @ v).transpose(1, 2).reshape(-1, self.window_size, self.window_size, C)
x = window_reverse(x, self.window_size, H_, W_)
x = x[:, :H, :W, :].reshape(B, N, C).contiguous()
x = self.out_proj(x)
x = self.proj_drop(x)
return x
这是一个BERT模型的一个基本层BertLayer,用于自然语言处理(NLP)和计算机视觉(CV)任务。
该层包括了两个子层:多头自注意力机制和前馈网络(FFN)。其中,如果设置了windowed=True,则使用窗口化自注意力层(WindowedAttention),否则使用传统的自注意力层(Attention)。自注意力机制是BERT模型的核心组成部分,它可以根据序列中的上下文信息自适应地计算不同单词之间的相关性,以此来提取特征表示。这里使用的自注意力机制是基于查询-键-值(query-key-value)机制的,即将输入序列拆分为查询(query)、键(key)和值(value)三个部分,通过计算它们之间的相似度来得到每个位置的输出向量。
在自注意力层之后,使用了一个前馈网络(FFN)来进一步处理特征向量。FFN由两个线性变换和一个激活函数(这里使用的是GELU)组成,其中第一个线性变换将特征向量映射到一个中间维度,第二个线性变换将中间维度映射回原始维度。这个过程可以看做是一种非线性变换,通过增加模型的复杂度来提高其表达能力。
为了加强模型的表达能力,该层还使用了两个残差连接和一个层归一化。残差连接可以帮助信息在网络中更快地传递和保持,层归一化可以帮助网络更好地学习特征表示。此外,为了防止过拟合,使用了一个Dropout正则化和一个DropPath方法来随机地丢弃一些特征向量。
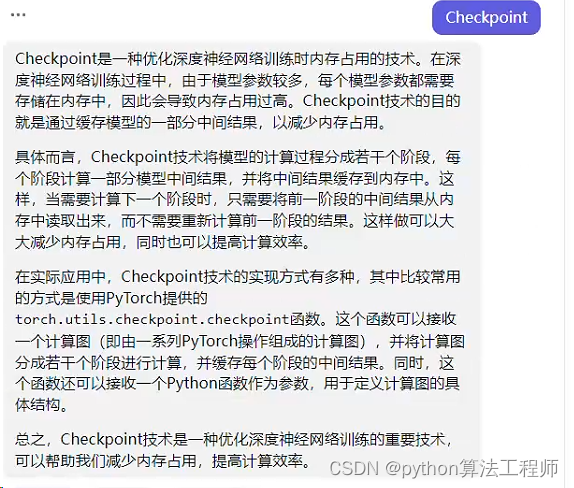
最后,该层还可以选择是否使用checkpoint技术进行加速。checkpoint技术是一种可以将计算图分成多个子图并在每个子图中进行计算的方法,它可以减少显存的使用并提高计算效率。
class BertLayer(nn.Module):
def __init__(self, hidden_size=768, intermediate_size=3072, num_attention_heads=12,
drop_path_ratio=0.1, windowed=False, window_size=14, with_cp=False):
super(BertLayer, self).__init__()
self.with_cp = with_cp
if windowed:
self.self_attn = WindowedAttention(hidden_size, num_attention_heads, qkv_bias=True, attn_drop=0.,
proj_drop=0., window_size=window_size)
else:
self.self_attn = Attention(hidden_size, num_attention_heads, qkv_bias=True, attn_drop=0., proj_drop=0.)
# self.intermediate = BertIntermediate(hidden_size, intermediate_size)
self.linear1 = nn.Linear(hidden_size, intermediate_size)
self.act_fn = nn.GELU()
self.linear2 = nn.Linear(intermediate_size, hidden_size)
self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()
self.norm1 = nn.LayerNorm(hidden_size)
self.norm2 = nn.LayerNorm(hidden_size)
self.gamma_1 = nn.Parameter(torch.zeros((hidden_size)), requires_grad=True)
self.gamma_2 = nn.Parameter(torch.zeros((hidden_size)), requires_grad=True)
def ffn_forward(self, x):
x = self.linear1(x)
x = self.act_fn(x)
x = self.linear2(x)
return x
def forward(self, x, H, W):
def _inner_forward(x):
x = x + self.gamma_1 * self.drop_path(self.self_attn(self.norm1(x), H, W))
x = x + self.gamma_2 * self.drop_path(self.ffn_forward(self.norm2(x)))
return x
if self.with_cp and x.requires_grad:
x = cp.checkpoint(_inner_forward, x)
else:
x = _inner_forward(x)
return x
这段代码是一个名为VisualPatchEmbedding的PyTorch模块的定义,用于将图像输入转换为嵌入向量。它包含以下几个部分:
__init__函数:在初始化模块时,它接受四个参数:in_dim表示输入图像的通道数,默认为3;out_dim表示输出嵌入向量的维度,默认为768;patch_size表示将输入图像划分为小块的大小,默认为16;image_size表示输入图像的大小,默认为224;dropout表示是否在嵌入向量上应用dropout,默认为0。
在函数体中,它首先调用了nn.LayerNorm函数来对输出嵌入向量进行归一化处理。然后,它定义了一个名为patch_embed的子模块,用于从输入图像中提取嵌入向量。patch_embed本身是另一个模块PatchEmbed的实例化,用于将输入图像划分为小块,并将每个小块转换为嵌入向量。
forward函数:在前向传播时,它接受一个输入张量x,表示输入的图像。它首先将输入图像通过patch_embed模块转换为嵌入向量embeddings,并返回嵌入向量的高度H和宽度W。然后,它对嵌入向量进行激活函数、归一化和dropout等操作,并最终返回处理后的嵌入向量embeddings、高度H和宽度W。
需要注意的是,当前代码中的注释中有一些被注释掉的代码,这些代码是关于嵌入向量类型的代码。这些代码被注释掉可能是因为在这个特定的应用中,嵌入向量类型并不是必须的。具体来说,注释中的代码使用了nn.Embedding来定义一个嵌入向量类型,并将它添加到嵌入向量中。
这段代码的输入是一个大小为[batch_size, in_dim, image_size, image_size]的4D张量x,表示输入的图像数据。其中,batch_size表示输入的图像数量,in_dim表示输入图像的通道数,image_size表示输入图像的高和宽。
输出为一个大小为[batch_size, num_patches, out_dim]的3D张量embeddings,表示通过嵌入层将输入图像转换为的嵌入向量。其中,num_patches表示输入图像被划分为的块数,即图像大小除以块大小的乘积。out_dim表示输出嵌入向量的维度大小。
除了embeddings之外,还会输出两个标量值H和W,分别表示通过嵌入层将输入图像划分为块后的高度和宽度。这两个值可以用于后续的操作,如在Transformer中进行自注意力计算时使用。
class VisualPatchEmbedding(nn.Module):
def __init__(self, in_dim=3, out_dim=768, patch_size=16, image_size=224, dropout=0.):
super(VisualPatchEmbedding, self).__init__()
self.embeddings_act = None
self.embeddings_norm = nn.LayerNorm(out_dim)
# self.embeddings_type = nn.Embedding(1, 768)
self.embeddings_dropout = nn.Dropout(dropout)
self.patch_embed = PatchEmbed(
img_size=(image_size, image_size),
patch_size=(patch_size, patch_size),
in_chans=in_dim, embed_dim=out_dim,
)
def forward(self, x):
embeddings, H, W = self.patch_embed(x)
# data_type = torch.zeros(1).long().cuda()
# embeddings_type = self.embeddings_type(data_type).unsqueeze(1)
# embeddings = embeddings + embeddings_type
# embeddings = embeddings + self.embeddings_type.weight[0].unsqueeze(0).unsqueeze(1).to(embeddings.dtype)
if self.embeddings_act is not None:
embeddings = self.embeddings_act(embeddings)
if self.embeddings_norm is not None:
embeddings = self.embeddings_norm(embeddings)
if self.embeddings_dropout is not None:
embeddings = self.embeddings_dropout(embeddings)
return embeddings, H, W
这段代码实现了一个将图像转换为嵌入向量的模块,使用了均匀采样的方式将图像划分为若干个块,并将每个块内的像素展平后通过一个卷积层进行特征提取,最终将特征向量按顺序串联起来得到嵌入向量。同时,该模块还为每个嵌入向量添加了位置编码和时间编码,以便于模型对嵌入向量的位置信息和时间信息进行建模。
具体而言,该模块的输入为一个大小为[batch_size, in_chans, img_size[0], img_size[1]]的4D张量x,表示输入的图像数据。其中,batch_size表示输入的图像数量,in_chans表示输入图像的通道数,img_size表示输入图像的高和宽。
输出为一个大小为[batch_size, num_patches, embed_dim]的3D张量x,表示通过嵌入层将输入图像转换为的嵌入向量。其中,num_patches表示输入图像被划分为的块数,即图像大小除以块大小的乘积。embed_dim表示输出嵌入向量的维度大小。
此外,该模块还输出两个标量值H和W,分别表示划分后的块数高和宽。这两个值可以用于后续的操作,如在Transformer中进行自注意力计算时使用。
class PatchEmbed(torch.nn.Module):
"""Image to Patch Embedding."""
def __init__(self, img_size=(224, 224), patch_size=(16, 16), in_chans=3, embed_dim=768):
super().__init__()
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.pretrain_size = img_size
self.spatial_pos_embed = nn.Embedding(num_patches, embed_dim)
self.temporal_pos_embed = nn.Embedding(8, embed_dim)
self.proj = torch.nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def _get_pos_embed(self, pos_embed, H, W):
pos_embed = pos_embed.reshape(
1, self.pretrain_size[0] // 16, self.pretrain_size[1] // 16, -1).permute(0, 3, 1, 2)
pos_embed = F.interpolate(pos_embed, size=(H, W), mode='bicubic', align_corners=False). \
reshape(1, -1, H * W).permute(0, 2, 1)
return pos_embed
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2) # B, N, C
temp_len = 1
pos_embed = self._get_pos_embed(self.spatial_pos_embed.weight.unsqueeze(0), H // 16, W // 16)
temporal_pos_ids = torch.arange(temp_len, dtype=torch.long, device=x.device)
temporal_pos_embed = self.temporal_pos_embed(temporal_pos_ids).unsqueeze(0)
x = x + pos_embed + temporal_pos_embed
return x, H // 16, W // 16
这段代码实现了一个基于BERT的视觉编码器,将输入的图像数据转换为一系列嵌入向量,并对这些嵌入向量进行多层次的自注意力计算,以提取图像的语义信息。
具体而言,该编码器的输入为一个大小为[batch_size, in_chans, img_size, img_size]的4D张量x,表示输入的图像数据。其中,batch_size表示输入的图像数量,in_chans表示输入图像的通道数,img_size表示输入图像的高和宽。
输出为一个大小为[batch_size, num_patches, embed_dim]的3D张量x,表示通过BERT视觉编码器将输入图像转换为的嵌入向量序列。其中,num_patches表示输入图像被划分为的块数,即图像大小除以块大小的乘积。embed_dim表示每个嵌入向量的维度大小。
该视觉编码器由多个BertLayer组成,每个BertLayer包含一个自注意力模块和一个全连接前馈网络模块。在自注意力模块中,会对输入的嵌入向量序列进行自注意力计算,以提取序列中每个嵌入向量的上下文信息。全连接前馈网络模块则对每个嵌入向量进行非线性变换,以进一步提取其语义信息。
在编码器的初始化过程中,会根据输入参数初始化BertLayer和VisualPatchEmbedding模块,并载入预训练模型的参数(如果有提供预训练模型)。
在前向计算过程中,会先通过VisualPatchEmbedding模块将输入图像转换为嵌入向量序列,然后通过多个BertLayer对嵌入向量序列进行多层次的自注意力计算。最后,输出计算得到的嵌入向量序列。
class UnifiedBertEncoder(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., drop_path_rate=0., norm_layer=nn.LayerNorm,
embed_layer=VisualPatchEmbedding, window_attn=False, window_size=14,
with_cp=False, pretrained=None):
super(UnifiedBertEncoder, self).__init__()
self.embed_dim = embed_dim
self.drop_path_rate = drop_path_rate
self.norm_layer = norm_layer
window_attn = [window_attn] * depth if not isinstance(window_attn, list) else window_attn
window_size = [window_size] * depth if not isinstance(window_size, list) else window_size
logging.info('window attention:', window_attn)
logging.info('window size:', window_size)
layers = []
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
for i in range(depth):
layers.append(
BertLayer(hidden_size=embed_dim, intermediate_size=int(embed_dim * mlp_ratio),
num_attention_heads=num_heads, drop_path_ratio=dpr[i],
windowed=window_attn[i], window_size=window_size[i], with_cp=with_cp)
)
self.layers = nn.ModuleList(layers)
self.visual_embed = embed_layer(in_dim=in_chans, out_dim=embed_dim,
patch_size=patch_size, image_size=img_size)
self.init_weights(pretrained)
def init_weights(self, pretrained=None):
if isinstance(pretrained, str):
logger = get_root_logger()
load_checkpoint(self, pretrained, map_location='cpu', strict=False, logger=logger)
def forward(self, x):
x, H, W = self.visual_embed(x)
for layer in self.layers:
x = layer(x, H, W)
return x
base vit.py
"""Vision Transformer (ViT) in PyTorch.
A PyTorch implement of Vision Transformers as described in:
'An Image Is Worth 16 x 16 Words: Transformers for Image Recognition at Scale'
- https://arxiv.org/abs/2010.11929
`How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers`
- https://arxiv.org/abs/2106.10270
The official jax code is released and available at https://github.com/google-research/vision_transformer
DeiT model defs and weights from https://github.com/facebookresearch/deit,
paper `DeiT: Data-efficient Image Transformers` - https://arxiv.org/abs/2012.12877
Acknowledgments:
* The paper authors for releasing code and weights, thanks!
* I fixed my class token impl based on Phil Wang's https://github.com/lucidrains/vit-pytorch ... check it out
for some einops/einsum fun
* Simple transformer style inspired by Andrej Karpathy's https://github.com/karpathy/minGPT
* Bert reference code checks against Huggingface Transformers and Tensorflow Bert
Hacked together by / Copyright 2021 Ross Wightman
"""
import logging
import math
from functools import partial
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as cp
from mmcv.runner import BaseModule
from mmcv_custom import my_load_checkpoint as load_checkpoint
from mmseg.utils import get_root_logger
from timm.models.layers import DropPath, Mlp, to_2tuple
class PatchEmbed(nn.Module):
"""2D Image to Patch Embedding."""
def __init__(self, img_size=224, patch_size=16, in_chans=3,
embed_dim=768, norm_layer=None, flatten=True):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.flatten = flatten
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
_, _, H, W = x.shape
if self.flatten:
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
x = self.norm(x)
return x, H, W
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, H, W):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class WindowedAttention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0., window_size=14,
pad_mode="constant"):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.window_size = window_size
self.pad_mode = pad_mode
def forward(self, x, H, W):
B, N, C = x.shape
N_ = self.window_size * self.window_size
H_ = math.ceil(H / self.window_size) * self.window_size
W_ = math.ceil(W / self.window_size) * self.window_size
qkv = self.qkv(x) # [B, N, C]
qkv = qkv.transpose(1, 2).reshape(B, C * 3, H, W) # [B, C, H, W]
qkv = F.pad(qkv, [0, W_ - W, 0, H_ - H], mode=self.pad_mode)
qkv = F.unfold(qkv, kernel_size=(self.window_size, self.window_size),
stride=(self.window_size, self.window_size))
B, C_kw_kw, L = qkv.shape # L - the num of windows
qkv = qkv.reshape(B, C * 3, N_, L).permute(0, 3, 2, 1) # [B, L, N_, C]
qkv = qkv.reshape(B, L, N_, 3, self.num_heads, C // self.num_heads).permute(3, 0, 1, 4, 2, 5)
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
# q,k,v [B, L, num_head, N_, C/num_head]
attn = (q @ k.transpose(-2, -1)) * self.scale # [B, L, num_head, N_, N_]
# if self.mask:
# attn = attn * mask
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn) # [B, L, num_head, N_, N_]
# attn @ v = [B, L, num_head, N_, C/num_head]
x = (attn @ v).permute(0, 2, 4, 3, 1).reshape(B, C_kw_kw // 3, L)
x = F.fold(x, output_size=(H_, W_), kernel_size=(self.window_size, self.window_size),
stride=(self.window_size, self.window_size)) # [B, C, H_, W_]
x = x[:, :, :H, :W].reshape(B, C, N).transpose(-1, -2)
x = self.proj(x)
x = self.proj_drop(x)
return x
# class WindowedAttention(nn.Module):
# def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0., window_size=14, pad_mode="constant"):
# super().__init__()
# self.num_heads = num_heads
# head_dim = dim // num_heads
# self.scale = head_dim ** -0.5
#
# self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
# self.attn_drop = nn.Dropout(attn_drop)
# self.proj = nn.Linear(dim, dim)
# self.proj_drop = nn.Dropout(proj_drop)
# self.window_size = window_size
# self.pad_mode = pad_mode
#
# def forward(self, x, H, W):
# B, N, C = x.shape
#
# N_ = self.window_size * self.window_size
# H_ = math.ceil(H / self.window_size) * self.window_size
# W_ = math.ceil(W / self.window_size) * self.window_size
# x = x.view(B, H, W, C)
# x = F.pad(x, [0, 0, 0, W_ - W, 0, H_- H], mode=self.pad_mode)
#
# x = window_partition(x, window_size=self.window_size)# nW*B, window_size, window_size, C
# x = x.view(-1, N_, C)
#
# qkv = self.qkv(x).view(-1, N_, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
# attn = (q @ k.transpose(-2, -1)) * self.scale # [B, L, num_head, N_, N_]
# attn = attn.softmax(dim=-1)
# attn = self.attn_drop(attn) # [B, L, num_head, N_, N_]
# x = (attn @ v).transpose(1, 2).reshape(-1, self.window_size, self.window_size, C)
#
# x = window_reverse(x, self.window_size, H_, W_)
# x = x[:, :H, :W, :].reshape(B, N, C).contiguous()
# x = self.proj(x)
# x = self.proj_drop(x)
# return x
这段代码实现了一个Transformer的基础Block,用于构建Transformer的Encoder和Decoder。Block的输入为一个大小为[batch_size, seq_len, dim]的3D张量x,表示输入的序列数据。其中,batch_size表示输入序列的数量,seq_len表示序列的长度,dim表示每个序列元素的维度大小。
输出为一个大小为[batch_size, seq_len, dim]的3D张量x,表示经过一个Block计算后得到的新的序列。在Block中,输入序列会分别经过自注意力模块和全连接前馈网络模块,然后通过残差连接和Layer Normalization进行融合。
具体而言,Block包含以下几个模块:
norm1:一个Layer Normalization模块,对输入序列进行归一化处理。attn:一个自注意力模块,对输入序列进行自注意力计算,以提取序列中每个元素的上下文信息。drop_path:一个Drop Path模块,用于随机丢弃一些模型参数,从而实现模型的随机性和鲁棒性。norm2:一个Layer Normalization模块,对自注意力模块的输出进行归一化处理。mlp:一个全连接前馈网络模块,用于对自注意力模块的输出进行进一步的特征提取和转换。layer_scale:一个标志位,用于指示是否使用Layer Scale技术(即对每个Block进行缩放)。gamma1和gamma2:两个可学习的缩放因子,用于对Block的输出进行缩放。with_cp:一个标志位,用于指示是否使用Checkpoint技术(即对模型进行缓存,以节省内存并提高训练速度)。
其中,_inner_forward函数表示Block的内部计算过程,根据layer_scale标志位的不同,分别对输入序列进行不同的处理。如果layer_scale为True,则对输入序列进行缩放,并将缩放后的输出与原始输入序列进行加和,然后通过Drop Path模块进行随机丢弃。如果layer_scale为False,则直接对输入序列进行自注意力计算和全连接前馈网络计算,并将计算结果与原始输入序列进行加和,然后通过Drop Path模块进行随机丢弃。
最后,在forward函数中,根据with_cp标志位的不同,选择是否使用Checkpoint技术。如果使用,则对计算过程进行缓存,以节省内存并提高训练速度。如果不使用,则直接调用_inner_forward函数进行计算。
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, windowed=False,
window_size=14, pad_mode="constant", layer_scale=False, with_cp=False):
super().__init__()
self.with_cp = with_cp
self.norm1 = norm_layer(dim)
if windowed:
self.attn = WindowedAttention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop,
proj_drop=drop, window_size=window_size, pad_mode=pad_mode)
else:
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.layer_scale = layer_scale
if layer_scale:
self.gamma1 = nn.Parameter(torch.ones((dim)), requires_grad=True)
self.gamma2 = nn.Parameter(torch.ones((dim)), requires_grad=True)
def forward(self, x, H, W):
def _inner_forward(x):
if self.layer_scale:
x = x + self.drop_path(self.gamma1 * self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.gamma2 * self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
if self.with_cp and x.requires_grad:
x = cp.checkpoint(_inner_forward, x)
else:
x = _inner_forward(x)
return x
这是一个PyTorch实现的Vision Transformer模型。Vision Transformer是一种用于图像分类的深度学习模型,其基本思想是将图像分成一组固定大小的图像块,并将每个图像块转换为一个向量,然后使用Transformer模型将这些向量组合起来以生成整张图像的分类结果。
该模型的核心是一个基于Transformer的块,其中包含一个自注意力层和一个前馈神经网络层。该模型还包括一个Patch Embedding层,用于将输入图像分成一组固定大小的图像块,并将每个图像块转换为一个向量。该模型还包括一个位置嵌入层,用于为每个图像块添加位置信息。最后,该模型还包括一个分类头,用于将Transformer输出的向量映射到类别概率空间中。
该模型的构造函数接受多个参数,包括输入图像大小,图像块大小,嵌入维度,Transformer深度,注意力头数,MLP隐藏层大小比例等。该模型还支持使用预训练权重进行初始化。
该模型的前向传播函数接受输入张量x,并首先将其传递给Patch Embedding层,然后将位置嵌入添加到结果中,并对结果进行dropout处理。接下来,该模型将结果传递给一系列基于Transformer的块,然后将结果传递给最终的分类头。
class TIMMVisionTransformer(BaseModule):
"""Vision Transformer.
A PyTorch impl of : `An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale`
- https://arxiv.org/abs/2010.11929
Includes distillation token & head support for `DeiT: Data-efficient Image Transformers`
- https://arxiv.org/abs/2012.12877
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000,
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., layer_scale=True,
embed_layer=PatchEmbed, norm_layer=partial(nn.LayerNorm, eps=1e-6),
act_layer=nn.GELU, window_attn=False, window_size=14, pretrained=None,
with_cp=False):
"""
Args:
img_size (int, tuple): input image size
patch_size (int, tuple): patch size
in_chans (int): number of input channels
num_classes (int): number of classes for classification head
embed_dim (int): embedding dimension
depth (int): depth of transformer
num_heads (int): number of attention heads
mlp_ratio (int): ratio of mlp hidden dim to embedding dim
qkv_bias (bool): enable bias for qkv if True
drop_rate (float): dropout rate
attn_drop_rate (float): attention dropout rate
drop_path_rate (float): stochastic depth rate
embed_layer (nn.Module): patch embedding layer
norm_layer: (nn.Module): normalization layer
pretrained: (str): pretrained path
"""
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.num_tokens = 1
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
act_layer = act_layer or nn.GELU
self.norm_layer = norm_layer
self.act_layer = act_layer
self.pretrain_size = img_size
self.drop_path_rate = drop_path_rate
self.drop_rate = drop_rate
window_attn = [window_attn] * depth if not isinstance(window_attn, list) else window_attn
window_size = [window_size] * depth if not isinstance(window_size, list) else window_size
logging.info("window attention:", window_attn)
logging.info("window size:", window_size)
logging.info("layer scale:", layer_scale)
self.patch_embed = embed_layer(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.Sequential(*[
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer,
windowed=window_attn[i], window_size=window_size[i], layer_scale=layer_scale, with_cp=with_cp)
for i in range(depth)])
self.init_weights(pretrained)
def init_weights(self, pretrained=None):
if isinstance(pretrained, str):
logger = get_root_logger()
load_checkpoint(self, pretrained, map_location='cpu', strict=False, logger=logger)
def forward_features(self, x):
x, H, W = self.patch_embed(x)
cls_token = self.cls_token.expand(x.shape[0], -1, -1) # stole cls_tokens impl from Phil Wang, thanks
x = torch.cat((cls_token, x), dim=1)
x = self.pos_drop(x + self.pos_embed)
for blk in self.blocks:
x = blk(x, H, W)
x = self.norm(x)
return x
def forward(self, x):
x = self.forward_features(x)
return x
backbones 骨干网络
adapter_modules.py
这段代码定义了 ConvFFN 类,它实现了一个具有卷积层的前馈神经网络。该网络由一个线性层、一个深度可分离卷积层、一个激活函数、另一个线性层和一个 dropout 层组成。
ConvFFN 类构造函数接受以下参数:
in_features:输入特征的数量hidden_features:隐藏特征的数量;如果为None,则默认为in_featuresout_features:输出特征的数量;如果为None,则默认为in_featuresact_layer:要使用的激活函数;默认为nn.GELUdrop:dropout 概率;默认为0.
forward 方法接受以下参数:
x:形状为(batch_size, in_features)的输入张量H:输入张量的高度W:输入张量的宽度
该方法将线性层应用于输入张量,然后是具有内核大小 (H, W) 的深度可分离卷积层、激活函数、第二个线性层和 dropout。输出张量的形状为 (batch_size, out_features)。
请注意,DWConv 类在此代码片段中未定义,并且可能在其他地方实现。
import logging
from functools import partial
import torch
import torch.nn as nn
import torch.utils.checkpoint as cp
from ops.modules import MSDeformAttn
from timm.models.layers import DropPath
_logger = logging.getLogger(__name__)
def get_reference_points(spatial_shapes, device):
reference_points_list = []
for lvl, (H_, W_) in enumerate(spatial_shapes):
ref_y, ref_x = torch.meshgrid(
torch.linspace(0.5, H_ - 0.5, H_, dtype=torch.float32, device=device),
torch.linspace(0.5, W_ - 0.5, W_, dtype=torch.float32, device=device))
ref_y = ref_y.reshape(-1)[None] / H_
ref_x = ref_x.reshape(-1)[None] / W_
ref = torch.stack((ref_x, ref_y), -1)
reference_points_list.append(ref)
reference_points = torch.cat(reference_points_list, 1)
reference_points = reference_points[:, :, None]
return reference_points
def deform_inputs(x):
bs, c, h, w = x.shape
spatial_shapes = torch.as_tensor([(h // 8, w // 8),
(h // 16, w // 16),
(h // 32, w // 32)],
dtype=torch.long, device=x.device)
level_start_index = torch.cat((spatial_shapes.new_zeros(
(1,)), spatial_shapes.prod(1).cumsum(0)[:-1]))
reference_points = get_reference_points([(h // 16, w // 16)], x.device)
deform_inputs1 = [reference_points, spatial_shapes, level_start_index]
spatial_shapes = torch.as_tensor([(h // 16, w // 16)], dtype=torch.long, device=x.device)
level_start_index = torch.cat((spatial_shapes.new_zeros(
(1,)), spatial_shapes.prod(1).cumsum(0)[:-1]))
reference_points = get_reference_points([(h // 8, w // 8),
(h // 16, w // 16),
(h // 32, w // 32)], x.device)
deform_inputs2 = [reference_points, spatial_shapes, level_start_index]
return deform_inputs1, deform_inputs2
class ConvFFN(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None,
act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x, H, W):
x = self.fc1(x)
x = self.dwconv(x, H, W)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
该代码定义了一个深度可分离卷积层 DWConv 类。深度可分离卷积层是一种轻量级卷积层,它将卷积操作分解为两个步骤:深度卷积和逐点卷积。这种卷积层通常用于在计算资源有限的情况下加速模型的训练和推理。
DWConv 类构造函数接受一个参数:
dim:输入张量的通道数
DWConv 类的 forward 方法接受三个参数:
x:形状为(batch_size, sequence_length, dim)的输入张量H:输入张量的高度W:输入张量的宽度
该方法首先将输入张量分成三个部分,分别对应于输出张量的三个部分。然后,它将每个部分转置、重塑为 (batch_size, dim, H', W') 的形状,其中 H' 和 W' 分别是输入张量高度和宽度的一半、两倍和相同的值。接下来,该方法对每个部分应用深度可分离卷积层,并将结果拼接在一起。最终输出张量的形状为 (batch_size, 3 * dim, sequence_length / 21)。
请注意,该代码实现了一个特定的序列分割方式,其中输入序列被分成三个部分,分别对应于输出张量的三个部分。这种分割方式可能是为了在特定的任务中获得更好的性能而设计的。
class DWConv(nn.Module):
def __init__(self, dim=768):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x, H, W):
B, N, C = x.shape
n = N // 21
x1 = x[:, 0:16 * n, :].transpose(1, 2).view(B, C, H * 2, W * 2).contiguous()
x2 = x[:, 16 * n:20 * n, :].transpose(1, 2).view(B, C, H, W).contiguous()
x3 = x[:, 20 * n:, :].transpose(1, 2).view(B, C, H // 2, W // 2).contiguous()
x1 = self.dwconv(x1).flatten(2).transpose(1, 2)
x2 = self.dwconv(x2).flatten(2).transpose(1, 2)
x3 = self.dwconv(x3).flatten(2).transpose(1, 2)
x = torch.cat([x1, x2, x3], dim=1)
return x
这段代码定义了 Extractor 类,它实现了一个特征提取器模块,用于计算查询向量在给定特征图和参考点的条件下的注意力权重。该模块由一个多尺度变形注意力层和一个可选的前馈神经网络层组成。
Extractor 类构造函数接受以下参数:
dim:输入张量的特征维度num_heads:注意力头的数量;默认为6n_points:每个头使用的采样点数;默认为4n_levels:金字塔级数;默认为1deform_ratio:变形卷积的变形比率;默认为1.0with_cffn:是否使用前馈神经网络层;默认为Truecffn_ratio:前馈神经网络层中隐藏特征的比率;默认为0.25drop:dropout 概率;默认为0.drop_path:DropPath 概率;默认为0.norm_layer:要使用的归一化层;默认为nn.LayerNormwith_cp:是否启用 Checkpointing 技术;默认为False
forward 方法接受以下参数:
query:形状为(batch_size, dim)的查询向量reference_points:形状为(batch_size, n_heads * n_points, 2)的参考点张量feat:形状为(batch_size, channels, height, width)的特征张量spatial_shapes:金字塔每个级别的空间尺寸的列表level_start_index:每个级别在参考点张量中的起始索引的列表H:输入特征张量的高度W:输入特征张量的宽度
该方法首先对查询向量进行归一化,然后使用多尺度变形注意力层计算注意力权重,并将它们应用于查询向量。然后,如果启用了前馈神经网络层,该方法将应用前馈神经网络层。最后,该方法返回计算后的查询向量。
请注意,如果启用了 Checkpointing 技术,则该方法将使用 torch.utils.checkpoint.checkpoint 函数对 _inner_forward 函数进行检查点,以减少内存消耗。
class Extractor(nn.Module):
def __init__(self, dim, num_heads=6, n_points=4, n_levels=1, deform_ratio=1.0,
with_cffn=True, cffn_ratio=0.25, drop=0., drop_path=0.,
norm_layer=partial(nn.LayerNorm, eps=1e-6), with_cp=False):
super().__init__()
self.query_norm = norm_layer(dim)
self.feat_norm = norm_layer(dim)
self.attn = MSDeformAttn(d_model=dim, n_levels=n_levels, n_heads=num_heads,
n_points=n_points, ratio=deform_ratio)
self.with_cffn = with_cffn
self.with_cp = with_cp
if with_cffn:
self.ffn = ConvFFN(in_features=dim, hidden_features=int(dim * cffn_ratio), drop=drop)
self.ffn_norm = norm_layer(dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, query, reference_points, feat, spatial_shapes, level_start_index, H, W):
def _inner_forward(query, feat):
attn = self.attn(self.query_norm(query), reference_points,
self.feat_norm(feat), spatial_shapes,
level_start_index, None)
query = query + attn
if self.with_cffn:
query = query + self.drop_path(self.ffn(self.ffn_norm(query), H, W))
return query
if self.with_cp and query.requires_grad:
query = cp.checkpoint(_inner_forward, query, feat)
else:
query = _inner_forward(query, feat)
return query
这段代码定义了 Injector 类,它实现了一个注入器模块,用于计算查询向量在给定特征图和参考点的条件下的注意力权重,并将其与查询向量相加。该模块由一个多尺度变形注意力层和一个可学习的缩放因子组成。
Injector 类构造函数接受以下参数:
dim:输入张量的特征维度num_heads:注意力头的数量;默认为6n_points:每个头使用的采样点数;默认为4n_levels:金字塔级数;默认为1deform_ratio:变形卷积的变形比率;默认为1.0norm_layer:要使用的归一化层;默认为nn.LayerNorminit_values:用于初始化缩放因子的值;默认为0.with_cp:是否启用 Checkpointing 技术;默认为False
forward 方法接受以下参数:
query:形状为(batch_size, dim)的查询向量reference_points:形状为(batch_size, n_heads * n_points, 2)的参考点张量feat:形状为(batch_size, channels, height, width)的特征张量spatial_shapes:金字塔每个级别的空间尺寸的列表level_start_index:每个级别在参考点张量中的起始索引的列表
该方法首先对查询向量进行归一化,然后使用多尺度变形注意力层计算注意力权重,并将其乘以一个可学习的缩放因子。最后,该方法将计算得到的注意力向量与查询向量相加。注意力向量的缩放因子由一个可学习的参数 self.gamma 控制。
请注意,如果启用了 Checkpointing 技术,则该方法将使用 torch.utils.checkpoint.checkpoint 函数对 _inner_forward 函数进行检查点,以减少内存消耗。
class Injector(nn.Module):
def __init__(self, dim, num_heads=6, n_points=4, n_levels=1, deform_ratio=1.0,
norm_layer=partial(nn.LayerNorm, eps=1e-6), init_values=0., with_cp=False):
super().__init__()
self.with_cp = with_cp
self.query_norm = norm_layer(dim)
self.feat_norm = norm_layer(dim)
self.attn = MSDeformAttn(d_model=dim, n_levels=n_levels, n_heads=num_heads,
n_points=n_points, ratio=deform_ratio)
self.gamma = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
def forward(self, query, reference_points, feat, spatial_shapes, level_start_index):
def _inner_forward(query, feat):
attn = self.attn(self.query_norm(query), reference_points,
self.feat_norm(feat), spatial_shapes,
level_start_index, None)
return query + self.gamma * attn
if self.with_cp and query.requires_grad:
query = cp.checkpoint(_inner_forward, query, feat)
else:
query = _inner_forward(query, feat)
return query
这段代码定义了 InteractionBlock 类,它实现了一个交互块模块。该模块包含了一个注入器和一个提取器,其中注入器用于计算查询向量在给定特征图和参考点的条件下的注意力权重,并将其与查询向量相加,提取器用于从特征图中提取特征。
InteractionBlock 类构造函数接受以下参数:
dim:输入张量的特征维度num_heads:注意力头的数量;默认为6n_points:每个头使用的采样点数;默认为4norm_layer:要使用的归一化层;默认为nn.LayerNormdrop:Dropout 概率;默认为0.drop_path:DropPath 概率;默认为0.with_cffn:是否启用 Cross-Feature-Map Fusion 网络;默认为Truecffn_ratio:Cross-Feature-Map Fusion 网络的比率;默认为0.25init_values:用于初始化缩放因子的值;默认为0.deform_ratio:变形卷积的变形比率;默认为1.0extra_extractor:是否使用额外的提取器;默认为Falsewith_cp:是否启用 Checkpointing 技术;默认为False
forward 方法接受以下参数:
x:形状为(batch_size, dim)的查询向量c:形状为(batch_size, channels, height, width)的特征张量blocks:由多个基础块组成的列表deform_inputs1:注入器所需的输入参数的元组,包括参考点、空间尺寸和起始索引deform_inputs2:提取器所需的输入参数的元组,包括参考点、空间尺寸和起始索引H:特征图的高度W:特征图的宽度
该方法首先使用注入器将查询向量注入到特征图中,得到一个新的查询向量。然后,该方法使用多个基础块对查询向量进行处理,并返回最终的查询向量。接下来,该方法使用提取器从特征张量中提取特征,并返回提取的特征。如果启用了额外的提取器,则继续使用额外的提取器从特征张量中提取特征,并将提取的特征添加到之前提取的特征中。最后,该方法返回注入后的查询向量和提取的特征。
class InteractionBlock(nn.Module):
def __init__(self, dim, num_heads=6, n_points=4, norm_layer=partial(nn.LayerNorm, eps=1e-6),
drop=0., drop_path=0., with_cffn=True, cffn_ratio=0.25, init_values=0.,
deform_ratio=1.0, extra_extractor=False, with_cp=False):
super().__init__()
self.injector = Injector(dim=dim, n_levels=3, num_heads=num_heads, init_values=init_values,
n_points=n_points, norm_layer=norm_layer, deform_ratio=deform_ratio,
with_cp=with_cp)
self.extractor = Extractor(dim=dim, n_levels=1, num_heads=num_heads, n_points=n_points,
norm_layer=norm_layer, deform_ratio=deform_ratio, with_cffn=with_cffn,
cffn_ratio=cffn_ratio, drop=drop, drop_path=drop_path, with_cp=with_cp)
if extra_extractor:
self.extra_extractors = nn.Sequential(*[
Extractor(dim=dim, num_heads=num_heads, n_points=n_points, norm_layer=norm_layer,
with_cffn=with_cffn, cffn_ratio=cffn_ratio, deform_ratio=deform_ratio,
drop=drop, drop_path=drop_path, with_cp=with_cp)
for _ in range(2)
])
else:
self.extra_extractors = None
def forward(self, x, c, blocks, deform_inputs1, deform_inputs2, H, W):
x = self.injector(query=x, reference_points=deform_inputs1[0],
feat=c, spatial_shapes=deform_inputs1[1],
level_start_index=deform_inputs1[2])
for idx, blk in enumerate(blocks):
x = blk(x, H, W)
c = self.extractor(query=c, reference_points=deform_inputs2[0],
feat=x, spatial_shapes=deform_inputs2[1],
level_start_index=deform_inputs2[2], H=H, W=W)
if self.extra_extractors is not None:
for extractor in self.extra_extractors:
c = extractor(query=c, reference_points=deform_inputs2[0],
feat=x, spatial_shapes=deform_inputs2[1],
level_start_index=deform_inputs2[2], H=H, W=W)
return x, c
class InteractionBlockWithCls(nn.Module):
def __init__(self, dim, num_heads=6, n_points=4, norm_layer=partial(nn.LayerNorm, eps=1e-6),
drop=0., drop_path=0., with_cffn=True, cffn_ratio=0.25, init_values=0.,
deform_ratio=1.0, extra_extractor=False, with_cp=False):
super().__init__()
self.injector = Injector(dim=dim, n_levels=3, num_heads=num_heads, init_values=init_values,
n_points=n_points, norm_layer=norm_layer, deform_ratio=deform_ratio,
with_cp=with_cp)
self.extractor = Extractor(dim=dim, n_levels=1, num_heads=num_heads, n_points=n_points,
norm_layer=norm_layer, deform_ratio=deform_ratio, with_cffn=with_cffn,
cffn_ratio=cffn_ratio, drop=drop, drop_path=drop_path, with_cp=with_cp)
if extra_extractor:
self.extra_extractors = nn.Sequential(*[
Extractor(dim=dim, num_heads=num_heads, n_points=n_points, norm_layer=norm_layer,
with_cffn=with_cffn, cffn_ratio=cffn_ratio, deform_ratio=deform_ratio,
drop=drop, drop_path=drop_path, with_cp=with_cp)
for _ in range(2)
])
else:
self.extra_extractors = None
def forward(self, x, c, cls, blocks, deform_inputs1, deform_inputs2, H, W):
x = self.injector(query=x, reference_points=deform_inputs1[0],
feat=c, spatial_shapes=deform_inputs1[1],
level_start_index=deform_inputs1[2])
x = torch.cat((cls, x), dim=1)
for idx, blk in enumerate(blocks):
x = blk(x, H, W)
cls, x = x[:, :1, ], x[:, 1:, ]
c = self.extractor(query=c, reference_points=deform_inputs2[0],
feat=x, spatial_shapes=deform_inputs2[1],
level_start_index=deform_inputs2[2], H=H, W=W)
if self.extra_extractors is not None:
for extractor in self.extra_extractors:
c = extractor(query=c, reference_points=deform_inputs2[0],
feat=x, spatial_shapes=deform_inputs2[1],
level_start_index=deform_inputs2[2], H=H, W=W)
return x, c, cls
这段代码定义了一个带有分类令牌(CLS)的交互块,用于在基于Transformer的神经网络中使用。该块由一个注入器模块、一个提取器模块和可能的额外提取器模块组成,具体取决于extra_extractor参数的值。
在前向传播过程中,将x张量通过注入器模块,并附加额外的输入c和deform_inputs1。将结果张量与CLS令牌连接起来,然后将其通过一系列blocks。将结果张量拆分成两个张量:cls,其中包含CLS令牌,以及x,其中包含其余输出。然后使用附加输入x和deform_inputs2将c张量通过提取器模块。如果extra_extractor为True,则还会将c张量传递给其他提取器模块。块的最终输出是包含x、c和cls的元组。
num_heads,n_points,norm_layer,drop,drop_path,with_cffn,cffn_ratio,init_values,deform_ratio,extra_extractor和with_cp参数控制块的各个方面的行为,例如注意力头的数量,每个特征图采样点的数量,所使用的归一化层的类型,dropout 的数量,是否存在交叉形式前馈网络(CFFN)以及 CFFN 隐藏大小与输入大小之比。
class SpatialPriorModule(nn.Module):
def __init__(self, inplanes=64, embed_dim=384, with_cp=False):
super().__init__()
self.with_cp = with_cp
self.stem = nn.Sequential(*[
nn.Conv2d(3, inplanes, kernel_size=3, stride=2, padding=1, bias=False),
nn.SyncBatchNorm(inplanes),
nn.ReLU(inplace=True),
nn.Conv2d(inplanes, inplanes, kernel_size=3, stride=1, padding=1, bias=False),
nn.SyncBatchNorm(inplanes),
nn.ReLU(inplace=True),
nn.Conv2d(inplanes, inplanes, kernel_size=3, stride=1, padding=1, bias=False),
nn.SyncBatchNorm(inplanes),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
])
self.conv2 = nn.Sequential(*[
nn.Conv2d(inplanes, 2 * inplanes, kernel_size=3, stride=2, padding=1, bias=False),
nn.SyncBatchNorm(2 * inplanes),
nn.ReLU(inplace=True)
])
self.conv3 = nn.Sequential(*[
nn.Conv2d(2 * inplanes, 4 * inplanes, kernel_size=3, stride=2, padding=1, bias=False),
nn.SyncBatchNorm(4 * inplanes),
nn.ReLU(inplace=True)
])
self.conv4 = nn.Sequential(*[
nn.Conv2d(4 * inplanes, 4 * inplanes, kernel_size=3, stride=2, padding=1, bias=False),
nn.SyncBatchNorm(4 * inplanes),
nn.ReLU(inplace=True)
])
self.fc1 = nn.Conv2d(inplanes, embed_dim, kernel_size=1, stride=1, padding=0, bias=True)
self.fc2 = nn.Conv2d(2 * inplanes, embed_dim, kernel_size=1, stride=1, padding=0, bias=True)
self.fc3 = nn.Conv2d(4 * inplanes, embed_dim, kernel_size=1, stride=1, padding=0, bias=True)
self.fc4 = nn.Conv2d(4 * inplanes, embed_dim, kernel_size=1, stride=1, padding=0, bias=True)
def forward(self, x):
def _inner_forward(x):
c1 = self.stem(x)
c2 = self.conv2(c1)
c3 = self.conv3(c2)
c4 = self.conv4(c3)
c1 = self.fc1(c1)
c2 = self.fc2(c2)
c3 = self.fc3(c3)
c4 = self.fc4(c4)
bs, dim, _, _ = c1.shape
# c1 = c1.view(bs, dim, -1).transpose(1, 2) # 4s
c2 = c2.view(bs, dim, -1).transpose(1, 2) # 8s
c3 = c3.view(bs, dim, -1).transpose(1, 2) # 16s
c4 = c4.view(bs, dim, -1).transpose(1, 2) # 32s
return c1, c2, c3, c4
if self.with_cp and x.requires_grad:
outs = cp.checkpoint(_inner_forward, x)
else:
outs = _inner_forward(x)
return outs
这是BEiTAdapter的PyTorch实现,它是BEiT(Bottleneck Transformers for Visual Recognition)骨干网络的修改版本。BEiTAdapter骨干网络包括额外的模块,如空间先验模块(SPM)和交互块。
SPM模块从输入图像中提取空间特征,并在不同的层级上生成四个特征图。交互块模块应用于BEiT骨干网络的输出,并在SPM模块的特征和BEiT骨干网络的特征之间引入空间交互。
该骨干网络接受输入图像并在不同的层级上产生四个特征图。输出特征图传递给后续层进行进一步处理。该骨干网络可用于各种计算机视觉任务,如目标检测、语义分割和图像分类。
beit_adapter.py
# Copyright (c) Shanghai AI Lab. All rights reserved.
import logging
import math
from functools import partial
import torch
import torch.nn as nn
import torch.nn.functional as F
from mmseg.models.builder import BACKBONES
from ops.modules import MSDeformAttn
from timm.models.layers import DropPath, trunc_normal_
from torch.nn.init import normal_
from .base.beit import BEiT
from .adapter_modules import SpatialPriorModule, deform_inputs
from .adapter_modules import InteractionBlockWithCls as InteractionBlock
_logger = logging.getLogger(__name__)
@BACKBONES.register_module()
class BEiTAdapter(BEiT):
def __init__(self, pretrain_size=224, conv_inplane=64, n_points=4, deform_num_heads=6,
init_values=0., cffn_ratio=0.25, deform_ratio=1.0, with_cffn=True,
interaction_indexes=None, add_vit_feature=True, with_cp=False, *args, **kwargs):
super().__init__(init_values=init_values, with_cp=with_cp, *args, **kwargs)
# self.num_classes = 80
# self.cls_token = None
self.num_block = len(self.blocks)
self.pretrain_size = (pretrain_size, pretrain_size)
self.flags = [i for i in range(-1, self.num_block, self.num_block // 4)][1:]
self.interaction_indexes = interaction_indexes
self.add_vit_feature = add_vit_feature
embed_dim = self.embed_dim
self.level_embed = nn.Parameter(torch.zeros(3, embed_dim))
self.spm = SpatialPriorModule(inplanes=conv_inplane, embed_dim=embed_dim, with_cp=False)
self.interactions = nn.Sequential(*[
InteractionBlock(dim=embed_dim, num_heads=deform_num_heads, n_points=n_points,
init_values=init_values, drop_path=self.drop_path_rate,
norm_layer=self.norm_layer, with_cffn=with_cffn,
cffn_ratio=cffn_ratio, deform_ratio=deform_ratio,
extra_extractor=True if i == len(interaction_indexes) - 1 else False,
with_cp=with_cp)
for i in range(len(interaction_indexes))
])
self.up = nn.ConvTranspose2d(embed_dim, embed_dim, 2, 2)
self.norm1 = nn.SyncBatchNorm(embed_dim)
self.norm2 = nn.SyncBatchNorm(embed_dim)
self.norm3 = nn.SyncBatchNorm(embed_dim)
self.norm4 = nn.SyncBatchNorm(embed_dim)
self.up.apply(self._init_weights)
self.spm.apply(self._init_weights)
self.interactions.apply(self._init_weights)
self.apply(self._init_deform_weights)
normal_(self.level_embed)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm) or isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def _get_pos_embed(self, pos_embed, H, W):
pos_embed = pos_embed.reshape(
1, self.pretrain_size[0] // 16, self.pretrain_size[1] // 16, -1).permute(0, 3, 1, 2)
pos_embed = F.interpolate(pos_embed, size=(H, W), mode='bicubic', align_corners=False).\
reshape(1, -1, H * W).permute(0, 2, 1)
return pos_embed
def _init_deform_weights(self, m):
if isinstance(m, MSDeformAttn):
m._reset_parameters()
def _add_level_embed(self, c2, c3, c4):
c2 = c2 + self.level_embed[0]
c3 = c3 + self.level_embed[1]
c4 = c4 + self.level_embed[2]
return c2, c3, c4
def forward(self, x):
deform_inputs1, deform_inputs2 = deform_inputs(x)
# SPM forward
c1, c2, c3, c4 = self.spm(x)
c2, c3, c4 = self._add_level_embed(c2, c3, c4)
c = torch.cat([c2, c3, c4], dim=1)
# Patch Embedding forward
x, H, W = self.patch_embed(x)
bs, n, dim = x.shape
cls = self.cls_token.expand(bs, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
if self.pos_embed is not None:
pos_embed = self._get_pos_embed(self.pos_embed, H, W)
x = x + pos_embed
x = self.pos_drop(x)
# Interaction
outs = list()
for i, layer in enumerate(self.interactions):
indexes = self.interaction_indexes[i]
x, c, cls = layer(x, c, cls, self.blocks[indexes[0]:indexes[-1] + 1],
deform_inputs1, deform_inputs2, H, W)
outs.append(x.transpose(1, 2).view(bs, dim, H, W).contiguous())
# Split & Reshape
c2 = c[:, 0:c2.size(1), :]
c3 = c[:, c2.size(1):c2.size(1) + c3.size(1), :]
c4 = c[:, c2.size(1) + c3.size(1):, :]
c2 = c2.transpose(1, 2).view(bs, dim, H * 2, W * 2).contiguous()
c3 = c3.transpose(1, 2).view(bs, dim, H, W).contiguous()
c4 = c4.transpose(1, 2).view(bs, dim, H // 2, W // 2).contiguous()
c1 = self.up(c2) + c1
if self.add_vit_feature:
x1, x2, x3, x4 = outs
x1 = F.interpolate(x1, scale_factor=4, mode='bilinear', align_corners=False)
x2 = F.interpolate(x2, scale_factor=2, mode='bilinear', align_corners=False)
x4 = F.interpolate(x4, scale_factor=0.5, mode='bilinear', align_corners=False)
c1, c2, c3, c4 = c1 + x1, c2 + x2, c3 + x3, c4 + x4
# Final Norm
f1 = self.norm1(c1)
f2 = self.norm2(c2)
f3 = self.norm3(c3)
f4 = self.norm4(c4)
return [f1, f2, f3, f4]
beit_baseline
BeiT (Bottleneck Transformers for Visual Recognition)是一个基于Transformer架构的图像分类模型系列,由谷歌研究团队提出。其中,BeiT-Baseline是其中的一个模型,它具有以下特点:
-
使用了类似于ViT的分块策略将图像分为多个patch,并将每个patch视为一个序列,然后通过Transformer进行特征提取和分类。
-
与ViT不同的是,BeiT使用了一种新的基于bottleneck结构的Transformer编码器,可以减少计算和参数量。
-
Beit-Baseline使用了一个相对较小的模型,只有12个编码器层和约6600万个参数,但在多个图像分类基准数据集上的表现都非常出色,并且比现有的许多SOTA方法更快、更简单。
-
Beit-Baseline还使用了一种新的数据增强方法,称为RandAugment+Cutout,可以在不增加计算成本的情况下提高模型的性能。
总的来说,BeiT-Baseline是一种简单而有效的图像分类模型,可以在多个数据集上实现出色的性能,同时具有较小的计算和参数成本。
beit_baseline.py
这是一个PyTorch模块,用于实现DropPath(或称为Stochastic Depth)技术。DropPath是在残差网络的主路径中随机丢弃一些连接,以加强模型的正则化和防止过拟合。
该模块包含一个DropPath类,其中包含一个前向方法,用于在训练过程中应用DropPath技术。在前向方法中,输入张量x会被传递到drop_path函数中,该函数会在x的维度0上应用随机掩码,将一定比例的元素置为0。掩码的比例由drop_prob参数指定,drop_prob越大,丢弃的元素越多。
该模块还包含一个extra_repr方法,用于返回DropPath模块的额外描述信息,其中包括drop_prob参数的值。此方法用于打印模型的结构信息。
# --------------------------------------------------------
# BEIT: BERT Pre-Training of Image Transformers (https://arxiv.org/abs/2106.08254)
# Github source: https://github.com/microsoft/unilm/tree/master/beit
# Copyright (c) 2021 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# By Hangbo Bao
# Based on timm, mmseg, setr, xcit and swin code bases
# https://github.com/rwightman/pytorch-image-models/tree/master/timm
# https://github.com/fudan-zvg/SETR
# https://github.com/facebookresearch/xcit/
# https://github.com/microsoft/Swin-Transformer
# --------------------------------------------------------'
import math
from functools import partial
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
from mmcv_custom import load_checkpoint
from mmseg.models.builder import BACKBONES
from mmseg.utils import get_root_logger
from timm.models.layers import drop_path, to_2tuple, trunc_normal_
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of
residual blocks)."""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
def extra_repr(self) -> str:
return 'p={}'.format(self.drop_prob)
这是一个PyTorch模块,用于实现多层感知机(MLP)。MLP是一种常见的神经网络模型,它由多个全连接层组成,每个层之间都有一个非线性激活函数。
该模块包含一个Mlp类,其中包含一个初始化方法和一个前向方法。初始化方法接受输入特征数in_features、隐藏层特征数hidden_features、输出特征数out_features、激活函数act_layer和dropout比率drop作为参数。在初始化方法中,首先根据输入参数设置输出特征数和隐藏层特征数的默认值,然后创建两个全连接层,分别是fc1和fc2。在每个全连接层之间,使用激活函数act_layer进行非线性变换。最后,使用dropout层进行正则化。
前向方法接受输入张量x作为参数,首先通过fc1进行线性变换,然后使用激活函数进行非线性变换,接着使用fc2进行线性变换,最后使用dropout对输出进行正则化。该模块可以用于各种深度学习任务,如自然语言处理和计算机视觉。
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None,
act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
# x = self.drop(x)
# commit this for the original BERT implement
x = self.fc2(x)
x = self.drop(x)
return x
这段代码实现了一个带有相对位置编码的注意力机制。它的输入是一个形状为(B, N, C)的张量x,其中B表示batch size,N表示序列的长度,C表示每个位置的特征维度。输出是一个形状相同的张量,表示经过注意力机制后的特征。
在初始化方法中,需要指定注意力机制的参数,包括每个头的数量num_heads、每个头的维度head_dim、是否使用偏置项qkv_bias、缩放因子qk_scale、dropout概率attn_drop和proj_drop、窗口大小window_size以及每个头的维度attn_head_dim。初始化方法中定义了一个线性层self.qkv,用于将输入张量x映射到多个头。如果使用窗口化的相对位置编码,还需要定义一个形状为(num_relative_distance, num_heads)的张量self.relative_position_bias_table,其中num_relative_distance表示相对位置编码的数量。
在前向方法中,首先将输入张量x通过self.qkv线性层映射到多个头,然后将多个头的查询向量q、键向量k和值向量v分别提取出来,并进行缩放操作。之后,将查询向量q和键向量k进行点积操作,得到注意力分数attn。如果使用窗口化的相对位置编码,还需要将相对位置编码张量self.relative_position_bias_table加到注意力分数attn中。如果还有其他的相对位置编码,可以将它们加到attn中,如参数rel_pos_bias所示。然后,将attn进行softmax操作,得到权重分布,再将权重分布和值向量v进行加权求和,得到输出张量。最后,将输出张量通过self.proj线性层映射回原始特征维度,并进行dropout操作,得到最终的输出。
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., window_size=None, attn_head_dim=None):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
if attn_head_dim is not None:
head_dim = attn_head_dim
all_head_dim = head_dim * self.num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, all_head_dim * 3, bias=False)
if qkv_bias:
self.q_bias = nn.Parameter(torch.zeros(all_head_dim))
self.v_bias = nn.Parameter(torch.zeros(all_head_dim))
else:
self.q_bias = None
self.v_bias = None
if window_size:
self.window_size = window_size
self.num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
self.relative_position_bias_table = nn.Parameter(
torch.zeros(self.num_relative_distance, num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# cls to token & token 2 cls & cls to cls
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(window_size[0])
coords_w = torch.arange(window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += window_size[1] - 1
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
relative_position_index = \
torch.zeros(size=(window_size[0] * window_size[1] + 1,) * 2, dtype=relative_coords.dtype)
relative_position_index[1:, 1:] = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
relative_position_index[0, 0:] = self.num_relative_distance - 3
relative_position_index[0:, 0] = self.num_relative_distance - 2
relative_position_index[0, 0] = self.num_relative_distance - 1
self.register_buffer("relative_position_index", relative_position_index)
# trunc_normal_(self.relative_position_bias_table, std=.0)
else:
self.window_size = None
self.relative_position_bias_table = None
self.relative_position_index = None
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(all_head_dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, rel_pos_bias=None):
B, N, C = x.shape
qkv_bias = None
if self.q_bias is not None:
qkv_bias = torch.cat((self.q_bias, torch.zeros_like(self.v_bias, requires_grad=False), self.v_bias))
# qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
qkv = qkv.reshape(B, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
if self.relative_position_bias_table is not None:
relative_position_bias = \
self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1] + 1,
self.window_size[0] * self.window_size[1] + 1, -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if rel_pos_bias is not None:
attn = attn + rel_pos_bias
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
x = self.proj(x)
x = self.proj_drop(x)
return x
这段代码实现了一个带有相对位置编码的注意力机制。它的输入是一个形状为(B, N, C)的张量x,其中B表示batch size,N表示序列的长度,C表示每个位置的特征维度。输出是一个形状相同的张量,表示经过注意力机制后的特征。
在初始化方法中,需要指定注意力机制的参数,包括每个头的数量num_heads、每个头的维度head_dim、是否使用偏置项qkv_bias、缩放因子qk_scale、dropout概率attn_drop和proj_drop、窗口大小window_size以及每个头的维度attn_head_dim。初始化方法中定义了一个线性层self.qkv,用于将输入张量x映射到多个头。如果使用窗口化的相对位置编码,还需要定义一个形状为(num_relative_distance, num_heads)的张量self.relative_position_bias_table,其中num_relative_distance表示相对位置编码的数量。
在前向方法中,首先将输入张量x通过self.qkv线性层映射到多个头,然后将多个头的查询向量q、键向量k和值向量v分别提取出来,并进行缩放操作。之后,将查询向量q和键向量k进行点积操作,得到注意力分数attn。如果使用窗口化的相对位置编码,还需要将相对位置编码张量self.relative_position_bias_table加到注意力分数attn中。如果还有其他的相对位置编码,可以将它们加到attn中,如参数rel_pos_bias所示。然后,将attn进行softmax操作,得到权重分布,再将权重分布和值向量v进行加权求和,得到输出张量。最后,将输出张量通过self.proj线性层映射回原始特征维度,并进行dropout操作,得到最终的输出。
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., init_values=None, act_layer=nn.GELU, norm_layer=nn.LayerNorm,
window_size=None, attn_head_dim=None):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, window_size=window_size, attn_head_dim=attn_head_dim)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
if init_values is not None:
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
else:
self.gamma_1, self.gamma_2 = None, None
def forward(self, x, rel_pos_bias=None):
if self.gamma_1 is None:
x = x + self.drop_path(self.attn(self.norm1(x), rel_pos_bias=rel_pos_bias))
x = x + self.drop_path(self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x), rel_pos_bias=rel_pos_bias))
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.patch_shape = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x, **kwargs):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
# assert H == self.img_size[0] and W == self.img_size[1], \
# f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x)
Hp, Wp = x.shape[2], x.shape[3]
x = x.flatten(2).transpose(1, 2)
return x, (Hp, Wp)
class HybridEmbed(nn.Module):
""" CNN Feature Map Embedding
Extract feature map from CNN, flatten, project to embedding dim.
"""
def __init__(self, backbone, img_size=224, feature_size=None, in_chans=3, embed_dim=768):
super().__init__()
assert isinstance(backbone, nn.Module)
img_size = to_2tuple(img_size)
self.img_size = img_size
self.backbone = backbone
if feature_size is None:
with torch.no_grad():
# FIXME this is hacky, but most reliable way of determining the exact dim of the output feature
# map for all networks, the feature metadata has reliable channel and stride info, but using
# stride to calc feature dim requires info about padding of each stage that isn't captured.
training = backbone.training
if training:
backbone.eval()
o = self.backbone(torch.zeros(1, in_chans, img_size[0], img_size[1]))[-1]
feature_size = o.shape[-2:]
feature_dim = o.shape[1]
backbone.train(training)
else:
feature_size = to_2tuple(feature_size)
feature_dim = self.backbone.feature_info.channels()[-1]
self.num_patches = feature_size[0] * feature_size[1]
self.proj = nn.Linear(feature_dim, embed_dim)
def forward(self, x):
x = self.backbone(x)[-1]
x = x.flatten(2).transpose(1, 2)
x = self.proj(x)
return x
这是一个PyTorch模块,名为HybridEmbed,用于从CNN的特征图中提取特征并将其投影到嵌入维度。该模块接受以下参数:
- backbone (nn.Module): 一个CNN模型,用于从输入图像中提取特征。
- img_size (int or tuple): 输入图像的大小,可以是一个整数(表示宽度和高度相等),也可以是一个元组(表示宽度和高度)。
- feature_size (int or tuple): 特征图的大小,可以是一个整数(表示宽度和高度相等),也可以是一个元组(表示宽度和高度)。
- in_chans (int): 输入图像的通道数。
- embed_dim (int): 嵌入特征的维度。
在初始化时,该模块会根据传入的参数计算出特征图的大小,并创建一个线性层,用于将特征图投影到嵌入维度。在前向传播时,该模块首先使用CNN模型从输入图像中提取特征,然后将特征图展平并转置,最后通过线性层进行投影并返回嵌入特征。
class RelativePositionBias(nn.Module):
def __init__(self, window_size, num_heads):
super().__init__()
self.window_size = window_size
self.num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
self.relative_position_bias_table = nn.Parameter(
torch.zeros(self.num_relative_distance, num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# cls to token & token 2 cls & cls to cls
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(window_size[0])
coords_w = torch.arange(window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += window_size[1] - 1
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
relative_position_index = \
torch.zeros(size=(window_size[0] * window_size[1] + 1,) * 2, dtype=relative_coords.dtype)
relative_position_index[1:, 1:] = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
relative_position_index[0, 0:] = self.num_relative_distance - 3
relative_position_index[0:, 0] = self.num_relative_distance - 2
relative_position_index[0, 0] = self.num_relative_distance - 1
self.register_buffer("relative_position_index", relative_position_index)
# trunc_normal_(self.relative_position_bias_table, std=.02)
def forward(self):
relative_position_bias = \
self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1] + 1,
self.window_size[0] * self.window_size[1] + 1, -1) # Wh*Ww,Wh*Ww,nH
return relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
这是BEiT(Bottleneck Enhanced Information Transformer)模型的实现,它是图像分类的Vision Transformer(ViT)的变体。BEiT模型支持基于patch和混合CNN的输入阶段。该模型接受图像张量作为输入,通过一个patch嵌入层,然后通过一系列transformer块。某些块的输出可以用于特征提取。
BEiTBaseline类派生自nn.Module类,实现模型架构。构造函数采用多个参数,包括图像大小、patch大小、输入通道数、类别数、嵌入维度、transformer深度、头数、MLP比率、dropout率以及是否使用绝对或相对位置嵌入。forward_features方法实现了通过模型的前向传递到指定输出索引,返回特征映射。forward方法调用forward_features并将特征映射作为元组返回。
该模型还包括几个附加组件,包括可学习的分类令牌、位置嵌入和一系列应用于transformer块的正则化层。
@BACKBONES.register_module()
class BEiTBaseline(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=80, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., hybrid_backbone=None, norm_layer=None, init_values=None, with_cp=False,
use_abs_pos_emb=True, use_rel_pos_bias=False, use_shared_rel_pos_bias=False,
out_indices=[3, 5, 7, 11], pretrained=None):
super().__init__()
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
if hybrid_backbone is not None:
self.patch_embed = HybridEmbed(
hybrid_backbone, img_size=img_size, in_chans=in_chans, embed_dim=embed_dim)
else:
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.out_indices = out_indices
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# self.mask_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
if use_abs_pos_emb:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
else:
self.pos_embed = None
self.pos_drop = nn.Dropout(p=drop_rate)
if use_shared_rel_pos_bias:
self.rel_pos_bias = RelativePositionBias(window_size=self.patch_embed.patch_shape, num_heads=num_heads)
else:
self.rel_pos_bias = None
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.use_rel_pos_bias = use_rel_pos_bias
self.with_cp = with_cp
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
init_values=init_values, window_size=self.patch_embed.patch_shape if use_rel_pos_bias else None)
for i in range(depth)])
if self.pos_embed is not None:
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
# trunc_normal_(self.mask_token, std=.02)
self.out_indices = out_indices
if patch_size == 16:
self.fpn1 = nn.Sequential(
nn.ConvTranspose2d(embed_dim, embed_dim, kernel_size=2, stride=2),
nn.SyncBatchNorm(embed_dim),
nn.GELU(),
nn.ConvTranspose2d(embed_dim, embed_dim, kernel_size=2, stride=2),
)
self.fpn2 = nn.Sequential(
nn.ConvTranspose2d(embed_dim, embed_dim, kernel_size=2, stride=2),
)
self.fpn3 = nn.Identity()
self.fpn4 = nn.MaxPool2d(kernel_size=2, stride=2)
elif patch_size == 8:
self.fpn1 = nn.Sequential(
nn.ConvTranspose2d(embed_dim, embed_dim, kernel_size=2, stride=2),
)
self.fpn2 = nn.Identity()
self.fpn3 = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.fpn4 = nn.Sequential(
nn.MaxPool2d(kernel_size=4, stride=4),
)
self.apply(self._init_weights)
self.init_weights(pretrained)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def init_weights(self, pretrained=None):
"""Initialize the weights in backbone.
Args:
pretrained (str, optional): Path to pre-trained weights.
Defaults to None.
"""
if isinstance(pretrained, str):
logger = get_root_logger()
load_checkpoint(self, pretrained, strict=False, logger=logger)
def get_num_layers(self):
return len(self.blocks)
def forward_features(self, x):
B, C, H, W = x.shape
x, (Hp, Wp) = self.patch_embed(x)
batch_size, seq_len, _ = x.size()
cls_tokens = self.cls_token.expand(batch_size, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
x = torch.cat((cls_tokens, x), dim=1)
if self.pos_embed is not None:
x = x + self.pos_embed
x = self.pos_drop(x)
rel_pos_bias = self.rel_pos_bias() if self.rel_pos_bias is not None else None
features = []
for i, blk in enumerate(self.blocks):
if self.with_cp:
x = checkpoint.checkpoint(blk, x, rel_pos_bias)
else:
x = blk(x, rel_pos_bias)
if i in self.out_indices:
xp = x[:, 1:, :].permute(0, 2, 1).reshape(B, -1, Hp, Wp)
features.append(xp.contiguous())
ops = [self.fpn1, self.fpn2, self.fpn3, self.fpn4]
for i in range(len(features)):
features[i] = ops[i](features[i])
return tuple(features)
def forward(self, x):
x = self.forward_features(x)
return x
uniperceiver_adapter.py
这是一个用于图像分割的UniPerceiverAdapter模型的PyTorch实现,它是基于Unified Perceiver模型的变体。该模型包括一个空间先验模块、多个交互块和一个可选的ViT特征嵌入块。输入为图像张量,通过空间先验模块和ViT的嵌入块转换为特征张量,然后通过多个交互块进行特征提取。每个交互块都接收ViT嵌入和先前交互块的输出,然后返回新的特征张量。ViT嵌入和每个交互块的输出都被分割成四个不同的尺度,并通过上采样和下采样进行重构。最后,特征张量通过规范化层进行最终处理,然后返回作为列表的四个不同尺度。
该模型还包括一些额外的组件,例如形变注意力、SyncBatchNorm规范化层、学习嵌入和附加的交互块。构造函数接受多个超参数,例如图像预处理大小、头数、交互块数量等。
# Copyright (c) Shanghai AI Lab. All rights reserved.
import logging
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from mmseg.models.builder import BACKBONES
from ops.modules import MSDeformAttn
from timm.models.layers import DropPath, trunc_normal_
from torch.nn.init import normal_
from .base.uniperceiver import UnifiedBertEncoder
from .adapter_modules import SpatialPriorModule, InteractionBlock, deform_inputs
_logger = logging.getLogger(__name__)
@BACKBONES.register_module()
class UniPerceiverAdapter(UnifiedBertEncoder):
def __init__(self, pretrain_size=224, num_heads=12, conv_inplane=64, n_points=4,
deform_num_heads=6, init_values=0., with_cffn=True, cffn_ratio=0.25,
deform_ratio=1.0, add_vit_feature=True, interaction_indexes=None,
*args, **kwargs):
super().__init__(num_heads=num_heads, *args, **kwargs)
# self.num_classes = 80
self.cls_token = None
self.num_block = len(self.layers)
self.pretrain_size = (pretrain_size, pretrain_size)
self.interaction_indexes = interaction_indexes
self.add_vit_feature = add_vit_feature
embed_dim = self.embed_dim
self.level_embed = nn.Parameter(torch.zeros(3, embed_dim))
self.spm = SpatialPriorModule(inplanes=conv_inplane,
embed_dim=embed_dim)
self.interactions = nn.Sequential(*[
InteractionBlock(dim=embed_dim, num_heads=deform_num_heads, n_points=n_points,
init_values=init_values, drop_path=self.drop_path_rate,
norm_layer=self.norm_layer, with_cffn=with_cffn,
cffn_ratio=cffn_ratio, deform_ratio=deform_ratio,
extra_extractor=True if i == len(interaction_indexes) - 1 else False)
for i in range(len(interaction_indexes))
])
self.up = nn.ConvTranspose2d(embed_dim, embed_dim, 2, 2)
self.norm1 = nn.SyncBatchNorm(embed_dim)
self.norm2 = nn.SyncBatchNorm(embed_dim)
self.norm3 = nn.SyncBatchNorm(embed_dim)
self.norm4 = nn.SyncBatchNorm(embed_dim)
self.up.apply(self._init_weights)
self.spm.apply(self._init_weights)
self.interactions.apply(self._init_weights)
self.apply(self._init_deform_weights)
normal_(self.level_embed)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm) or isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def _init_deform_weights(self, m):
if isinstance(m, MSDeformAttn):
m._reset_parameters()
def _add_level_embed(self, c2, c3, c4):
c2 = c2 + self.level_embed[0]
c3 = c3 + self.level_embed[1]
c4 = c4 + self.level_embed[2]
return c2, c3, c4
def forward(self, x):
deform_inputs1, deform_inputs2 = deform_inputs(x)
# SPM forward
c1, c2, c3, c4 = self.spm(x)
c2, c3, c4 = self._add_level_embed(c2, c3, c4)
c = torch.cat([c2, c3, c4], dim=1)
# Patch Embedding forward
x, H, W = self.visual_embed(x)
bs, n, dim = x.shape
# Interaction
outs = list()
for i, layer in enumerate(self.interactions):
indexes = self.interaction_indexes[i]
x, c = layer(x, c, self.layers[indexes[0]:indexes[-1] + 1],
deform_inputs1, deform_inputs2, H, W)
outs.append(x.transpose(1, 2).view(bs, dim, H, W).contiguous())
# Split & Reshape
c2 = c[:, 0:c2.size(1), :]
c3 = c[:, c2.size(1):c2.size(1) + c3.size(1), :]
c4 = c[:, c2.size(1) + c3.size(1):, :]
c2 = c2.transpose(1, 2).view(bs, dim, H * 2, W * 2).contiguous()
c3 = c3.transpose(1, 2).view(bs, dim, H, W).contiguous()
c4 = c4.transpose(1, 2).view(bs, dim, H // 2, W // 2).contiguous()
c1 = self.up(c2) + c1
if self.add_vit_feature:
x1, x2, x3, x4 = outs
x1 = F.interpolate(x1, scale_factor=4, mode='bilinear', align_corners=False)
x2 = F.interpolate(x2, scale_factor=2, mode='bilinear', align_corners=False)
x4 = F.interpolate(x4, scale_factor=0.5, mode='bilinear', align_corners=False)
c1, c2, c3, c4 = c1 + x1, c2 + x2, c3 + x3, c4 + x4
# Final Norm
f1 = self.norm1(c1)
f2 = self.norm2(c2)
f3 = self.norm3(c3)
f4 = self.norm4(c4)
return [f1, f2, f3, f4]
vit_adapter.py
这是一个名为 “ViTAdapter” 的视觉Transformer主干网络的Python代码。它使用PyTorch实现,并在mmseg库中注册为一个主干模块。该主干网络基于Vision Transformer(ViT)架构,并包括其他模块来集成空间信息和不同特征图之间的交互。
代码定义了ViTAdapter类,该类继承自TIMMVisionTransformer类。TIMMVisionTransformer类在另一个模块中定义,并包含ViT架构的实现。
ViTAdapter类构造函数接受几个超参数,包括网络的输入大小、注意力头的数量、卷积层中的通道数、可变形注意力头的数量、可变形注意力头与总注意力头数的比率以及CFFN模块中通道数与输入通道数的比率。
该类定义了几个方法,包括_init_weights方法用于初始化网络权重、_get_pos_embed方法用于计算位置嵌入、_init_deform_weights方法用于初始化可变形注意力权重以及_add_level_embed方法用于向特征图添加级别嵌入。
类的前向方法_forward定义了网络的前向传递过程,其中包括ViT的标准前向传递以及其他模块的集成。最终,网络输出特征图,可以用于语义分割或其他计算机视觉任务。
# Copyright (c) Shanghai AI Lab. All rights reserved.
import logging
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from mmseg.models.builder import BACKBONES
from ops.modules import MSDeformAttn
from timm.models.layers import trunc_normal_
from torch.nn.init import normal_
from .base.vit import TIMMVisionTransformer
from .adapter_modules import SpatialPriorModule, InteractionBlock, deform_inputs
_logger = logging.getLogger(__name__)
@BACKBONES.register_module()
class ViTAdapter(TIMMVisionTransformer):
def __init__(self, pretrain_size=224, num_heads=12, conv_inplane=64, n_points=4,
deform_num_heads=6, init_values=0., interaction_indexes=None, with_cffn=True,
cffn_ratio=0.25, deform_ratio=1.0, add_vit_feature=True, pretrained=None,
use_extra_extractor=True, with_cp=False, *args, **kwargs):
super().__init__(num_heads=num_heads, pretrained=pretrained,
with_cp=with_cp, *args, **kwargs)
# self.num_classes = 80
self.cls_token = None
self.num_block = len(self.blocks)
self.pretrain_size = (pretrain_size, pretrain_size)
self.interaction_indexes = interaction_indexes
self.add_vit_feature = add_vit_feature
embed_dim = self.embed_dim
self.level_embed = nn.Parameter(torch.zeros(3, embed_dim))
self.spm = SpatialPriorModule(inplanes=conv_inplane, embed_dim=embed_dim, with_cp=False)
self.interactions = nn.Sequential(*[
InteractionBlock(dim=embed_dim, num_heads=deform_num_heads, n_points=n_points,
init_values=init_values, drop_path=self.drop_path_rate,
norm_layer=self.norm_layer, with_cffn=with_cffn,
cffn_ratio=cffn_ratio, deform_ratio=deform_ratio,
extra_extractor=((True if i == len(interaction_indexes) - 1
else False) and use_extra_extractor),
with_cp=with_cp)
for i in range(len(interaction_indexes))
])
self.up = nn.ConvTranspose2d(embed_dim, embed_dim, 2, 2)
self.norm1 = nn.SyncBatchNorm(embed_dim)
self.norm2 = nn.SyncBatchNorm(embed_dim)
self.norm3 = nn.SyncBatchNorm(embed_dim)
self.norm4 = nn.SyncBatchNorm(embed_dim)
self.up.apply(self._init_weights)
self.spm.apply(self._init_weights)
self.interactions.apply(self._init_weights)
self.apply(self._init_deform_weights)
normal_(self.level_embed)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm) or isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def _get_pos_embed(self, pos_embed, H, W):
pos_embed = pos_embed.reshape(
1, self.pretrain_size[0] // 16, self.pretrain_size[1] // 16, -1).permute(0, 3, 1, 2)
pos_embed = F.interpolate(pos_embed, size=(H, W), mode='bicubic', align_corners=False).\
reshape(1, -1, H * W).permute(0, 2, 1)
return pos_embed
def _init_deform_weights(self, m):
if isinstance(m, MSDeformAttn):
m._reset_parameters()
def _add_level_embed(self, c2, c3, c4):
c2 = c2 + self.level_embed[0]
c3 = c3 + self.level_embed[1]
c4 = c4 + self.level_embed[2]
return c2, c3, c4
def forward(self, x):
deform_inputs1, deform_inputs2 = deform_inputs(x)
# SPM forward
c1, c2, c3, c4 = self.spm(x)
c2, c3, c4 = self._add_level_embed(c2, c3, c4)
c = torch.cat([c2, c3, c4], dim=1)
# Patch Embedding forward
x, H, W = self.patch_embed(x)
bs, n, dim = x.shape
pos_embed = self._get_pos_embed(self.pos_embed[:, 1:], H, W)
x = self.pos_drop(x + pos_embed)
# Interaction
outs = list()
for i, layer in enumerate(self.interactions):
indexes = self.interaction_indexes[i]
x, c = layer(x, c, self.blocks[indexes[0]:indexes[-1] + 1],
deform_inputs1, deform_inputs2, H, W)
outs.append(x.transpose(1, 2).view(bs, dim, H, W).contiguous())
# Split & Reshape
c2 = c[:, 0:c2.size(1), :]
c3 = c[:, c2.size(1):c2.size(1) + c3.size(1), :]
c4 = c[:, c2.size(1) + c3.size(1):, :]
c2 = c2.transpose(1, 2).view(bs, dim, H * 2, W * 2).contiguous()
c3 = c3.transpose(1, 2).view(bs, dim, H, W).contiguous()
c4 = c4.transpose(1, 2).view(bs, dim, H // 2, W // 2).contiguous()
c1 = self.up(c2) + c1
if self.add_vit_feature:
x1, x2, x3, x4 = outs
x1 = F.interpolate(x1, scale_factor=4, mode='bilinear', align_corners=False)
x2 = F.interpolate(x2, scale_factor=2, mode='bilinear', align_corners=False)
x4 = F.interpolate(x4, scale_factor=0.5, mode='bilinear', align_corners=False)
c1, c2, c3, c4 = c1 + x1, c2 + x2, c3 + x3, c4 + x4
# Final Norm
f1 = self.norm1(c1)
f2 = self.norm2(c2)
f3 = self.norm3(c3)
f4 = self.norm4(c4)
return [f1, f2, f3, f4]
这段代码实现了一个视觉领域的神经网络模型,称为ViTAdapter,它是TIMM-Vision-Transformer模型的扩展版本。具体功能如下:
-
初始化函数中,定义了该模型的一些基本属性,如输入尺寸、注意力头数、卷积通道数、交互块的数量和位置等。同时,该函数调用了父类TIMMVisionTransformer的初始化函数,实现了继承。
-
forward函数实现了该模型的前向传播过程,包括以下步骤:
- 对输入图像进行空间金字塔池化(Spatial Prior Module,SPM),获取不同尺度的特征图c1, c2, c3, c4。
- 对输入图像进行patch embedding,获取序列形式的图像表示x,并且为x添加位置编码。同时,该函数还对位置编码进行插值操作,使其与特征图尺寸相匹配。
- 使用交互块对x和c进行交互,其中c来自于SPM模块输出的特征图,交互块利用MSDeformAttn模块实现了可变形注意力机制。
- 将交互块的输出进行分裂和重塑,使其与SPM模块输出的特征图c1, c2, c3, c4的尺寸相匹配。
- 将分裂后的特征图与SPM模块输出的特征图进行融合,其中融合方式包括上采样、下采样和插值等操作。
- 对融合后的特征图进行归一化处理。
总之,这段代码实现了一个基于ViT和可变形注意力机制的视觉神经网络模型,可以用于图像分类、目标检测和语义分割等任务。
vit_baseline.py
这是一个用于图像分割模型的 ViTBaseline 后骨干的 Python 模块,使用 PyTorch 实现。该后骨干基于 TIMM(PyTorch 图像模型)实现的 Vision Transformer(ViT)架构,这是一种用于图像分类的流行自注意力模型。
该实现通过在网络末尾添加四个上采样层扩展了 ViT 架构,这些层用于恢复在网络早期的下采样操作中丢失的分辨率。四个上采样层对应于 ViT 块产生的不同层次的特征图,并且在特征图通过层归一化之后应用于它们。
该模块定义了一个名为 ViTBaseline 的 PyTorch nn.Module 子类,该子类使用 mmseg 库中的 BACKBONES.register_module() 装饰器进行修饰。这允许将该后骨干用作更大的分割模型的构建块。
ViTBaseline 类的 __init__ 方法设置了后骨干的体系结构,包括使用的 ViT 块数、输入图像的大小以及 ViT 产生的嵌入向量的维数。该方法还设置了上采样层并使用截断正态分布初始化它们的权重。
init_weights 方法用于加载预训练权重到后骨干中,如果提供了权重。
forward_features 方法执行后骨干的前向传递,产生不同分辨率水平的特征图。该方法首先通过 ViT 块传递输入,然后将层归一化和上采样层应用于输出特征图。该方法返回一个上采样特征图列表,以及原始输入图像的高度和宽度。
forward 方法是一个方便的方法,它调用 forward_features 方法,然后返回上采样特征图列表。
# Copyright (c) Shanghai AI Lab. All rights reserved.
import logging
import math
import torch.nn as nn
import torch.nn.functional as F
from mmcv.runner import load_checkpoint
from mmseg.models.builder import BACKBONES
from mmseg.utils import get_root_logger
from timm.models.layers import trunc_normal_
from .base.vit import TIMMVisionTransformer
_logger = logging.getLogger(__name__)
@BACKBONES.register_module()
class ViTBaseline(TIMMVisionTransformer):
def __init__(self, pretrain_size=224, *args, **kwargs):
super().__init__(*args, **kwargs)
# self.num_classes = 80
self.cls_token = None
self.num_block = len(self.blocks)
self.pretrain_size = (pretrain_size, pretrain_size)
self.flags = [i for i in range(-1, self.num_block, self.num_block // 4)][1:]
embed_dim = self.embed_dim
self.norm1 = self.norm_layer(embed_dim)
self.norm2 = self.norm_layer(embed_dim)
self.norm3 = self.norm_layer(embed_dim)
self.norm4 = self.norm_layer(embed_dim)
self.up1 = nn.Sequential(*[
nn.ConvTranspose2d(embed_dim, embed_dim, 2, 2),
nn.GroupNorm(32, embed_dim),
nn.GELU(),
nn.ConvTranspose2d(embed_dim, embed_dim, 2, 2)
])
self.up2 = nn.ConvTranspose2d(embed_dim, embed_dim, 2, 2)
self.up3 = nn.Identity()
self.up4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.up1.apply(self._init_weights)
self.up2.apply(self._init_weights)
self.up3.apply(self._init_weights)
self.up4.apply(self._init_weights)
def init_weights(self, pretrained=None):
if isinstance(pretrained, str):
logger = get_root_logger()
load_checkpoint(self, pretrained, map_location='cpu', strict=False, logger=logger)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm) or isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def _get_pos_embed(self, pos_embed, H, W):
pos_embed = pos_embed.reshape(
1, self.pretrain_size[0] // 16, self.pretrain_size[1] // 16, -1).permute(0, 3, 1, 2)
pos_embed = F.interpolate(pos_embed, size=(H, W), mode='bicubic', align_corners=False).\
reshape(1, -1, H * W).permute(0, 2, 1)
return pos_embed
def forward_features(self, x):
outs = []
x, H, W = self.patch_embed(x)
pos_embed = self._get_pos_embed(self.pos_embed[:, 1:], H, W)
x = self.pos_drop(x + pos_embed)
for index, blk in enumerate(self.blocks):
x = blk(x, H, W)
if index in self.flags:
outs.append(x)
return outs, H, W
def forward(self, x):
outs, H, W = self.forward_features(x)
f1, f2, f3, f4 = outs
bs, n, dim = f1.shape
f1 = self.norm1(f1).transpose(1, 2).reshape(bs, dim, H, W)
f2 = self.norm2(f2).transpose(1, 2).reshape(bs, dim, H, W)
f3 = self.norm3(f3).transpose(1, 2).reshape(bs, dim, H, W)
f4 = self.norm4(f4).transpose(1, 2).reshape(bs, dim, H, W)
f1 = self.up1(f1).contiguous()
f2 = self.up2(f2).contiguous()
f3 = self.up3(f3).contiguous()
f4 = self.up4(f4).contiguous()
return [f1, f2, f3, f4]
decode_heads
mask2former_head.py
# Copyright (c) OpenMMLab. All rights reserved.
import copy
import torch
import torch.nn as nn
import torch.nn.functional as F
这行代码是从 mmcv.cnn 模块中导入了三个函数或类:Conv2d、build_plugin_layer 和 caffe2_xavier_init。
mmcv 是一个用于计算机视觉的开源工具箱,包含了很多常用的函数和类。cnn 模块提供了各种卷积神经网络(CNN)相关的函数和类。
Conv2d 是一个二维卷积层类,用于实现卷积神经网络中的卷积操作。它继承自 PyTorch 的 nn.Conv2d 类,并添加了一些额外的功能,例如支持从文件中读取预训练权重。
build_plugin_layer 是一个函数,用于构建 PyTorch 中的可插拔层(Plugin Layer)。可插拔层是一种灵活的机制,可以将自定义的层嵌入到现有的神经网络中,以实现各种特定的功能。
caffe2_xavier_init 是一个函数,用于使用 Xavier 初始化方法初始化权重。在深度学习中,初始化方法是非常重要的,可以影响神经网络的训练效果。Xavier 初始化方法是一种常用的初始化方法,可以使得神经网络的输出具有相同的方差,从而加速训练过程。
from mmcv.cnn import Conv2d, build_plugin_layer, caffe2_xavier_init
这行代码从 mmcv.cnn.bricks.transformer 模块中导入了两个函数:build_positional_encoding 和 build_transformer_layer_sequence。
mmcv 是一个用于计算机视觉的开源工具箱,cnn 模块提供了各种卷积神经网络(CNN)相关的函数和类,而 bricks 模块提供了一些常用的神经网络构建块。
transformer 模块中包含了用于构建 Transformer 模型的函数和类。Transformer 是一种用于自然语言处理和计算机视觉任务的深度学习模型,由 Vaswani 等人在 2017 年提出。
build_positional_encoding 是一个函数,用于构建位置编码层。在 Transformer 模型中,位置编码层用于将序列中每个位置的信息编码成一个向量,以便在注意力机制中使用。
build_transformer_layer_sequence 是一个函数,用于构建 Transformer 模型中的一个或多个 Transformer 层。Transformer 层是一个基本的计算单元,由多头注意力机制和前馈神经网络组成,可以堆叠多个层来构建深度的 Transformer 模型。该函数接受一些参数,例如 Transformer 层数、输入维度和头数(多头注意力机制中的头数)等,以便构建特定的 Transformer 模型。
from mmcv.cnn.bricks.transformer import (build_positional_encoding,
build_transformer_layer_sequence)
这行代码从 mmcv.ops 模块中导入了 point_sample 函数。
mmcv 是一个用于计算机视觉的开源工具箱,ops 模块提供了各种运算操作的实现。
point_sample 函数实现了双线性插值的点采样操作,用于将输入的特征图映射到指定的位置上。在计算机视觉中,点采样操作常用于实现空间变换网络(Spatial Transformer Network,STN),将输入图像进行旋转、缩放、平移等操作以适应特定的任务需求。该函数接受两个参数:输入特征图和采样位置,返回插值后的结果。
from mmcv.ops import point_sample
这行代码从 mmcv.runner 模块中导入了 ModuleList 和 force_fp32 两个类。
mmcv 是一个用于计算机视觉的开源工具箱,runner 模块提供了各种训练和测试深度学习模型的工具和类。
ModuleList 是一个 PyTorch 中的模块列表类,用于管理一组子模块。在深度学习模型中,经常需要使用多个子模块构建复杂的网络结构,ModuleList 可以方便地管理这些子模块,例如进行前向传播和反向传播等操作。
force_fp32 是一个装饰器,用于强制将输入的数据类型转换为 float32 类型。在深度学习模型中,数据类型的精度很重要,不同的精度对模型的训练和推理效果有很大的影响。使用 force_fp32 可以确保输入数据的精度与模型的精度匹配,从而避免精度损失带来的影响。
from mmcv.runner import ModuleList, force_fp32
这行代码从 mmseg.models.builder 模块中导入了 HEADS 和 build_loss 两个对象。
mmseg 是一个用于语义分割任务的开源工具箱,models 模块包含了各种用于构建图像分割模型的类和函数。
builder 模块提供了用于构建模型的工具函数和装饰器。
HEADS 是一个字典对象,用于存储不同类型的分割头(Segmentation Head),例如 FCNHead、PSPHead、DeepLabV3Head 等。分割头是神经网络中的一部分,用于将特征图转换为分割结果(例如像素级别的类别标签或边界框等)。
build_loss 是一个函数,用于构建损失函数。在深度学习中,损失函数用于衡量模型预测结果与真实标签之间的差距,是优化模型训练的关键。build_loss 函数接受一个参数 cfg,用于配置损失函数的类型、权重等参数,返回一个 PyTorch 中的损失函数对象。
from mmseg.models.builder import HEADS, build_loss
这行代码是从 mmseg.models.decode_heads.decode_head 模块中导入 BaseDecodeHead 类。
mmseg 是一个开源的语义分割库,语义分割是一种计算机视觉任务,涉及将图像中的每个像素分配一个类别标签。decode_head 是 mmseg.models 包中的一个模块,其中包含用于将神经网络输出解码为分割掩模的类。
BaseDecodeHead 是一个基础类,定义了解码神经网络输出的接口。它提供了处理输出的方法,包括上采样、连接和卷积等方法。BaseDecodeHead 的子类可以实现特定的解码策略,例如 FPN(特征金字塔网络)或 ASPP(空洞空间金字塔池化)解码方法。
from mmseg.models.decode_heads.decode_head import BaseDecodeHead
from ...core import build_sampler, multi_apply, reduce_mean
from ..builder import build_assigner
from ..utils import get_uncertain_point_coords_with_randomness
@HEADS.register_module()
class Mask2FormerHead(BaseDecodeHead):
"""Implements the Mask2Former head.
See `Masked-attention Mask Transformer for Universal Image
Segmentation <https://arxiv.org/pdf/2112.01527>`_ for details.
Args:
in_channels (list[int]): Number of channels in the input feature map.
feat_channels (int): Number of channels for features.
out_channels (int): Number of channels for output.
num_things_classes (int): Number of things.
num_stuff_classes (int): Number of stuff.
num_queries (int): Number of query in Transformer decoder.
pixel_decoder (:obj:`mmcv.ConfigDict` | dict): Config for pixel
decoder. Defaults to None.
enforce_decoder_input_project (bool, optional): Whether to add
a layer to change the embed_dim of tranformer encoder in
pixel decoder to the embed_dim of transformer decoder.
Defaults to False.
transformer_decoder (:obj:`mmcv.ConfigDict` | dict): Config for
transformer decoder. Defaults to None.
positional_encoding (:obj:`mmcv.ConfigDict` | dict): Config for
transformer decoder position encoding. Defaults to None.
loss_cls (:obj:`mmcv.ConfigDict` | dict): Config of the classification
loss. Defaults to None.
loss_mask (:obj:`mmcv.ConfigDict` | dict): Config of the mask loss.
Defaults to None.
loss_dice (:obj:`mmcv.ConfigDict` | dict): Config of the dice loss.
Defaults to None.
train_cfg (:obj:`mmcv.ConfigDict` | dict): Training config of
Mask2Former head.
test_cfg (:obj:`mmcv.ConfigDict` | dict): Testing config of
Mask2Former head.
init_cfg (dict or list[dict], optional): Initialization config dict.
Defaults to None.
"""
本段代码实现了 Mask2Former 网络头(Mask2Former head),用于语义分割任务中的像素级别的预测。该网络头的具
体实现方式在论文 "Masked-attention Mask Transformer for Universal Image Segmentation" 中有详细描述。
参数说明:
- in_channels(list[int]):输入特征图的通道数。
- feat_channels(int):特征通道数。
- out_channels(int):输出通道数。
- num_things_classes(int):物体类别数。
- num_stuff_classes(int):背景类别数。
- num_queries(int):Transformer 解码器中的查询数。
- pixel_decoder(mmcv.ConfigDict | dict,可选):像素解码器的配置,默认为 None。
- enforce_decoder_input_project(bool,可选):是否添加一个层来将 Transformer 编码器的 embed_dim 更改为 Transformer 解码器的 embed_dim。默认为 False。
- transformer_decoder(mmcv.ConfigDict | dict,可选):Transformer 解码器的配置,默认为 None。
- positional_encoding(mmcv.ConfigDict | dict,可选):Transformer 解码器位置编码的配置,默认为 None。
- loss_cls(mmcv.ConfigDict | dict,可选):分类损失的配置,默认为 None。
- loss_mask(mmcv.ConfigDict | dict,可选):掩码损失的配置,默认为 None。
- loss_dice(mmcv.ConfigDict | dict,可选):Dice 损失的配置,默认为 None。
- train_cfg(mmcv.ConfigDict | dict,可选):Mask2Former 网络头的训练配置。
- test_cfg(mmcv.ConfigDict | dict,可选):Mask2Former 网络头的测试配置。
- init_cfg(dict 或 list[dict],可选):初始化配置字典。默认为 None。
def __init__(self,
in_channels,
feat_channels,
out_channels,
num_things_classes=80,
num_stuff_classes=53,
num_queries=100,
num_transformer_feat_level=3,
pixel_decoder=None,
enforce_decoder_input_project=False,
transformer_decoder=None,
positional_encoding=None,
loss_cls=None,
loss_mask=None,
loss_dice=None,
train_cfg=None,
test_cfg=None,
init_cfg=None,
**kwargs):
super(Mask2FormerHead, self).__init__(
in_channels=in_channels,
channels=feat_channels,
num_classes=(num_things_classes + num_stuff_classes),
init_cfg=init_cfg,
input_transform='multiple_select',
**kwargs)
self.num_things_classes = num_things_classes
self.num_stuff_classes = num_stuff_classes
self.num_classes = self.num_things_classes + self.num_stuff_classes
self.num_queries = num_queries
self.num_transformer_feat_level = num_transformer_feat_level
self.num_heads = transformer_decoder.transformerlayers. \
attn_cfgs.num_heads
self.num_transformer_decoder_layers = transformer_decoder.num_layers
assert pixel_decoder.encoder.transformerlayers. \
attn_cfgs.num_levels == num_transformer_feat_level
pixel_decoder_ = copy.deepcopy(pixel_decoder)
pixel_decoder_.update(
in_channels=in_channels,
feat_channels=feat_channels,
out_channels=out_channels)
self.pixel_decoder = build_plugin_layer(pixel_decoder_)[1]
self.transformer_decoder = build_transformer_layer_sequence(
transformer_decoder)
self.decoder_embed_dims = self.transformer_decoder.embed_dims
self.decoder_input_projs = ModuleList()
# from low resolution to high resolution
for _ in range(num_transformer_feat_level):
if (self.decoder_embed_dims != feat_channels
or enforce_decoder_input_project):
self.decoder_input_projs.append(
Conv2d(
feat_channels, self.decoder_embed_dims, kernel_size=1))
else:
self.decoder_input_projs.append(nn.Identity())
self.decoder_positional_encoding = build_positional_encoding(
positional_encoding)
self.query_embed = nn.Embedding(self.num_queries, feat_channels)
self.query_feat = nn.Embedding(self.num_queries, feat_channels)
# from low resolution to high resolution
self.level_embed = nn.Embedding(self.num_transformer_feat_level,
feat_channels)
self.cls_embed = nn.Linear(feat_channels, self.num_classes + 1)
self.mask_embed = nn.Sequential(
nn.Linear(feat_channels, feat_channels), nn.ReLU(inplace=True),
nn.Linear(feat_channels, feat_channels), nn.ReLU(inplace=True),
nn.Linear(feat_channels, out_channels))
self.conv_seg = None # fix a bug here (conv_seg is not used)
self.test_cfg = test_cfg
self.train_cfg = train_cfg
if train_cfg:
self.assigner = build_assigner(self.train_cfg.assigner)
self.sampler = build_sampler(self.train_cfg.sampler, context=self)
self.num_points = self.train_cfg.get('num_points', 12544)
self.oversample_ratio = self.train_cfg.get('oversample_ratio', 3.0)
self.importance_sample_ratio = self.train_cfg.get(
'importance_sample_ratio', 0.75)
self.class_weight = loss_cls.class_weight
self.loss_cls = build_loss(loss_cls)
self.loss_mask = build_loss(loss_mask)
self.loss_dice = build_loss(loss_dice)
def init_weights(self):
for m in self.decoder_input_projs:
if isinstance(m, Conv2d):
caffe2_xavier_init(m, bias=0)
self.pixel_decoder.init_weights()
for p in self.transformer_decoder.parameters():
if p.dim() > 1:
nn.init.xavier_normal_(p)
def get_targets(self, cls_scores_list, mask_preds_list, gt_labels_list,
gt_masks_list, img_metas):
"""Compute classification and mask targets for all images for a decoder
layer.
Args:
cls_scores_list (list[Tensor]): Mask score logits from a single
decoder layer for all images. Each with shape [num_queries,
cls_out_channels].
mask_preds_list (list[Tensor]): Mask logits from a single decoder
layer for all images. Each with shape [num_queries, h, w].
gt_labels_list (list[Tensor]): Ground truth class indices for all
images. Each with shape (n, ), n is the sum of number of stuff
type and number of instance in a image.
gt_masks_list (list[Tensor]): Ground truth mask for each image,
each with shape (n, h, w).
img_metas (list[dict]): List of image meta information.
Returns:
tuple[list[Tensor]]: a tuple containing the following targets.
- labels_list (list[Tensor]): Labels of all images.
Each with shape [num_queries, ].
- label_weights_list (list[Tensor]): Label weights of all
images.Each with shape [num_queries, ].
- mask_targets_list (list[Tensor]): Mask targets of all images.
Each with shape [num_queries, h, w].
- mask_weights_list (list[Tensor]): Mask weights of all images.
Each with shape [num_queries, ].
- num_total_pos (int): Number of positive samples in all
images.
- num_total_neg (int): Number of negative samples in all
images.
"""
(labels_list, label_weights_list, mask_targets_list, mask_weights_list,
pos_inds_list,
neg_inds_list) = multi_apply(self._get_target_single, cls_scores_list,
mask_preds_list, gt_labels_list,
gt_masks_list, img_metas)
num_total_pos = sum((inds.numel() for inds in pos_inds_list))
num_total_neg = sum((inds.numel() for inds in neg_inds_list))
return (labels_list, label_weights_list, mask_targets_list,
mask_weights_list, num_total_pos, num_total_neg)
这是一个计算实例分割模型中分类和掩码目标的函数。该函数接受以下参数:
cls_scores_list:一个列表,包含所有图像中单个解码器层的掩码分数 logits。每个元素都是形状为[num_queries, cls_out_channels]的张量。mask_preds_list:一个列表,包含所有图像中单个解码器层的掩码 logits。每个元素都是形状为[num_queries, h, w]的张量。gt_labels_list:一个列表,包含所有图像中的实例和背景类别的真实标签。每个元素都是形状为(n,)的张量,其中n是图像中实例和背景类别的总数。gt_masks_list:一个列表,包含所有图像中实例的真实掩码。每个元素都是形状为(n, h, w)的张量。img_metas:一个列表,包含所有图像的元信息。
该函数将返回一个包含以下目标的元组:
labels_list:一个列表,包含所有图像中的标签。每个元素都是形状为[num_queries, ]的张量。label_weights_list:一个列表,包含所有图像中的标签权重。每个元素都是形状为[num_queries, ]的张量。mask_targets_list:一个列表,包含所有图像中的掩码目标。每个元素都是形状为[num_queries, h, w]的张量。mask_weights_list:一个列表,包含所有图像中的掩码权重。每个元素都是形状为[num_queries, ]的张量。num_total_pos:所有图像中正样本的数量。num_total_neg:所有图像中负样本的数量。
def _get_target_single(self, cls_score, mask_pred, gt_labels, gt_masks,
img_metas):
"""Compute classification and mask targets for one image.
Args:
cls_score (Tensor): Mask score logits from a single decoder layer
for one image. Shape (num_queries, cls_out_channels).
mask_pred (Tensor): Mask logits for a single decoder layer for one
image. Shape (num_queries, h, w).
gt_labels (Tensor): Ground truth class indices for one image with
shape (num_gts, ).
gt_masks (Tensor): Ground truth mask for each image, each with
shape (num_gts, h, w).
img_metas (dict): Image informtation.
Returns:
tuple[Tensor]: A tuple containing the following for one image.
- labels (Tensor): Labels of each image. \
shape (num_queries, ).
- label_weights (Tensor): Label weights of each image. \
shape (num_queries, ).
- mask_targets (Tensor): Mask targets of each image. \
shape (num_queries, h, w).
- mask_weights (Tensor): Mask weights of each image. \
shape (num_queries, ).
- pos_inds (Tensor): Sampled positive indices for each \
image.
- neg_inds (Tensor): Sampled negative indices for each \
image.
"""
# sample points
num_queries = cls_score.shape[0]
num_gts = gt_labels.shape[0]
point_coords = torch.rand((1, self.num_points, 2),
device=cls_score.device)
# shape (num_queries, num_points)
mask_points_pred = point_sample(
mask_pred.unsqueeze(1), point_coords.repeat(num_queries, 1,
1)).squeeze(1)
# shape (num_gts, num_points)
gt_points_masks = point_sample(
gt_masks.unsqueeze(1).float(), point_coords.repeat(num_gts, 1,
1)).squeeze(1)
# assign and sample
assign_result = self.assigner.assign(cls_score, mask_points_pred,
gt_labels, gt_points_masks,
img_metas)
sampling_result = self.sampler.sample(assign_result, mask_pred,
gt_masks)
pos_inds = sampling_result.pos_inds
neg_inds = sampling_result.neg_inds
# label target
labels = gt_labels.new_full((self.num_queries, ),
self.num_classes,
dtype=torch.long)
labels[pos_inds] = gt_labels[sampling_result.pos_assigned_gt_inds]
label_weights = gt_labels.new_ones((self.num_queries, ))
# mask target
mask_targets = gt_masks[sampling_result.pos_assigned_gt_inds]
mask_weights = mask_pred.new_zeros((self.num_queries, ))
mask_weights[pos_inds] = 1.0
return (labels, label_weights, mask_targets, mask_weights, pos_inds,
neg_inds)
这段代码似乎是计算机视觉任务中损失函数的一个方法定义,可能涉及目标检测和实例分割。该函数接受多个参数,包括预测的不同类别得分、预测的掩码、真实标签和掩码以及图像元数据。
该函数首先从输入参数中提取相关信息,并使用预测的得分和真实标签计算分类损失。然后从预测的掩码中提取正例,并使用它们计算Dice损失和掩码损失。Dice损失衡量预测掩码和真实掩码之间的相似性,而掩码损失则像素级地衡量预测掩码和真实掩码之间的差异。该函数的最终输出是三个损失组件的元组:分类损失、掩码损失和Dice损失。
def loss_single(self, cls_scores, mask_preds, gt_labels_list,
gt_masks_list, img_metas):
"""Loss function for outputs from a single decoder layer.
Args:
cls_scores (Tensor): Mask score logits from a single decoder layer
for all images. Shape (batch_size, num_queries,
cls_out_channels). Note `cls_out_channels` should includes
background.
mask_preds (Tensor): Mask logits for a pixel decoder for all
images. Shape (batch_size, num_queries, h, w).
gt_labels_list (list[Tensor]): Ground truth class indices for each
image, each with shape (num_gts, ).
gt_masks_list (list[Tensor]): Ground truth mask for each image,
each with shape (num_gts, h, w).
img_metas (list[dict]): List of image meta information.
Returns:
tuple[Tensor]: Loss components for outputs from a single \
decoder layer.
"""
num_imgs = cls_scores.size(0)
cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
mask_preds_list = [mask_preds[i] for i in range(num_imgs)]
(labels_list, label_weights_list, mask_targets_list, mask_weights_list,
num_total_pos,
num_total_neg) = self.get_targets(cls_scores_list, mask_preds_list,
gt_labels_list, gt_masks_list,
img_metas)
# shape (batch_size, num_queries)
labels = torch.stack(labels_list, dim=0)
# shape (batch_size, num_queries)
label_weights = torch.stack(label_weights_list, dim=0)
# shape (num_total_gts, h, w)
mask_targets = torch.cat(mask_targets_list, dim=0)
# shape (batch_size, num_queries)
mask_weights = torch.stack(mask_weights_list, dim=0)
# classfication loss
# shape (batch_size * num_queries, )
cls_scores = cls_scores.flatten(0, 1)
labels = labels.flatten(0, 1)
label_weights = label_weights.flatten(0, 1)
class_weight = cls_scores.new_tensor(self.class_weight)
loss_cls = self.loss_cls(
cls_scores,
labels,
label_weights,
avg_factor=class_weight[labels].sum())
num_total_masks = reduce_mean(cls_scores.new_tensor([num_total_pos]))
num_total_masks = max(num_total_masks, 1)
# extract positive ones
# shape (batch_size, num_queries, h, w) -> (num_total_gts, h, w)
mask_preds = mask_preds[mask_weights > 0]
if mask_targets.shape[0] == 0:
# zero match
loss_dice = mask_preds.sum()
loss_mask = mask_preds.sum()
return loss_cls, loss_mask, loss_dice
with torch.no_grad():
points_coords = get_uncertain_point_coords_with_randomness(
mask_preds.unsqueeze(1), None, self.num_points,
self.oversample_ratio, self.importance_sample_ratio)
# shape (num_total_gts, h, w) -> (num_total_gts, num_points)
mask_point_targets = point_sample(
mask_targets.unsqueeze(1).float(), points_coords).squeeze(1)
# shape (num_queries, h, w) -> (num_queries, num_points)
mask_point_preds = point_sample(
mask_preds.unsqueeze(1), points_coords).squeeze(1)
# dice loss
loss_dice = self.loss_dice(
mask_point_preds, mask_point_targets, avg_factor=num_total_masks)
# mask loss
# shape (num_queries, num_points) -> (num_queries * num_points, )
mask_point_preds = mask_point_preds.reshape(-1,1)
# shape (num_total_gts, num_points) -> (num_total_gts * num_points, )
mask_point_targets = mask_point_targets.reshape(-1)
loss_mask = self.loss_mask(
mask_point_preds,
mask_point_targets,
avg_factor=num_total_masks * self.num_points)
return loss_cls, loss_mask, loss_dice
这段代码定义了一个损失函数,用于目标检测和实例分割任务中的模型训练。该函数接受多个参数,包括预测的分类得分、掩码预测、真实标签和掩码以及图像元数据。其中,预测的分类得分和掩码预测是来自解码器的输出,而真实标签和掩码是来自数据集的标注信息。
该函数首先通过装饰器@force_fp32将输入参数强制转换为32位浮点数,然后将输入参数分别传递给multi_apply函数,该函数将输入参数沿着第二个维度进行切片,并将切片后的参数传递给self.loss_single函数进行单次计算。loss_single函数计算每个切片的分类损失、掩码损失和Dice损失,并将它们汇总到一个元组中,最终通过multi_apply函数将所有元组汇总到一个列表中。
在汇总完所有的损失值之后,该函数将它们按照解码器层数的顺序分别保存到一个字典中,并将该字典作为函数的返回值。其中,最后一个解码器层的分类损失、掩码损失和Dice损失被保存为loss_cls、loss_mask和loss_dice,而其他解码器层的损失则被保存为d{i}.loss_cls、d{i}.loss_mask和d{i}.loss_dice,其中i表示解码器层的索引。
@force_fp32(apply_to=('all_cls_scores', 'all_mask_preds'))
def loss(self, all_cls_scores, all_mask_preds, gt_labels_list,
gt_masks_list, img_metas):
"""Loss function.
Args:
all_cls_scores (Tensor): Classification scores for all decoder
layers with shape [num_decoder, batch_size, num_queries,
cls_out_channels].
all_mask_preds (Tensor): Mask scores for all decoder layers with
shape [num_decoder, batch_size, num_queries, h, w].
gt_labels_list (list[Tensor]): Ground truth class indices for each
image with shape (n, ). n is the sum of number of stuff type
and number of instance in a image.
gt_masks_list (list[Tensor]): Ground truth mask for each image with
shape (n, h, w).
img_metas (list[dict]): List of image meta information.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
num_dec_layers = len(all_cls_scores)
all_gt_labels_list = [gt_labels_list for _ in range(num_dec_layers)]
all_gt_masks_list = [gt_masks_list for _ in range(num_dec_layers)]
img_metas_list = [img_metas for _ in range(num_dec_layers)]
losses_cls, losses_mask, losses_dice = multi_apply(
self.loss_single, all_cls_scores, all_mask_preds,
all_gt_labels_list, all_gt_masks_list, img_metas_list)
loss_dict = dict()
# loss from the last decoder layer
loss_dict['loss_cls'] = losses_cls[-1]
loss_dict['loss_mask'] = losses_mask[-1]
loss_dict['loss_dice'] = losses_dice[-1]
# loss from other decoder layers
num_dec_layer = 0
for loss_cls_i, loss_mask_i, loss_dice_i in zip(
losses_cls[:-1], losses_mask[:-1], losses_dice[:-1]):
loss_dict[f'd{num_dec_layer}.loss_cls'] = loss_cls_i
loss_dict[f'd{num_dec_layer}.loss_mask'] = loss_mask_i
loss_dict[f'd{num_dec_layer}.loss_dice'] = loss_dice_i
num_dec_layer += 1
return loss_dict
这段代码定义了一个用于解码器输出的头部部分的前向传递函数。该函数接受三个参数,包括解码器输出、掩码特征和目标注意力掩码的大小。
函数首先对解码器输出进行后向传递规范化,并对维度进行转置以便于后续处理。然后,利用两个全连接层将解码器输出映射到分类得分和掩码嵌入向量上。分类得分被用于预测物体类别,而掩码嵌入向量被用于预测实例分割掩码。
接着,该函数使用torch.einsum函数将掩码嵌入向量和掩码特征相乘,得到实例分割掩码的预测结果。同时,该函数还通过插值操作将实例分割掩码的分辨率调整为目标注意力掩码的大小。最后,该函数将实例分割掩码转换为注意力掩码,并将其作为函数的返回值之一。
需要注意的是,在将实例分割掩码转换为注意力掩码时,该函数首先将实例分割掩码展平为二维张量,然后将其复制num_heads次,并将其重塑为四维张量。最后,该函数将注意力掩码的数值转换为二进制,使得注意力掩码中的像素值只能取0或1。这样做的目的是为了将注意力掩码离散化,使其更适合用于注意力计算。
def forward_head(self, decoder_out, mask_feature, attn_mask_target_size):
"""Forward for head part which is called after every decoder layer.
Args:
decoder_out (Tensor): in shape (num_queries, batch_size, c).
mask_feature (Tensor): in shape (batch_size, c, h, w).
attn_mask_target_size (tuple[int, int]): target attention
mask size.
Returns:
tuple: A tuple contain three elements.
- cls_pred (Tensor): Classification scores in shape \
(batch_size, num_queries, cls_out_channels). \
Note `cls_out_channels` should includes background.
- mask_pred (Tensor): Mask scores in shape \
(batch_size, num_queries,h, w).
- attn_mask (Tensor): Attention mask in shape \
(batch_size * num_heads, num_queries, h, w).
"""
decoder_out = self.transformer_decoder.post_norm(decoder_out)
decoder_out = decoder_out.transpose(0, 1)
# shape (num_queries, batch_size, c)
cls_pred = self.cls_embed(decoder_out)
# shape (num_queries, batch_size, c)
mask_embed = self.mask_embed(decoder_out)
# shape (num_queries, batch_size, h, w)
mask_pred = torch.einsum('bqc,bchw->bqhw', mask_embed, mask_feature)
attn_mask = F.interpolate(
mask_pred,
attn_mask_target_size,
mode='bilinear',
align_corners=False)
# shape (num_queries, batch_size, h, w) ->
# (batch_size * num_head, num_queries, h, w)
attn_mask = attn_mask.flatten(2).unsqueeze(1).repeat(
(1, self.num_heads, 1, 1)).flatten(0, 1)
attn_mask = attn_mask.sigmoid() < 0.5
attn_mask = attn_mask.detach()
return cls_pred, mask_pred, attn_mask
这段代码似乎是实现了一个基于Transformer的目标检测模型的前向传递。以下是简要概括:
- 输入特征(
feats)通过一个“像素解码器”(self.pixel_decoder)得到掩膜特征(mask_features)和多尺度记忆张量的列表(multi_scale_memorys)。 - 这些多尺度记忆作为输入传递给Transformer网络的解码器层(
self.transformer_decoder),同时还有学习的位置嵌入(decoder_positional_encodings)和查询嵌入(query_embed)。 - 在每个解码器层中,查询嵌入根据查询和记忆张量之间计算的注意力权重进行更新。然后将这些更新后的嵌入传递到“前向头”(
self.forward_head)中,以得到分类对数和掩膜对数(cls_pred和mask_pred)。 - 每个解码器层的分类和掩膜对数都被收集在列表中(
cls_pred_list和mask_pred_list),并作为前向传递的最终输出返回。
总体而言,这段代码实现了一个基于Transformer的目标检测模型,它使用像素解码器从输入特征中获得掩膜特征,并使用一系列解码器层来优化查询嵌入并计算分类和掩膜对数。
def forward(self, feats, img_metas):
"""Forward function.
Args:
feats (list[Tensor]): Multi scale Features from the
upstream network, each is a 4D-tensor.
img_metas (list[dict]): List of image information.
Returns:
tuple: A tuple contains two elements.
- cls_pred_list (list[Tensor)]: Classification logits \
for each decoder layer. Each is a 3D-tensor with shape \
(batch_size, num_queries, cls_out_channels). \
Note `cls_out_channels` should includes background.
- mask_pred_list (list[Tensor]): Mask logits for each \
decoder layer. Each with shape (batch_size, num_queries, \
h, w).
"""
batch_size = len(img_metas)
mask_features, multi_scale_memorys = self.pixel_decoder(feats)
# multi_scale_memorys (from low resolution to high resolution)
decoder_inputs = []
decoder_positional_encodings = []
for i in range(self.num_transformer_feat_level):
decoder_input = self.decoder_input_projs[i](multi_scale_memorys[i])
# shape (batch_size, c, h, w) -> (h*w, batch_size, c)
decoder_input = decoder_input.flatten(2).permute(2, 0, 1)
level_embed = self.level_embed.weight[i].view(1, 1, -1)
decoder_input = decoder_input + level_embed
# shape (batch_size, c, h, w) -> (h*w, batch_size, c)
mask = decoder_input.new_zeros(
(batch_size, ) + multi_scale_memorys[i].shape[-2:],
dtype=torch.bool)
decoder_positional_encoding = self.decoder_positional_encoding(
mask)
decoder_positional_encoding = decoder_positional_encoding.flatten(
2).permute(2, 0, 1)
decoder_inputs.append(decoder_input)
decoder_positional_encodings.append(decoder_positional_encoding)
# shape (num_queries, c) -> (num_queries, batch_size, c)
query_feat = self.query_feat.weight.unsqueeze(1).repeat(
(1, batch_size, 1))
query_embed = self.query_embed.weight.unsqueeze(1).repeat(
(1, batch_size, 1))
cls_pred_list = []
mask_pred_list = []
cls_pred, mask_pred, attn_mask = self.forward_head(
query_feat, mask_features, multi_scale_memorys[0].shape[-2:])
cls_pred_list.append(cls_pred)
mask_pred_list.append(mask_pred)
for i in range(self.num_transformer_decoder_layers):
level_idx = i % self.num_transformer_feat_level
# if a mask is all True(all background), then set it all False.
attn_mask[torch.where(
attn_mask.sum(-1) == attn_mask.shape[-1])] = False
# cross_attn + self_attn
layer = self.transformer_decoder.layers[i]
attn_masks = [attn_mask, None]
query_feat = layer(
query=query_feat,
key=decoder_inputs[level_idx],
value=decoder_inputs[level_idx],
query_pos=query_embed,
key_pos=decoder_positional_encodings[level_idx],
attn_masks=attn_masks,
query_key_padding_mask=None,
# here we do not apply masking on padded region
key_padding_mask=None)
cls_pred, mask_pred, attn_mask = self.forward_head(
query_feat, mask_features, multi_scale_memorys[
(i + 1) % self.num_transformer_feat_level].shape[-2:])
cls_pred_list.append(cls_pred)
mask_pred_list.append(mask_pred)
return cls_pred_list, mask_pred_list
这段代码实现了一个在训练模式下的前向传递函数。以下是简要概括:
- 多层特征(
x)和图像信息(img_metas)作为输入,经过模型的前向传递 (self(x, img_metas)),得到分类和掩膜对数 (all_cls_scores和all_mask_preds)。 - 通过调用
self.loss()函数计算分类和掩膜对数与 ground truth labels (gt_labels)和 masks (gt_masks)的损失值。 - 将损失值作为字典 (
losses) 返回。
总体而言,这段代码实现了一个在训练模式下的前向传递函数,并计算了分类和掩膜对数与 ground truth 之间的损失。
def forward_train(self, x, img_metas, gt_semantic_seg, gt_labels,
gt_masks):
"""Forward function for training mode.
Args:
x (list[Tensor]): Multi-level features from the upstream network,
each is a 4D-tensor.
img_metas (list[Dict]): List of image information.
gt_semantic_seg (list[tensor]):Each element is the ground truth
of semantic segmentation with the shape (N, H, W).
train_cfg (dict): The training config, which not been used in
maskformer.
gt_labels (list[Tensor]): Each element is ground truth labels of
each box, shape (num_gts,).
gt_masks (list[BitmapMasks]): Each element is masks of instances
of a image, shape (num_gts, h, w).
Returns:
losses (dict[str, Tensor]): a dictionary of loss components
"""
# forward
all_cls_scores, all_mask_preds = self(x, img_metas)
# loss
losses = self.loss(all_cls_scores, all_mask_preds, gt_labels, gt_masks,
img_metas)
return losses
这段代码实现了一个在测试模式下的前向传递函数,用于生成语义分割预测。以下是简要概括:
- 多层特征(
inputs)和图像信息(img_metas)作为输入,经过模型的前向传递 (self(inputs, img_metas)),得到分类和掩膜对数列表 (all_cls_scores和all_mask_preds)。 - 只使用最后一个解码器层的分类和掩膜对数 (
cls_score和mask_pred),并获取输入图像的原始高度和宽度 (ori_h和ori_w)。 - 对分类对数进行 softmax 操作,并对掩膜对数进行 sigmoid 操作。
- 将分类和掩膜对数相乘,并对结果进行像素级加权求和,得到语义分割预测 (
seg_mask)。 - 将语义分割预测作为输出返回。
总体而言,这段代码实现了一个在测试模式下的前向传递函数,用于生成语义分割预测。它只使用最后一个解码器层的输出,并对分类和掩膜对数进行一些后处理,以得到最终的语义分割预测。
def forward_test(self, inputs, img_metas, test_cfg):
"""Test segment without test-time aumengtation.
Only the output of last decoder layers was used.
Args:
inputs (list[Tensor]): Multi-level features from the
upstream network, each is a 4D-tensor.
img_metas (list[dict]): List of image information.
test_cfg (dict): Testing config.
Returns:
seg_mask (Tensor): Predicted semantic segmentation logits.
"""
all_cls_scores, all_mask_preds = self(inputs, img_metas)
cls_score, mask_pred = all_cls_scores[-1], all_mask_preds[-1]
ori_h, ori_w, _ = img_metas[0]['ori_shape']
# semantic inference
cls_score = F.softmax(cls_score, dim=-1)[..., :-1]
mask_pred = mask_pred.sigmoid()
seg_mask = torch.einsum('bqc,bqhw->bchw', cls_score, mask_pred)
return seg_mask
segmentors
这是一个名为EncoderDecoderMask2FormerAug的分割模型的Python类定义。该模型用于图像分割任务,包括编码器-解码器架构。
__init__方法初始化模型架构并设置各种配置选项。使用builder模块构建backbone,neck,decode_head和auxiliary_head。如果pretrained不为None,则使用预训练权重初始化backbone。
train_cfg和test_cfg是包含训练和测试模型的配置选项的字典。
assert self.with_decode_head语句检查模型是否具有decode_head属性,该属性对于分割任务是必需的。如果不存在此属性,则会引发错误。
encoder_decoder_mask2former_aug.py
# Copyright (c) OpenMMLab. All rights reserved.
import torch
import torch.nn as nn
import torch.nn.functional as F
from mmseg.core import add_prefix
from mmseg.models import builder
from mmseg.models.builder import SEGMENTORS
from mmseg.models.segmentors.base import BaseSegmentor
from mmseg.ops import resize
@SEGMENTORS.register_module()
class EncoderDecoderMask2FormerAug(BaseSegmentor):
"""Encoder Decoder segmentors.
EncoderDecoder typically consists of backbone, decode_head, auxiliary_head.
Note that auxiliary_head is only used for deep supervision during training,
which could be dumped during inference.
"""
def __init__(self,
backbone,
decode_head,
neck=None,
auxiliary_head=None,
train_cfg=None,
test_cfg=None,
pretrained=None,
init_cfg=None):
super(EncoderDecoderMask2FormerAug, self).__init__(init_cfg)
if pretrained is not None:
assert backbone.get('pretrained') is None, \
'both backbone and segmentor set pretrained weight'
backbone.pretrained = pretrained
self.backbone = builder.build_backbone(backbone)
if neck is not None:
self.neck = builder.build_neck(neck)
decode_head.update(train_cfg=train_cfg)
decode_head.update(test_cfg=test_cfg)
self._init_decode_head(decode_head)
self._init_auxiliary_head(auxiliary_head)
self.train_cfg = train_cfg
self.test_cfg = test_cfg
assert self.with_decode_head
这是EncoderDecoderMask2FormerAug类中的一个方法 _init_decode_head,用于初始化decode_head。
在该方法中,decode_head通过builder模块构建。然后,将decode_head分配给self.decode_head属性。此外,将self.align_corners和self.num_classes属性分别设置为decode_head的align_corners和num_classes属性的值。这些属性用于进行分割任务,并在模型的其他部分中使用。
def _init_decode_head(self, decode_head):
"""Initialize ``decode_head``"""
self.decode_head = builder.build_head(decode_head)
self.align_corners = self.decode_head.align_corners
self.num_classes = self.decode_head.num_classes
这是EncoderDecoderMask2FormerAug类中的一个方法 _init_auxiliary_head,用于初始化auxiliary_head。
在该方法中,首先检查auxiliary_head是否为None。如果不是,就检查auxiliary_head是否为列表类型。如果是,就循环遍历auxiliary_head列表中的每个子项,并使用builder模块构建每个head_cfg的头部。这些头部将存储在nn.ModuleList()中,并分配给self.auxiliary_head属性。
如果auxiliary_head不是列表类型,就直接使用builder模块构建它,并将其分配给self.auxiliary_head属性。
def _init_auxiliary_head(self, auxiliary_head):
"""Initialize ``auxiliary_head``"""
if auxiliary_head is not None:
if isinstance(auxiliary_head, list):
self.auxiliary_head = nn.ModuleList()
for head_cfg in auxiliary_head:
self.auxiliary_head.append(builder.build_head(head_cfg))
else:
self.auxiliary_head = builder.build_head(auxiliary_head)
这是EncoderDecoderMask2FormerAug类中的一个方法extract_feat,用于从图像中提取特征。
在该方法中,首先使用backbone对图像进行特征提取,得到一个特征图x。如果with_neck为True,则将特征图x通过neck进行进一步处理,得到更高层次的特征表示。最终,返回处理后的特征图x。
def extract_feat(self, img):
"""Extract features from images."""
x = self.backbone(img)
if self.with_neck:
x = self.neck(x)
return x
def encode_decode(self, img, img_metas):
"""Encode images with backbone and decode into a semantic segmentation
map of the same size as input."""
x = self.extract_feat(img)
out = self._decode_head_forward_test(x, img_metas)
out = resize(
input=out,
size=img.shape[2:],
mode='bilinear',
align_corners=self.align_corners)
return out
这是EncoderDecoderMask2FormerAug类中的一个方法 encode_decode,用于将图像进行编码和解码,生成与输入图像大小相同的语义分割映射。
在该方法中,首先使用extract_feat方法对输入图像进行特征提取,得到特征图x。然后,使用_decode_head_forward_test方法将特征图解码为语义分割映射。该方法在测试时使用,用于生成输出结果。
最后,使用resize方法将解码后的映射out调整为与输入图像相同的大小,并以双线性插值的方式进行对齐。最终,返回调整大小后的语义分割映射out。
def _decode_head_forward_train(self, x, img_metas, gt_semantic_seg,
**kwargs):
"""Run forward function and calculate loss for decode head in
training."""
losses = dict()
loss_decode = self.decode_head.forward_train(x, img_metas,
gt_semantic_seg, **kwargs)
losses.update(add_prefix(loss_decode, 'decode'))
return losses
这是EncoderDecoderMask2FormerAug类中的一个方法 _decode_head_forward_test,在测试时用于运行解码器头部的前向传递,并生成分割结果。
在该方法中,首先调用decode_head的forward_test方法,将特征图x、图像元数据img_metas和测试配置self.test_cfg作为输入,生成分割结果seg_logits。forward_test方法用于测试时的前向传递,用于生成输出结果。
最终,返回分割结果seg_logits。
def _decode_head_forward_test(self, x, img_metas):
"""Run forward function and calculate loss for decode head in
inference."""
seg_logits = self.decode_head.forward_test(x, img_metas, self.test_cfg)
return seg_logits
def _auxiliary_head_forward_train(self, x, img_metas, gt_semantic_seg):
"""Run forward function and calculate loss for auxiliary head in
training."""
losses = dict()
if isinstance(self.auxiliary_head, nn.ModuleList):
for idx, aux_head in enumerate(self.auxiliary_head):
loss_aux = aux_head.forward_train(x, img_metas,
gt_semantic_seg,
self.train_cfg)
losses.update(add_prefix(loss_aux, f'aux_{idx}'))
else:
loss_aux = self.auxiliary_head.forward_train(
x, img_metas, gt_semantic_seg, self.train_cfg)
losses.update(add_prefix(loss_aux, 'aux'))
return losses
这是EncoderDecoderMask2FormerAug类中的一个方法 _auxiliary_head_forward_train,用于在训练时运行辅助头部的前向传递,并计算损失。
在该方法中,首先检查self.auxiliary_head是否为nn.ModuleList类型。如果是,表示存在多个辅助头部,需要循环遍历每个辅助头部并计算对应的损失。对于每个辅助头部,调用forward_train方法,将特征图x、图像元数据img_metas和真实语义分割标签gt_semantic_seg作为输入,计算相应的损失。然后,将损失结果添加到字典losses中,并使用add_prefix方法添加前缀aux_。
如果self.auxiliary_head不是nn.ModuleList类型,表示只存在一个辅助头部,直接调用forward_train方法计算损失,并将结果添加到字典losses中,并使用前缀aux。
最终,返回损失字典losses。
def forward_dummy(self, img):
"""Dummy forward function."""
seg_logit = self.encode_decode(img, None)
return seg_logit
这是EncoderDecoderMask2FormerAug类中的一个方法 forward_train,用于在训练时进行前向传递,并计算损失。
在该方法中,首先使用extract_feat方法对输入图像进行特征提取,得到特征图x。然后,调用_decode_head_forward_train方法,将特征图x、图像元数据img_metas和真实语义分割标签gt_semantic_seg作为输入,计算解码器头部的损失,并将结果添加到字典losses中。
如果存在辅助头部,调用_auxiliary_head_forward_train方法,将特征图x、图像元数据img_metas和真实语义分割标签gt_semantic_seg作为输入,计算辅助头部的损失,并将结果添加到losses字典中。
最终,返回损失字典losses。
def forward_train(self, img, img_metas, gt_semantic_seg, **kwargs):
"""Forward function for training.
Args:
img (Tensor): Input images.
img_metas (list[dict]): List of image info dict where each dict
has: 'img_shape', 'scale_factor', 'flip', and may also contain
'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
For details on the values of these keys see
`mmseg/datasets/pipelines/formatting.py:Collect`.
gt_semantic_seg (Tensor): Semantic segmentation masks
used if the architecture supports semantic segmentation task.
Returns:
dict[str, Tensor]: a dictionary of loss components
"""
x = self.extract_feat(img)
losses = dict()
loss_decode = self._decode_head_forward_train(x, img_metas,
gt_semantic_seg,
**kwargs)
losses.update(loss_decode)
if self.with_auxiliary_head:
loss_aux = self._auxiliary_head_forward_train(
x, img_metas, gt_semantic_seg)
losses.update(loss_aux)
return losses
# TODO refactor
def slide_inference(self, img, img_meta, rescale, unpad=True):
"""Inference by sliding-window with overlap.
If h_crop > h_img or w_crop > w_img, the small patch will be used to
decode without padding.
"""
h_stride, w_stride = self.test_cfg.stride
h_crop, w_crop = self.test_cfg.crop_size
batch_size, _, h_img, w_img = img.size()
num_classes = self.num_classes
h_grids = max(h_img - h_crop + h_stride - 1, 0) // h_stride + 1
w_grids = max(w_img - w_crop + w_stride - 1, 0) // w_stride + 1
preds = img.new_zeros((batch_size, num_classes, h_img, w_img))
count_mat = img.new_zeros((batch_size, 1, h_img, w_img))
for h_idx in range(h_grids):
for w_idx in range(w_grids):
y1 = h_idx * h_stride
x1 = w_idx * w_stride
y2 = min(y1 + h_crop, h_img)
x2 = min(x1 + w_crop, w_img)
y1 = max(y2 - h_crop, 0)
x1 = max(x2 - w_crop, 0)
crop_img = img[:, :, y1:y2, x1:x2]
crop_seg_logit = self.encode_decode(crop_img, img_meta)
preds += F.pad(crop_seg_logit,
(int(x1), int(preds.shape[3] - x2), int(y1),
int(preds.shape[2] - y2)))
count_mat[:, :, y1:y2, x1:x2] += 1
assert (count_mat == 0).sum() == 0
if torch.onnx.is_in_onnx_export():
# cast count_mat to constant while exporting to ONNX
count_mat = torch.from_numpy(
count_mat.cpu().detach().numpy()).to(device=img.device)
preds = preds / count_mat
if unpad:
unpad_h, unpad_w = img_meta[0]['img_shape'][:2]
# logging.info(preds.shape, img_meta[0])
preds = preds[:, :, :unpad_h, :unpad_w]
if rescale:
preds = resize(preds,
size=img_meta[0]['ori_shape'][:2],
mode='bilinear',
align_corners=self.align_corners,
warning=False)
return preds
def whole_inference(self, img, img_meta, rescale):
"""Inference with full image."""
seg_logit = self.encode_decode(img, img_meta)
if rescale:
# support dynamic shape for onnx
if torch.onnx.is_in_onnx_export():
size = img.shape[2:]
else:
size = img_meta[0]['ori_shape'][:2]
seg_logit = resize(
seg_logit,
size=size,
mode='bilinear',
align_corners=self.align_corners,
warning=False)
return seg_logit
这是EncoderDecoderMask2FormerAug类中的两个方法,用于进行推理。
slide_inference方法实现了基于滑动窗口的推理。它将输入图像分为多个重叠的子图,然后对每个子图进行语义分割预测,最后将所有子图的预测结果组合起来得到最终的预测结果。在组合过程中,使用F.pad函数将每个子图的预测结果填充到对应的位置上,并使用count_mat记录每个像素被预测的次数。最终将预测结果除以count_mat得到平均值。如果unpad参数为True,则将预测结果裁剪到原始图像的大小。如果rescale参数为True,则将预测结果缩放到原始图像的大小。
whole_inference方法实现了对整张图像进行推理。它将输入图像直接输入到网络中进行语义分割预测,并根据rescale参数决定是否将预测结果缩放到原始图像的大小。
两个方法都调用了encode_decode方法进行语义分割预测,其中slide_inference方法对图像进行了分割,而whole_inference方法则直接对整张图像进行预测。
def inference(self, img, img_meta, rescale):
"""Inference with slide/whole style.
Args:
img (Tensor): The input image of shape (N, 3, H, W).
img_meta (dict): Image info dict where each dict has: 'img_shape',
'scale_factor', 'flip', and may also contain
'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
For details on the values of these keys see
`mmseg/datasets/pipelines/formatting.py:Collect`.
rescale (bool): Whether rescale back to original shape.
Returns:
Tensor: The output segmentation map.
"""
assert self.test_cfg.mode in ['slide', 'whole']
ori_shape = img_meta[0]['ori_shape']
assert all(_['ori_shape'] == ori_shape for _ in img_meta)
if self.test_cfg.mode == 'slide':
seg_logit = self.slide_inference(img, img_meta, rescale)
else:
seg_logit = self.whole_inference(img, img_meta, rescale)
output = F.softmax(seg_logit, dim=1)
flip = img_meta[0]['flip']
if flip:
flip_direction = img_meta[0]['flip_direction']
assert flip_direction in ['horizontal', 'vertical']
if flip_direction == 'horizontal':
output = output.flip(dims=(3, ))
elif flip_direction == 'vertical':
output = output.flip(dims=(2, ))
return output
simple_test方法是一个简单的测试方法,用于对单个图像进行推理并返回推理结果。
它首先调用inference方法进行语义分割预测,并将结果转换为类别预测。然后,如果当前在导出ONNX模型,则需要将预测结果的维度扩展为4维,并返回预测结果。否则,将预测结果转换为numpy数组并返回。最后,将预测结果解开批次维度并转换为列表形式返回。
def simple_test(self, img, img_meta, rescale=True):
"""Simple test with single image."""
seg_logit = self.inference(img, img_meta, rescale)
seg_pred = seg_logit.argmax(dim=1)
if torch.onnx.is_in_onnx_export():
# our inference backend only support 4D output
seg_pred = seg_pred.unsqueeze(0)
return seg_pred
seg_pred = seg_pred.cpu().numpy()
# unravel batch dim
seg_pred = list(seg_pred)
return seg_pred
aug_test方法用于在多个增强的图像上进行测试。它对每个增强的图像进行推理,然后将所有图像的预测结果取平均值作为最终的预测结果。在推理过程中,使用了inference方法进行语义分割预测。最后,将预测结果转换为numpy数组并返回。最后,将预测结果解开批次维度并转换为列表形式返回。
需要注意的是,目前只支持rescale=True的情况,且所有图像都会被缩放回原始尺寸进行预测。
def aug_test(self, imgs, img_metas, rescale=True):
"""Test with augmentations.
Only rescale=True is supported.
"""
# aug_test rescale all imgs back to ori_shape for now
assert rescale
# to save memory, we get augmented seg logit inplace
seg_logit = self.inference(imgs[0], img_metas[0], rescale)
for i in range(1, len(imgs)):
cur_seg_logit = self.inference(imgs[i], img_metas[i], rescale)
seg_logit += cur_seg_logit
seg_logit /= len(imgs)
seg_pred = seg_logit.argmax(dim=1)
seg_pred = seg_pred.cpu().numpy()
# unravel batch dim
seg_pred = list(seg_pred)
return seg_pred
encoder_decoder_mask2former.py
# Copyright (c) OpenMMLab. All rights reserved.
import torch
import torch.nn as nn
import torch.nn.functional as F
from mmseg.core import add_prefix
from mmseg.models import builder
from mmseg.models.builder import SEGMENTORS
from mmseg.models.segmentors.base import BaseSegmentor
from mmseg.ops import resize
@SEGMENTORS.register_module()
class EncoderDecoderMask2Former(BaseSegmentor):
"""Encoder Decoder segmentors.
EncoderDecoder typically consists of backbone, decode_head, auxiliary_head.
Note that auxiliary_head is only used for deep supervision during training,
which could be dumped during inference.
"""
def __init__(self,
backbone,
decode_head,
neck=None,
auxiliary_head=None,
train_cfg=None,
test_cfg=None,
pretrained=None,
init_cfg=None):
super(EncoderDecoderMask2Former, self).__init__(init_cfg)
if pretrained is not None:
assert backbone.get('pretrained') is None, \
'both backbone and segmentor set pretrained weight'
backbone.pretrained = pretrained
self.backbone = builder.build_backbone(backbone)
if neck is not None:
self.neck = builder.build_neck(neck)
decode_head.update(train_cfg=train_cfg)
decode_head.update(test_cfg=test_cfg)
self._init_decode_head(decode_head)
self._init_auxiliary_head(auxiliary_head)
self.train_cfg = train_cfg
self.test_cfg = test_cfg
assert self.with_decode_head
def _init_decode_head(self, decode_head):
"""Initialize ``decode_head``"""
self.decode_head = builder.build_head(decode_head)
self.align_corners = self.decode_head.align_corners
self.num_classes = self.decode_head.num_classes
def _init_auxiliary_head(self, auxiliary_head):
"""Initialize ``auxiliary_head``"""
if auxiliary_head is not None:
if isinstance(auxiliary_head, list):
self.auxiliary_head = nn.ModuleList()
for head_cfg in auxiliary_head:
self.auxiliary_head.append(builder.build_head(head_cfg))
else:
self.auxiliary_head = builder.build_head(auxiliary_head)
def extract_feat(self, img):
"""Extract features from images."""
x = self.backbone(img)
if self.with_neck:
x = self.neck(x)
return x
def encode_decode(self, img, img_metas):
"""Encode images with backbone and decode into a semantic segmentation
map of the same size as input."""
x = self.extract_feat(img)
out = self._decode_head_forward_test(x, img_metas)
out = resize(
input=out,
size=img.shape[2:],
mode='bilinear',
align_corners=self.align_corners)
return out
def _decode_head_forward_train(self, x, img_metas, gt_semantic_seg,
**kwargs):
"""Run forward function and calculate loss for decode head in
training."""
losses = dict()
loss_decode = self.decode_head.forward_train(x, img_metas,
gt_semantic_seg, **kwargs)
losses.update(add_prefix(loss_decode, 'decode'))
return losses
def _decode_head_forward_test(self, x, img_metas):
"""Run forward function and calculate loss for decode head in
inference."""
seg_logits = self.decode_head.forward_test(x, img_metas, self.test_cfg)
return seg_logits
def _auxiliary_head_forward_train(self, x, img_metas, gt_semantic_seg):
"""Run forward function and calculate loss for auxiliary head in
training."""
losses = dict()
if isinstance(self.auxiliary_head, nn.ModuleList):
for idx, aux_head in enumerate(self.auxiliary_head):
loss_aux = aux_head.forward_train(x, img_metas,
gt_semantic_seg,
self.train_cfg)
losses.update(add_prefix(loss_aux, f'aux_{idx}'))
else:
loss_aux = self.auxiliary_head.forward_train(
x, img_metas, gt_semantic_seg, self.train_cfg)
losses.update(add_prefix(loss_aux, 'aux'))
return losses
def forward_dummy(self, img):
"""Dummy forward function."""
seg_logit = self.encode_decode(img, None)
return seg_logit
def forward_train(self, img, img_metas, gt_semantic_seg, **kwargs):
"""Forward function for training.
Args:
img (Tensor): Input images.
img_metas (list[dict]): List of image info dict where each dict
has: 'img_shape', 'scale_factor', 'flip', and may also contain
'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
For details on the values of these keys see
`mmseg/datasets/pipelines/formatting.py:Collect`.
gt_semantic_seg (Tensor): Semantic segmentation masks
used if the architecture supports semantic segmentation task.
Returns:
dict[str, Tensor]: a dictionary of loss components
"""
x = self.extract_feat(img)
losses = dict()
loss_decode = self._decode_head_forward_train(x, img_metas,
gt_semantic_seg,
**kwargs)
losses.update(loss_decode)
if self.with_auxiliary_head:
loss_aux = self._auxiliary_head_forward_train(
x, img_metas, gt_semantic_seg)
losses.update(loss_aux)
return losses
# TODO refactor
def slide_inference(self, img, img_meta, rescale):
"""Inference by sliding-window with overlap.
If h_crop > h_img or w_crop > w_img, the small patch will be used to
decode without padding.
"""
h_stride, w_stride = self.test_cfg.stride
h_crop, w_crop = self.test_cfg.crop_size
batch_size, _, h_img, w_img = img.size()
num_classes = self.num_classes
h_grids = max(h_img - h_crop + h_stride - 1, 0) // h_stride + 1
w_grids = max(w_img - w_crop + w_stride - 1, 0) // w_stride + 1
preds = img.new_zeros((batch_size, num_classes, h_img, w_img))
count_mat = img.new_zeros((batch_size, 1, h_img, w_img))
for h_idx in range(h_grids):
for w_idx in range(w_grids):
y1 = h_idx * h_stride
x1 = w_idx * w_stride
y2 = min(y1 + h_crop, h_img)
x2 = min(x1 + w_crop, w_img)
y1 = max(y2 - h_crop, 0)
x1 = max(x2 - w_crop, 0)
crop_img = img[:, :, y1:y2, x1:x2]
crop_seg_logit = self.encode_decode(crop_img, img_meta)
preds += F.pad(crop_seg_logit,
(int(x1), int(preds.shape[3] - x2), int(y1),
int(preds.shape[2] - y2)))
count_mat[:, :, y1:y2, x1:x2] += 1
assert (count_mat == 0).sum() == 0
if torch.onnx.is_in_onnx_export():
# cast count_mat to constant while exporting to ONNX
count_mat = torch.from_numpy(
count_mat.cpu().detach().numpy()).to(device=img.device)
preds = preds / count_mat
if rescale:
preds = resize(
preds,
size=img_meta[0]['ori_shape'][:2],
mode='bilinear',
align_corners=self.align_corners,
warning=False)
return preds
def whole_inference(self, img, img_meta, rescale):
"""Inference with full image."""
seg_logit = self.encode_decode(img, img_meta)
if rescale:
# support dynamic shape for onnx
if torch.onnx.is_in_onnx_export():
size = img.shape[2:]
else:
size = img_meta[0]['ori_shape'][:2]
seg_logit = resize(
seg_logit,
size=size,
mode='bilinear',
align_corners=self.align_corners,
warning=False)
return seg_logit
def inference(self, img, img_meta, rescale):
"""Inference with slide/whole style.
Args:
img (Tensor): The input image of shape (N, 3, H, W).
img_meta (dict): Image info dict where each dict has: 'img_shape',
'scale_factor', 'flip', and may also contain
'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
For details on the values of these keys see
`mmseg/datasets/pipelines/formatting.py:Collect`.
rescale (bool): Whether rescale back to original shape.
Returns:
Tensor: The output segmentation map.
"""
assert self.test_cfg.mode in ['slide', 'whole']
ori_shape = img_meta[0]['ori_shape']
assert all(_['ori_shape'] == ori_shape for _ in img_meta)
if self.test_cfg.mode == 'slide':
seg_logit = self.slide_inference(img, img_meta, rescale)
else:
seg_logit = self.whole_inference(img, img_meta, rescale)
output = F.softmax(seg_logit, dim=1)
flip = img_meta[0]['flip']
if flip:
flip_direction = img_meta[0]['flip_direction']
assert flip_direction in ['horizontal', 'vertical']
if flip_direction == 'horizontal':
output = output.flip(dims=(3,))
elif flip_direction == 'vertical':
output = output.flip(dims=(2,))
return output
def simple_test(self, img, img_meta, rescale=True):
"""Simple test with single image."""
seg_logit = self.inference(img, img_meta, rescale)
seg_pred = seg_logit.argmax(dim=1)
if torch.onnx.is_in_onnx_export():
# our inference backend only support 4D output
seg_pred = seg_pred.unsqueeze(0)
return seg_pred
seg_pred = seg_pred.cpu().numpy()
# unravel batch dim
seg_pred = list(seg_pred)
return seg_pred
def aug_test(self, imgs, img_metas, rescale=True):
"""Test with augmentations.
Only rescale=True is supported.
"""
# aug_test rescale all imgs back to ori_shape for now
assert rescale
# to save memory, we get augmented seg logit inplace
seg_logit = self.inference(imgs[0], img_metas[0], rescale)
for i in range(1, len(imgs)):
cur_seg_logit = self.inference(imgs[i], img_metas[i], rescale)
seg_logit += cur_seg_logit
seg_logit /= len(imgs)
seg_pred = seg_logit.argmax(dim=1)
seg_pred = seg_pred.cpu().numpy()
# unravel batch dim
seg_pred = list(seg_pred)
return seg_pred
datasets
MapillaryDataset是一个继承自CustomDataset的自定义数据集类。它定义了Mapillary Vistas数据集的类别和调色板,以及数据集类的构造函数。
该数据集包含65个类别,每个类别都有一个对应的调色板颜色。数据集包含图像和分割掩码文件,文件名分别以.jpg和.png为后缀。在构造函数中,它指定了图像和分割掩码的后缀名,并将reduce_zero_label设置为False,以便在训练过程中保留所有标签。
mapillary.py
from mmseg.datasets.builder import DATASETS
from mmseg.datasets.custom import CustomDataset
@DATASETS.register_module()
class MapillaryDataset(CustomDataset):
"""Mapillary dataset.
"""
CLASSES = ('Bird', 'Ground Animal', 'Curb', 'Fence', 'Guard Rail', 'Barrier',
'Wall', 'Bike Lane', 'Crosswalk - Plain', 'Curb Cut', 'Parking', 'Pedestrian Area',
'Rail Track', 'Road', 'Service Lane', 'Sidewalk', 'Bridge', 'Building', 'Tunnel',
'Person', 'Bicyclist', 'Motorcyclist', 'Other Rider', 'Lane Marking - Crosswalk',
'Lane Marking - General', 'Mountain', 'Sand', 'Sky', 'Snow', 'Terrain', 'Vegetation',
'Water', 'Banner', 'Bench', 'Bike Rack', 'Billboard', 'Catch Basin', 'CCTV Camera',
'Fire Hydrant', 'Junction Box', 'Mailbox', 'Manhole', 'Phone Booth', 'Pothole',
'Street Light', 'Pole', 'Traffic Sign Frame', 'Utility Pole', 'Traffic Light',
'Traffic Sign (Back)', 'Traffic Sign (Front)', 'Trash Can', 'Bicycle', 'Boat',
'Bus', 'Car', 'Caravan', 'Motorcycle', 'On Rails', 'Other Vehicle', 'Trailer',
'Truck', 'Wheeled Slow', 'Car Mount', 'Ego Vehicle', 'Unlabeled')
PALETTE = [[165, 42, 42], [0, 192, 0], [196, 196, 196], [190, 153, 153],
[180, 165, 180], [90, 120, 150], [
102, 102, 156], [128, 64, 255],
[140, 140, 200], [170, 170, 170], [250, 170, 160], [96, 96, 96],
[230, 150, 140], [128, 64, 128], [
110, 110, 110], [244, 35, 232],
[150, 100, 100], [70, 70, 70], [150, 120, 90], [220, 20, 60],
[255, 0, 0], [255, 0, 100], [255, 0, 200], [200, 128, 128],
[255, 255, 255], [64, 170, 64], [230, 160, 50], [70, 130, 180],
[190, 255, 255], [152, 251, 152], [107, 142, 35], [0, 170, 30],
[255, 255, 128], [250, 0, 30], [100, 140, 180], [220, 220, 220],
[220, 128, 128], [222, 40, 40], [100, 170, 30], [40, 40, 40],
[33, 33, 33], [100, 128, 160], [142, 0, 0], [70, 100, 150],
[210, 170, 100], [153, 153, 153], [128, 128, 128], [0, 0, 80],
[250, 170, 30], [192, 192, 192], [220, 220, 0], [140, 140, 20],
[119, 11, 32], [150, 0, 255], [
0, 60, 100], [0, 0, 142], [0, 0, 90],
[0, 0, 230], [0, 80, 100], [128, 64, 64], [0, 0, 110], [0, 0, 70],
[0, 0, 192], [32, 32, 32], [120, 10, 10], [0, 0, 0]]
def __init__(self, **kwargs):
super(MapillaryDataset, self).__init__(
img_suffix='.jpg',
seg_map_suffix='.png',
reduce_zero_label=False,
**kwargs)
potsdam.py
PotsdamDataset是一个继承自CustomDataset的自定义数据集类。它定义了ISPRS Potsdam数据集的类别和调色板,以及数据集类的构造函数。
该数据集包含6个类别,每个类别都有一个对应的调色板颜色。数据集包含图像和分割掩码文件,文件名分别以.png为后缀。在分割掩码注释中,0是忽略的索引,因此reduce_zero_label被设置为True以在训练过程中忽略它。在构造函数中,它指定了图像和分割掩码的后缀名,并将reduce_zero_label设置为True。
# Copyright (c) OpenMMLab. All rights reserved.
from mmseg.datasets.builder import DATASETS
from mmseg.datasets.custom import CustomDataset
@DATASETS.register_module(force=True)
class PotsdamDataset(CustomDataset):
"""ISPRS Potsdam dataset.
In segmentation map annotation for Potsdam dataset, 0 is the ignore index.
``reduce_zero_label`` should be set to True. The ``img_suffix`` and
``seg_map_suffix`` are both fixed to '.png'.
"""
CLASSES = ('impervious_surface', 'building', 'low_vegetation', 'tree',
'car', 'clutter')
PALETTE = [[255, 255, 255], [0, 0, 255], [0, 255, 255], [0, 255, 0],
[255, 255, 0], [255, 0, 0]]
def __init__(self, **kwargs):
super(PotsdamDataset, self).__init__(
img_suffix='.png',
seg_map_suffix='.png',
reduce_zero_label=True,
**kwargs)
pipelines
formatting.py
# Copyright (c) OpenMMLab. All rights reserved.
import numpy as np
from mmcv.parallel import DataContainer as DC
from mmseg.datasets.builder import PIPELINES
from mmseg.datasets.pipelines.formatting import to_tensor
@PIPELINES.register_module(force=True)
class DefaultFormatBundle(object):
"""Default formatting bundle.
It simplifies the pipeline of formatting common fields, including "img"
and "gt_semantic_seg". These fields are formatted as follows.
- img: (1)transpose, (2)to tensor, (3)to DataContainer (stack=True)
- gt_semantic_seg: (1)unsqueeze dim-0 (2)to tensor,
(3)to DataContainer (stack=True)
"""
def __call__(self, results):
"""Call function to transform and format common fields in results.
Args:
results (dict): Result dict contains the data to convert.
Returns:
dict: The result dict contains the data that is formatted with
default bundle.
"""
if 'img' in results:
img = results['img']
if len(img.shape) < 3:
img = np.expand_dims(img, -1)
img = np.ascontiguousarray(img.transpose(2, 0, 1))
results['img'] = DC(to_tensor(img), stack=True)
if 'gt_semantic_seg' in results:
# convert to long
results['gt_semantic_seg'] = DC(to_tensor(
results['gt_semantic_seg'][None, ...].astype(np.int64)),
stack=True)
if 'gt_masks' in results:
results['gt_masks'] = DC(to_tensor(results['gt_masks']))
if 'gt_labels' in results:
results['gt_labels'] = DC(to_tensor(results['gt_labels']))
return results
def __repr__(self):
return self.__class__.__name__
@PIPELINES.register_module()
class ToMask(object):
"""Transfer gt_semantic_seg to binary mask and generate gt_labels."""
def __init__(self, ignore_index=255):
self.ignore_index = ignore_index
def __call__(self, results):
gt_semantic_seg = results['gt_semantic_seg']
gt_labels = np.unique(gt_semantic_seg)
# remove ignored region
gt_labels = gt_labels[gt_labels != self.ignore_index]
gt_masks = []
for class_id in gt_labels:
gt_masks.append(gt_semantic_seg == class_id)
if len(gt_masks) == 0:
# Some image does not have annotation (all ignored)
gt_masks = np.empty((0, ) + results['pad_shape'][:-1], dtype=np.int64)
gt_labels = np.empty((0, ), dtype=np.int64)
else:
gt_masks = np.asarray(gt_masks, dtype=np.int64)
gt_labels = np.asarray(gt_labels, dtype=np.int64)
results['gt_labels'] = gt_labels
results['gt_masks'] = gt_masks
return results
def __repr__(self):
return self.__class__.__name__ + \
f'(ignore_index={self.ignore_index})'
transform.py
这是一个用于图像分割的自定义数据增强流水线的Python脚本,使用了流行的开源框架mmsegmentation。该流水线包括一个名为SETR_Resize的类,它可以将图像和相应的分割掩模调整到指定的比例或一系列比例,使用不同的模式。
SETR_Resize类的构造函数接受多个参数,包括img_scale、multiscale_mode、ratio_range、keep_ratio、crop_size和setr_multi_scale。img_scale参数指定图像和掩模调整的比例或比例列表。multiscale_mode参数指定选择比例的模式,可以是“range”或“value”。如果模式为“range”,则从ratio_range指定的范围中随机采样比例。如果模式为“value”,则从比例列表中随机采样比例。keep_ratio参数确定在调整大小时是否保持图像的宽高比。crop_size参数指定裁剪图像的大小。setr_multi_scale参数是一个布尔标志,指示是否在SETR模型中使用多尺度训练。
该脚本还定义了两个静态方法,用于随机选择和采样图像比例,分别是random_select和random_sample。这些方法由SETR_Resize类使用,根据指定的模式随机选择或采样图像比例。
总的来说,该脚本提供了一种灵活和可定制的方式,使用mmsegmentation对图像和掩模进行预处理,用于图像分割任务。
import mmcv
import numpy as np
import torch
from mmseg.datasets.builder import PIPELINES
@PIPELINES.register_module()
class SETR_Resize(object):
"""Resize images & seg.
This transform resizes the input image to some scale. If the input dict
contains the key "scale", then the scale in the input dict is used,
otherwise the specified scale in the init method is used.
``img_scale`` can either be a tuple (single-scale) or a list of tuple
(multi-scale). There are 3 multiscale modes:
- ``ratio_range is not None``: randomly sample a ratio from the ratio range
and multiply it with the image scale.
- ``ratio_range is None and multiscale_mode == "range"``: randomly sample a
scale from the a range.
- ``ratio_range is None and multiscale_mode == "value"``: randomly sample a
scale from multiple scales.
Args:
img_scale (tuple or list[tuple]): Images scales for resizing.
multiscale_mode (str): Either "range" or "value".
ratio_range (tuple[float]): (min_ratio, max_ratio)
keep_ratio (bool): Whether to keep the aspect ratio when resizing the
image.
"""
def __init__(self,
img_scale=None,
multiscale_mode='range',
ratio_range=None,
keep_ratio=True,
crop_size=None,
setr_multi_scale=False):
if img_scale is None:
self.img_scale = None
else:
if isinstance(img_scale, list):
self.img_scale = img_scale
else:
self.img_scale = [img_scale]
# assert mmcv.is_list_of(self.img_scale, tuple)
if ratio_range is not None:
# mode 1: given a scale and a range of image ratio
assert len(self.img_scale) == 1
else:
# mode 2: given multiple scales or a range of scales
assert multiscale_mode in ['value', 'range']
self.multiscale_mode = multiscale_mode
self.ratio_range = ratio_range
self.keep_ratio = keep_ratio
self.crop_size = crop_size
self.setr_multi_scale = setr_multi_scale
@staticmethod
def random_select(img_scales):
"""Randomly select an img_scale from given candidates.
Args:
img_scales (list[tuple]): Images scales for selection.
Returns:
(tuple, int): Returns a tuple ``(img_scale, scale_dix)``,
where ``img_scale`` is the selected image scale and
``scale_idx`` is the selected index in the given candidates.
"""
assert mmcv.is_list_of(img_scales, tuple)
scale_idx = np.random.randint(len(img_scales))
img_scale = img_scales[scale_idx]
return img_scale, scale_idx
@staticmethod
def random_sample(img_scales):
"""Randomly sample an img_scale when ``multiscale_mode=='range'``.
Args:
img_scales (list[tuple]): Images scale range for sampling.
There must be two tuples in img_scales, which specify the lower
and uper bound of image scales.
Returns:
(tuple, None): Returns a tuple ``(img_scale, None)``, where
``img_scale`` is sampled scale and None is just a placeholder
to be consistent with :func:`random_select`.
"""
assert mmcv.is_list_of(img_scales, tuple) and len(img_scales) == 2
img_scale_long = [max(s) for s in img_scales]
img_scale_short = [min(s) for s in img_scales]
long_edge = np.random.randint(
min(img_scale_long),
max(img_scale_long) + 1)
short_edge = np.random.randint(
min(img_scale_short),
max(img_scale_short) + 1)
img_scale = (long_edge, short_edge)
return img_scale, None
@staticmethod
def random_sample_ratio(img_scale, ratio_range):
"""Randomly sample an img_scale when ``ratio_range`` is specified.
A ratio will be randomly sampled from the range specified by
``ratio_range``. Then it would be multiplied with ``img_scale`` to
generate sampled scale.
Args:
img_scale (tuple): Images scale base to multiply with ratio.
ratio_range (tuple[float]): The minimum and maximum ratio to scale
the ``img_scale``.
Returns:
(tuple, None): Returns a tuple ``(scale, None)``, where
``scale`` is sampled ratio multiplied with ``img_scale`` and
None is just a placeholder to be consistent with
:func:`random_select`.
"""
assert isinstance(img_scale, tuple) and len(img_scale) == 2
min_ratio, max_ratio = ratio_range
assert min_ratio <= max_ratio
ratio = np.random.random_sample() * (max_ratio - min_ratio) + min_ratio
scale = int(img_scale[0] * ratio), int(img_scale[1] * ratio)
return scale, None
def _random_scale(self, results):
"""Randomly sample an img_scale according to ``ratio_range`` and
``multiscale_mode``.
If ``ratio_range`` is specified, a ratio will be sampled and be
multiplied with ``img_scale``.
If multiple scales are specified by ``img_scale``, a scale will be
sampled according to ``multiscale_mode``.
Otherwise, single scale will be used.
Args:
results (dict): Result dict from :obj:`dataset`.
Returns:
dict: Two new keys 'scale` and 'scale_idx` are added into
``results``, which would be used by subsequent pipelines.
"""
if self.ratio_range is not None:
scale, scale_idx = self.random_sample_ratio(
self.img_scale[0], self.ratio_range)
elif len(self.img_scale) == 1:
scale, scale_idx = self.img_scale[0], 0
elif self.multiscale_mode == 'range':
scale, scale_idx = self.random_sample(self.img_scale)
elif self.multiscale_mode == 'value':
scale, scale_idx = self.random_select(self.img_scale)
else:
raise NotImplementedError
results['scale'] = scale
results['scale_idx'] = scale_idx
def _resize_img(self, results):
"""Resize images with ``results['scale']``."""
if self.keep_ratio:
if self.setr_multi_scale:
if min(results['scale']) < self.crop_size[0]:
new_short = self.crop_size[0]
else:
new_short = min(results['scale'])
h, w = results['img'].shape[:2]
if h > w:
new_h, new_w = new_short * h / w, new_short
else:
new_h, new_w = new_short, new_short * w / h
results['scale'] = (new_h, new_w)
img, scale_factor = mmcv.imrescale(results['img'],
results['scale'],
return_scale=True)
# the w_scale and h_scale has minor difference
# a real fix should be done in the mmcv.imrescale in the future
new_h, new_w = img.shape[:2]
h, w = results['img'].shape[:2]
w_scale = new_w / w
h_scale = new_h / h
else:
img, w_scale, h_scale = mmcv.imresize(results['img'],
results['scale'],
return_scale=True)
scale_factor = np.array([w_scale, h_scale, w_scale, h_scale],
dtype=np.float32)
results['img'] = img
results['img_shape'] = img.shape
results['pad_shape'] = img.shape # in case that there is no padding
results['scale_factor'] = scale_factor
results['keep_ratio'] = self.keep_ratio
def _resize_seg(self, results):
"""Resize semantic segmentation map with ``results['scale']``."""
for key in results.get('seg_fields', []):
if self.keep_ratio:
gt_seg = mmcv.imrescale(results[key],
results['scale'],
interpolation='nearest')
else:
gt_seg = mmcv.imresize(results[key],
results['scale'],
interpolation='nearest')
results['gt_semantic_seg'] = gt_seg
def __call__(self, results):
"""Call function to resize images, bounding boxes, masks, semantic
segmentation map.
Args:
results (dict): Result dict from loading pipeline.
Returns:
dict: Resized results, 'img_shape', 'pad_shape', 'scale_factor',
'keep_ratio' keys are added into result dict.
"""
if 'scale' not in results:
self._random_scale(results)
self._resize_img(results)
self._resize_seg(results)
return results
def __repr__(self):
repr_str = self.__class__.__name__
repr_str += (f'(img_scale={self.img_scale}, '
f'multiscale_mode={self.multiscale_mode}, '
f'ratio_range={self.ratio_range}, '
f'keep_ratio={self.keep_ratio})')
return repr_str
@PIPELINES.register_module()
class PadShortSide(object):
"""Pad the image & mask.
Pad to the minimum size that is equal or larger than a number.
Added keys are "pad_shape", "pad_fixed_size",
Args:
size (int, optional): Fixed padding size.
pad_val (float, optional): Padding value. Default: 0.
seg_pad_val (float, optional): Padding value of segmentation map.
Default: 255.
"""
def __init__(self, size=None, pad_val=0, seg_pad_val=255):
self.size = size
self.pad_val = pad_val
self.seg_pad_val = seg_pad_val
# only one of size and size_divisor should be valid
assert size is not None
def _pad_img(self, results):
"""Pad images according to ``self.size``."""
h, w = results['img'].shape[:2]
new_h = max(h, self.size)
new_w = max(w, self.size)
padded_img = mmcv.impad(results['img'],
shape=(new_h, new_w),
pad_val=self.pad_val)
results['img'] = padded_img
results['pad_shape'] = padded_img.shape
# results['unpad_shape'] = (h, w)
def _pad_seg(self, results):
"""Pad masks according to ``results['pad_shape']``."""
for key in results.get('seg_fields', []):
results[key] = mmcv.impad(results[key],
shape=results['pad_shape'][:2],
pad_val=self.seg_pad_val)
def __call__(self, results):
"""Call function to pad images, masks, semantic segmentation maps.
Args:
results (dict): Result dict from loading pipeline.
Returns:
dict: Updated result dict.
"""
h, w = results['img'].shape[:2]
if h >= self.size and w >= self.size: # 短边比窗口大,跳过
pass
else:
self._pad_img(results)
self._pad_seg(results)
return results
def __repr__(self):
repr_str = self.__class__.__name__
repr_str += f'(size={self.size}, pad_val={self.pad_val})'
return repr_str
@PIPELINES.register_module()
class MapillaryHack(object):
"""map MV 65 class to 19 class like Cityscapes."""
def __init__(self):
self.map = [[13, 24, 41], [2, 15], [17], [6], [3],
[45, 47], [48], [50], [30], [29], [27], [19], [20, 21, 22],
[55], [61], [54], [58], [57], [52]]
self.others = [i for i in range(66)]
for i in self.map:
for j in i:
if j in self.others:
self.others.remove(j)
def __call__(self, results):
"""Call function to process the image with gamma correction.
Args:
results (dict): Result dict from loading pipeline.
Returns:
dict: Processed results.
"""
gt_map = results['gt_semantic_seg']
# others -> 255
new_gt_map = np.zeros_like(gt_map)
for value in self.others:
new_gt_map[gt_map == value] = 255
for index, map in enumerate(self.map):
for value in map:
new_gt_map[gt_map == value] = index
results['gt_semantic_seg'] = new_gt_map
return results
def __repr__(self):
repr_str = self.__class__.__name__
return repr_str
mmsegmentation 是一个基于 PyTorch 的开源图像分割框架,由香港中文大学的计算机视觉团队开发。它提供了丰富的图像分割模型和训练/测试流程,支持各种图像分割任务,如语义分割、实例分割、轮廓分割等,并且非常易于使用和扩展。
mmsegmentation包括多个模块,如数据集、模型、优化器和调度器等,同时提供了丰富的预处理和后处理工具,如随机裁剪、随机翻转、多尺度训练和测试等。用户可以根据自己的需求选择不同的模块和工具,构建自己的图像分割流水线。
mmsegmentation中支持的模型包括传统的 U-Net、FCN、SegNet 等,还包括最新的一些模型,如 DeepLabV3、HRNet、OCRNet、SETR 等。这些模型在各种图像分割任务上表现出色,并且在一些比赛中取得了最好的结果。
总之,mmsegmentation 是一个功能强大、易于使用的图像分割框架,适用于各种应用场景和用户需求。