湖南智能网站建设推荐手机百度免费下载
本次利用python进行爬取,目前暂时只能实现全市信息的部分爬取,信息不全。有待继续补充其他方式建筑兔零基础自学记录45|获取高德/百度POI-1-CSDN博客但之前查到的工具POIKIT又对搜索分类有限制,不知道大家有没有什么更好的方式?
本次是基于一个现有代码的改造,省略了获取不同区域的经纬度坐标的步骤,仅以地名来限制范围,不知是否会造成获取数据不全或者超出范围的问题。
原始代码是还需导入一个不同区域的经纬度坐标这样的文件:
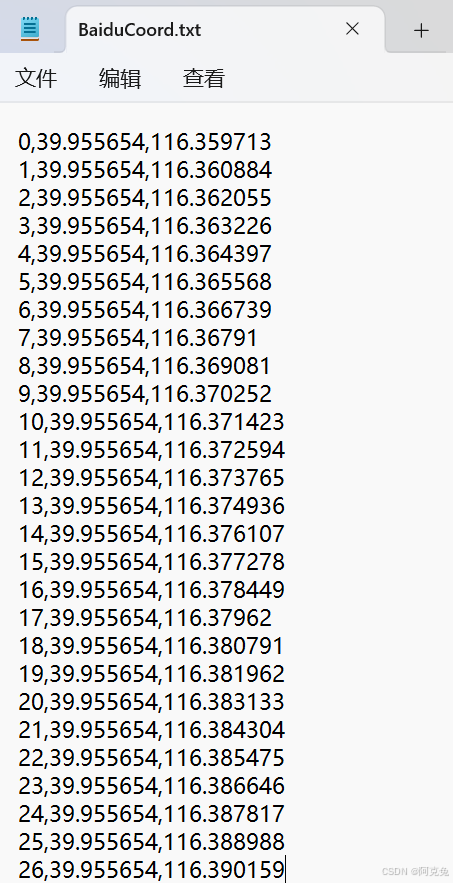
以下为尝试代码:
import urllib.request
import urllib.error
from urllib.parse import quote
import json
import time
import mathbaseURL = 'https://api.map.baidu.com/place/v2/search?query=&output=json&'
ak = 'XXXXXXXXXXXXXXXXXXXXXXXX'#申请的码
query = quote('烧烤店')
scope = '2'
region = quote('北京') # 对 region 进行 URL 编码
path = 'M:/python/workspace/PythonProject2_POI/json output/'
outputFile = path + 'BaiduPOI_1.txt'def fetch(url):try:feedback = urllib.request.urlopen(url)data = feedback.read()response = json.loads(data)time.sleep(2)return responseexcept (urllib.error.URLError, ValueError) as e:print(f"请求失败: {e}")return NonepoiList = []# 构建基于地区的初始请求URL
initialURL = f"{baseURL}ak={ak}&query={query}&scope={scope}®ion={region}&page_size=20&page_num=0"
response = fetch(initialURL)
if not response or 'total' not in response:print("未获取到有效数据")
else:totalNum = response['total']numPages = math.ceil(totalNum / 20.0) # 修正页码计算print(f"{numPages} pages in Total")for i in range(numPages):print(f"Fetching page {i}")URL = f"{baseURL}ak={ak}&query={query}&scope={scope}®ion={region}&page_size=20&page_num={i}"page_response = fetch(URL)if not page_response or 'results' not in page_response:continuefor content in page_response['results']:# 爬取店名,经纬度,uid,地址name = content.get('name', '')location = content.get('location', {})lat = location.get('lat', '')lng = location.get('lng', '')uid = content.get('uid', '')address = content.get('address', '') # 提取地址信息poiInfo = f"{name};{lat};{lng};{uid};{address}" # 更新 poiInfo 字符串poiList.append(poiInfo)# 统一写入文件
try:with open(outputFile, 'w', encoding='utf-8') as f:for poiInfo in poiList:f.write(poiInfo + '\n')
except Exception as e:print(f"写入文件时出错: {e}")
注:在content部分可以根据自己的需求增添字段。其中的uid是 Unique Identifier(唯一标识符) 的缩写,用于唯一标识每个 POI(兴趣点)。每个 POI 在百度地图中都有唯一的uid,可避免重复记录或混淆相同名称的不同地点。在数据清洗或合并时,uid可作为主键用于去重或关联其他数据集。
获得的POI数据是这样的:
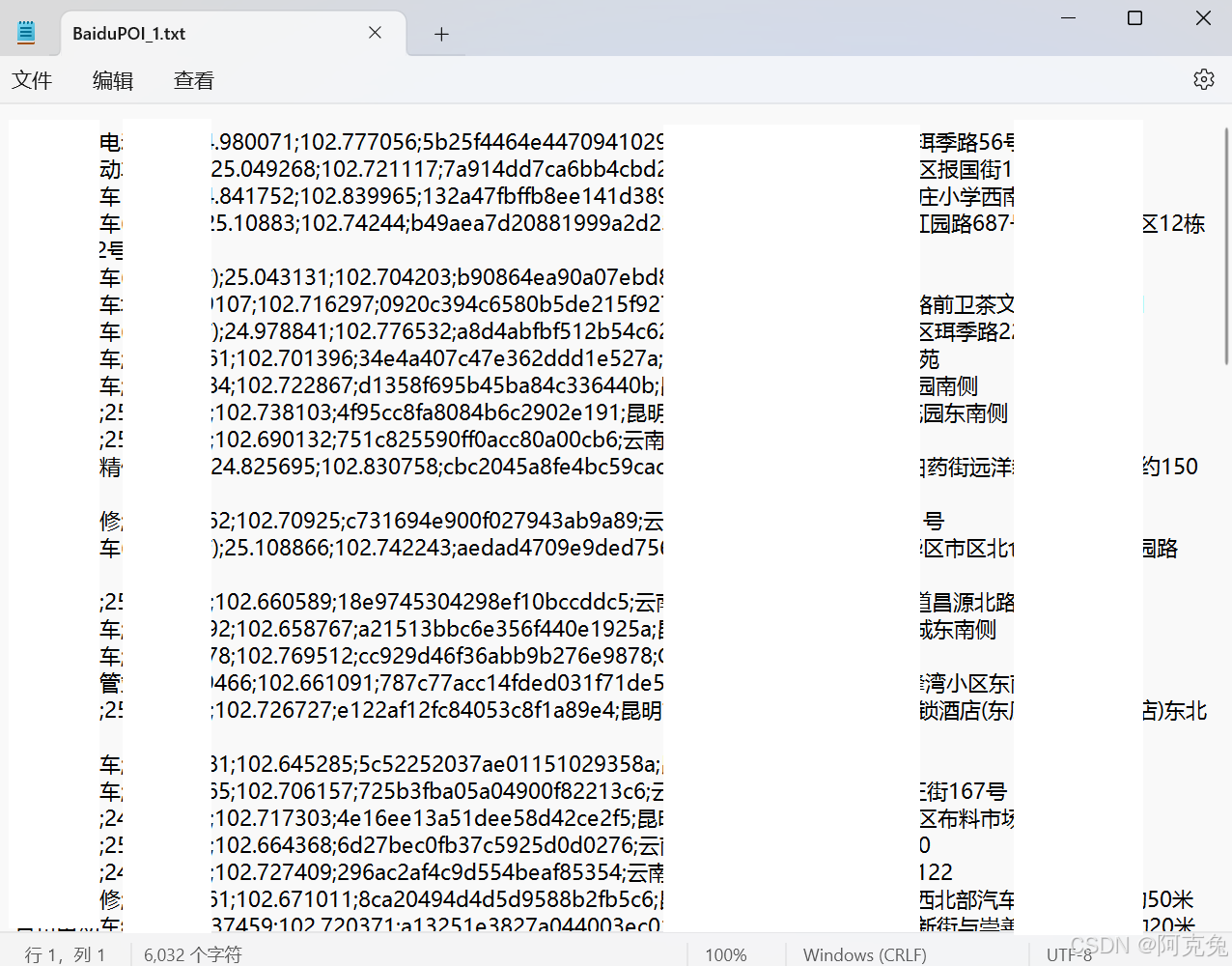
全市只获得了84条数据,肯定不全。
原始代码如下:
import urllib.request
import urllib.error
from urllib.parse import quote
import json
import time
import mathbaseURL = 'https://api.map.baidu.com/place/v2/search?query=&output=json&'
ak = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
query = quote('车')
scope = '2'
region = quote('北京') # 对 region 进行 URL 编码
path = 'M:/python/workspace/PythonProject2_POI/json output/'
outputFile = path + 'BaiduPOI_1.txt'def fetch(url):try:feedback = urllib.request.urlopen(url)data = feedback.read()response = json.loads(data)time.sleep(2)return responseexcept (urllib.error.URLError, ValueError) as e:print(f"请求失败: {e}")return None# 读取坐标文件
poiList = []
try:with open(path + 'BaiduCoord.txt', 'r') as coordinateFile:coordinates = coordinateFile.readlines()
except FileNotFoundError:print(f"未找到文件: {path + 'BaiduCoord.txt'}")#这里的BaiduCoord.txt就是坐标范围
else:for c in range(0, 10):# for c in range(len(coordinates)):coord_parts = coordinates[c].split(',')if len(coord_parts) < 3:continue # 跳过无效行current_lat = coord_parts[1].strip()current_lng = coord_parts[2].strip()locator = coord_parts[0]print(f"This is {locator} of {len(coordinates)}")initialURL = f"{baseURL}ak={ak}&query={query}&scope={scope}&location={current_lat},{current_lng}&radius=700&page_size=20&page_num=0" # 半径取700,一页返回20个数据# print(initialURL)response = fetch(initialURL)if not response or 'total' not in response:continuetotalNum = response['total']numPages = math.ceil(totalNum / 20.0) # 修正页码计算print(f"{numPages} pages in Total")for i in range(numPages):print(f"Fetching page {i}")URL = f"{baseURL}ak={ak}&query={query}&scope={scope}&location={current_lat},{current_lng}&radius=70&page_size=20&page_num={i}"page_response = fetch(URL)if not page_response or 'results' not in page_response:continuefor content in page_response['results']:# 爬取店名,经纬度,uid,地址name = content.get('name', '')location = content.get('location', {})lat = location.get('lat', '')lng = location.get('lng', '')uid = content.get('uid', '')address = content.get('address', '') # 提取地址信息poiInfo = f"{name};{lat};{lng};{uid};{address}" # 更新 poiInfo 字符串poiList.append(poiInfo)# 统一写入文件
try:with open(outputFile, 'w', encoding='utf-8') as f:for poiInfo in poiList:f.write(poiInfo + '\n')
except Exception as e:print(f"写入文件时出错: {e}")
哎头秃如何获取完整数据呢o(╥﹏╥)o