参考文献网站开发捕鱼游戏在哪做网站
这里写自定义目录标题
- 电商评论用户洞察
- 1、Baseline分析
- 1.1 带货视频商品识别
- 1.2 视频评论情感分析
- 1.3 视频评论聚类
- 2、优化思考
- 2.1 方案一:万物皆可用大模型
- 2.1.1 带货视频商品识别
- 2.1.2 视频评论情感分析
- 2.1.3 视频评论聚类
电商评论用户洞察
笔记主要记录了在Datawhale AI夏令营中,针对电商评论用户洞察任务Baseline的优化思考。
本次挑战赛的核心目标是:将电商直播带货视频的碎片化用户评论转化为可量化的商业洞察信息。核心在于利用自然语言处理(NLP)、机器学习技术、大模型技术,从海量的文本数据中提取有价值的商业洞察。主要涉及以下几个关键领域的任务:
- 任务一(文本编码):基于视频内容识别对应的商品
- 任务二(文本分类):从非结构化评论中提取情感倾向
- 任务三(文本聚类):通过聚类总结用户的关键观点
1、Baseline分析
核心思路是 分阶段处理 各个任务,并利用 TF-IDF / BGE向量化 和 线性分类器/KMeans 聚类 来完成商品识别、情感分析和评论聚类。
具体分为以下任务:
| 任务 | 算法 |
|---|---|
| 分词 | Jieba |
| 关键词提取 | TF-IDF |
| 文本分类 | 线性支持向量机(SGDClassifier) |
| 聚类 | KMeans |
1.1 带货视频商品识别
实现路径:使用Jieba对视频描述进行分词,使用TF-IDF进行关键词提取,最后基于线性支持向量机进行文本分类。
video_data["text"] = video_data["video_desc"].fillna("") + " " + video_data["video_tags"].fillna("")product_name_predictor = make_pipeline(TfidfVectorizer(tokenizer=jieba.lcut, max_features=50), SGDClassifier()
)
product_name_predictor.fit(video_data[~video_data["product_name"].isnull()]["text"],video_data[~video_data["product_name"].isnull()]["product_name"],
)
video_data["product_name"] = product_name_predictor.predict(video_data["text"])1.2 视频评论情感分析
实现路径:使用Jieba对评论文本进行分词,使用TF-IDF进行关键词提取,最后基于线性支持向量机进行文本分类。
for col in ['sentiment_category','user_scenario', 'user_question', 'user_suggestion']:predictor = make_pipeline(TfidfVectorizer(tokenizer=jieba.lcut), SGDClassifier())predictor.fit(comments_data[~comments_data[col].isnull()]["comment_text"],comments_data[~comments_data[col].isnull()][col],)comments_data[col] = predictor.predict(comments_data["comment_text"])1.3 视频评论聚类
实现路径:使用Jieba对评论文本进行分词,使用TF-IDF进行关键词提取,最后基于KMeans进行聚类并提取中心词。
kmeans_predictor = make_pipeline(TfidfVectorizer(tokenizer=jieba.lcut), KMeans(n_clusters=2)
)kmeans_predictor.fit(comments_data[comments_data["sentiment_category"].isin([1, 3])]["comment_text"])
kmeans_cluster_label = kmeans_predictor.predict(comments_data[comments_data["sentiment_category"].isin([1, 3])]["comment_text"])kmeans_top_word = []
tfidf_vectorizer = kmeans_predictor.named_steps['tfidfvectorizer']
kmeans_model = kmeans_predictor.named_steps['kmeans']
feature_names = tfidf_vectorizer.get_feature_names_out()
cluster_centers = kmeans_model.cluster_centers_
for i in range(kmeans_model.n_clusters):top_feature_indices = cluster_centers[i].argsort()[::-1]top_word = ' '.join([feature_names[idx] for idx in top_feature_indices[:top_n_words]])kmeans_top_word.append(top_word)comments_data.loc[comments_data["sentiment_category"].isin([1, 3]), "positive_cluster_theme"] = [kmeans_top_word[x] for x in kmeans_cluster_label]2、优化思考
Baseline有以下不足:
- TF-IDF 只考虑关键词,对上下文理解不足,可能影响商品识别和文本分类效果;
- 聚类分析随意,未尝试聚类方式和簇个数;
- 未对原始数据进行清洗和转换,可能会有噪声。
2.1 方案一:万物皆可用大模型
2.1.1 带货视频商品识别
考虑到大模型能够捕捉上下文语意信息,首先按尝试使用大模型进行带货视频商品识别。
client = OpenAI(api_key="XXXXX", base_url = 'https://spark-api-open.xf-yun.com/v1' # 指向讯飞星火的请求地址)def chat(q):result = client.chat.completions.create(model="4.0Ultra",messages=[{"role":"user", "content":q}],#temperature=0.2)return result.choices[0].message.content res = []
m = 0
for i, v in video_data.iterrows():video_id = v.video_idvideo_desc = v.video_descvideo_tags = v.video_tagsproduct_name = v.product_nametext = v.textparams = {"video_id":video_id,"text":text,"product_name":product_name,}output = {"video_id":video_id,"text":text,"product_name":product_name,}prompt = """你是一个专业的电商产品运营。请从视频描述中识别其推广的商品,必须严格选择以下选项之一:- Xfaiyx Smart Translator- Xfaiyx Smart Recorder识别规则说明:1. 当描述提到"翻译"、"多语言"等关键词时选择Translator2. 当描述出现"录音"、"转写"等关键词时选择Recorder3. 遇到不确定情况时选择更符合主要功能的选项示例:输入:这款设备支持实时语音转文字输出:Xfaiyx Smart Recorder现在请识别:输入:%(text)s输出:""" % paramsn_retry = 0while 1 and n_retry < 3:try:r = chat(prompt)output['output'] = rbreakexcept:print(prompt,'retry: %s' % n_retry)n_retry += 1output['output'] = -1if n_retry >= 3: output['output'] = -1res.append(output)res_df = pd.DataFrame(res)
然而,星火大模型判断的效果远差于TF-IDF分类(20条训练集中有8条错误),主要是有些特殊情况模型难以分辨,如果想要提升效果,需要基于人工分析总结,给出好的prompt。
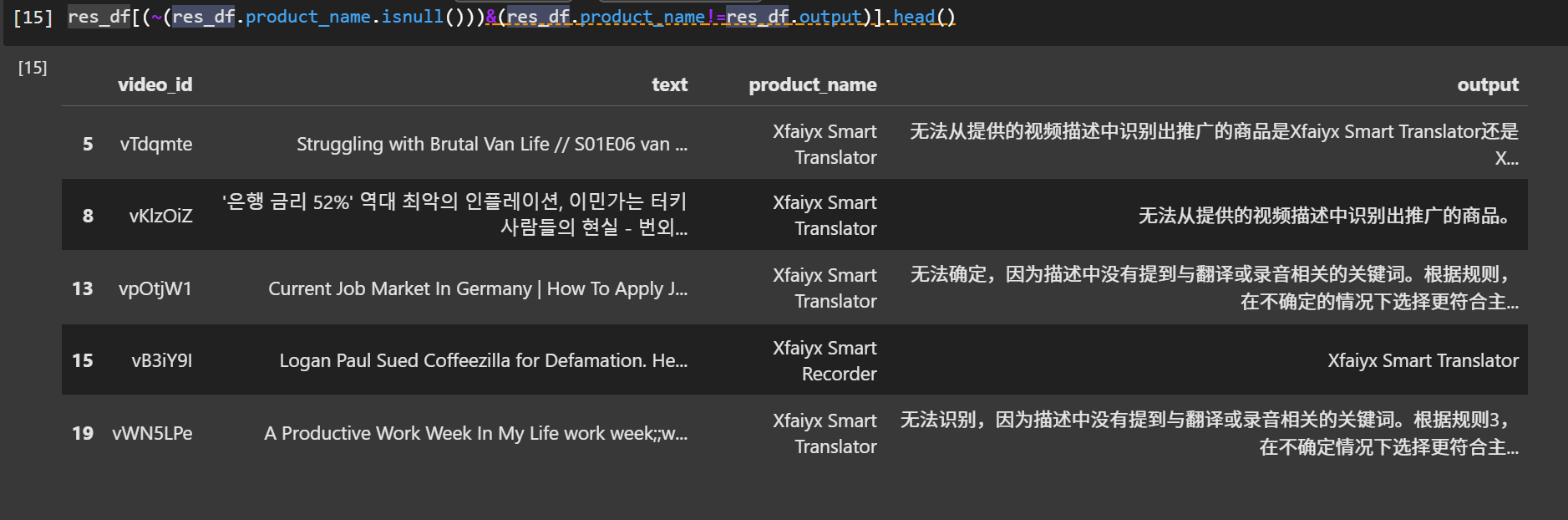
尝试基于某几个case对prompt进行修改,修改后的prompt如下:
prompt = """你是一个专业的电商产品运营。请从视频描述中识别其推广的商品,必须严格选择以下选项之一:- Xfaiyx Smart Translator- Xfaiyx Smart Recorder识别规则说明:1. 当描述提到"翻译"、"多语言"等关键词时选择Translator2. 当描述出现"录音"、"转写"等关键词时选择Recorder3. 遇到不确定情况时选择更符合主要功能的选项,例如Translator通常用在观看外语电视节目中,Recorder通常用在会议记录中。示例:输入:这款设备支持实时语音转文字输出:Xfaiyx Smart Recorder现在请识别下面视频描述中推广的商品,请直接输出商品,不要输出思考过程和原因,输出严格满足:Xfaiyx Smart Translator/Xfaiyx Smart Recorder。输入:%(text)s输出:""" % params
prompt修改后,20条训练集中只有2条错误。
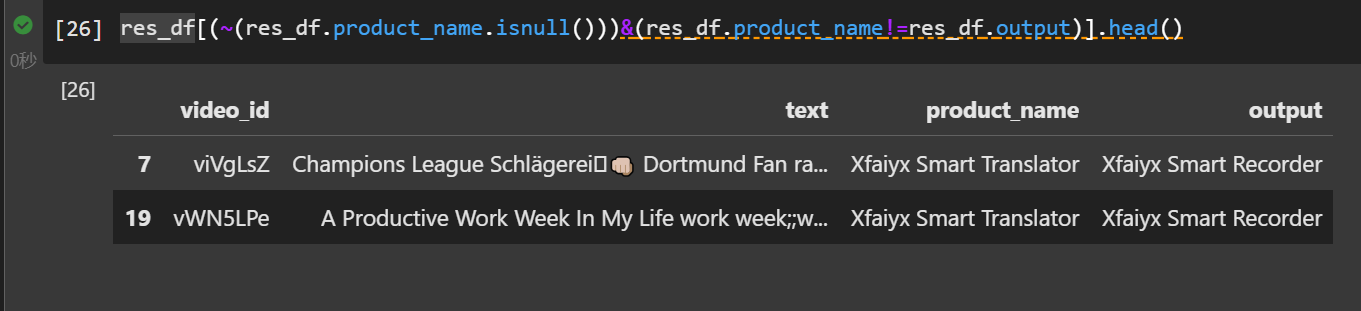
进一步修改prompt,将场景定义更加明确后,训练集全部识别正确:
prompt = """你是一个专业的电商产品运营。请从视频描述中识别其推广的商品,必须严格选择以下选项之一:- Xfaiyx Smart Translator- Xfaiyx Smart Recorder识别规则说明:1. 当描述提到"翻译"、"多语言"、"语言障碍"、"字幕"等关键词时选择Translator2. 当描述出现"录音"、"转写"、"会议记录"、"文字转录"等关键词时选择Recorder3. 遇到不确定情况时选择更符合主要功能的选项,若场景涉及生活记录 vlog、旅行、国外工作、跨国协作、多语言环境(如“working in london”)或生产力提升(如“how to stay productive”),选择 Translator。若场景明确涉及会议、课堂、访谈或语音记录,选择 Recorder。示例:输入:这款设备支持实时语音转文字输出:Xfaiyx Smart Recorder现在请识别下面视频描述中推广的商品,请直接输出商品,不要输出思考过程和原因,输出严格满足:Xfaiyx Smart Translator/Xfaiyx Smart Recorder。输入:%(text)s输出:""" % params
2.1.2 视频评论情感分析
第二步的工作是对用户评论进行情感分析,需要输出四块内容:
- sentiment_category 关于商品的情感倾向:1-正面,2-负面,3-正负都包含,4-中性,5-不相关;
- user_scenario 是否与用户场景有关:0表示否,1表示是;
- user_question 是否与用户疑问有关:0表示否,1表示是;
- user_suggestion 是否与用户建议有关:0表示否,1表示是。
为了提高大模型判断的准确率,将商品的情感倾向多分类任务与用户场景、疑问和建议的两分类任务分开进行判断。
res = []
m = 0
for i, v in comments_data.iterrows():video_id = v.video_idcomment_id = v.comment_idcomment_text = v.comment_textsentiment_category = v.sentiment_categoryuser_scenario = v.user_scenariouser_question = v.user_questionuser_suggestion = v.user_suggestionparams = {"video_id":video_id,"comment_id":comment_id,"comment_text":comment_text,"sentiment_category":sentiment_category,"user_scenario":user_scenario,"user_question":user_question,"user_suggestion":user_suggestion,}output = {"video_id":video_id,"comment_id":comment_id,"comment_text":comment_text,"sentiment_category":sentiment_category,"user_scenario":user_scenario,"user_question":user_question,"user_suggestion":user_suggestion,}prompt = """你是一个专业的电商产品运营。请从用户评论中识别用户关于带货商品的情感倾向,必须严格选择以下选项之一:1-正面,2-负面,3-正负都包含,4-中性,5-不相关。示例:输入:I tried using the Xfaiyx Translator during my trip to Japan, and it worked flawlessly! Highly recommend it.输出:1现在请识别下面用户评论中识别用户关于带货商品的情感倾向,请直接输出情感倾向的编号,不要输出思考过程和原因,输出严格满足:1/2/3/4/5。输入:%(comment_text)s输出:""" % paramsn_retry = 0while 1 and n_retry < 3:try:r = chat(prompt)output['output'] = rbreakexcept:print(prompt,'retry: %s' % n_retry)n_retry += 1if n_retry >= 3: output['output'] = -1prompt2 = """你是一个专业的电商产品运营。请判断用户关于带货商品的评论类别,需要判断三类,分别为- 是否与用户场景有关:必须严格选择以下选项之一:0表示否,1表示是;- 是否与用户疑问有关:必须严格选择以下选项之一:0表示否,1表示是;- 是否与用户建议有关:必须严格选择以下选项之一:0表示否,1表示是。示例:输入:I tried using the Xfaiyx Translator during my trip to Japan, and it worked flawlessly! Highly recommend it.输出:{"用户场景":1,"用户疑问":0,"用户建议":0}现在请识别下面用户关于带货商品的评论类别是否与用户场景、用户疑问和用户建议有关,请不要输出思考过程和原因,输出严格满足json形式:{"用户场景":0/1,"用户疑问":0/1,"用户建议":0/1}输入:%(comment_text)s输出:""" % paramsn_retry = 0while 1 and n_retry < 3:try:r = chat(prompt2)r_json = eval(r.split('\n')[1])output['scenario_output'] = r_json['用户场景']output['question_output'] = r_json['用户疑问']output['suggestio_output'] = r_json['用户建议']breakexcept:print(prompt2,'retry: %s' % n_retry)n_retry += 1if n_retry >= 3: output['scenario_output'] = -1output['question_output'] = -1output['suggestio_output'] = -1res.append(output)
判断结果略差,随机抽取的5条训练集中有1条错误,主要在于对用户问题的理解不够,需要在prompt中将用户问题的定义完善。
2.1.3 视频评论聚类
评论聚类这块的优化方向,一是寻找最佳聚类簇个数,二是更换聚类方法。
首先尝试寻找最佳聚类簇个数:
positive_comments = comments_data[comments_data["sentiment_category"].isin([1,3])]["comment_text"]
negative_comments = comments_data[comments_data["sentiment_category"].isin([2,3])]["comment_text"]
scenario_comments = comments_data[comments_data["user_scenario"].isin([1])]["comment_text"]
question_comments = comments_data[comments_data["user_question"].isin([1])]["comment_text"]
suggestion_comments = comments_data[comments_data["user_suggestion"].isin([1])]["comment_text"]k_values = range(5, 8)
best_k = [0,0,0,0,0]
best_silhouette = [-1,-1,-1,-1,-1]tfidf_for_silhouette = TfidfVectorizer(tokenizer=jieba.lcut)
X_positive = tfidf_for_silhouette.fit_transform(positive_comments)
X_negative = tfidf_for_silhouette.fit_transform(negative_comments)
X_scenario = tfidf_for_silhouette.fit_transform(scenario_comments)
X_question = tfidf_for_silhouette.fit_transform(question_comments)
X_suggestion = tfidf_for_silhouette.fit_transform(suggestion_comments)for k in k_values:kmeans = KMeans(n_clusters=k, random_state=42)positive_labels = kmeans.fit_predict(X_positive)positive_score = silhouette_score(X_positive, positive_labels) if positive_score > best_silhouette[0]:best_silhouette[0] = round(positive_score,4)best_k[0] = knegative_labels = kmeans.fit_predict(X_negative)negative_score = silhouette_score(X_negative, negative_labels) if negative_score > best_silhouette[1]:best_silhouette[1] = round(negative_score,4)best_k[1] = kscenario_labels = kmeans.fit_predict(X_scenario)scenario_score = silhouette_score(X_scenario, scenario_labels) if scenario_score > best_silhouette[2]:best_silhouette[2] =round( scenario_score,4)best_k[2] = kquestion_labels = kmeans.fit_predict(X_question)question_score = silhouette_score(X_question, question_labels) if question_score > best_silhouette[3]:best_silhouette[3] = round(question_score,4)best_k[3] = ksuggestion_labels = kmeans.fit_predict(X_suggestion)suggestion_score = silhouette_score(X_suggestion, suggestion_labels) if suggestion_score > best_silhouette[4]:best_silhouette[4] = round(suggestion_score,4)best_k[4] = k
然后根据选择的最佳聚类簇数进行聚类:
kmeans_predictor = make_pipeline(TfidfVectorizer(tokenizer=jieba.lcut), KMeans(n_clusters=best_k[0])
)kmeans_predictor.fit(comments_data[comments_data["sentiment_category"].isin([1, 3])]["comment_text"])
kmeans_cluster_label = kmeans_predictor.predict(comments_data[comments_data["sentiment_category"].isin([1, 3])]["comment_text"])kmeans_top_word = []
tfidf_vectorizer = kmeans_predictor.named_steps['tfidfvectorizer']
kmeans_model = kmeans_predictor.named_steps['kmeans']
feature_names = tfidf_vectorizer.get_feature_names_out()
cluster_centers = kmeans_model.cluster_centers_
for i in range(kmeans_model.n_clusters):top_feature_indices = cluster_centers[i].argsort()[::-1]top_word = ' '.join([feature_names[idx] for idx in top_feature_indices[:top_n_words]])kmeans_top_word.append(top_word)comments_data.loc[comments_data["sentiment_category"].isin([1, 3]), "positive_cluster_theme"] = [kmeans_top_word[x] for x in kmeans_cluster_label]