电商 网站模板永久域名查询
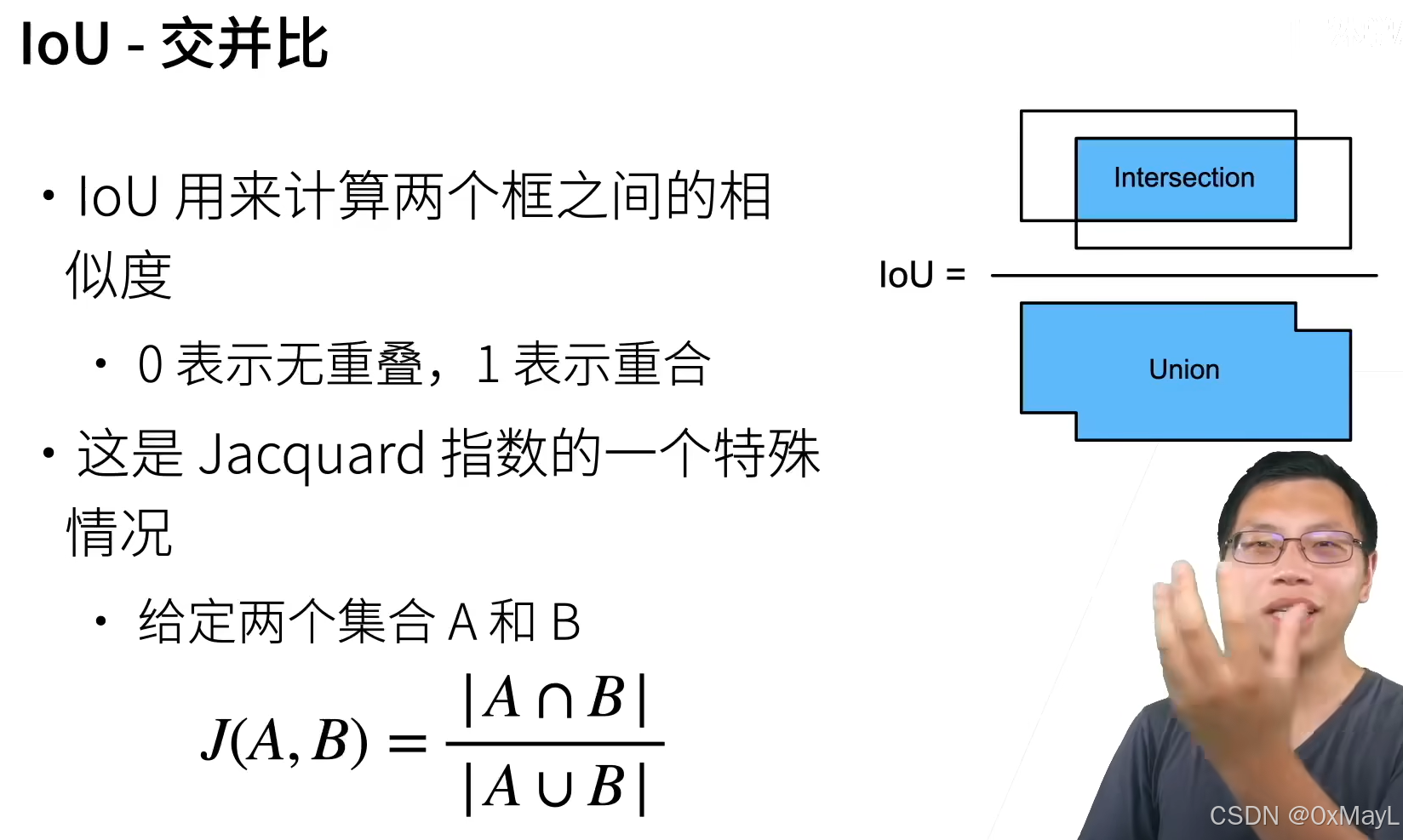
边缘框
- 不是标准的x,y坐标轴。
- 边缘框三种表示:左上右下下坐标,左上坐标+长宽,中心坐标+长宽

COCO
- 目标检测数据集的格式:注意一个图片有多个物体,使用csv或者文件夹结构的格式不可取。

锚框算法
- 生成很多个锚框
- 锚框之间和真实边缘框匹配(标签)。
-
一般的目标检测模型不直接预测锚框的四个位置,而是预测与真实值的偏移。
- 对于背景类,会有个掩码将偏移值设置为0.
-
匹配标签后使用NMS输出最后预测的锚框

在训练数据中标注锚框
label:subsec_labeling-anchor-boxes
在训练集中,我们将每个锚框视为一个训练样本。
为了训练目标检测模型,我们需要每个锚框的类别(class)和偏移量(offset)标签,其中前者是与锚框相关的对象的类别,后者是真实边界框相对于锚框的偏移量。
在预测时,我们为每个图像生成多个锚框,预测所有锚框的类别和偏移量,根据预测的偏移量调整它们的位置以获得预测的边界框,最后只输出符合特定条件的预测边界框。
目标检测训练集带有真实边界框的位置及其包围物体类别的标签。
要标记任何生成的锚框,我们可以参考分配到的最接近此锚框的真实边界框的位置和类别标签。
下文将介绍一个算法,它能够把最接近的真实边界框分配给锚框。
将真实边界框分配给锚框
给定图像,假设锚框是A1,A2,…,AnaA_1, A_2, \ldots, A_{n_a}A1,A2,…,Ana,真实边界框是B1,B2,…,BnbB_1, B_2, \ldots, B_{n_b}B1,B2,…,Bnb,其中na≥nbn_a \geq n_bna≥nb。
让我们定义一个矩阵X∈Rna×nb\mathbf{X} \in \mathbb{R}^{n_a \times n_b}X∈Rna×nb,其中第iii行、第jjj列的元素xijx_{ij}xij是锚框AiA_iAi和真实边界框BjB_jBj的IoU。
该算法包含以下步骤。
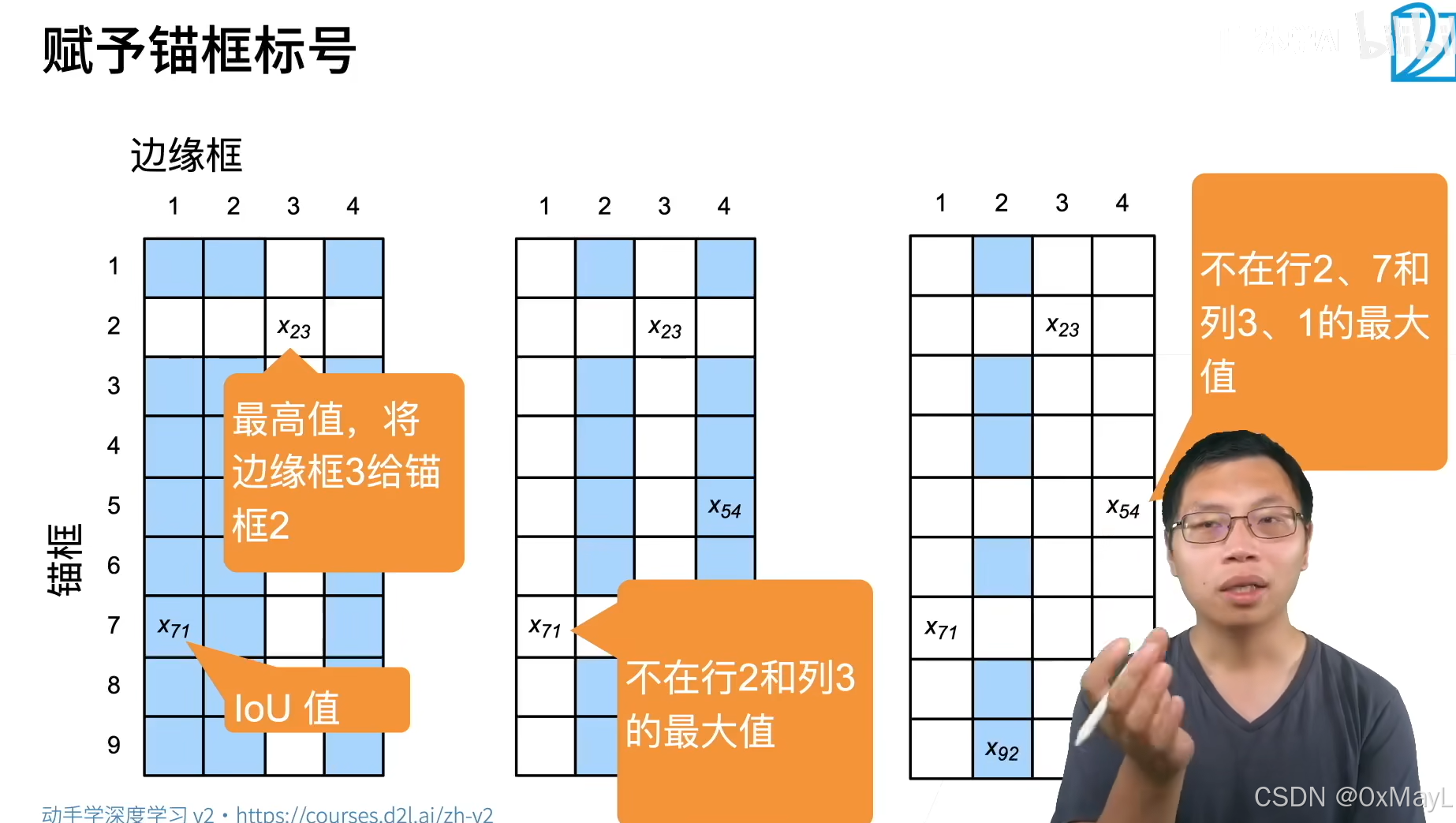
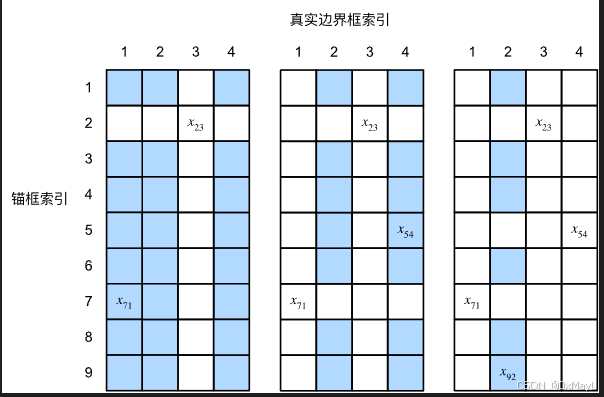
- 在矩阵X\mathbf{X}X中找到最大的元素,并将它的行索引和列索引分别表示为i1i_1i1和j1j_1j1。然后将真实边界框Bj1B_{j_1}Bj1分配给锚框Ai1A_{i_1}Ai1。这很直观,因为Ai1A_{i_1}Ai1和Bj1B_{j_1}Bj1是所有锚框和真实边界框配对中最相近的。在第一个分配完成后,丢弃矩阵中i1th{i_1}^\mathrm{th}i1th行和j1th{j_1}^\mathrm{th}j1th列中的所有元素。
- 在矩阵X\mathbf{X}X中找到剩余元素中最大的元素,并将它的行索引和列索引分别表示为i2i_2i2和j2j_2j2。我们将真实边界框Bj2B_{j_2}Bj2分配给锚框Ai2A_{i_2}Ai2,并丢弃矩阵中i2th{i_2}^\mathrm{th}i2th行和j2th{j_2}^\mathrm{th}j2th列中的所有元素。
- 此时,矩阵X\mathbf{X}X中两行和两列中的元素已被丢弃。我们继续,直到丢弃掉矩阵X\mathbf{X}X中nbn_bnb列中的所有元素。此时已经为这nbn_bnb个锚框各自分配了一个真实边界框。
- 只遍历剩下的na−nbn_a - n_bna−nb个锚框。例如,给定任何锚框AiA_iAi,在矩阵X\mathbf{X}X的第ithi^\mathrm{th}ith行中找到与AiA_iAi的IoU最大的真实边界框BjB_jBj,只有当此IoU大于预定义的阈值时,才将BjB_jBj分配给AiA_iAi。
下面用一个具体的例子来说明上述算法。
如 :numref:fig_anchor_label(左)所示,假设矩阵X\mathbf{X}X中的最大值为x23x_{23}x23,我们将真实边界框B3B_3B3分配给锚框A2A_2A2。
然后,我们丢弃矩阵第2行和第3列中的所有元素,在剩余元素(阴影区域)中找到最大的x71x_{71}x71,然后将真实边界框B1B_1B1分配给锚框A7A_7A7。
接下来,如 :numref:fig_anchor_label(中)所示,丢弃矩阵第7行和第1列中的所有元素,在剩余元素(阴影区域)中找到最大的x54x_{54}x54,然后将真实边界框B4B_4B4分配给锚框A5A_5A5。
最后,如 :numref:fig_anchor_label(右)所示,丢弃矩阵第5行和第4列中的所有元素,在剩余元素(阴影区域)中找到最大的x92x_{92}x92,然后将真实边界框B2B_2B2分配给锚框A9A_9A9。
之后,我们只需要遍历剩余的锚框A1,A3,A4,A6,A8A_1, A_3, A_4, A_6, A_8A1,A3,A4,A6,A8,然后根据阈值确定是否为它们分配真实边界框。
🏷fig_anchor_label
此算法在下面的assign_anchor_to_bbox函数中实现。
标记类别和偏移量
现在我们可以为每个锚框标记类别和偏移量了。
假设一个锚框AAA被分配了一个真实边界框BBB。
一方面,锚框AAA的类别将被标记为与BBB相同。
另一方面,锚框AAA的偏移量将根据BBB和AAA中心坐标的相对位置以及这两个框的相对大小进行标记。
鉴于数据集内不同的框的位置和大小不同,我们可以对那些相对位置和大小应用变换,使其获得分布更均匀且易于拟合的偏移量。
这里介绍一种常见的变换。
[**给定框AAA和BBB,中心坐标分别为(xa,ya)(x_a, y_a)(xa,ya)和(xb,yb)(x_b, y_b)(xb,yb),宽度分别为waw_awa和wbw_bwb,高度分别为hah_aha和hbh_bhb,可以将AAA的偏移量标记为:
(xb−xawa−μxσx,yb−yaha−μyσy,logwbwa−μwσw,loghbha−μhσh),\left( \frac{ \frac{x_b - x_a}{w_a} - \mu_x }{\sigma_x}, \frac{ \frac{y_b - y_a}{h_a} - \mu_y }{\sigma_y}, \frac{ \log \frac{w_b}{w_a} - \mu_w }{\sigma_w}, \frac{ \log \frac{h_b}{h_a} - \mu_h }{\sigma_h}\right),(σxwaxb−xa−μx,σyhayb−ya−μy,σwlogwawb−μw,σhloghahb−μh),
**]
其中常量的默认值为 μx=μy=μw=μh=0,σx=σy=0.1\mu_x = \mu_y = \mu_w = \mu_h = 0, \sigma_x=\sigma_y=0.1μx=μy=μw=μh=0,σx=σy=0.1 , σw=σh=0.2\sigma_w=\sigma_h=0.2σw=σh=0.2。里插入图片描述](https://i-blog.csdnimg.cn/direct/d0940b8fa45e4bf982f7ed9a5f981c99.png)
这种转换在下面的 offset_boxes 函数中实现。
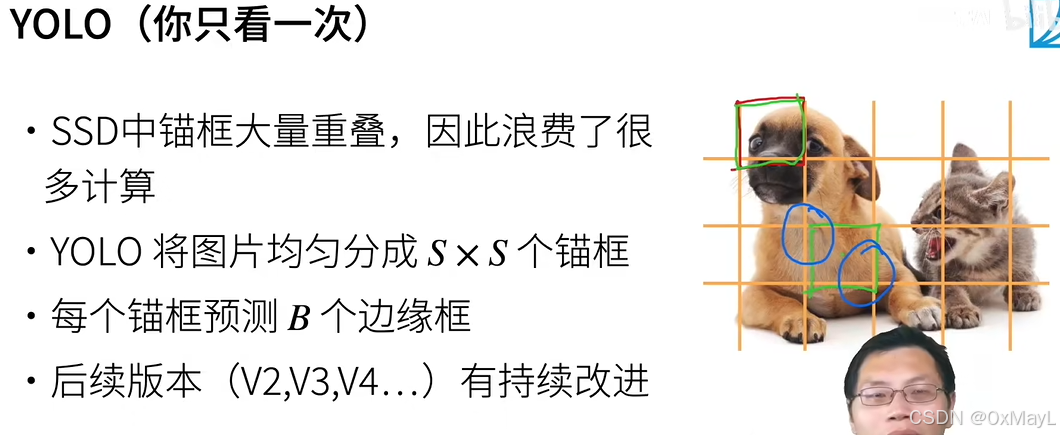
基于锚框的经典算法
语义分割
VOC数据集
- 图片在JPEGImages,标签在SegmentationClass中。
- 格式都为图片

图像增强的注意事项
在之前的实验,例如 :numref:sec_alexnet— :numref:sec_googlenet中,我们通过再缩放图像使其符合模型的输入形状。
然而在语义分割中,这样做需要将预测的像素类别重新映射回原始尺寸的输入图像。
这样的映射可能不够精确,尤其在不同语义的分割区域。
为了避免这个问题,我们将图像裁剪为固定尺寸,而不是再缩放。
具体来说,我们[使用图像增广中的随机裁剪,裁剪输入图像和标签的相同区域]。
小细节:原标签是一个3d RGB图片,要进一步转换为标签才行。
def __getitem__(self, idx):feature, label = voc_rand_crop(self.features[idx], self.labels[idx],*self.crop_size)return (feature, voc_label_indices(label, self.colormap2label))# 原标签是一张RGB图片,区分不同的背景,将其转换为可学习的标签。
将标签图片的RGB(3D)转换为标签索引(1D)
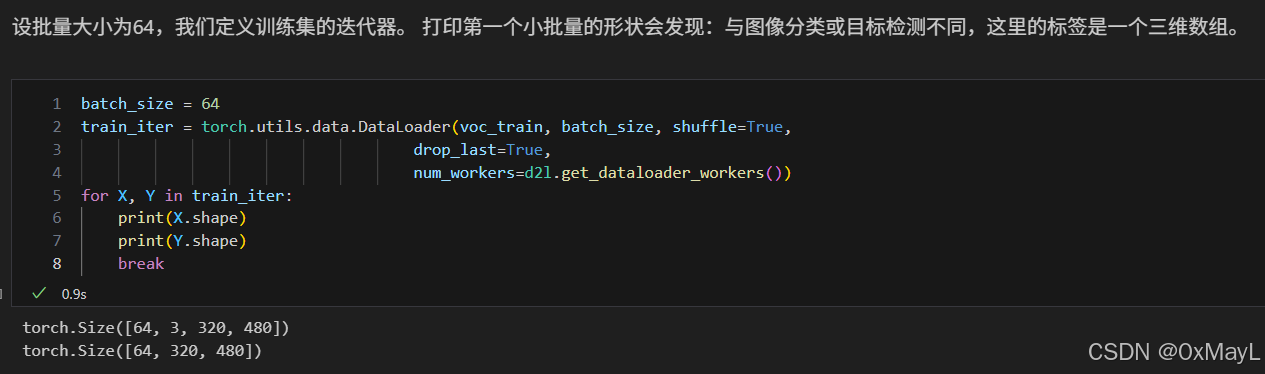
可见最后的dataloader标签是一个图片,每个像素是一个标签。
正常卷积Conv2d
输入和输出通道,
kernel_size=2padding+1,且stride=1时,大小不变。
kernel_size=2padding,且stride=1时,大小不变。
X = torch.rand(size=(1, 10, 16, 16))
conv = nn.Conv2d(10, 20, kernel_size=5, padding=2, stride=1)
X.shape,conv(X).shape
(torch.Size([1, 10, 16, 16]), torch.Size([1, 20, 16, 16]))
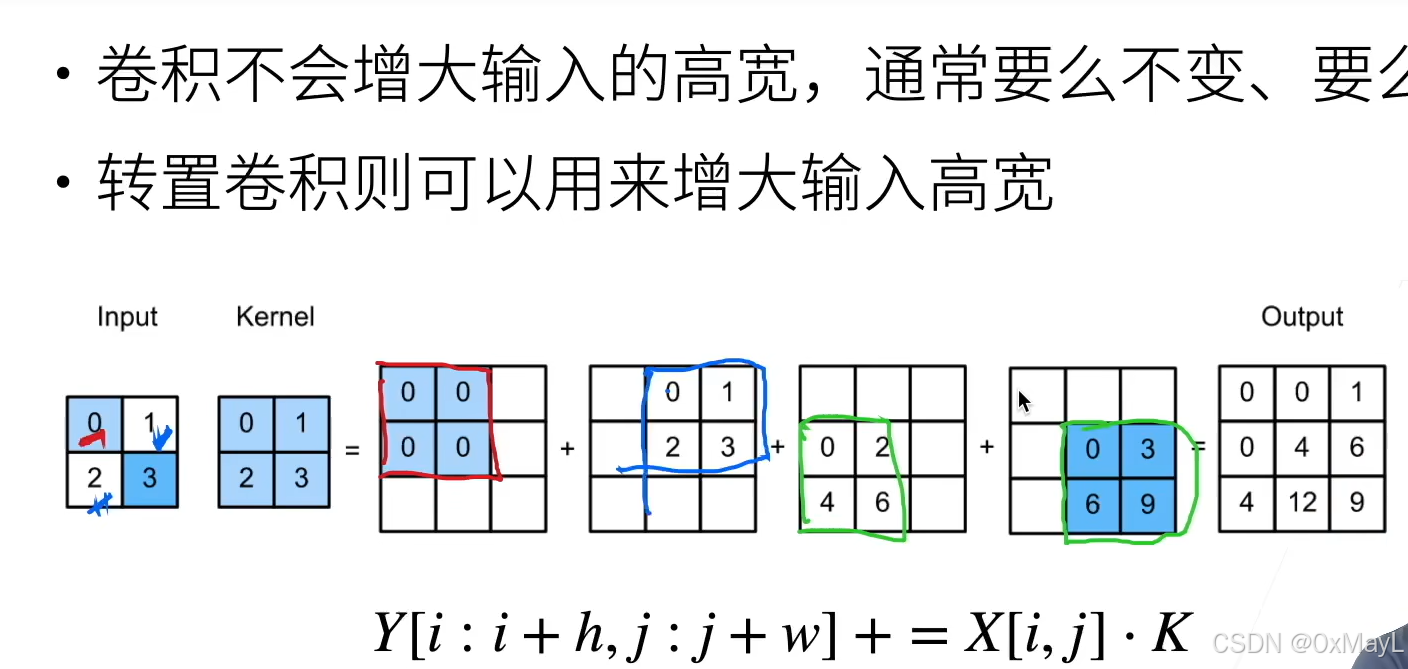
转置卷积TransConv2d
利用卷积核的感受野,逆还原卷积。

输入和输出通道,
kernel_size=2padding+1,且stride=1时,大小不变。
kernel_size=2padding,且stride=1时,大小不变。
padding相当于直接减少输出的大小,与conv相反,步长变为缩放k倍。
X = torch.rand(size=(1, 10, 16, 16))
tconv = nn.ConvTranspose2d(10, 20, kernel_size=5, padding=2, stride=1)
X.shape,tconv(X).shape
(torch.Size([1, 10, 16, 16]), torch.Size([1, 20, 16, 16]))
卷积和转置卷积是可逆的
X = torch.rand(size=(1, 10, 16, 16))
conv = nn.Conv2d(10, 20, kernel_size=5, padding=2, stride=3)
tconv = nn.ConvTranspose2d(20, 10, kernel_size=5, padding=2, stride=3)
tconv(conv(X)).shape == X.shape
FCN
CNN+1x1卷积(降低通道数)+转置卷积(重新缩放)
输出是(通道数,宽,高),其中通道数是用作类似全连接的标签,与标签数一致
pretrained_net = torchvision.models.resnet18(pretrained=True)
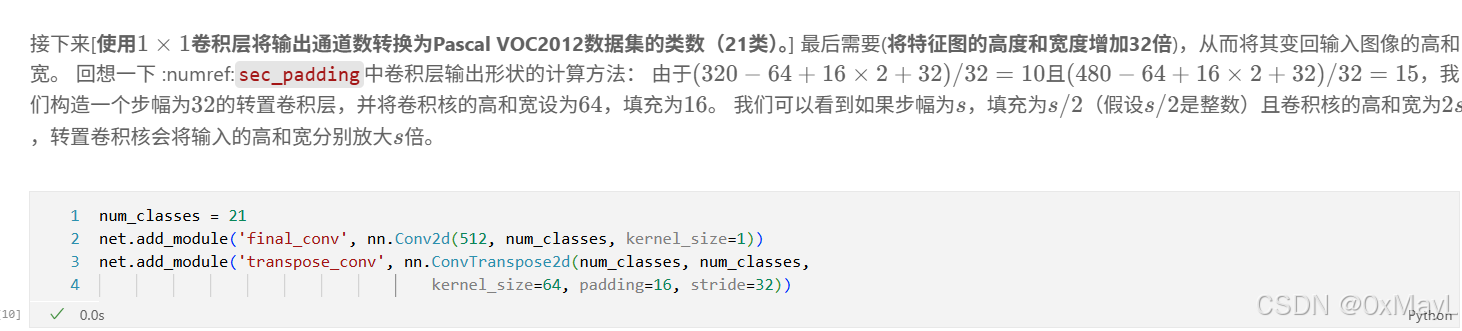
num_classes = 21
net.add_module('final_conv', nn.Conv2d(512, num_classes, kernel_size=1))
net.add_module('transpose_conv', nn.ConvTranspose2d(num_classes, num_classes,kernel_size=64, padding=16, stride=32))
RESNET输出:
torch.Size([1, 512, 10, 15])
加入转置卷积后输入和输出
torch.Size([1, 3, 320, 480])
torch.Size([1, 21, 320, 480])
参考文献
动手学深度学习主页