大模型应用开发之RAG学习
一:背景:如何让大模型能够回答专业领域的问题呢?
这个如何理解呢?说白了大模型本身是基于一些通用领域的语料库去进行训练的,如果你想让它回答比如医疗领域或者化工领域的问题它就回答的不是很准了,这个时候我们一般有两个办法
1.1 : 不改变模型,在提问的时候我们就传入对应的一些背景知识让大模型理解,然后回答问题
1.2: 改变模型,我们加入专业领域的这些知识作为底层数据,然后重新训练下模型
大家可能比较想要的是第一种方案,毕竟相对来说比较省时省力嘛,因为训练一个大模型的成本相对来说比较高,尤其是对于一些中小型公司来说,但是有的时候如果对应的背景知识太长了就不好处理,所以我们就需要用到一种办法,RAG
二:什么是RAG
RAG的全称是Retrieval Augumented Generation, 翻译过来就是检索增强式生成,那么它对应的工作原理是什么呢?对应的步骤如下所示,分成了两个步骤,分别是建立索引阶段和检索与生成阶段
2.1: RAG 建立索引阶段
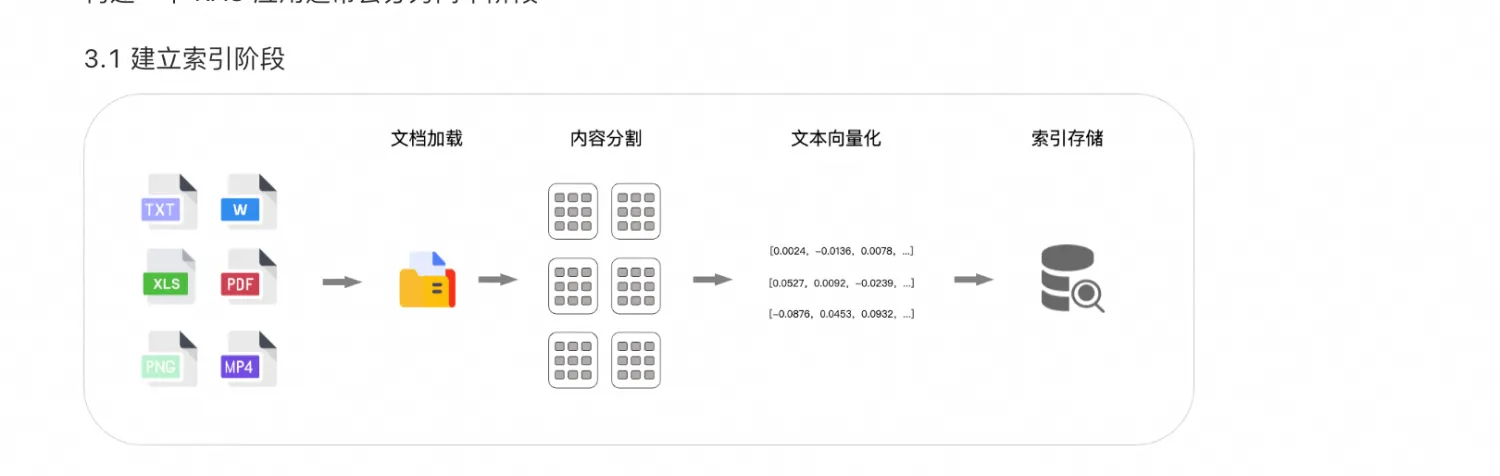
建立索引说白了就是把我们的私有资料分成一个个片段,然后有索引和这些片段链接,方便我们查找这些片段的内容,它分成四步:
2.1.1: 文档加载
说白了,就是把我们对应的文档资料加载进来,相当于我们开卷考试的时候找到了相关的资料,先把它存储起来,方便后续的使用
2.1.2: 文档分片
我们在找到一些相关的资料后,可能这些资料相对来说比较多,我们就需要根据内容把这些资料分成一个个片段,方便更加快速的查找
2.1.3: 文本向量化
因为计算机只能理解数字,他理解不了文本,所以我们就需要把这些文本进行向量化,方便计算机理解
2.1.4: 索引建立
上述得到的一个个向量,我们可以让计算机给他们编号,比如从1到500编号,这就是我们所说的索引了,这样的话就不需要每次回答时把对应的向量存入进去,从而可以节省时间;这里的索引我的理解是会进行两个存储,分别是向量和索引以及文本内容与索引,这样的话就可以找到向量之后快速找到对应的文本内容嘛
2.2: 检索与生成阶段
上述索引建立好了以后,那么客户提问后如何使用这个索引呢?这就是RAG的第二个阶段了,检索与生成阶段,如下所示,分成了两个步骤
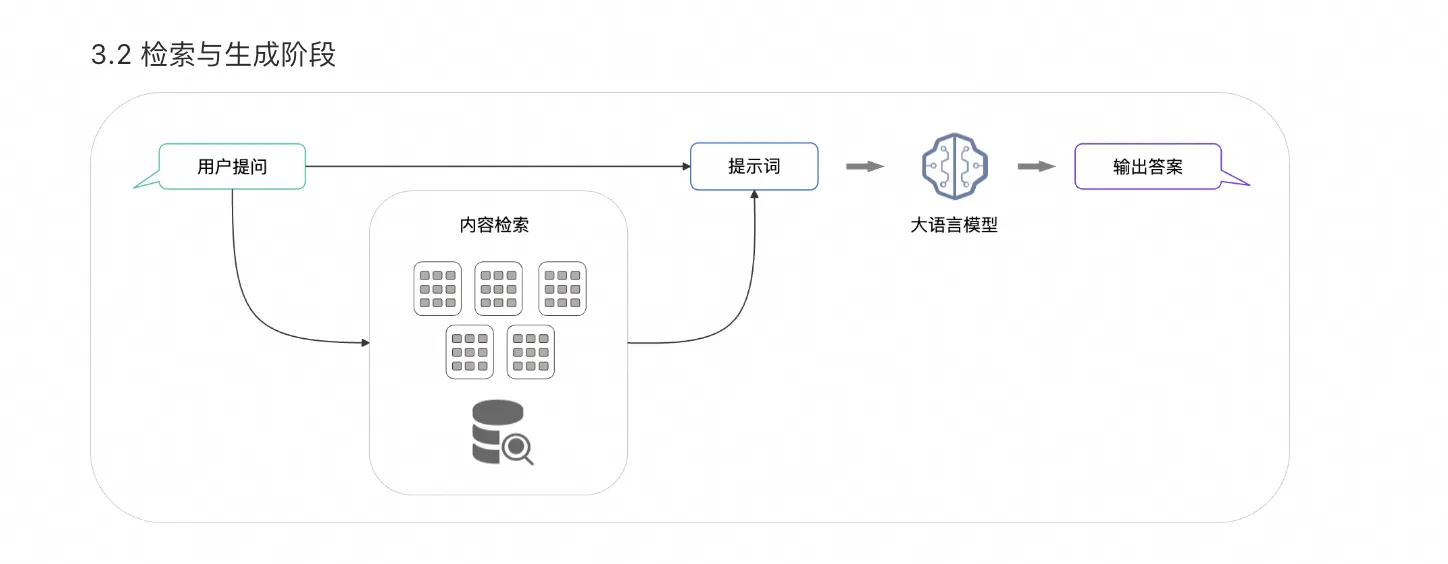
2.2.1: 检索阶段
这个步骤就是说用户提过来问题之后,首先我们会使用相应的方法把用户的问题进行一个向量化,然后去我们的那个向量化数据库找到最相似的向量并进而找到对应的文本,这一步是最重要的,就像我们开卷考试如果没找到准确的参考资料,这个考试岂不是会错了
2.2.2: 生成
这一步就是把上述找到的文本和我们用户的提问一并输入给大模型,让大模型去回答,其实这一步更多的是利用大模型的总结能力,而不是大模型的生成能力,一般这个时候就会使用一些特定的提示词模版给到大模型,一个典型的提示词模板为:请根据以下信息回答用户的问题:{召回文本段}。用户的问题是:{question}。