广东网站建设公司报价表广州seo顾问服务
文章目录
- 🧰 Python 实现一个带进度条的 URL 批量下载工具(含 GUI 界面)
- 效果
- ✨ 功能亮点
- 📦 用到的依赖库
- 🧠 项目结构拆解与说明
- 1️⃣ 提取工具逻辑:如何从 URL 获取文件名
- 2️⃣ 下载逻辑:requests 下载 + 失败捕获
- 3️⃣ 下载控制与进度条更新
- 4️⃣ GUI 界面设计与交互逻辑
- 📂 整体代码汇总
- 🧪 使用说明
- ✅ 实用建议
- 📎 源码
- 🧑💻 作者信息
🧰 Python 实现一个带进度条的 URL 批量下载工具(含 GUI 界面)
本文将带你一步一步实现一个支持 GUI 操作的批量 URL 下载工具,支持从 Excel 文件中读取链接,自动保存、记录失败链接,并带有下载进度条,非常适合运营、测试、爬虫等批量下载需求。
效果

✨ 功能亮点
- 📄 支持从
.xlsx文件读取 URL 列表 - 📥 批量下载,支持失败重试日志
- 📂 支持自定义保存目录和子文件夹
- 🔄 带有下载进度条和实时状态提示
- 🖱️ 全 GUI 操作,无需命令行
- ✅ 支持文件名自动提取,无需手动命名
📦 用到的依赖库
以下是该项目中用到的第三方库:
pip install requests pandas openpyxl
openpyxl是pandas.read_excel在读取.xlsx文件时默认依赖的后端。
🧠 项目结构拆解与说明
1️⃣ 提取工具逻辑:如何从 URL 获取文件名
from urllib.parse import urlparsedef extract_filename_from_url(url):path = urlparse(url).pathfilename = os.path.basename(path)return filename if filename else str(uuid.uuid4())
- 使用
urlparse提取路径,再用os.path.basename获取文件名; - 若链接无文件名(比如以
/结尾),则使用 UUID 作为备选。
2️⃣ 下载逻辑:requests 下载 + 失败捕获
def download_file(url, folder_path):try:response = requests.get(url, timeout=10)response.raise_for_status()filename = extract_filename_from_url(url)save_path = os.path.join(folder_path, filename)with open(save_path, 'wb') as f:f.write(response.content)return Trueexcept:return False
- 使用
requests.get()获取内容; - 若出现网络错误或 404,则返回 False,并记录。
3️⃣ 下载控制与进度条更新
def start_download_with_progress(...):...def process_next(index):...# 下载成功/失败计数# 写入失败日志# 更新进度条 + 状态文字# after(100, ...) 避免阻塞 GUI
- 使用
progress_bar.after()模拟异步,防止主线程卡死; - 实时更新进度条和状态标签;
- 下载失败写入
download_fail.log,便于事后处理。
4️⃣ GUI 界面设计与交互逻辑
from tkinter import ...
- 使用 Tkinter 实现图形界面;
- 包括:文件选择按钮、路径输入、保存子目录输入、进度条、状态文字、下载按钮等;
- 绑定
Entry的<KeyRelease>事件实现路径预览实时更新; - 使用
ttk.Progressbar实现可视化进度条。
界面示例(启动后):
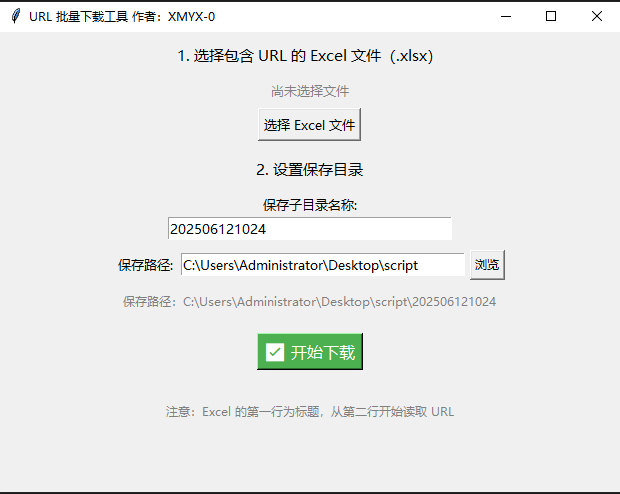
📂 整体代码汇总
可参考本文开头提供的完整源代码,复制后直接运行,即可体验图形化批量下载。
🧪 使用说明
- 准备一个
.xlsx文件,第一列为 URL 列,第一行可为表头; - 启动程序,点击“选择 Excel 文件”按钮;
- 设置保存目录与子文件夹名称;
- 点击“开始下载”,等待进度条完成;
- 下载失败的 URL 会记录在
download_fail.log文件中。
✅ 实用建议
- 遇到下载失败,可以手动查看
download_fail.log并尝试重试;
📎 源码
import os
import uuid
import requests
import pandas as pd
from datetime import datetime
from urllib.parse import urlparse
from tkinter import Tk, Label, Button, filedialog, messagebox, Entry, StringVar, Frame
from tkinter import ttk# 获取当前时间默认文件夹名
def get_default_folder_name():return datetime.now().strftime('%Y%m%d%H%M')# 提取 URL 文件名
def extract_filename_from_url(url):path = urlparse(url).pathfilename = os.path.basename(path)return filename if filename else str(uuid.uuid4())# 单个下载逻辑
def download_file(url, folder_path):try:response = requests.get(url, timeout=10)response.raise_for_status()filename = extract_filename_from_url(url)save_path = os.path.join(folder_path, filename)with open(save_path, 'wb') as f:f.write(response.content)return Trueexcept:return False# 下载并更新 UI 进度
def start_download_with_progress(urls, save_path, fail_log_path, progress_bar, status_label, start_button):total = len(urls)success = 0fail = 0def process_next(index):nonlocal success, failif index >= total:status_label.config(text=f"✅ 下载完成,成功 {success} 个,失败 {fail} 个")start_button.config(state='normal')returnurl = urls[index]ok = download_file(url, save_path)if ok:success += 1else:fail += 1with open(fail_log_path, 'a', encoding='utf-8') as f:f.write(url + '\n')percent = int(((index + 1) / total) * 100)progress_bar['value'] = percentstatus_label.config(text=f"进度:{percent}% | 成功:{success} 失败:{fail}")progress_bar.update()# 延迟调用下一项,避免 UI 卡死progress_bar.after(100, lambda: process_next(index + 1))process_next(0)# 下载启动逻辑
def start_download(selected_file, folder_name_var, base_path_var, full_path_label_var,progress_bar, status_label, start_button):if not selected_file:messagebox.showwarning("警告", "请先选择 Excel 文件")returnfolder_name = folder_name_var.get().strip() or get_default_folder_name()base_path = base_path_var.get().strip() or os.getcwd()save_path = os.path.join(base_path, folder_name)os.makedirs(save_path, exist_ok=True)full_path_label_var.set(f"保存路径:{save_path}")try:df = pd.read_excel(selected_file, usecols=[0])urls = df.iloc[:, 0].astype(str).str.strip()urls = urls[urls != ''] # 过滤空字符串urls = urls.tolist()if not urls:messagebox.showinfo("提示", "未检测到有效 URL")return# 清空失败记录failed_log_path = os.path.join(save_path, 'download_fail.log')with open(failed_log_path, 'w', encoding='utf-8') as f:passprogress_bar['maximum'] = 100progress_bar['value'] = 0progress_bar.pack(pady=10)status_label.pack()start_button.config(state='disabled')start_download_with_progress(urls, save_path, failed_log_path,progress_bar, status_label, start_button)except Exception as e:messagebox.showerror("错误", f"下载过程中发生错误:{e}")# 文件选择
def choose_file(selected_file_var, file_label):file_path = filedialog.askopenfilename(filetypes=[("Excel 文件", "*.xlsx")])if file_path:selected_file_var.set(file_path)file_label.config(text=f"已选择文件:{os.path.basename(file_path)}")# 保存路径选择
def select_directory(base_path_var, folder_name_var, full_path_label_var):selected = filedialog.askdirectory()if selected:base_path_var.set(selected)update_full_path_label(folder_name_var, base_path_var, full_path_label_var)# 路径标签更新
def update_full_path_label(folder_name_var, base_path_var, full_path_label_var):folder_name = folder_name_var.get().strip() or get_default_folder_name()base_path = base_path_var.get().strip() or os.getcwd()full_path_label_var.set(f"保存路径:{os.path.join(base_path, folder_name)}")# 主界面
def create_gui():root = Tk()root.title("URL 批量下载工具 作者:XMYX-0")root.geometry("620x460")selected_file_var = StringVar()folder_name_var = StringVar(value=get_default_folder_name())base_path_var = StringVar(value=os.getcwd())full_path_label_var = StringVar()# UI 元素Label(root, text="1. 选择包含 URL 的 Excel 文件(.xlsx)", font=("微软雅黑", 11)).pack(pady=10)file_label = Label(root, text="尚未选择文件", font=("微软雅黑", 10), fg="gray")file_label.pack()Button(root, text="选择 Excel 文件", font=("微软雅黑", 10),command=lambda: choose_file(selected_file_var, file_label)).pack(pady=5)Label(root, text="2. 设置保存目录", font=("微软雅黑", 11)).pack(pady=10)Label(root, text="保存子目录名称:", font=("微软雅黑", 10)).pack()folder_entry = Entry(root, textvariable=folder_name_var, font=("微软雅黑", 10), width=35)folder_entry.pack()path_frame = Frame(root)path_frame.pack(pady=10)Label(path_frame, text="保存路径:", font=("微软雅黑", 10)).grid(row=0, column=0, padx=5)path_entry = Entry(path_frame, textvariable=base_path_var, font=("微软雅黑", 10), width=35)path_entry.grid(row=0, column=1)Button(path_frame, text="浏览", command=lambda: select_directory(base_path_var, folder_name_var, full_path_label_var)).grid(row=0, column=2, padx=5)update_full_path_label(folder_name_var, base_path_var, full_path_label_var)Label(root, textvariable=full_path_label_var, font=("微软雅黑", 9), fg="gray").pack()progress_bar = ttk.Progressbar(root, length=400)status_label = Label(root, text="", font=("微软雅黑", 10))start_button = Button(root, text="✅ 开始下载", font=("微软雅黑", 12), bg="#4CAF50", fg="white",command=lambda: start_download(selected_file_var.get(),folder_name_var,base_path_var,full_path_label_var,progress_bar,status_label,start_button))start_button.pack(pady=20)folder_entry.bind("<KeyRelease>", lambda e: update_full_path_label(folder_name_var, base_path_var, full_path_label_var))path_entry.bind("<KeyRelease>", lambda e: update_full_path_label(folder_name_var, base_path_var, full_path_label_var))Label(root, text="注意:Excel 的第一行为标题,从第二行开始读取 URL", font=("微软雅黑", 9), fg="gray").pack(pady=10)root.mainloop()if __name__ == "__main__":create_gui()
🧑💻 作者信息
- 作者:XMYX-0
- 简介:Python & DevOps 爱好者,热衷于实用自动化工具开发
- 联系方式:
