Linux中的调试器gdb与冯·诺伊曼体系
一、Linux中的调试器:gdb
1.1安装与版本查看
可以使用yum进行安装:
yum install -y gdb
版本查看:使用指令
gdb --version

1.2调试的先决条件:release版本与debug版本的切换
debug版本:含有调试信息
release版本:无调试信息
如果我们需要进行调试,则必须选择debug版本
gcc/g++默认的是release版本,如果要更浑阿伟debug,需要在gcc后加上-g选项
如:

可执行程序的具体信息可以利用
file+[可执行程序]
来进行查看(debug和release模式在ubuntu系统下会有信息上的区别,但CentOS只能看到程序大小上的差距)
1.3调试的使用
进入gdb的指令:
gdb+[可运行程序]

1.3.1简单的使用
一般我们在VS2022调试过程中,用到的功能主要是(冒号后就是对应的指令)
打断点:b
删断点:d
运行到第一个断点处:r
一个断点运行到下一个断点:c
F10逐过程:n
F11逐语句:s
监视窗口:display/p
1.3.2具体的调试指令
①查看代码(推荐使用cgdb)
1>l+[行号] 可以一次展示十行代码,会尽量展示行号上下五行

2>l+[函数名] 列出指定函数位置的上下五行代码

3>l+[文件名]+[行号] 列出指定文件 对应行号的上下五行
注:gdb会默认记录最近的一次指令,直接回车就继续/重新执行它
②断点设置/删除
1>打断点
b+[行号]
b+[文件名]+[行号]
b+[文件名]:[函数名]
2>查看断点信息
info b
可以查看对应断点的编号
3>删除断点
d+[断点序号]
注:在一次调试下,断点的序号只会线性递增
4>禁用断点
disable+[断点序号]
5>启用断点
enable+[断点序号]
③启动程序
1>断点间运行
r
直接开始运行,运行第一个断点,没有的话到结束
c
是continue的简写,从一个断点运行到下一个断点(如果遇到错误,会告知错误在哪一行)
2>逐步调试
n
是next的简写,相当于VS2022中的F10,逐过程运行(单步执行,不进入函数内部)
s
是step的简写,相当于VS2022中的F11,逐语句调试,可以进函数
3>运行函数栈的查看
bt
可以查看函数栈(所谓函数栈其实就是当前调用函数列表,在汇编层面需要借助栈这种数据结构来辅助组织函数的调用与返回)

4>变量名的展示
display+[变量名]
相当于调试的监视窗口,之后n的时候会自动显示
p+[变量名]
相当于调试的监视窗口,之后n的时候不会自动显示(但是p可以用来查表达式)
info locals
自动监视窗口,一次性查看
undisplay+[监视列表中变量的序号]
不同于添加监视使用变量名,undisplay使用的是监视列表中的序号来确定移除对哪一个变量的监视
watch+[变量名]
对一个变量添加隐式监视,在变量值改变的时候会停止运行并显式部分内容,未改变则不会显示
他也类似于一种断点,会有编号,删除方式与普通断点相同

4>快速执行
until+[行数]
快速执行/回退到对应行
finish
快速执行完当前函数
④退出调试
quit
退出调试模式
⑤调试期间修改值
set var [变量=?]
如set var i=5;
这个功能支持我们运行中进行修改尝试
1.3补:条件断点
条件断点打法有两种
①新增
b+[行号]+if+[条件]
如
b 11 if n==6
②为已有的断点添加条件
condition+[断点编号]+[条件]
如condition 2 n==6
1.4更方便的cgdb(推荐)
依旧可以使用yum进行安装
yum install -y cgdb
他与gdb唯一的区别就是将代码和终端同时展示
gdb:
cgdb:

在cgdb中,可以使用ESC键切换光标到上窗口,再按i键返回命令行中
1.5调试过程遇到问题的处理
1.5.1首先明确调试的本质
调试本质上是为了找到并定位问题,而解决问题的是程序员
1.5.2结合例子理解
假如在代码中添加一个除以0的错误

运行到最后会提示

打印的是inf这样一个未知的值 ,由此可以定位到f的计算过程有问题,进而进行修改
1.5.3调试过程推荐的指令组合
cgdb中比较常用的一个组合是:断点+finish+until+c
用来对大的代码块区间进行debug
二、冯·诺伊曼体系
2.1体系结构图示

①输入设备: 如键盘,鼠标,网卡,磁盘(又名外存),摄像头等等
②输出设备:如显示屏,磁盘,网卡,打印机等等
③存储器:就是内存
④CPU:由运算器和控制器构成
2.2分析体系结构得出的结论
控制信号上:CPU可以直接与输入/输出设备进行交互
数据信号上:不管是从键盘读取数据交给CPU处理,还是从磁盘读取数据供运算需要,都要经历内存才能到达CPU
总结可以得出结论:
①CPU在数据层面,不与外设直接打交道,只会和内存进行交互
因此:任何程序在运行的时候,都必须先(从磁盘)加载到内存
例如一个二进制程序本质上是一个文件,文件存储在磁盘中,磁盘是一种外部设备
②Input本质上就是从输入设备向存储器传输的过程
Onput本质上就是从存储器向输出设备传输的过程

2.3冯诺依曼体系在实践中的体现
例如张三和李四通过自己的电脑在两地间通信:

这期间他们每个人都是一个冯诺依曼体系,张三写的消息经过内存加密后,Output到网卡中
然后通过网络将加密消息发送到李四的网卡中,然后Input到内存中进行解密,最后加载到显示器上
综上,数据在不同计算机内部流转的时候,本质是在不同的设备间进行拷贝
2.4为什么要有内存(即存储器位置)
假设没有内存,那么就会变成这样:

CPU直接和外设打交道,会因为木桶效应:虽然CPU的效率远高于外设,但是外设的效率很低,所以会造成总体效率很低,因此需要通过在CPU和外设之间一个“巨大的缓存”来避免CPU直接和外设打交道
那为什么这个“巨大的缓存”必须是内存呢?
其实它的功能也可以通过寄存器或者三级缓存来实现,
但他们的造价太高了,平常人难以负担,计算机就无法普及大众
存储金字塔:
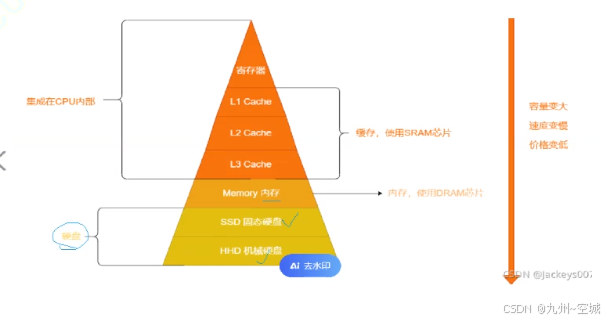
因此,正因为有了内存,才有如今互联网的局面