行业电子商务网站有哪些西安排名seo公司
爬虫其实就是请求http、解析网页、存储数据的过程,并非高深的技术,但凡是编程语言都能做,连Excel VBA都可以实现爬虫,但Python爬虫的使用频率最高、场景最广。

这可不仅仅是因为Python有众多爬虫和数据处理库,还有一个更直接的原因是Python足够简单。
Python作为解释型语言,不需要编译就可以运行,而且采用动态类型,灵活赋值,同样的功能实现,代码量比Java、C++少很多。
而且Python既可以面向对象也可以面向过程编程,这样就简化了爬虫脚本编写的难度,即使新手也可以快速入门。

比如一个简单网页请求和解析任务,Python只需要7行代码,Java则需要20行。
python实现:
requests.get用于请求http服务,soup.find_all用于解析html
import requests
from bs4 import BeautifulSoupurl = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')links = [a['href'] for a in soup.find_all('a', href=True)]
print(links)
Java实现:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;public class JavaCrawler {public static void main(String[] args) {String url = "https://example.com";try {Document doc = Jsoup.connect(url).get();Elements links = doc.select("a[href]");for (Element link : links) {System.out.println(link.attr("href"));}} catch (IOException e) {e.printStackTrace();}}
}
当然python的第三方库生态也为Python爬虫提供了诸多便利,比如requests、bs4、scrapy,这些库将爬虫技术进行了高级封装,提供了便捷的api接口,原来需要几十行代码解决的问题,现在只需要一行就可以搞定。
这里介绍6个最常用的爬虫库。
requests
不用多说,requests 是 Python 中一个非常流行的第三方库,用于发送各种 HTTP 请求。它简化了 HTTP 请求的发送过程,使得从网页获取数据变得非常简单和直观。
requests 库提供了丰富的功能和灵活性,支持多种请求类型(如 GET、POST、PUT、DELETE 等),可以发送带有参数、头信息、文件等的请求,并且能够处理复杂的响应内容(如 JSON、XML 等)。

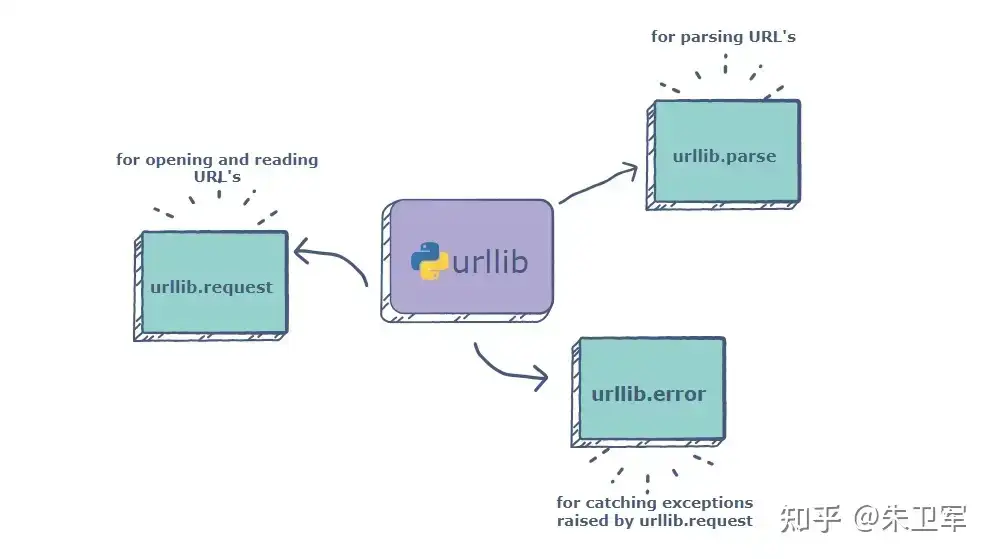
urllib3
urllib3 是 Python内置网页请求库,类似于requests库,主要用于发送HTTP请求和处理HTTP响应。它建立在Python标准库的urllib模块之上,但提供了更高级别、更健壮的API。
urllib3可以用于处理简单身份验证、cookie 和代理等复杂任务。
BeautifulSoup
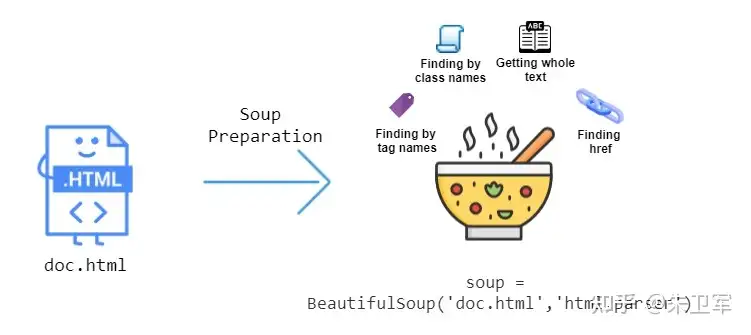
BeautifulSoup是最常用的Python网页解析库之一,可将 HTML 和 XML 文档解析为树形结构,能更方便地识别和提取数据。
此外,你还可以设置 BeautifulSoup 扫描整个解析页面,识别所有重复的数据(例如,查找文档中的所有链接),只需几行代码就能自动检测特殊字符等编码。
lxml
lxml也是网页解析库,主要用于处理XML和HTML文档。它提供了丰富的API,可以轻松地读取、解析、创建和修改XML和HTML文档。

Scrapy
Scrapy是一个流行的高级爬虫框架,可快速高效地抓取网站并从其页面中提取结构化数据。
由于 Scrapy 主要用于构建复杂的爬虫项目,并且它通常与项目文件结构一起使用。
Scrapy 不仅仅是一个库,还可以用于各种任务,包括监控、自动测试和数据挖掘。
Selenium
Selenium 是一款基于浏览器地自动化程序库,可以抓取网页数据。它能在 JavaScript 渲染的网页上高效运行,这在其他 Python 库中并不多见。
在开始使用 Python 处理 Selenium 之前,需要先使用 Selenium Web 驱动程序创建功能测试用例。
Selenium 库能很好地与任何浏览器(如 Firefox、Chrome、IE 等)配合进行测试,比如表单提交、自动登录、数据添加/删除和警报处理等。
其实除了Python这样编程语言实现爬虫之外,还有其他无代码爬虫工具可以使用。
八爪鱼爬虫
八爪鱼是一款简单方便的桌面端爬虫软件,主打可视化操作,即使是没有任何编程基础的用户也能轻松上手。
八爪鱼支持多种数据类型采集,包括文本、图片、表格等,并提供强大的自定义功能,能够满足不同用户需求。此外,八爪鱼爬虫支持将采集到的数据导出为多种格式,方便后续分析处理。
使用和下载:https://affiliate.bazhuayu.com/zwjzht

亮数据爬虫
亮数据则是专门用于复杂网页数据采集的工具,可以搞定反爬、动态页面,比如它的Web Scraper IDE、亮数据浏览器、SERP API等,能够自动化地从网站上抓取所需数据,无需分析目标平台的接口,直接使用亮数据提供的方案即可安全稳定地获取数据。
而且亮数据有个很强大的功能:Scraper APIs,你可以理解成一种爬虫接口,它帮你绕开了IP限制、验证码、加密等问题,无需编写任何的反爬机制处理、动态网页处理代码,后续也无需任何维护,就可以“一键”获取Tiktok、Amazon、Linkedin、Github、Instagram等全球各大主流网站数据。
web直接使用:https://get.brightdata.com/webscra
Web Scraper
Web Scraper是一款轻便易用的浏览器扩展插件,用户无需安装额外的软件,即可在Chrome浏览器中进行爬虫。插件支持多种数据类型采集,并可将采集到的数据导出为多种格式。
无论是Python库还是爬虫软件,都能实现数据采集任务,可以选择适合自己的。当然记得在使用这些工具时,一定要遵守相关网站的爬虫政策和法律法规。