网上赚钱的方法有哪些湛江seo
公司的老项目了,采用的是sqlserver 2022作为数据卡做的,但是产品对接客户,发现对搜索的要求很高,尤其是全文检索,考虑到ES采用倒排所以效率上的优势和整体开发的成本,大佬们商量之后,果断的采用了Elasticsearch作为搜索引擎的策略,那么剩下的就是如何将数据同步到ES的问题了,这个的一部分也就是我的工作了,所以分享一下自己工作过程当中的思路和遇到的问题。
一、整体同步思路
1. 同步架构选择
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| CDC + Logstash | 实时性好,低延迟 | 配置复杂 | 需要准实时同步 |
| 定时批量导出导入 | 实现简单 | 数据延迟大 | 非实时分析场景 |
| 触发器+消息队列 | 灵活可控 | 影响源库性能 | 高定制化需求 |
| 第三方工具(如Debezium) | 开箱即用 | 额外成本 | 企业级解决方案 |
2. 采用方案:变更数据捕获(CDC) + Logstash 管道
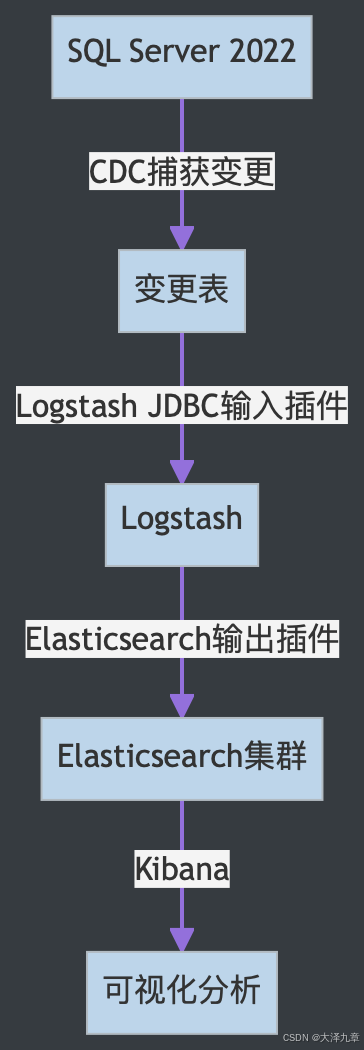
二、具体实现案例
步骤1:启用CDC
-- 在数据库级别启用CDC EXEC sys.sp_cdc_enable_db; -- 对特定表启用CDC EXEC sys.sp_cdc_enable_table@source_schema = 'dbo',@source_name = 'Products',@role_name = NULL,@supports_net_changes = 1;
步骤2:配置Logstash管道
input {jdbc {jdbc_driver_library => "D:/sqljdbc_12.2/enu/mssql-jdbc-12.2.0.jre11.jar"jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"jdbc_connection_string => "jdbc:sqlserver://localhost:1433;databaseName=YourDB"jdbc_user => "sa"jdbc_password => "yourpassword"schedule => "* * * * *" # 每分钟执行一次statement => "SELECT * FROM cdc.dbo_Products_CT WHERE __$start_lsn > ?"use_column_value => truetracking_column => "__$start_lsn"tracking_column_type => "numeric"last_run_metadata_path => "D:/logstash-8.12.0/products_last_run"}
}
output {elasticsearch {hosts => ["http://localhost:9200"]index => "sqlserver-products"document_id => "%{ProductID}"action => "update"doc_as_upsert => true}
}
案例2:批量全量+增量同步
使用Elasticsearch JDBC插件直接导入
# 全量导入 bin/elasticsearch-jdbc \-url "jdbc:sqlserver://localhost:1433;databaseName=YourDB" \-user sa -password yourpassword \-table "Products" \-index "products-index" \-type "product-type" \-id "ProductID" # 增量导入(基于时间戳) bin/elasticsearch-jdbc \-url "jdbc:sqlserver://localhost:1433;databaseName=YourDB" \-user sa -password yourpassword \-table "Products" \-index "products-index" \-type "product-type" \-id "ProductID" \-incremental "true" \-incremental_column "ModifiedDate" \-incremental_last_value "2024-01-01"
三、常见问题及解决方案
1. 性能问题
问题表现:
-
SQL Server CPU使用率高
-
Elasticsearch索引速度慢
-
网络带宽成为瓶颈
解决方案:
# Logstash优化配置示例
input {jdbc {# 增加分页大小jdbc_paging_enabled => truejdbc_page_size => 50000# 使用fetch_size提高性能jdbc_fetch_size => 1000}
}
output {elasticsearch {# 启用批量提交flush_size => 1000# 增加工作线程workers => 4}
}
2. 数据一致性问题
问题表现:
-
同步过程中数据不一致
-
漏同步或重复同步
-
数据类型映射错误
解决方案:
-- 1. 在SQL Server端添加版本控制字段 ALTER TABLE Products ADD SyncVersion ROWVERSION; -- 2. 使用事务一致性快照 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION; -- 查询数据 COMMIT TRANSACTION;
3. 网络和连接问题
问题表现:
-
连接超时
-
断线后无法恢复
-
SSL/TLS配置问题
解决方案:
input {jdbc {# 连接池配置connection_retry_attempts => 3connection_retry_attempts_wait_time => 10# 连接验证validate_connection => true# 超时设置jdbc_connection_timeout => 60}
}
4. 映射和转换问题
问题表现:
-
字段类型不匹配
-
日期格式问题
-
特殊字符处理
解决方案:
filter {# 日期格式转换date {match => ["CreatedDate", "yyyy-MM-dd HH:mm:ss.SSS"]target => "CreatedDate"}# 字段类型转换mutate {convert => {"Price" => "float""Stock" => "integer"}}# 处理NULL值if [Description] == NULL {mutate {add_field => { "Description" => "" }}}
}
5. 监控和错误处理
推荐方案:
output {if "_jsonparsefailure" in [tags] {file {path => "D:/logstash-8.12.0/error_logs/%{+yyyy-MM-dd}-parse-errors.log"}}elasticsearch {# 主输出}# 监控管道性能pipeline {send_to => ["monitoring"]}
}
四、过去的思考
-
索引设计优化
PUT /products-index {"settings": {"number_of_shards": 3,"number_of_replicas": 1,"refresh_interval": "30s"},"mappings": {"properties": {"ProductName": { "type": "text", "fields": { "keyword": { "type": "keyword" } } },"Price": { "type": "scaled_float", "scaling_factor": 100 },"CreatedDate": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss||epoch_millis" }}} } -
使用Ingest Pipeline预处理
PUT _ingest/pipeline/sqlserver_pipeline {"description": "Process SQL Server data","processors": [{"remove": {"field": ["__$start_lsn", "__$update_mask"]}},{"script": {"source": """if(ctx['IsActive'] == false) {ctx['tags'] = ['inactive'];}"""}}] }