免费的发帖收录网站在哪里做推广效果好
HashCode 为什么使用 31 作为乘数?
- 1. 固定乘积 31 在这用到了
- 2. 来自 stackoverflow 的回答
- 3. Hash 值碰撞概率统计
- 3.1 读取单词字典表
- 3.2 Hash 计算函数
- 3.3 Hash 碰撞概率计算
- 封装碰撞统计信息的类
- 3.4 针对一组乘数,分别计算碰撞率
- 3.5 碰撞结果可视化
- 3.6 Main方法
- 3.7 测试结果
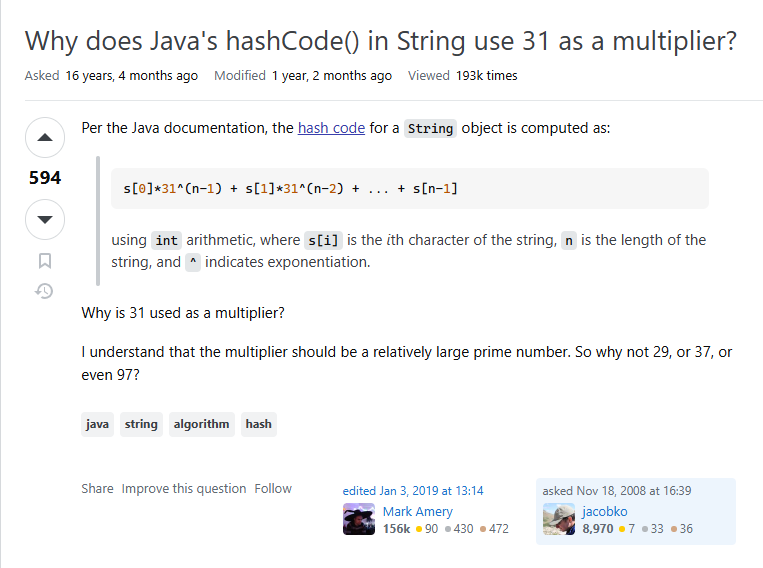
问题如上:
☞hashCode 的计算逻辑中,为什么是 31 作为乘数。
1. 固定乘积 31 在这用到了
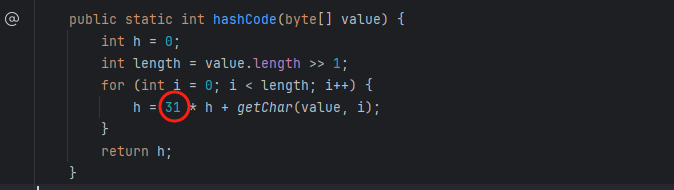
在获取 hashCode 的源码中可以看到,有一个固定值 31,在 for 循环每次执行时进行乘积计算,循环后的公式如下:
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
那么这里为什么选择 31 作为乘积值呢?
2. 来自 stackoverflow 的回答
在 stackoverflow 关于为什么选择 31 作为固定乘积值,有一篇讨论文章,Why does Java’s hashCode() in String use 31 as a multiplier?
这是一个时间比较久的问题了,摘取两个回答点赞最多的:

这段内容主要阐述的观点包括;
- 31 是一个奇质数,如果选择偶数会导致乘积运算时数据溢出。
- 另外在二进制中,2 个 5 次方是 32,那么也就是
31 * i == (i << 5) - i。这主要是说乘积运算可以使用位移提升性能,同时目前的 JVM 虚拟机也会自动支持此类的优化。
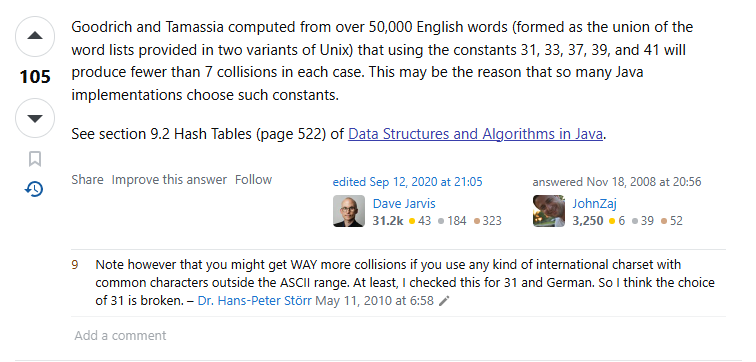
- 这个回答就很有实战意义了,告诉你用超过 5 千个单词计算 hashCode,这个 hashCode 的运算使用 31、33、37、39 和 41 作为乘积,得到的碰撞结果,31 被使用就很正常了。
- 他这句话就就可以作为我们实践的指向了。
3. Hash 值碰撞概率统计
接下来要做的事情并不难,只是根据 stackoverflow 的回答,统计出不同的乘积数对 10 万个单词的 hash 计算结果。
103976个英语单词库已通过资源绑定,将在文章顶部展示,可自行下载测试。
3.1 读取单词字典表
/*** 读取单词表文件,提取每行的第一个单词** @param filePath 文件路径* @return 单词列表*/public static List<String> readWordList(String filePath) {List<String> words = new ArrayList<>();try (BufferedReader reader = new BufferedReader(new FileReader(filePath))) {String line;while ((line = reader.readLine()) != null) {// 1. 跳过空行line = line.trim();if (line.isEmpty()) {continue;}// 2. 按空格或制表符分割行内容String[] parts = line.split("\\s+"); // 使用正则匹配连续空白符if (parts.length >= 2) {// 3. 提取第一个单词(索引为 1,因为首项是行号)String word = parts[1];words.add(word);}}} catch (IOException e) {e.printStackTrace();}return words;}
3.2 Hash 计算函数
public static Integer hashCode(String str, Integer multiplier) {int hash = 0;for (int i = 0; i < str.length(); i++) {hash = multiplier * hash + str.charAt(i);}return hash;}
3.3 Hash 碰撞概率计算
private static RateInfo hashCollisionRate(Integer multiplier, List<Integer> hashCodeList) {int maxHash = hashCodeList.stream().max(Integer::compareTo).get();int minHash = hashCodeList.stream().min(Integer::compareTo).get();int collisionCount = (int) (hashCodeList.size() - hashCodeList.stream().distinct().count());double collisionRate = (collisionCount * 1.0) / hashCodeList.size();return new RateInfo(multiplier, minHash, maxHash, collisionCount, collisionRate);}
封装碰撞统计信息的类
public class RateInfo {private int multiplier;private int minHash;private int maxHash;private int collisionCount;private double collisionRate;public RateInfo(int multiplier, int minHash, int maxHash, int collisionCount, double collisionRate) {this.multiplier = multiplier;this.minHash = minHash;this.maxHash = maxHash;this.collisionCount = collisionCount;this.collisionRate = collisionRate;}public int getMultiplier() {return multiplier;}public void setMultiplier(int multiplier) {this.multiplier = multiplier;}public int getMinHash() {return minHash;}public void setMinHash(int minHash) {this.minHash = minHash;}public int getMaxHash() {return maxHash;}public void setMaxHash(int maxHash) {this.maxHash = maxHash;}public int getCollisionCount() {return collisionCount;}public void setCollisionCount(int collisionCount) {this.collisionCount = collisionCount;}public double getCollisionRate() {return collisionRate;}public void setCollisionRate(double collisionRate) {this.collisionRate = collisionRate;}@Overridepublic String toString() {return String.format("乘数 = %4d, 最小Hash = %11d, 最大Hash = %10d, 碰撞数量 = %6d, 碰撞率 = %.4f%%",multiplier, minHash, maxHash, collisionCount, collisionRate * 100);}
3.4 针对一组乘数,分别计算碰撞率
public static List<RateInfo> collisionRateList(List<String> words, int[] multipliers) {List<RateInfo> rateInfoList = new ArrayList<>();for (int m : multipliers) {// 对所有单词计算 hash 值(使用传入的 m)List<Integer> hashCodeList = words.stream().map(word -> hashCode(word, m)).collect(Collectors.toList());// 传递 m 而非计算出的某个 hash 值RateInfo rate = hashCollisionRate(m, hashCodeList);rateInfoList.add(rate);}return rateInfoList;}
3.5 碰撞结果可视化
public static void printBarChart(List<RateInfo> rateInfoList) {// 求出所有记录中碰撞率的最大值,用于归一化条形长度double maxRate = rateInfoList.stream().mapToDouble(RateInfo::getCollisionRate).max().orElse(1.0);// 设定条形图最大宽度(字符数)int maxBarWidth = 50;System.out.println("==== 横向条形图展示各乘数下的碰撞率 ====");for (RateInfo rate : rateInfoList) {// 当前碰撞率归一化后的条形长度计算int barLength = (int) ((rate.getCollisionRate() / maxRate) * maxBarWidth);String bar = new String(new char[barLength]).replace('\0', '#');System.out.printf("乘数 %4d | %s (碰撞率: %.4f%%)%n",rate.getMultiplier(), bar, rate.getCollisionRate() * 100);}}
3.6 Main方法
// 指定需要测试的乘数列表List<String> words = FileUtil.readWordList("D:\\英语单词库.txt");List<RateInfo> rateInfoList = collisionRateList(words, new int[]{2, 3, 5, 7, 17, 31, 32, 33, 39, 41, 199});System.out.println("读取单词总数: " + words.size());// 输出各乘数下的碰撞统计信息System.out.println("============ 哈希碰撞统计 ============");for (RateInfo rate : rateInfoList) {System.out.println(rate.toString());}System.out.println();printBarChart(rateInfoList);
3.7 测试结果
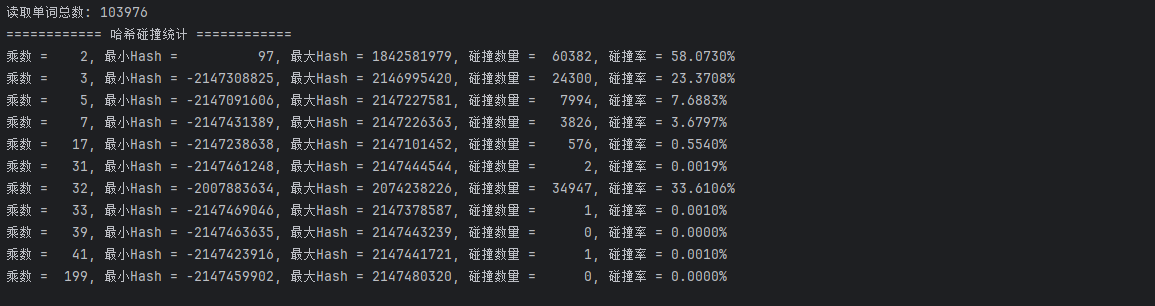
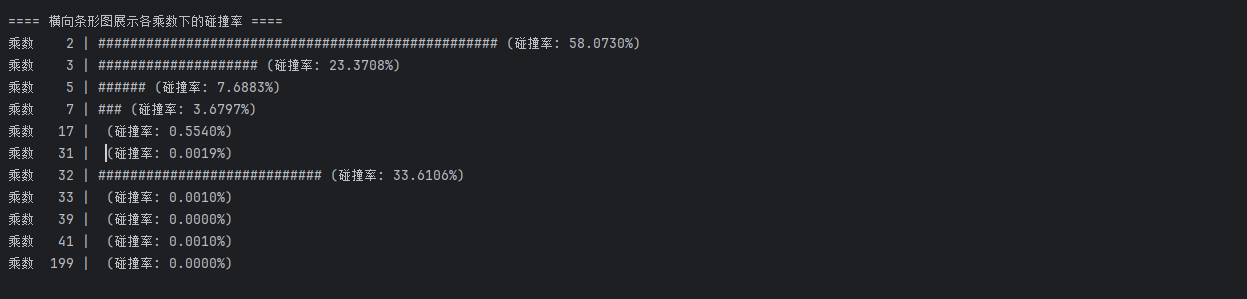
以上就是不同的乘数下的 hash 碰撞结果图标展示,从这里可以看出如下信息;
- 乘数是 2 时,hash 的取值范围比较小,基本是堆积到一个范围内了。
- 乘数是 3、5、7、17 等,都有较大的碰撞概率
- 乘数是 31 的时候,碰撞的概率已经很小了,基本稳定。
- 顺着往下看,你会发现 199 的碰撞概率更小,这就相当于一排奇数的茅坑量多,自然会减少碰撞。但这个范围值已经远超过 int 的取值范围了,如果用此数作为乘数,又返回 int 值,就会丢失数据信息。