源代码网站和模板做的区别手机网站建设价格
目录
0-环境配置
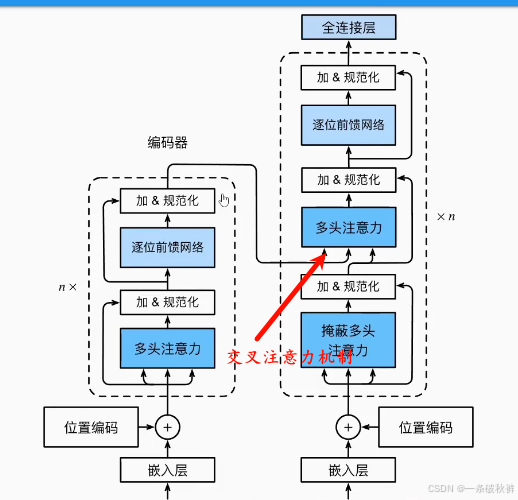
1-编码器
源
嵌入层
位置编码
多头注意力
加 & 规范化 || 逐位前馈网络
编码器
2-解码器
3-模型构建
4-数据&任务
生成数据
生成数据集
5-掩码
0-环境配置
安装torch环境
conda create -n trans python=3.10
# CUDA 12.1
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu121安装jupyter
pip install jupyter -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple --trusted-host=https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple训练进度条
pip install tqdm
1-编码器
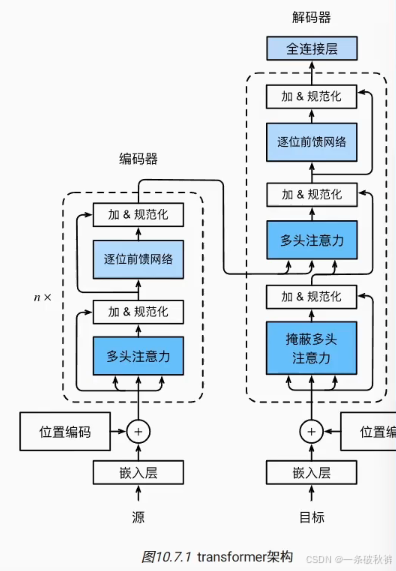
源

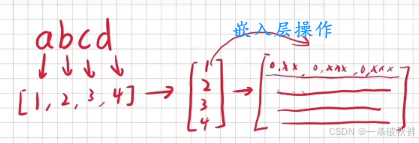
嵌入层
可以将输入转换成向量。【防止数字大小代表文字重要性、且向量有大小也有方向】
位置编码
可以修改为可学习的位置编码。
import torch
from torch import nn#【词汇表长度:28】
#【句子最大查询长度:12】class EBD(nn.Module):def __init__(self, ):super(EBD, self).__init__()# 词嵌入层self.word_ebd = nn.Embedding(28, 24)# 位置编码层self.pos_ebd = nn.Embedding(12, 24)self.pos_t = torch.arange(0,12).reshape(1, 12) #【注释:arange(0,12)表示0到11的数字,reshape(1, 12)表示将其变为1行12列的矩阵,pos_t表示位置编码矩阵,用于将位置信息编码到词向量中】# 编码层# X: [batch_size, seq_len]def forward(self, X:torch.tensor):return self.word_ebd(X) + self.pos_ebd(self.pos_t)if __name__ == '__main__':aaa = torch.ones(2, 12).long() #【注释:这里的12是句子最大查询长度,28是词汇表长度 ones(2, 12)表示2个句子,每个句子12个词, long()表示数据类型为long】print(aaa.shape) # torch.Size([2, 12])model = EBD()print(model(aaa).shape) # torch.Size([2, 12, 24])# 【2:2个句子,12:每个句子12个词||编码长度,24:词嵌入维度(隐藏层大小)】多头注意力
注意力

import torch
from torch import nn#【词汇表长度:28】
#【句子最大查询长度:12】class EBD(nn.Module):def __init__(self, *args, **kwargs)-> None:super(EBD, self).__init__(*args, **kwargs)# 词嵌入层self.word_ebd = nn.Embedding(28, 24)# 位置编码层self.pos_ebd = nn.Embedding(12, 24)self.pos_t = torch.arange(0,12).reshape(1, 12) #【注释:arange(0,12)表示0到11的数字,reshape(1, 12)表示将其变为1行12列的矩阵,pos_t表示位置编码矩阵,用于将位置信息编码到词向量中】# 编码层# X: [batch_size, seq_len]def forward(self, X:torch.tensor):return self.word_ebd(X) + self.pos_ebd(self.pos_t)
def attention(Q, K, V):A = Q @ K.transpose(-1, -2) #【注释:@表示矩阵乘法,transpose(-1, -2)表示计转至K的最后两个维度】A = A / (K.shape[-1] ** 0.5) #【注释:K.shape[-1]表示K的最后一个维度,**0.5表示取平方根】A = torch.softmax(A, dim=-1)O = A @ Vreturn Oclass Attention_block(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Attention_block, self).__init__(*args, **kwargs)# 注意力层:相当于一个MLP,输入为词向量,输出为注意力权重self.W_q = nn.Linear(24, 24, bias=False)self.W_k = nn.Linear(24, 24, bias=False)self.W_v = nn.Linear(24, 24, bias=False)self.W_o = nn.Linear(24, 24, bias=False)def forward(self, X:torch.tensor):Q, K, V = self.W_q(X), self.W_k(X), self.W_v(X)# 计算注意力权重O = attention(Q, K, V)O = self.W_o(O)return Oif __name__ == '__main__':aaa = torch.ones(2, 12).long() #【注释:这里的12是句子最大查询长度,28是词汇表长度 ones(2, 12)表示2个句子,每个句子12个词, long()表示数据类型为long】print(aaa.shape) # torch.Size([2, 12])ebd = EBD()print(ebd(aaa).shape) # torch.Size([2, 12, 24])attention_block = Attention_block()print(attention_block(ebd(aaa)).shape) # torch.Size([2, 12, 24])多头注意力


import torch
from torch import nn#【词汇表长度:28】
#【句子最大查询长度:12】class EBD(nn.Module):def __init__(self, *args, **kwargs)-> None:super(EBD, self).__init__(*args, **kwargs)# 词嵌入层self.word_ebd = nn.Embedding(28, 24)# 位置编码层self.pos_ebd = nn.Embedding(12, 24)self.pos_t = torch.arange(0,12).reshape(1, 12) #【注释:arange(0,12)表示0到11的数字,reshape(1, 12)表示将其变为1行12列的矩阵,pos_t表示位置编码矩阵,用于将位置信息编码到词向量中】# 编码层# X: [batch_size, seq_len]def forward(self, X:torch.tensor):return self.word_ebd(X) + self.pos_ebd(self.pos_t)
def attention(Q, K, V):A = Q @ K.transpose(-1, -2) #【注释:@表示矩阵乘法,transpose(-1, -2)表示计转至K的最后两个维度】A = A / (K.shape[-1] ** 0.5) #【注释:K.shape[-1]表示K的最后一个维度,**0.5表示取平方根】A = torch.softmax(A, dim=-1)O = A @ Vreturn O
def transpose_qkv(QKV:torch.tensor):QKV = QKV.reshape(QKV.shape[0], QKV.shape[1], 4, 6) #【torch.Size([batch_size, seq_len, 4, 6])表示输入的QKV的形状,4表示QKV的个数,6表示每个QKV的维度】QKV = QKV.transpose(-2, -3) #【注释:置换1和2维度】return QKV
def transpose_o(O:torch.tensor):O = O.transpose(-2, -3) # O: torch.Size([2, 12, 4, 6])O = O.reshape(O.shape[0], O.shape[1], -1)return O
class Attention_block(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Attention_block, self).__init__(*args, **kwargs)# 注意力层:相当于一个MLP,输入为词向量,输出为注意力权重self.W_q = nn.Linear(24, 24, bias=False)self.W_k = nn.Linear(24, 24, bias=False)self.W_v = nn.Linear(24, 24, bias=False)self.W_o = nn.Linear(24, 24, bias=False)def forward(self, X:torch.tensor):Q, K, V = self.W_q(X), self.W_k(X), self.W_v(X)# 转置QKVQ, K, V = transpose_qkv(Q), transpose_qkv(K), transpose_qkv(V) #【Q: torch.Size([2, 4, 12, 6])】# 计算注意力权重O = attention(Q, K, V) # O: torch.Size([2, 4, 12, 6])O = transpose_o(O) # O: torch.Size([2, 12, 24])O = self.W_o(O)print('O', O.shape)return Oif __name__ == '__main__':aaa = torch.ones(2, 12).long() #【注释:这里的12是句子最大查询长度,28是词汇表长度 ones(2, 12)表示2个句子,每个句子12个词, long()表示数据类型为long】print(aaa.shape) # torch.Size([2, 12])ebd = EBD()print(ebd(aaa).shape) # torch.Size([2, 12, 24])attention_block = Attention_block()print(attention_block(ebd(aaa)).shape) # torch.Size([2, 12, 24])加 & 规范化 || 逐位前馈网络
加 & 规范化:防止模型过拟合。
逐位前馈网络:
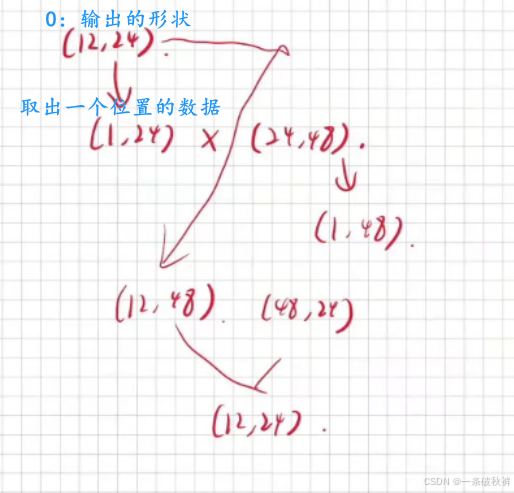
# 加&规范化层
class Add_norm(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Add_norm, self).__init__(*args, **kwargs)self.add_norm = nn.LayerNorm(24)def forward(self, X:torch.tensor, Y:torch.tensor):X = X + YX = self.add_norm(X) #【注释:LayerNorm(24)表示对24维的词向量进行层归一化】return X# 逐位前馈网络层
class Pos_FFN(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Pos_FFN, self).__init__(*args, **kwargs)self.linear1 = nn.Linear(24, 48)self.linear2 = nn.Linear(48, 24)self.relu = nn.ReLU()def forward(self, X:torch.tensor):X = self.linear1(X)X = self.relu(X)X = self.linear2(X)X = self.relu(X)return X编码器
import torch
from torch import nn#【词汇表长度:28】
#【句子最大查询长度:12】# 词嵌入层
class EBD(nn.Module):def __init__(self, *args, **kwargs)-> None:super(EBD, self).__init__(*args, **kwargs)# 词嵌入层self.word_ebd = nn.Embedding(28, 24)# 位置编码层self.pos_ebd = nn.Embedding(12, 24)self.pos_t = torch.arange(0,12).reshape(1, 12) #【注释:arange(0,12)表示0到11的数字,reshape(1, 12)表示将其变为1行12列的矩阵,pos_t表示位置编码矩阵,用于将位置信息编码到词向量中】# 编码层# X: [batch_size, seq_len]def forward(self, X:torch.tensor):return self.word_ebd(X) + self.pos_ebd(self.pos_t)# 注意力层
def attention(Q, K, V):A = Q @ K.transpose(-1, -2) #【注释:@表示矩阵乘法,transpose(-1, -2)表示计转至K的最后两个维度】A = A / (K.shape[-1] ** 0.5) #【注释:K.shape[-1]表示K的最后一个维度,**0.5表示取平方根】A = torch.softmax(A, dim=-1)O = A @ Vreturn O
def transpose_qkv(QKV:torch.tensor):QKV = QKV.reshape(QKV.shape[0], QKV.shape[1], 4, 6) #【torch.Size([batch_size, seq_len, 4, 6])表示输入的QKV的形状,4表示QKV的个数,6表示每个QKV的维度】QKV = QKV.transpose(-2, -3) #【注释:置换1和2维度】return QKV
def transpose_o(O:torch.tensor):O = O.transpose(-2, -3) # O: torch.Size([2, 12, 4, 6])O = O.reshape(O.shape[0], O.shape[1], -1)return O
class Attention_block(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Attention_block, self).__init__(*args, **kwargs)# 注意力层:相当于一个MLP,输入为词向量,输出为注意力权重self.W_q = nn.Linear(24, 24, bias=False)self.W_k = nn.Linear(24, 24, bias=False)self.W_v = nn.Linear(24, 24, bias=False)self.W_o = nn.Linear(24, 24, bias=False)def forward(self, X:torch.tensor):Q, K, V = self.W_q(X), self.W_k(X), self.W_v(X)# 转置QKVQ, K, V = transpose_qkv(Q), transpose_qkv(K), transpose_qkv(V) #【Q: torch.Size([2, 4, 12, 6])】# 计算注意力权重O = attention(Q, K, V) # O: torch.Size([2, 4, 12, 6])O = transpose_o(O) # O: torch.Size([2, 12, 24])O = self.W_o(O)# print('O', O.shape)return O# 加&规范化层
class Add_norm(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Add_norm, self).__init__(*args, **kwargs)self.add_norm = nn.LayerNorm(24)self.dropout = nn.Dropout(0.1)def forward(self, X:torch.tensor, Y:torch.tensor):X = X + YX = self.add_norm(X) #【注释:LayerNorm(24)表示对24维的词向量进行层归一化】X = self.dropout(X)return X# 逐位前馈网络层
class Pos_FFN(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Pos_FFN, self).__init__(*args, **kwargs)self.linear1 = nn.Linear(24, 48)self.linear2 = nn.Linear(48, 24)self.relu = nn.ReLU()def forward(self, X:torch.tensor):X = self.linear1(X)X = self.relu(X)X = self.linear2(X)X = self.relu(X)return X# 编码器层
class Encoder_block(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Encoder_block, self).__init__(*args, **kwargs)self.attention_block = Attention_block()self.add_norm1 = Add_norm()self.pos_ffn = Pos_FFN()self.add_norm2 = Add_norm()def forward(self, X:torch.tensor):X1 = self.attention_block(X)X = self.add_norm1(X, X1)X1 = self.pos_ffn(X)X = self.add_norm2(X, X1)return X
class Encoder_layer(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Encoder_layer, self).__init__(*args, **kwargs)self.ebd = EBD()self.encoder_blks = nn.Sequential()self.encoder_blks.append(Encoder_block())self.encoder_blks.append(Encoder_block())def forward(self, X:torch.tensor):X = self.ebd(X)for encoder_blk in self.encoder_blks:X = encoder_blk(X)return Xif __name__ == '__main__':aaa = torch.ones(2, 12).long() #【注释:这里的12是句子最大查询长度,28是词汇表长度 ones(2, 12)表示2个句子,每个句子12个词, long()表示数据类型为long】print(aaa.shape) # torch.Size([2, 12])encoder = Encoder_layer()print(encoder(aaa).shape) # torch.Size([2, 12, 24])2-解码器
解码器工作过程:
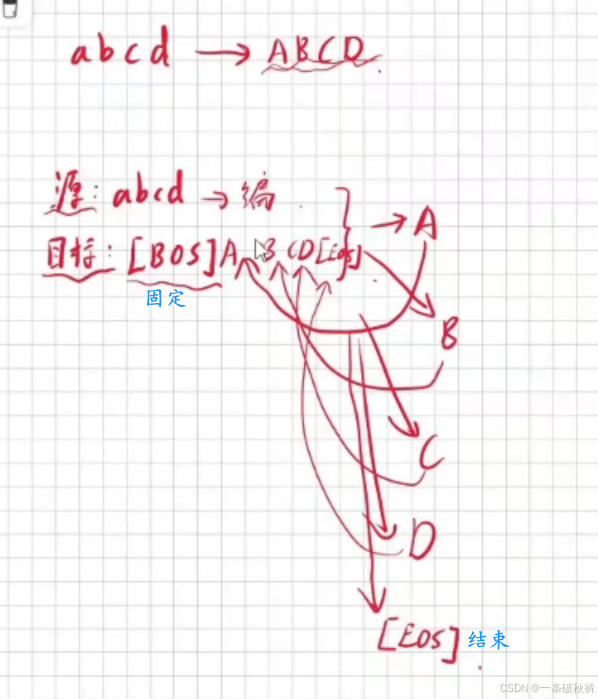
解码器输入:

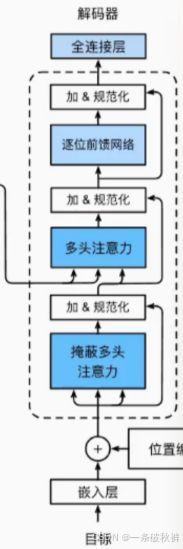
# 解码器层
class Cross_attention_block(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Cross_attention_block, self).__init__(*args, **kwargs)self.W_q = nn.Linear(24, 24, bias=False)self.W_k = nn.Linear(24, 24, bias=False)self.W_v = nn.Linear(24, 24, bias=False)self.W_o = nn.Linear(24, 24, bias=False)def forward(self, X:torch.tensor, X_encoder:torch.tensor):Q, K, V = self.W_q(X), self.W_k(X_encoder), self.W_v(X_encoder)Q, K, V = transpose_qkv(Q), transpose_qkv(K), transpose_qkv(V) #【Q: torch.Size([2, 4, 12, 6])】O = attention(Q, K, V) # O: torch.Size([2, 4, 12, 6])O = transpose_o(O) # O: torch.Size([2, 12, 24])O = self.W_o(O)return O
class Decoder_block(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Decoder_block, self).__init__(*args, **kwargs)self.attention_block = Attention_block()self.add_norm1 = Add_norm()self.cross_attention_block = Cross_attention_block()self.add_norm2 = Add_norm()self.pos_ffn = Pos_FFN()self.add_norm3 = Add_norm()def forward(self, X:torch.tensor, X_encoder:torch.tensor):X1 = self.attention_block(X)X = self.add_norm1(X, X1)X1 = self.cross_attention_block(X, X_encoder)X = self.add_norm2(X, X1)X1 = self.pos_ffn(X)X = self.add_norm3(X, X1)return Xclass Decoder(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Decoder, self).__init__(*args, **kwargs)self.ebd = EBD()self.decoder_blks = nn.Sequential()self.decoder_blks.append(Decoder_block())self.decoder_blks.append(Decoder_block())self.dense = nn.Linear(24, 28, bias=False)def forward(self, X:torch.tensor, X_encoder:torch.tensor):X = self.ebd(X)for decoder_blk in self.decoder_blks:X = decoder_blk(X, X_encoder)X = self.dense(X)return X3-模型构建
import torch
from torch import nn#【词汇表长度:28】
#【句子最大查询长度:12】# 词嵌入层
class EBD(nn.Module):def __init__(self, *args, **kwargs)-> None:super(EBD, self).__init__(*args, **kwargs)# 词嵌入层self.word_ebd = nn.Embedding(29, 24)# 位置编码层self.pos_ebd = nn.Embedding(12, 24)self.pos_t = torch.arange(0, 12).reshape(1, 12) #【注释:arange(0,12)表示0到11的数字,reshape(1, 12)表示将其变为1行12列的矩阵,pos_t表示位置编码矩阵,用于将位置信息编码到词向量中】# 编码层# X: [batch_size, seq_len]def forward(self, X:torch.tensor):return self.word_ebd(X) + self.pos_ebd(self.pos_t[:, :X.shape[-1]])# 注意力层
def attention(Q, K, V):A = Q @ K.transpose(-1, -2) #【注释:@表示矩阵乘法,transpose(-1, -2)表示计转至K的最后两个维度】A = A / (K.shape[-1] ** 0.5) #【注释:K.shape[-1]表示K的最后一个维度,**0.5表示取平方根】A = torch.softmax(A, dim=-1)O = A @ Vreturn O
def transpose_qkv(QKV:torch.tensor):QKV = QKV.reshape(QKV.shape[0], QKV.shape[1], 4, 6) #【torch.Size([batch_size, seq_len, 4, 6])表示输入的QKV的形状,4表示QKV的个数,6表示每个QKV的维度】QKV = QKV.transpose(-2, -3) #【注释:置换1和2维度】return QKV
def transpose_o(O:torch.tensor):O = O.transpose(-2, -3) # O: torch.Size([2, 12, 4, 6])O = O.reshape(O.shape[0], O.shape[1], -1)return O
class Attention_block(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Attention_block, self).__init__(*args, **kwargs)# 注意力层:相当于一个MLP,输入为词向量,输出为注意力权重self.W_q = nn.Linear(24, 24, bias=False)self.W_k = nn.Linear(24, 24, bias=False)self.W_v = nn.Linear(24, 24, bias=False)self.W_o = nn.Linear(24, 24, bias=False)def forward(self, X:torch.tensor):Q, K, V = self.W_q(X), self.W_k(X), self.W_v(X)# 转置QKVQ, K, V = transpose_qkv(Q), transpose_qkv(K), transpose_qkv(V) #【Q: torch.Size([2, 4, 12, 6])】# 计算注意力权重O = attention(Q, K, V) # O: torch.Size([2, 4, 12, 6])O = transpose_o(O) # O: torch.Size([2, 12, 24])O = self.W_o(O)# print('O', O.shape)return O# 加&规范化层
class Add_norm(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Add_norm, self).__init__(*args, **kwargs)self.add_norm = nn.LayerNorm(24)self.dropout = nn.Dropout(0.1)def forward(self, X:torch.tensor, Y:torch.tensor):X = X + YX = self.add_norm(X) #【注释:LayerNorm(24)表示对24维的词向量进行层归一化】X = self.dropout(X)return X# 逐位前馈网络层
class Pos_FFN(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Pos_FFN, self).__init__(*args, **kwargs)self.linear1 = nn.Linear(24, 48, bias=False)self.linear2 = nn.Linear(48, 24, bias=False)self.relu = nn.ReLU()def forward(self, X:torch.tensor):X = self.linear1(X)X = self.relu(X)X = self.linear2(X)X = self.relu(X)return X# 编码器层
class Encoder_block(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Encoder_block, self).__init__(*args, **kwargs)self.attention_block = Attention_block()self.add_norm1 = Add_norm()self.pos_ffn = Pos_FFN()self.add_norm2 = Add_norm()def forward(self, X:torch.tensor):X1 = self.attention_block(X)X = self.add_norm1(X, X1)X1 = self.pos_ffn(X)X = self.add_norm2(X, X1)return X
class Encoder(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Encoder, self).__init__(*args, **kwargs)self.ebd = EBD()self.encoder_blks = nn.Sequential()self.encoder_blks.append(Encoder_block())self.encoder_blks.append(Encoder_block())def forward(self, X:torch.tensor):X = self.ebd(X)for encoder_blk in self.encoder_blks:X = encoder_blk(X)return X# 解码器层
class Cross_attention_block(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Cross_attention_block, self).__init__(*args, **kwargs)self.W_q = nn.Linear(24, 24, bias=False)self.W_k = nn.Linear(24, 24, bias=False)self.W_v = nn.Linear(24, 24, bias=False)self.W_o = nn.Linear(24, 24, bias=False)def forward(self, X:torch.tensor, X_encoder:torch.tensor):Q, K, V = self.W_q(X), self.W_k(X_encoder), self.W_v(X_encoder)Q, K, V = transpose_qkv(Q), transpose_qkv(K), transpose_qkv(V) #【Q: torch.Size([2, 4, 12, 6])】O = attention(Q, K, V) # O: torch.Size([2, 4, 12, 6])O = transpose_o(O) # O: torch.Size([2, 12, 24])O = self.W_o(O)return O
class Decoder_block(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Decoder_block, self).__init__(*args, **kwargs)self.attention_block = Attention_block()self.add_norm1 = Add_norm()self.cross_attention_block = Cross_attention_block()self.add_norm2 = Add_norm()self.pos_ffn = Pos_FFN()self.add_norm3 = Add_norm()def forward(self, X:torch.tensor, X_encoder:torch.tensor):X1 = self.attention_block(X)X = self.add_norm1(X, X1)X1 = self.cross_attention_block(X, X_encoder)X = self.add_norm2(X, X1)X1 = self.pos_ffn(X)X = self.add_norm3(X, X1)return Xclass Decoder(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Decoder, self).__init__(*args, **kwargs)self.ebd = EBD()self.decoder_blks = nn.Sequential()self.decoder_blks.append(Decoder_block())self.decoder_blks.append(Decoder_block())self.dense = nn.Linear(24, 28, bias=False)def forward(self, X:torch.tensor, X_encoder:torch.tensor):X = self.ebd(X)for decoder_blk in self.decoder_blks:X = decoder_blk(X, X_encoder)X = self.dense(X)return X# 构建模型
class Transformer(nn.Module):def __init__(self, *args, **kwargs)-> None:super(Transformer, self).__init__(*args, **kwargs)self.encoder = Encoder()self.decoder = Decoder()def forward(self, X_s, X_t):X_encoder = self.encoder(X_s)X = self.decoder(X_t, X_encoder)return Xif __name__ == '__main__':sss = torch.ones(2, 12).long() ttt = torch.ones(2, 4).long()model = Transformer()output = model(sss, ttt)print(output.shape) # torch.Size([2, 1, 28])4-数据&任务
生成数据
# 对于一个英语字符串,输出加密后的字符串,加密方式如下:
# 对于每一个字符,使其ASCII码值循环减5,然后将整个字符串逆序
# abcfg --> vwxab --> baxwvimport random# 定义字符集和特殊标记
vocab_list = ["[BOS]", "[EOS]", "[PAD]", 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k','l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
chr_list = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p','q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
bos_token = "[BOS]"
eos_token = "[EOS]"
pad_token = "[PAD]"# 定义文件路径
source_path = "/home74/liguangzhen/Project/Jupyther/Transformer/source.txt"
target_path = "/home74/liguangzhen/Project/Jupyther/Transformer/target.txt"# 清空文件内容
with open(source_path, "w") as f:passwith open(target_path, "w") as f:pass# 生成随机字符串并加密
with open(source_path, "a") as source_file, open(target_path, "a") as target_file:for _ in range(10000):source_str = ""target_str = ""# 随机生成字符串长度(3到13之间)length = random.randint(3, 13)for _ in range(length):# 随机选择一个字符char_index = random.randint(0, 25)source_str += chr_list[char_index]# 加密字符:循环减5encrypted_char_index = (char_index + 26 - 5) % 26target_str += chr_list[encrypted_char_index]# 逆序加密后的字符串target_str = target_str[::-1]# 写入文件source_file.write(source_str + "\n")target_file.write(target_str + "\n")print("数据生成完成!")生成数据集
import torch
import torch.utils.data as data
import numpy as np
from copy import deepcopyvocab_list = ["[BOS]", "[EOS]", "[PAD]", 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k','l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
chr_list = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p','q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
bos_token = "[BOS]"
eos_token = "[EOS]"
pad_token = "[PAD]"def proccess_dara(source, target):max_length = 12if len(source) > max_length:source = source[:max_length]if len(target) > max_length - 1:target = target[:max_length - 1]source_id = [vocab_list.index(token) for token in source]traget_id = [vocab_list.index(token) for token in target]traget_id = [vocab_list.index("[BOS]")] + traget_id + [vocab_list.index("[EOS]")]if len(source_id) < max_length:source_id += [vocab_list.index(pad_token)] * (max_length - len(source_id))if len(traget_id) < max_length:traget_id += [vocab_list.index(pad_token)] * (max_length - len(traget_id) + 1)return source_id, traget_idclass Dataset(data.Dataset):def __init__(self, source_path, target_path)-> None:super(Dataset, self).__init__()self.source_list = []self.target_list = []with open(source_path)as f:content = f.readlines()for line in content:self.source_list.append(deepcopy(line.strip()))with open(target_path)as f:content = f.readlines()for line in content:self.target_list.append(deepcopy(line.strip()))def __len__(self):return len(self.source_list)def __getitem__(self, index):source = self.source_list[index]target = self.target_list[index]return source, targetif __name__== "__main__":dataset = Dataset("source.txt", "target.txt")print(dataset[0])5-掩码
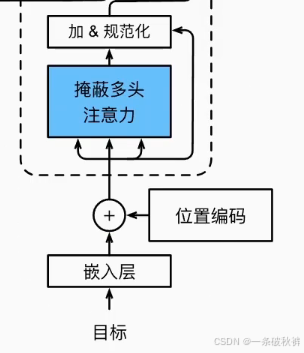
希望一次输入一个句子,提高计算效率。但是一个句子输入到模型,就等于提前告知模型答案,影响模型预测。所以使用掩码进行掩蔽。还有就是句子长度不够,补充[pad]时也会影响模型效率,也需要掩码进行掩蔽。

掩码
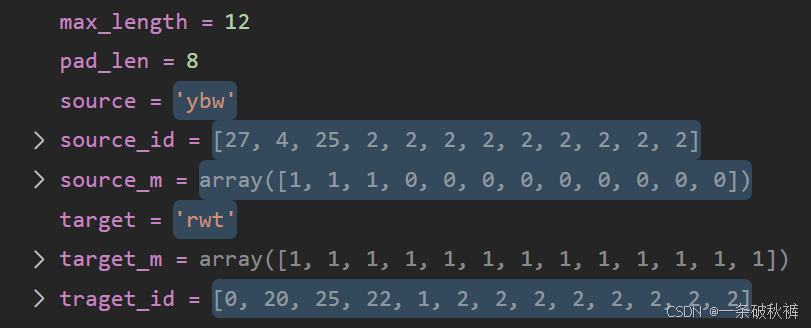
import torch
import torch.utils.data as data
import numpy as np
from copy import deepcopyvocab_list = ["[BOS]", "[EOS]", "[PAD]", 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k','l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
chr_list = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p','q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
bos_token = "[BOS]" # 开始标记
eos_token = "[EOS]" # 结束标记
pad_token = "[PAD]" # 填充标记def proccess_dara(source, target):max_length = 12if len(source) > max_length:source = source[:max_length]if len(target) > max_length - 1:target = target[:max_length - 1]source_id = [vocab_list.index(token) for token in source]traget_id = [vocab_list.index(token) for token in target]traget_id = [vocab_list.index("[BOS]")] + traget_id + [vocab_list.index("[EOS]")]source_m = np.array([1] * max_length)target_m = np.array([1] * (max_length + 1))if len(source_id) < max_length:pad_len = max_length - len(source_id)source_id += [vocab_list.index(pad_token)] *pad_lensource_m[-pad_len:] = 0if len(traget_id) < max_length:pad_len = max_length - len(traget_id) + 1traget_id += [vocab_list.index(pad_token)] * pad_lentarget_m[-pad_len:] = 0return source_id, source_m, traget_id, target_mclass Dataset(data.Dataset):def __init__(self, source_path, target_path)-> None:super(Dataset, self).__init__()self.source_list = []self.target_list = []with open(source_path, "r")as f:content = f.readlines() # 读取全部内容for line in content:self.source_list.append(line.strip())with open(target_path, "r")as f:content = f.readlines()for line in content:self.target_list.append(line.strip())# print(self.source_list)# print(self.target_list)print(len(self.source_list))print(len(self.target_list))def __len__(self):return len(self.source_list)def __getitem__(self, index):source_id, source_m, target_id, target_m = proccess_dara(self.source_list[index], self.target_list[index])return torch.LongTensor(source_id), torch.FloatTensor(source_m), torch.LongTensor(target_id), torch.FloatTensor(target_m)if __name__== "__main__":dataset = Dataset(r"/home74/liguangzhen/Project/Jupyther/Transformer/source.txt", r"/home74/liguangzhen/Project/Jupyther/Transformer/target.txt")print(len(dataset)) # 10000print(dataset[3]) #(tensor([27, 4, 25, 2, 2, 2, 2, 2, 2, 2, 2, 2]), tensor([1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.]), tensor([ 0, 20, 25, 22, 1, 2, 2, 2, 2, 2, 2, 2, 2]), tensor([1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.]))模型添加掩码
烂尾中...