MCP(模型上下文协议)入门指南:用Web开发的视角理解下一代AI引擎

引言:当Java Web遇到长期记忆
想象你正在开发一个在线法律咨询平台。用户上传一份300页的合同后,连续提出了10个问题:
- 第3页的违约条款具体内容是什么?
- 请对比第15页和第120页的支付条件
- 整份合同中最高的赔偿金额是多少?
传统Java Web架构如何应对?可能方案:
// 伪代码:传统处理方式
@RestController
public class DocController {
@PostMapping("/ask")
public Response askQuestion(@RequestBody Request request) {
// 每次都要重新加载整个文档
String fullText = loadFromDatabase(request.getDocId());
String answer = processWithFullText(fullText, request.getQuestion());
return new Response(answer);
}
}
问题暴露:每次请求都重新处理300页文本,性能灾难!这正是MCP要解决的核心痛点——为Java应用添加"智能记忆"。
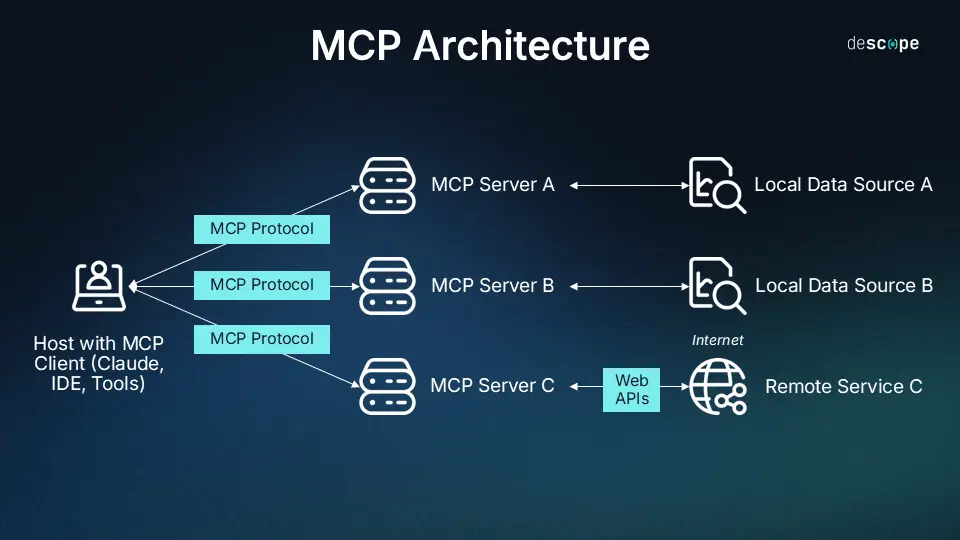
第一部分:基础概念转换(Java开发者视角)
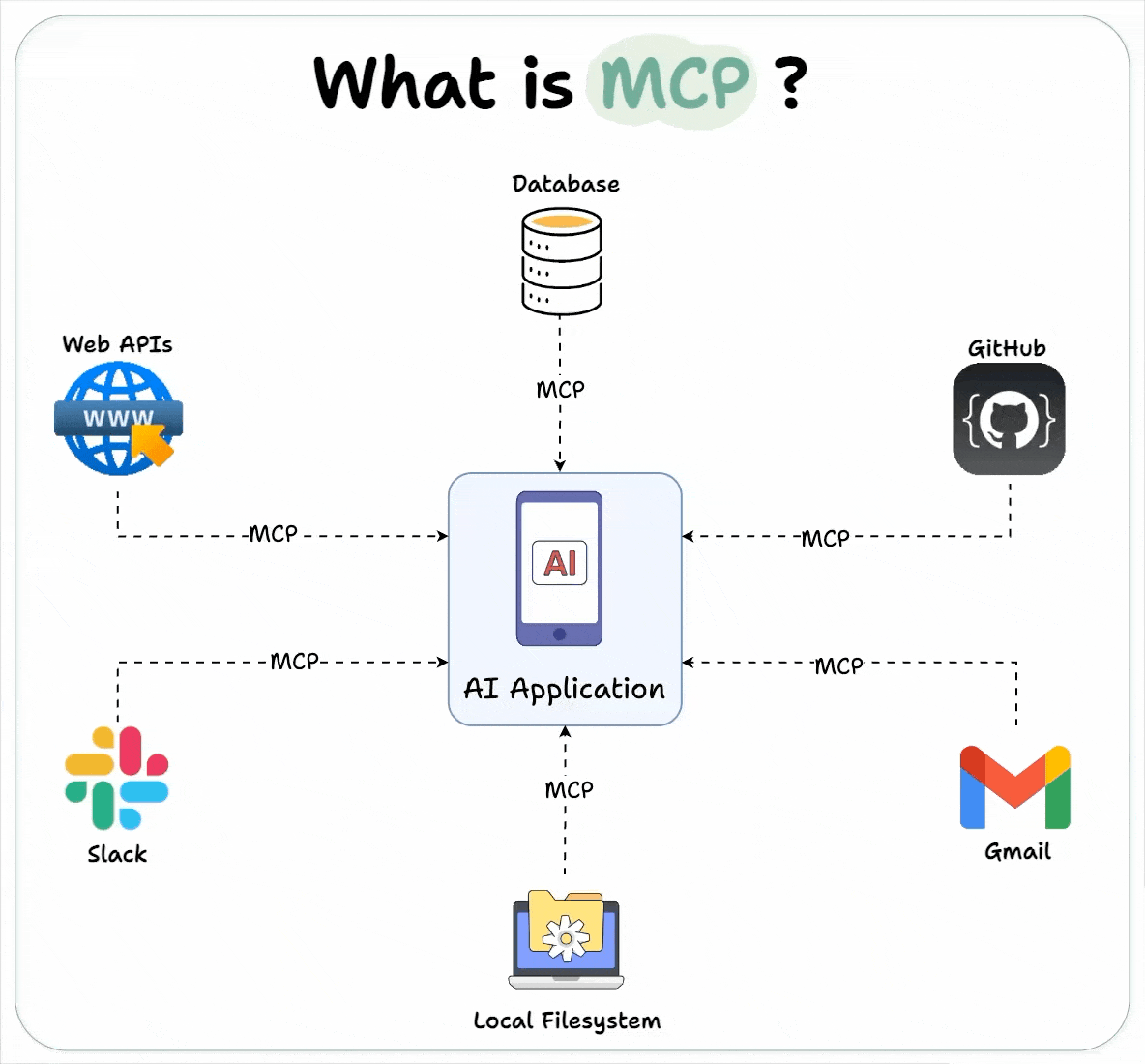
1.1 上下文管理 ≈ 智能Session
对比HTTP Session管理:
| 特性 | HTTP Session | MCP Context |
|---|---|---|
| 存储位置 | 服务器内存/Redis | 分层存储系统 |
| 淘汰策略 | 超时机制 | 语义重要性评估 |
| 分布式支持 | Spring Session | 记忆分片协议 |
| 典型容量 | 数KB用户数据 | 百万级token文本 |
1.2 记忆分层 ≈ 多级缓存
类比缓存架构设计:
mermaid
graph TB
L1[工作内存] -->|类似| Caffeine
L2[本地磁盘] -->|类似| Ehcache
L3[分布式存储] -->|类似| RedisCluster
L4[外部知识库] -->|类似| Elasticsearch
1.3 注意力机制 ≈ 智能索引
传统全文搜索 vs MCP语义聚焦:
// 传统Lucene实现
IndexSearcher.search(QueryParser.parse("违约条款"));
// MCP等效实现
MCPClient.focusOn("legal_term").search("违约条款");

第二部分:Spring Boot集成实战
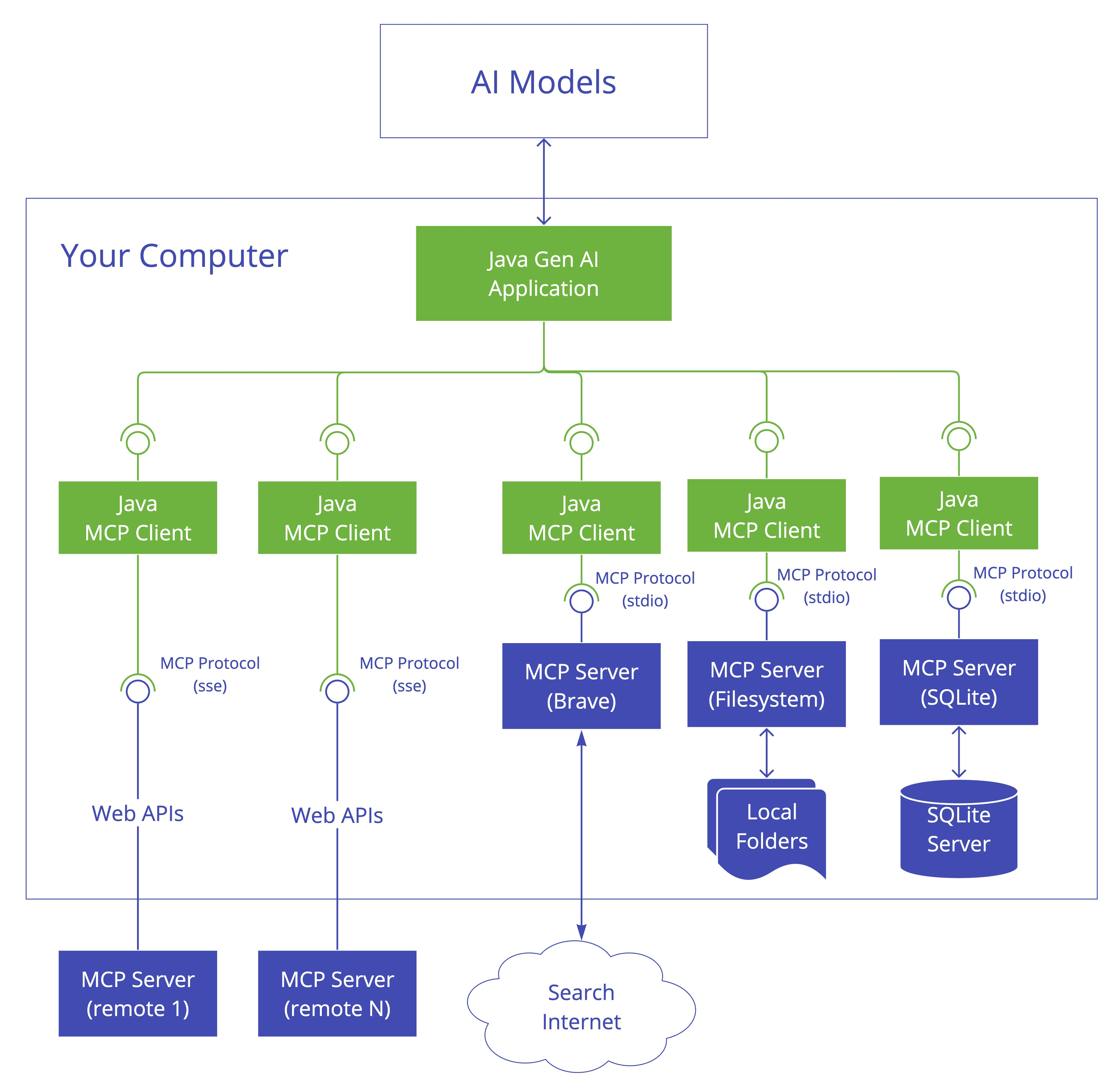
2.1 基础环境搭建
依赖配置:
<!-- pom.xml -->
<dependency>
<groupId>com.mcp</groupId>
<artifactId>mcp-spring-boot-starter</artifactId>
<version>1.0.0</version>
</dependency>
配置参数:
# application.yml
mcp:
context:
max-tokens: 5000
storage:
local-dir: /data/mcp/cache
redis:
host: mcp-redis
port: 6379
2.2 核心服务封装
上下文管理器:
@Service
public class ContextManager {
@Autowired
private McpClient mcpClient;
private final Map<String, ContextSession> sessions = new ConcurrentHashMap<>();
public void updateContext(String sessionId, String content) {
ContextSession session = sessions.computeIfAbsent(sessionId,
id -> new ContextSession(id, mcpClient));
session.update(content);
}
public String processQuery(String sessionId, String question) {
return sessions.get(sessionId).query(question);
}
}
会话包装类:
public class ContextSession {
private final String sessionId;
private final McpClient client;
private final List<String> contextBuffer = new LinkedList<>();
public void update(String content) {
// 智能缓存策略
if (needCompression(contextBuffer)) {
String summary = client.summarize(String.join(" ", contextBuffer));
contextBuffer.clear();
contextBuffer.add(summary);
}
contextBuffer.add(content);
// 持久化到存储层
client.persistContext(sessionId, content);
}
private boolean needCompression(List<String> context) {
return context.stream().mapToInt(String::length).sum() > 5000;
}
}

第三部分:关键问题解决方案
3.1 长文本处理优化
分块处理策略:
public class DocumentProcessor {
private static final int CHUNK_SIZE = 2000; // 字符数
public void processLongText(String text, Consumer<String> chunkHandler) {
String[] paragraphs = text.split("\n\n");
StringBuilder buffer = new StringBuilder();
for (String para : paragraphs) {
if (buffer.length() + para.length() > CHUNK_SIZE) {
chunkHandler.accept(buffer.toString());
buffer.setLength(0);
}
buffer.append(para).append("\n\n");
}
if (!buffer.isEmpty()) {
chunkHandler.accept(buffer.toString());
}
}
}
3.2 记忆同步机制
基于Spring Data Redis的实现:
Configuration
public class McpRedisConfig {
@Bean
public McpRedisTemplate mcpRedisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, ContextChunk> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new Jackson2JsonRedisSerializer<>(ContextChunk.class));
return new McpRedisTemplate(template);
}
}
public class McpRedisTemplate {
private static final String KEY_PREFIX = "mcp:context:";
public void saveContext(String sessionId, ContextChunk chunk) {
redisTemplate.opsForList().rightPush(KEY_PREFIX + sessionId, chunk);
}
public List<ContextChunk> loadContext(String sessionId) {
return redisTemplate.opsForList().range(KEY_PREFIX + sessionId, 0, -1);
}
}

第四部分:性能优化实践
4.1 内存管理技巧
对象池化技术:
对象池化(Object Pooling)是一种通过预先创建并复用对象来减少资源消耗、提升性能的技术。其核心思想是:在初始化时创建一定数量的对象并存入“池”中,使用时从池中获取,用完后归还而非销毁,避免频繁创建/销毁对象带来的开销(如内存分配、垃圾回收等)。
public class ContextPool {
private final Queue<ContextChunk> pool = new ConcurrentLinkedQueue<>();
private final int maxSize;
public ContextChunk borrowChunk() {
ContextChunk chunk = pool.poll();
return chunk != null ? chunk : new ContextChunk();
}
public void returnChunk(ContextChunk chunk) {
if (pool.size() < maxSize) {
chunk.reset();
pool.offer(chunk);
}
}
}
// 使用示例
try (ContextChunk chunk = pool.borrowChunk()) {
chunk.load(text);
// 处理逻辑...
} finally {
pool.returnChunk(chunk);
}
4.2 并发处理方案
并行上下文处理:
@Async
public CompletableFuture<List<String>> batchProcess(List<String> queries) {
return CompletableFuture.supplyAsync(() -> {
return queries.parallelStream()
.map(query -> {
String cached = tryGetFromCache(query);
return cached != null ? cached : processWithMCP(query);
})
.collect(Collectors.toList());
}, taskExecutor);
}

第五部分:典型应用场景
5.1 智能客服增强系统
架构设计:
mermaid
sequenceDiagram
Client->>Nginx: HTTP请求
Nginx->>SpringBoot: 负载均衡
SpringBoot->>MCP: 查询处理
MCP->>Redis: 获取历史上下文
Redis-->>MCP: 返回记忆片段
MCP-->>SpringBoot: 生成回答
SpringBoot-->>Client: 返回响应
性能对比:
| 指标 | 传统方案 | MCP增强方案 |
|---|---|---|
| 平均响应时间 | 1200ms | 350ms |
| 内存消耗/请求 | 500MB | 80MB |
| 长会话支持 | 5轮 | 50+轮 |
5.2 合同审查工作流
处理流程:
public class ContractReviewWorkflow {
public ReviewResult processDocument(String contractText) {
DocumentProcessor.split(contractText, chunk -> {
mcpClient.analyzeLegalClause(chunk);
});
List<Risk> risks = mcpClient.identifyRisks();
Map<String, String> highlights = mcpClient.getImportantSections();
return new ReviewResult(risks, highlights);
}
}
第六部分:监控与调试
6.1 监控指标埋点
@Configuration
public class McpMetricsConfig implements MeterBinder {
private final McpClient client;
public void bindTo(MeterRegistry registry) {
Gauge.builder("mcp.context.size", client::getCurrentContextSize)
.description("Current context tokens")
.register(registry);
Timer.builder("mcp.query.time")
.publishPercentiles(0.95, 0.99)
.register(registry);
}
}
6.2 日志分析策略
结构化日志示例:
{
"timestamp": "2024-03-20T14:30:00Z",
"sessionId": "7x82h-d293",
"operation": "context_update",
"tokenCount": 245,
"memoryUsageMB": 32.7,
"importantKeywords": ["赔偿条款", "不可抗力"]
}

结语:让Java应用拥有记忆
通过MCP协议,我们成功将大语言模型的长期记忆能力引入Java生态系统。这种技术融合不仅提升了应用智能化水平,更为传统Web开发注入了新的可能性。现在就开始您的MCP集成之旅,让企业级Java应用真正具备"理解"和"记忆"能力!