制作动作游戏吧中文北京网站优化策略
目录
一、红楼梦数据分析
(1)红楼梦源文件
(2)数据预处理——分卷实现思路
(3)分卷代码
二、分卷处理,删除停用词,将文章转换为标准格式
1.实现的思路及细节
2.代码实现(遍历所有卷的内容,并添加到内存中)
3、代码实现“1”中剩余的步骤
(1)数据展示
(2)代码及方法
三、计算红楼梦分词后文件的 TF_IDF的值
一、红楼梦数据分析
(1)红楼梦源文件
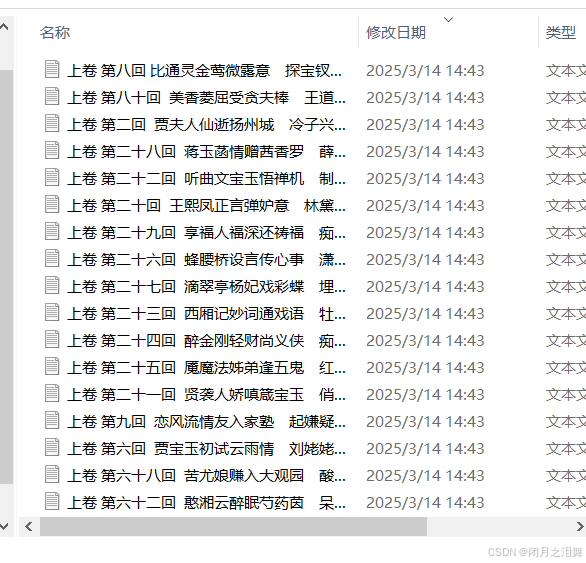
预计要实现的效果:观察下面的文件截图,我们希望将红楼梦每一回的文件内容存在文件中,将文件的“上卷 第一回 甄士隐梦幻识通灵 贾雨村风尘怀闺秀”第几回,这一整行作为文件的名字,每一回作为一个文件,储存到指定的路径下。



最终效果:
(2)数据预处理——分卷实现思路
(1)使用os是python的标准库,读取红楼梦源文件
(2)以写的格式打开一个以"红楼梦开头.txt"为名字的文件,用以存储文件开头的内容,如下:

(3)使用for循环,逐行读取文件内容,通过观察,每一回的开头,都会有“卷 第 ”这样的字,如下

我们可以通过in来判断是否读取到这一行,满足条件则对这行执行strip()方法,去除行前后的空格和换行符。
(4)使用os.path.join方法构建一个完整的路径,将路径(根据自己的实际情况来写)和文件名拼接在一起,这里是把前面写的路径,与后面读取的文件名拼接起来了,分卷最好放置在一个单独的文件夹中,为了更有条理。
os.path.join 会自动添加成斜杠,会根据系统自动补充路径中的斜杠,对不同系统有适配性,windows 斜杠\,macos 斜杠/,Linux 斜杠 /。
效果
![]()
(5)关闭先前存储文件开头的juan_file这个文件,使用close()方法。
(6)按照上面第(4)步拼接的路径,打开文件,然后使用continue跳出本次循环,向文件中逐行写入第一回的内容
(7)发现在每一回的下一行都会有这样一行内容,我们希望将其剔除,剔除方法如下:
![]()
if '手机电子书·大学生小说网' in line: #过滤掉无用的行 continue
这里表示如果发现读取的行中存在'手机电子书·大学生小说网'这个内容,就直接跳出循环,即跳过这一行,循环读取文件下一行的内容。
(8)按照上面的方法不断地循环,最终我们就能将整个红楼梦文件按照每一回存储在一个文件中的格式将红楼梦分卷处理。
效果:

(3)分卷代码
import osfile=open("./data/红楼梦/红楼原数据/红楼梦.txt",encoding='utf-8') #读取红楼梦原数据集
juan_file=open('./data/红楼梦/红楼梦开头.txt','w',encoding='utf-8') #这里会创建并打开,以红楼梦开头.txt为名字的文件
#逐行读取读取红楼梦.txt中的文件内容
for line in file:if '卷 第'in line: #为了将第几回这一行,每一回的标头作为文件的名字,这里需要能够识别到这样的行,通过文字匹配来匹配,如果满足这个条件则会执行下面的其他代码juan_name=line.strip()+'.txt' #去除行前后的空格和换行符,与.txt拼接成文件名path = os.path.join('.\\data\\红楼梦\\分卷\\',juan_name) #使用os.path.join方法将路径和文件名拼接在一起print(path)juan_file.close()juan_file=open(path,'w',encoding='utf-8')continueif '手机电子书·大学生小说网' in line: 过滤掉无用的行continuejuan_file.write(line) #将文件的其他内容写入到juan_file中
juan_file.close()二、分卷处理,删除停用词,将文章转换为标准格式
(词之间通过空格分隔),即进行分词处理
1.实现的思路及细节
(1)遍历所有卷的内容,并添加到内存中
(2)将红楼梦词库添加到jieba库中(jieba不一定能识别出红楼梦中所有的词,需要手动添加词库)
(3)读取停用词(删除无用的词)
(4)对每个卷进行分词,
(5)将所有分词后的内容写入到分词后汇总.txt
分词后汇总.txt的效果为:

可以看出,红楼梦的原文被分成上图的格式,词与词之间以空格分隔,同时每一行就是一个分卷的内容,也就是每一行是一回的内容。
2.代码实现(遍历所有卷的内容,并添加到内存中)
(1)os.walk():os.walk是直接对文件夹进行遍历,总共会有三个返回值第一个是文件的路径,第二个是路径下的文件夹,第三个是路径下的文件。
for root,dirs,files in os.walk(r"./data/红楼梦/分卷"):
这里我们分别用三个变量去接收,os.walk的返回值。
import pandas as pd
import os
filePaths=[] #用于保存文件的路径
fileContents=[] #用于保存文件的内容for root,dirs,files in os.walk(r"./data/红楼梦/分卷"):for name in files: #对files进行遍历,依次取出文件操作filePath=os.path.join(root,name) #将文件的路径和名字拼接到一起形成一个完整的路径,并将路径存储在filepath这个变量中print(filePath)filePaths.append(filePath) #将完整路径存储到filepathS这个列表中f=open(filePath,'r',encoding='utf-8') #根据上面拼接好的路径,打开文件fileContent=f.read() #读取文章内容,一次性读取全文f.close() #关闭文件减少内存占用fileContents.append(fileContent) #将文章内容添加到filecontents这个列表中
corpos=pd.DataFrame( #使用pandas的DataFrame方法,将filepath和filecontent存储成dataframe类型{"filePath":filePaths,"fileContent":fileContents}
)
print(corpos)corpos内部存储的效果:每一行是一个分卷的内容,第一列是文件存储的路径,第二列是每个分卷的内容。

3、代码实现“1”中剩余的步骤
(1)数据展示
红楼梦词库(红楼梦词库.txt):

停用词(StopwordsCN.txt):

(2)代码及方法
load_userdict():是jieba库中加载新词到jieba的辞海中,针对海量的新词可以使用这个方法,对文件格式也有要求,文件的每一行是一个停用词。
iterrows():遍历pandas数据,逐行读取,返回值有两个,行索引和pandas类型数据的全部内容
“if seg not in stopwords.stopword.values and len(seg.strip())>0:”其中stopwords.stopword.values是stopwords变量下stopword列对应的值调用。
import jiebajieba.load_userdict(r".\data\红楼梦\红楼原数据\红楼梦词库.txt")
#读取停用词
stopwords=pd.read_csv(r"./data/红楼梦/红楼原数据/StopwordsCN.txt",encoding='utf-8',engine='python',index_col=False)
file_to_jieba=open(r'./data/红楼梦/分词后汇总.txt','w',encoding='utf-8')
for index,row in corpos.iterrows():juan_ci=''filePath=row['filePath'] #获取文件路径fileContent=row['fileContent'] #获取文件内容 segs=jieba.cut(fileContent) #使用cut()方法对第一行的内容进行切分,也可以使用lcut(),并将分词后的结果存储在segs中for seg in segs: #利用for循环过滤掉文章中的停用词if seg not in stopwords.stopword.values and len(seg.strip())>0:#if如果满足,当前词不在停用词中,并且词不为空的前提下,将这个词添加到juan_ci+保存juan_ci+=seg+' '#将没一回的内容写入到file_to_jieba这个文件中,我们希望每一回在同一行,所以这里在每一回的内容后加上"\n"换行符file_to_jieba.write(juan_ci+'\n')file_to_jieba.close() #等所有分卷的内容全部写入后关闭file_to_jieba(分词后汇总.txt)这个文件,减少内存的占用为什么总是把处理完成的文件保存下来呢,预处理结束将文件保存到本地,这样做的目的是代码分块化实现,防止调试代码时每次都要全部执行,每做一步将处理好的结果保存下来,可以加快调试的效率。
三、计算红楼梦分词后文件的 TF_IDF的值
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd#读取分词后汇总,并逐行读取文件内容,存储在corpos变量中
inFile = open(r"./data/红楼梦/分词后汇总.txt","r",encoding='utf-8')
corpos = inFile.readlines()#实例化对象,使用fit_transfrom计算每个词的TF-IDF的值
vectorizer=TfidfVectorizer()
tfidf=vectorizer.fit_transform(corpos)
print(tfidf)#使用get_feature_names方法获取红楼梦的所有关键词
wordlist=vectorizer.get_feature_names()
print(wordlist)#将tfidf转化为稀疏矩阵
df=pd.DataFrame(tfidf.T.todense(),index=wordlist)
print(df)#逐列排序,输出tfidf排名前十的关键词及TF-IDF值
for i in range(len(corpos)):featurelist=df[[i]]feature_rank=featurelist.sort_values(by=i,ascending=False)print(f"第{i+1}回的关键词是:{feature_rank[:10]}")wordlistte特征值的个数33703个为:
![]()
输出效果为:我们就能得到每一回的关键词以及对应的TF-IDF值

代码汇总:
此处代码为上面的整合,去除了部分注释,可以将其放在一个.py文件中,安装好指定的库即可运行,需要注意文件的路径与你自己的文件路径对应,数据集文件可以到我的数据集中获取(有单独的一篇文章注明了数据集)
"""通过os系统标准库,读取红楼梦的原始数据,并将每一回的数据文本存储到不同的txt文件中。"""import osfile=open("./data/红楼梦/红楼原数据/红楼梦.txt",encoding='utf-8') #读取红楼梦原数据集
juan_file=open('./data/红楼梦/红楼梦开头.txt','w',encoding='utf-8') #这里会创建并打开,以红楼梦开头.txt为名字的文件
#逐行读取读取红楼梦.txt中的文件内容
for line in file:if '卷 第'in line: #为了将第几回这一行,每一回的标头作为文件的名字,这里需要能够识别到这样的行,通过文字匹配来匹配,如果满足这个条件则会执行下面的其他代码juan_name=line.strip()+'.txt' #去除行前后的空格和换行符,与.txt拼接成文件名path = os.path.join('.\\data\\红楼梦\\分卷\\',juan_name) #使用os.path.join方法将路径和文件名拼接在一起print(path)juan_file.close()juan_file=open(path,'w',encoding='utf-8')continueif '手机电子书·大学生小说网' in line: #过滤掉无用的行continuejuan_file.write(line) #将文件的其他内容写入到juan_file中
juan_file.close()import pandas as pd
import os
filePaths=[]
fileContents=[]for root,dirs,files in os.walk(r"./data/红楼梦/分卷"):for name in files:filePath=os.path.join(root,name)print(filePath)filePaths.append(filePath)f=open(filePath,'r',encoding='utf-8')fileContent=f.read()f.close()fileContents.append(fileContent)
corpos=pd.DataFrame({"filePath":filePaths,"fileContent":fileContents}
)print(corpos)import jiebajieba.load_userdict(r".\data\红楼梦\红楼原数据\红楼梦词库.txt")
stopwords=pd.read_csv(r"./data/红楼梦/红楼原数据/StopwordsCN.txt",encoding='utf-8',engine='python',index_col=False)
file_to_jieba=open(r'./data/红楼梦/分词后汇总.txt','w',encoding='utf-8')
for index,row in corpos.iterrows():juan_ci=''filePath=row['filePath']fileContent=row['fileContent']segs=jieba.cut(fileContent)for seg in segs:if seg not in stopwords.stopword.values and len(seg.strip())>0:juan_ci+=seg+' 'file_to_jieba.write(juan_ci+'\n')
file_to_jieba.close()from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pdinFile = open(r"./data/红楼梦/分词后汇总.txt","r",encoding='utf-8')
corpos = inFile.readlines()vectorizer=TfidfVectorizer()
tfidf=vectorizer.fit_transform(corpos)
print(tfidf)wordlist=vectorizer.get_feature_names()
print(wordlist)df=pd.DataFrame(tfidf.T.todense(),index=wordlist)
print(df)for i in range(len(corpos)):featurelist=df[[i]]feature_rank=featurelist.sort_values(by=i,ascending=False)print(f"第{i+1}回的关键词是:{feature_rank[:10]}")