网站建设没有业务怎么办南昌seo网站推广
RAG从入门到精通系列1:基础RAG
原创 南七无名式 PyTorch研习社
LLM(Large Language Model,大型语言模型)是一个功能强大的新平台,但它们并不总是使用与我们的任务相关的数据或者是最新的数据进行训练。
RAG(Retrieval Augmented Generation,检索增强生成)是一种将 LLM 与外部数据源(例如私有数据或最新数据)连接的通用方法。它允许 LLM 使用外部数据来生成其输出。
要想真正掌握 RAG,我们需要学习下图所示的技术(技巧):
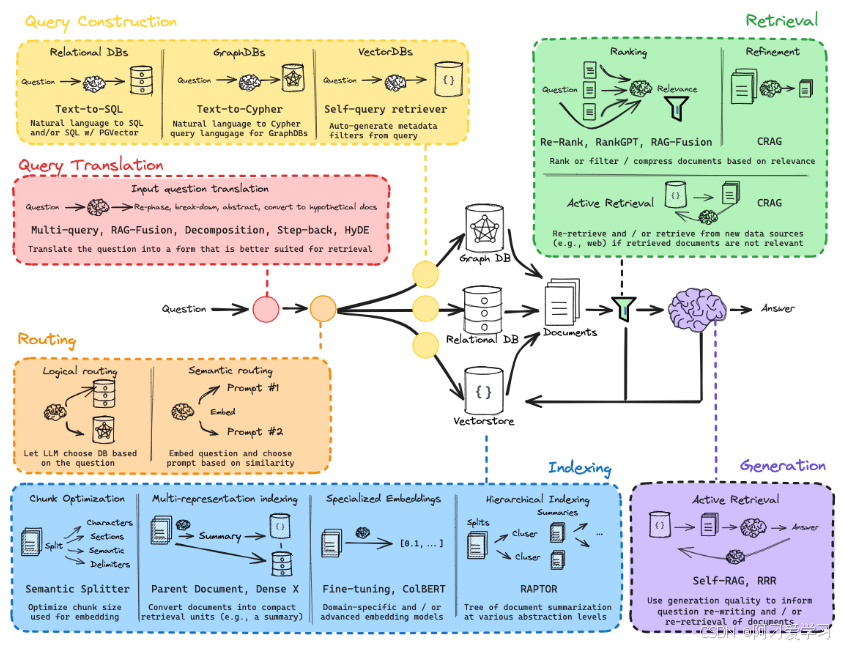
这个图看起来很让人头大,但是不用担心,你来对地方了。
本系列教程将从头开始介绍如何建立对 RAG 的理解。
我们先从 Indexing(索引)、**Retrieval(检索)**和 **Generation(生成)**的基础知识开始。
下面的流程图说明了基础 RAG 的过程:
我们对外部文档建立索引(Indexing);
根据用户的问题去检索(Retrieval)相关的文档;
将问题和相关的文档输入 LLM 生成(Generation)最终答案。
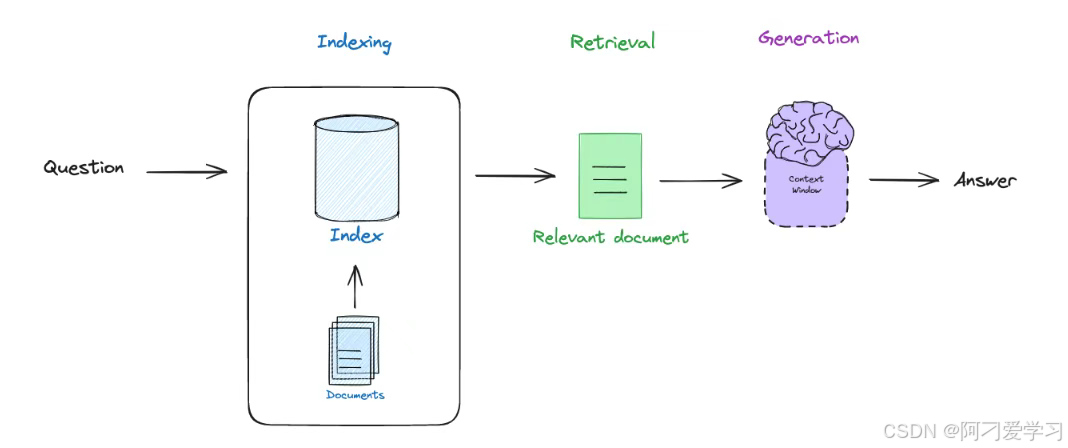
Indexing
我们从加载文档开始学习 Indexing。LangChain 有超过 160 种不同的文档加载器,我们可以使用它们从许多不同的来源抓取数据进行 Indexing。
https://python.langchain.com/docs/integrations/document_loaders/
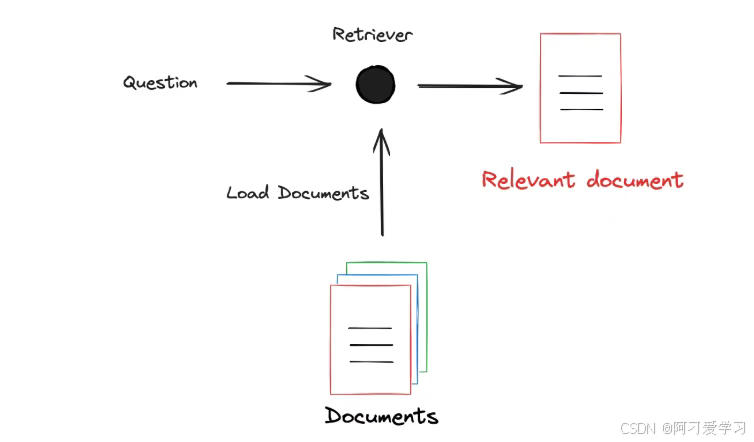
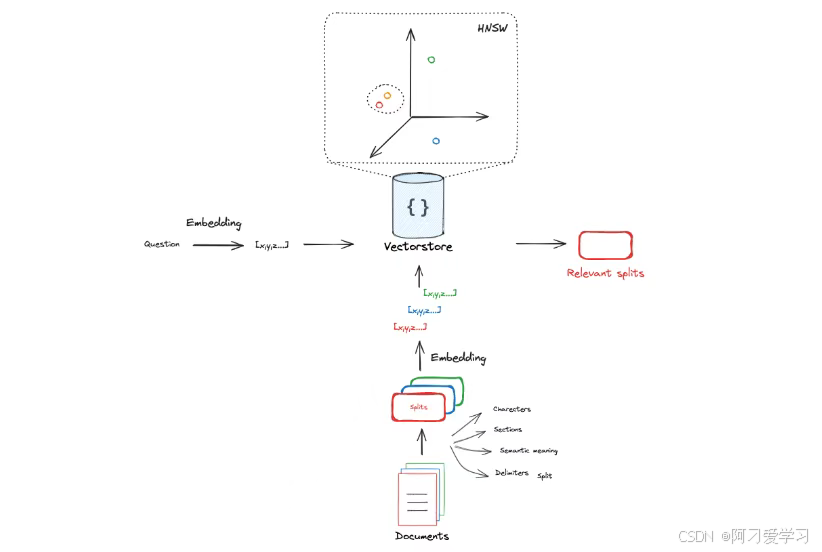
我们将 Question(问题)输入到 Retriever(检索器),Retriever 也会加载外部文档(知识),然后筛选出与 Question 相关的文档:
我们需要将 Text Representation(文本表示)转成 Numerical Representation(数值表示)才能更好地实现相关性(比如余弦相似度)筛选:
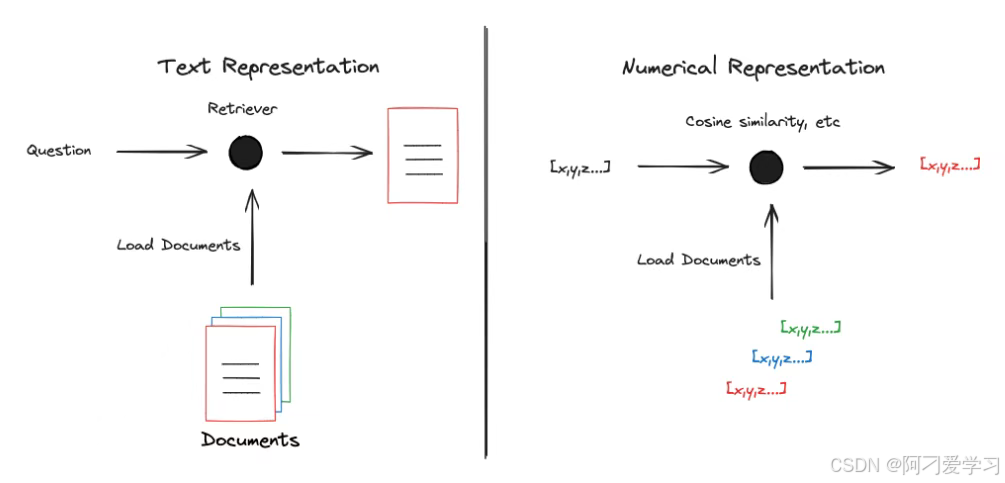
有很多种方法可以将文本转成数值表示,典型的有:
Statistical(基于统计学)
Machine Learned(基于机器学习)

目前最常用的就是使用机器学习方法将文本转成固定长度的,可捕获文本语义的 Embedding Vector(嵌入向量)。
有很多开源的 Embedding Model(比如 BAAI 系列)可以将文本转成 Embedding Vector。但是这些模型能接受的 Context Window(上下文窗口)有限,一般在 512~8192 个 token(如果你不知道什么是 token 的话,请跳到文末)。
所以正常的流程是我们将外部文档切分成一个个 Split,使得这些 Split 的长度能够满足 Embedding Model 的 Context Window:
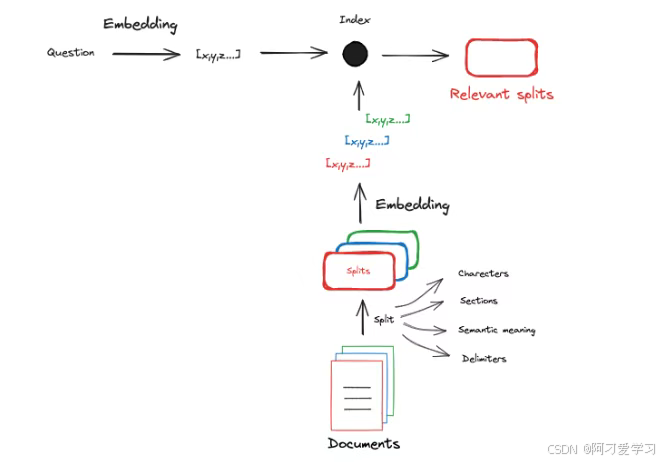
到现在,我们已经掌握了 Indexing 的理论了,现在可以用 Qwen + BAAI + LangChain + Qdrant 实践了。
首先配置 LLM 和 Embedding Model:

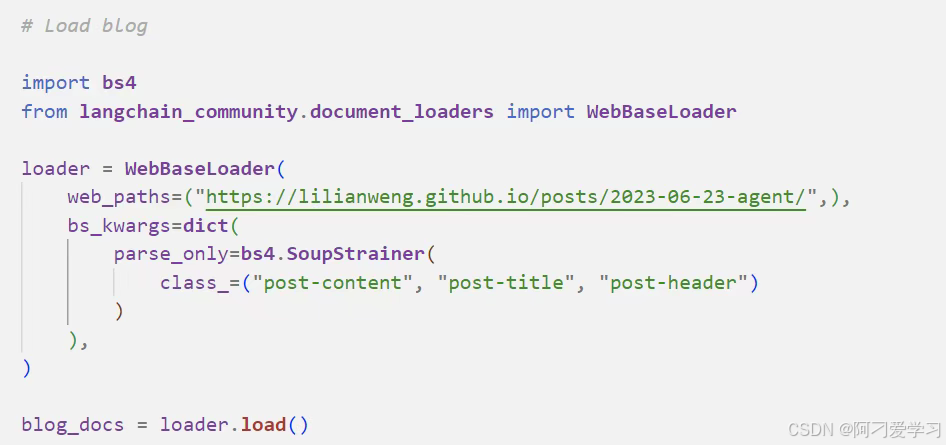
然后加载外部文档,这里的文档是一个网页博客:
正如我之前说的, Embedding Model 的 Context Window 有限,我们不能直接把整篇文档丢进去,所以要将原始文档拆分成一个个文档块:

接下来就是配置 Qdrant 向量数据库:

可以阅读《Qdrant:使用Rust编写的开源向量数据库&向量搜索引擎》了解一下 Qdrant。
最后一步对文档块建立索引并存到向量数据库中:

Retrieval
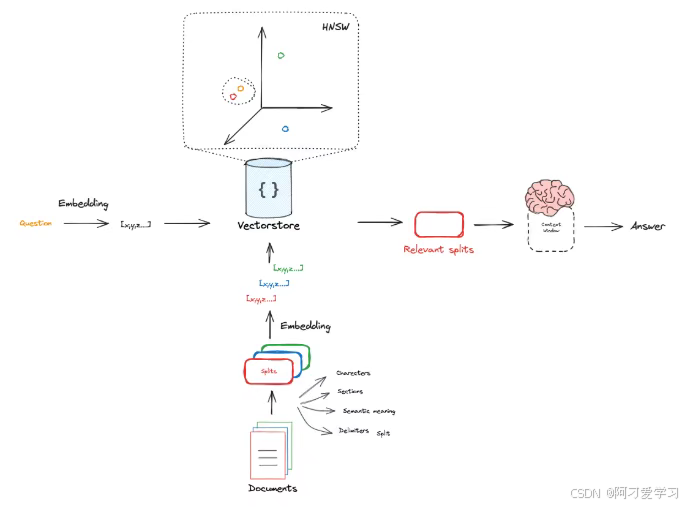
Retrieval 就是根据我们提出的问题的语义向量(也就是 Embedding Vector)去按照某种距离/相似度衡量方法找出与之相似的 k 个 Split 的语义向量。
下图演示了一个在一个 3D 空间的 Embedding Vector Retrieval:
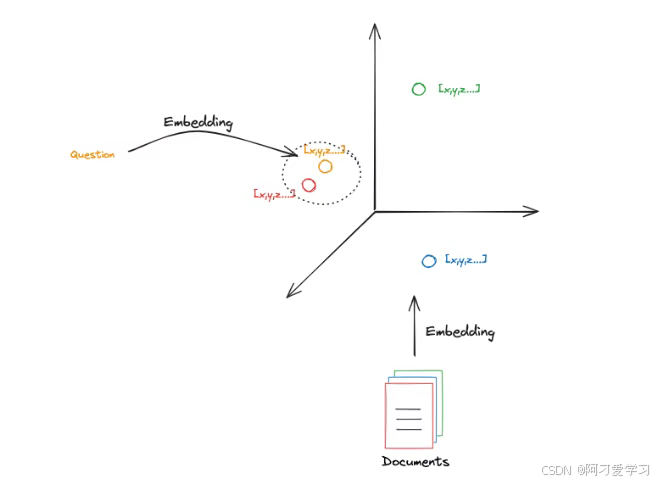
Embedding Vector 通常存储在 Vector Store(向量数据库)中,Vector Store 实现了各种比较 Embedding Vector 之间相似度的方法。
接下来我们用在 Indexing 时构建的 Vector Store 构建一个 retriever,然后输入问题并进行检索:
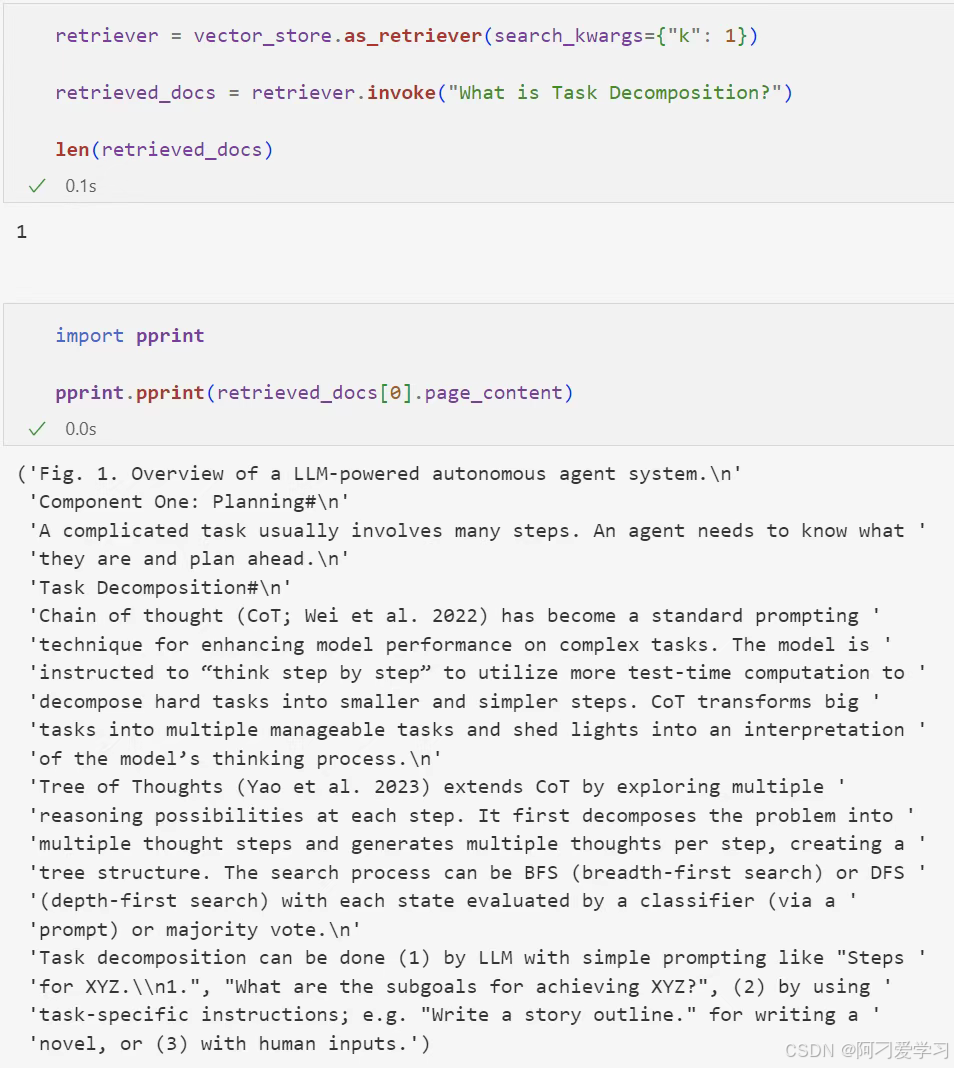
根据我们设定的 k 值,我们检索出了一个与问题相关的文档块。
Generation
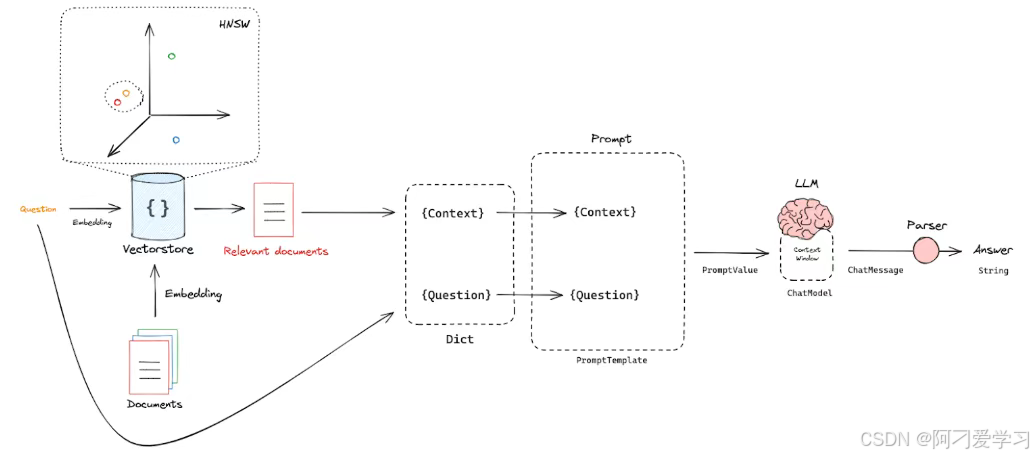
现在我们已经能够根据用户的问题检索出与之相关的知识片段(Split),那么我们现在需要将这些信息(问题 + 知识片段)输入 LLM,让 LLM 帮忙生成一个有时事实依据(知识片段)的回答:
我们需要:
问题和知识片段放到一个字典中,问题放到 Question 这个 key,知识片段放到 Context 这个 key;
然后通过 PromptTemplate 组成一个 Prompt String;
最后将 Prompt String 输入 LLM,LLM 再产生回答。
看起来很复杂,但这就是 LangChain 和 LlamaIndex 这类框架存在的意义:
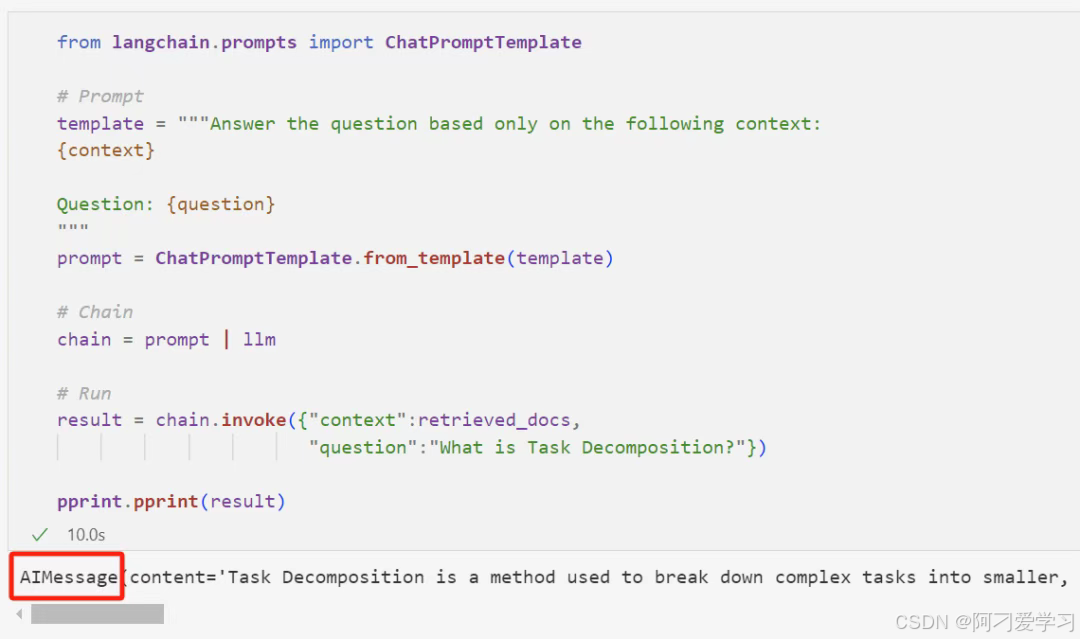
细心的你发现返回的结果是一个 AIMessage 对象,我们可能需要一个纯字符串的输出结果;而且检索过程和生成过程是分开的,这很不方便。
不过我们可以借助于 LangChain 将上述检索和生成过程链(Chain)在一起:

LangSmith
如果你还是对整个 RAG 管道过程很陌生,那么不妨去 LangSmith 页面上看一下整个过程是怎么被一步步串到一起的:
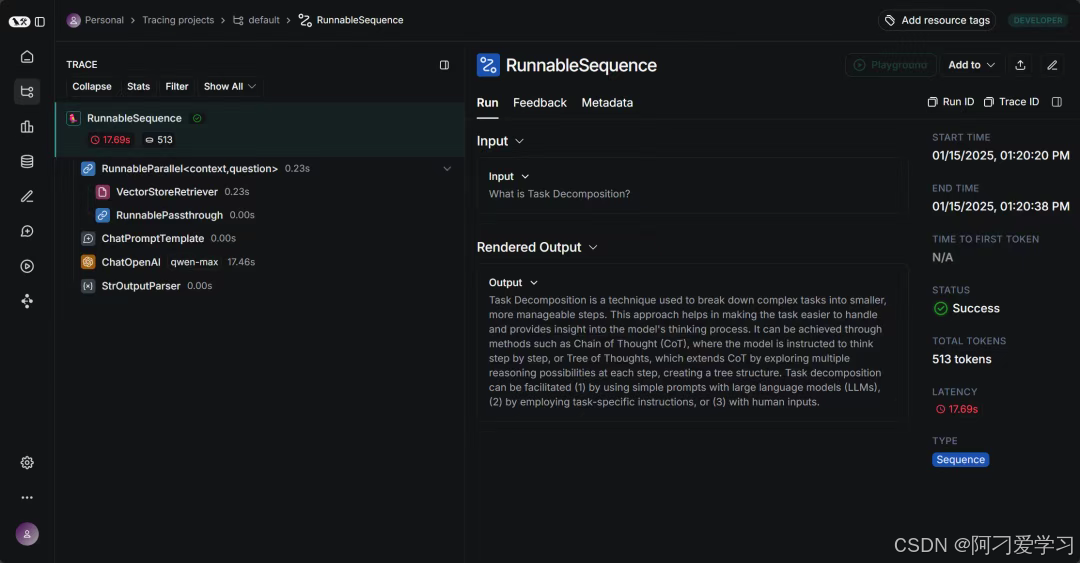
LangSmith 是一个用于构建生产级 LLM 应用程序的平台。它允许我们密切监控和评估我们的应用程序,以便我们可以快速、自信地交付。使用 LangSmith,我们可以:
跟踪 LLM 应用程序
了解 LLM 调用和应用程序逻辑的其他部分。
什么是 token?
token 是模型用来表示自然语言文本的基本单位,可以直观的理解为“字”或“词”。
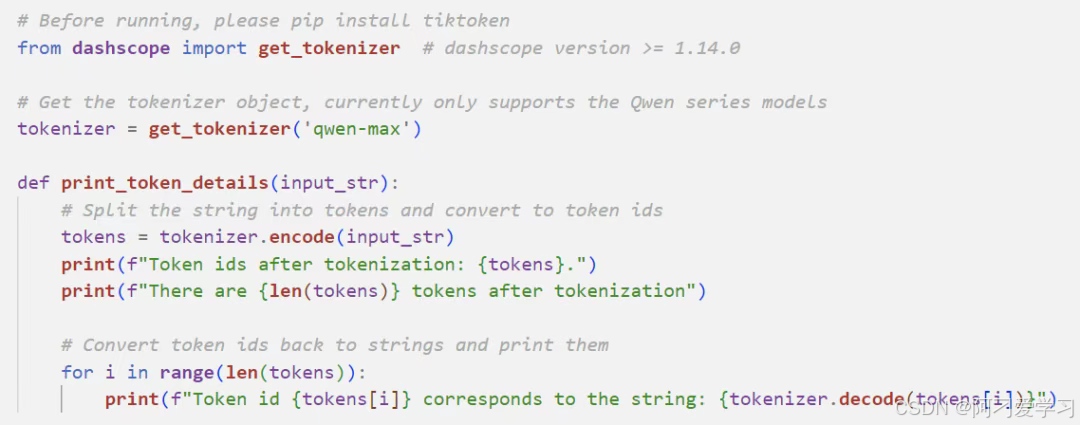
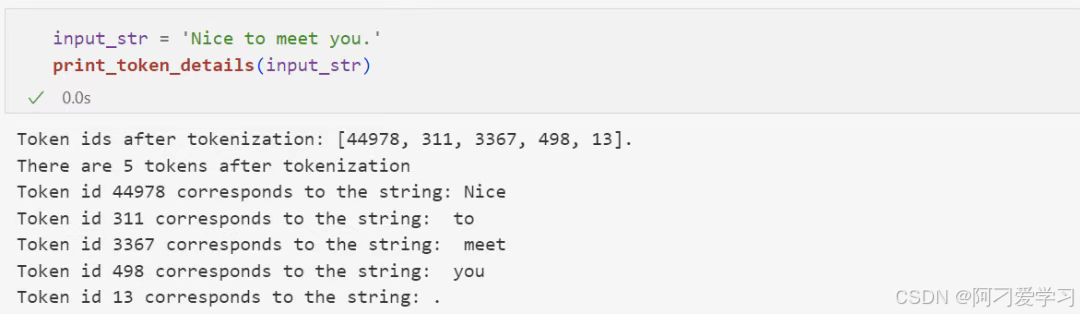
对于英文文本来说,1 个 token 通常对应 3 至 4 个字母:
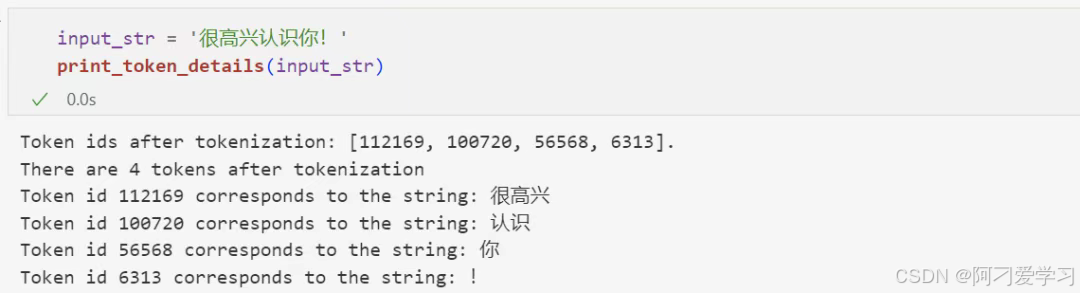
对于中文文本来说,1 个 token 通常对应一个汉字:
GitHub 链接:
https://github.com/realyinchen/RAG/blob/main/01_Indexing_Retrieval_Generation.ipynb
文章来源:PyTorch研习社