做网站域名需哪些网站权重什么意思
CUDA四则运算示例程序
这是一个使用CUDA进行GPU并行四则运算的示例程序。程序展示了如何利用GPU的并行计算能力执行大规模的加法、减法、乘法和除法运算,并与CPU计算结果进行对比验证。
功能特点
- 使用CUDA实现四种基本算术运算:加法、减法、乘法和除法
- 处理大规模数据集(默认100万个元素)
- 自动验证GPU计算结果与CPU计算结果的一致性
- 包含完整的错误处理机制
系统要求
- NVIDIA GPU(支持CUDA)
- CUDA工具包(建议使用CUDA 10.0或更高版本)
- C++编译器(如Visual Studio、GCC等)
编译方法
Windows系统(使用NVCC命令行)
nvcc -o arithmetic arithmetic.cu
Linux系统
nvcc -o arithmetic arithmetic.cu
运行程序
编译成功后,直接运行生成的可执行文件:
./arithmetic # Linux系统
或
arithmetic.exe # Windows系统
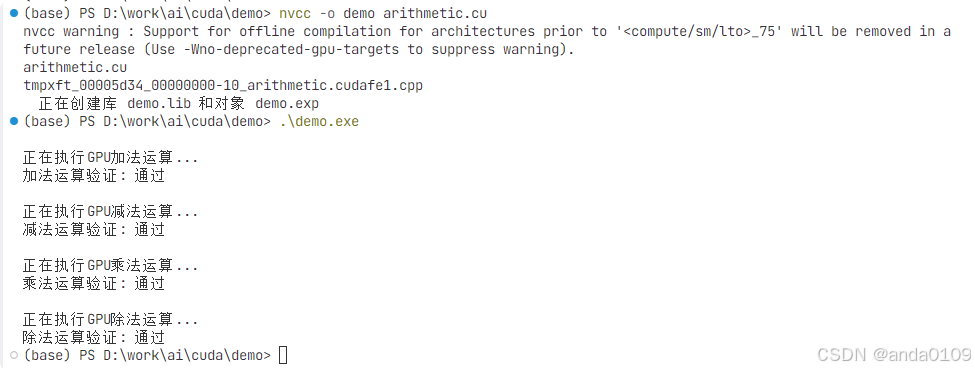
程序输出
程序将依次执行加法、减法、乘法和除法运算,并输出每种运算的验证结果。如果GPU计算结果与CPU计算结果一致,将显示"通过";否则显示"失败"并指出不匹配的位置。
代码说明
arithmetic.cu:主程序文件,包含CUDA内核函数和主函数- 程序使用随机生成的浮点数据进行计算
- 默认数组大小为100万个元素,可通过修改代码中的
N宏定义调整
注意事项
- 程序中的除法运算已处理除数为零的情况
- 验证结果时允许有微小误差(epsilon = 1e-5)
- 如需处理更大规模的数据,请确保GPU内存足够
示例代码
// arithmetic.cu
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>/**** CUDA 基础概念:* 1. 线程层次结构:* - 线程(Thread):基本执行单元* - 线程块(Block):由多个线程组成* - 网格(Grid):由多个线程块组成** 2. 重要内置变量:* - threadIdx:线程在块内的索引* - blockIdx:线程块在网格中的索引* - blockDim:线程块的维度(每块的线程数)* - gridDim:网格的维度(线程块数量)***/// 定义数组大小
#define N 2000000000// CUDA 核函数 - 加法
// __global__: 表示这是一个在GPU上运行并可以从CPU调用的核函数
__global__ void addKernel(const float* a, const float* b, float* c, int n) {// 计算全局线程索引:// blockIdx.x: 网格中当前块的索引// blockDim.x: 每个块的线程数// threadIdx.x: 块中当前线程的索引int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx < n) {c[idx] = a[idx] + b[idx];}
}// CUDA 核函数 - 减法
// 类似于加法,这个核函数在GPU上执行并行减法
__global__ void subtractKernel(const float* a, const float* b, float* c, int n) {// 计算全局线程索引int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx < n) {c[idx] = a[idx] - b[idx];}
}// CUDA 核函数 - 乘法
// 在GPU上执行并行乘法
__global__ void multiplyKernel(const float* a, const float* b, float* c, int n) {// 计算全局线程索引int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx < n) {c[idx] = a[idx] * b[idx];}
}// CUDA 核函数 - 除法
// 在GPU上执行并行除法,包括处理除以零的情况
__global__ void divideKernel(const float* a, const float* b, float* c, int n) {// 计算全局线程索引int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx < n) {if (b[idx] != 0) { // 避免除以零c[idx] = a[idx] / b[idx];} else {c[idx] = 0; // 当除数为零时,将结果设为0}}
}// 检查CUDA错误
// 该函数检查CUDA操作是否成功,失败时输出错误信息并退出
// CUDA API调用通常返回cudaError_t类型的错误码
void checkCudaError(cudaError_t error, const char* message) {if (error != cudaSuccess) {fprintf(stderr, "CUDA错误: %s - %s\n", message, cudaGetErrorString(error));exit(-1);}
}// 用于结果验证的CPU计算函数版本
void cpuCalculate(const float* a, const float* b, float* c, int n, char operation) {for (int i = 0; i < n; i++) {switch (operation) {case '+':c[i] = a[i] + b[i];break;case '-':c[i] = a[i] - b[i];break;case '*':c[i] = a[i] * b[i];break;case '/':c[i] = (b[i] != 0) ? a[i] / b[i] : 0;break;}}
}// 验证GPU和CPU结果
bool verifyResults(const float* cpu_result, const float* gpu_result, int n) {const float epsilon = 1e-5; // 允许的误差范围for (int i = 0; i < n; i++) {if (fabs(cpu_result[i] - gpu_result[i]) > epsilon) {printf("结果不匹配! 索引 %d: CPU = %f, GPU = %f\n", i, cpu_result[i], gpu_result[i]);return false;}}return true;
}int main() {// 声明主机和设备内存指针// h_前缀表示主机内存(CPU内存)// d_前缀表示设备内存(GPU内存)float *h_a, *h_b, *h_c, *h_verify;float *d_a, *d_b, *d_c;// 分配主机内存(使用标准C的malloc函数)h_a = (float*)malloc(N * sizeof(float)); // 第一个输入数组h_b = (float*)malloc(N * sizeof(float)); // 第二个输入数组h_c = (float*)malloc(N * sizeof(float)); // 存储GPU计算结果h_verify = (float*)malloc(N * sizeof(float)); // 存储CPU验证结果// 初始化输入数据// 用随机数填充输入数组for (int i = 0; i < N; i++) {h_a[i] = rand() / (float)RAND_MAX; // 生成0到1之间的随机浮点数h_b[i] = rand() / (float)RAND_MAX;}// 分配设备内存(GPU内存)// cudaMalloc是用于GPU内存分配的CUDA API// 第一个参数是指向指针的指针,第二个是要分配的字节数checkCudaError(cudaMalloc((void**)&d_a, N * sizeof(float)), "分配设备内存d_a失败");checkCudaError(cudaMalloc((void**)&d_b, N * sizeof(float)), "分配设备内存d_b失败");checkCudaError(cudaMalloc((void**)&d_c, N * sizeof(float)), "分配设备内存d_c失败");// 将数据从主机内存复制到设备内存// cudaMemcpy是用于主机和设备之间数据传输的CUDA API// 参数:目标指针,源指针,要复制的字节数,复制方向// cudaMemcpyHostToDevice表示从CPU复制到GPUcheckCudaError(cudaMemcpy(d_a, h_a, N * sizeof(float), cudaMemcpyHostToDevice), "复制数据到设备d_a失败");checkCudaError(cudaMemcpy(d_b, h_b, N * sizeof(float), cudaMemcpyHostToDevice), "复制数据到设备d_b失败");// 设置CUDA核函数启动参数// 定义块大小和网格大小int threadsPerBlock = 256; // 每个块包含256个线程// 计算处理所有数据所需的块数// 公式确保有足够的线程处理所有N个元素int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;// 执行加法运算printf("\n正在执行GPU加法运算...\n");addKernel<<<blocksPerGrid, threadsPerBlock>>>(d_a, d_b, d_c, N);checkCudaError(cudaGetLastError(), "加法核函数启动失败");checkCudaError(cudaMemcpy(h_c, d_c, N * sizeof(float), cudaMemcpyDeviceToHost), "拷贝加法结果到主机失败");cpuCalculate(h_a, h_b, h_verify, N, '+');printf("加法运算验证: %s\n", verifyResults(h_verify, h_c, N) ? "通过" : "未通过");// 执行减法运算printf("\n正在执行GPU减法运算...\n");// 使用相同的网格和块配置启动减法核函数subtractKernel<<<blocksPerGrid, threadsPerBlock>>>(d_a, d_b, d_c, N);checkCudaError(cudaGetLastError(), "减法核函数启动失败");// 将GPU结果复制回CPUcheckCudaError(cudaMemcpy(h_c, d_c, N * sizeof(float), cudaMemcpyDeviceToHost), "复制减法结果到主机失败");// 在CPU上执行相同的减法cpuCalculate(h_a, h_b, h_verify, N, '-');// 验证结果printf("减法运算验证: %s\n", verifyResults(h_verify, h_c, N) ? "通过" : "未通过");// 执行乘法运算printf("\n正在执行GPU乘法运算...\n");// 启动乘法核函数multiplyKernel<<<blocksPerGrid, threadsPerBlock>>>(d_a, d_b, d_c, N);checkCudaError(cudaGetLastError(), "乘法核函数启动失败");checkCudaError(cudaMemcpy(h_c, d_c, N * sizeof(float), cudaMemcpyDeviceToHost), "复制乘法结果到主机失败");cpuCalculate(h_a, h_b, h_verify, N, '*');printf("乘法运算验证: %s\n", verifyResults(h_verify, h_c, N) ? "通过" : "未通过");// 执行除法运算printf("\n正在执行GPU除法运算...\n");divideKernel<<<blocksPerGrid, threadsPerBlock>>>(d_a, d_b, d_c, N);checkCudaError(cudaGetLastError(), "除法核函数启动失败");checkCudaError(cudaMemcpy(h_c, d_c, N * sizeof(float), cudaMemcpyDeviceToHost), "复制除法结果到主机失败");cpuCalculate(h_a, h_b, h_verify, N, '/');printf("除法运算验证: %s\n", verifyResults(h_verify, h_c, N) ? "通过" : "未通过");// 清理内存// 使用cudaFree释放GPU内存cudaFree(d_a);cudaFree(d_b);cudaFree(d_c);// 使用标准C的free释放CPU内存free(h_a);free(h_b);free(h_c);free(h_verify);return 0;
}