专业性网站 ip百度网盟推广
数据获取
深度学习训练中第一个是获取数据集,数据集的质量很重要,我们这里做的是动物分类,大致会选择几个动物,来做一个简单的多分类问题,数据获取的方法,鼠鼠我这里选择使用爬虫的方式来对数据进行爬取,目标网站为Hippopx - beautiful free stock photos
代码如下
# -*- coding: utf-8 -*-
import json
import os
import requests
from lxml import etreeimage_number = 1def get_image(folder_name, page):global image_numberheaders = {"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7","accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","priority": "u=0, i","referer": "https://www.hippopx.com/zh/search?q=%E5%B0%8F%E7%8B%97","sec-ch-ua": "\"Microsoft Edge\";v=\"129\", \"Not=A?Brand\";v=\"8\", \"Chromium\";v=\"129\"","sec-ch-ua-mobile": "?0","sec-ch-ua-platform": "\"Windows\"","sec-fetch-dest": "document","sec-fetch-mode": "navigate","sec-fetch-site": "same-origin","sec-fetch-user": "?1","upgrade-insecure-requests": "1","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0"}url = "https://www.hippopx.com/zh/search"params = {"q": folder_name,"page": page}response = requests.get(url, headers=headers, params=params)html = etree.HTML(response.text)data_list = html.xpath('//ul[@class="main_list"]/li//a/img')for data in data_list:src = data.xpath('string(./@src)')folder_path = f"dataset/{folder_name}"if not os.path.exists(folder_path):os.makedirs(folder_path)print(f"文件夹 '{folder_path}' 已创建。")response = requests.get(src)if response.status_code == 200:# 打开一个文件以二进制写入模式with open(f"{folder_path}/{image_number}.jpg", "wb") as file:file.write(response.content)print(f"{image_number}保存成功")else:print("请求失败,状态码:", response.status_code)image_number += 1if __name__ == '__main__':folder_name = str(input("请输入你要爬取的动物名称:"))for page in range(1, 3): # 爬取两页的图片数据get_image(folder_name=folder_name, page=str(page))
计算图像均值和方差
代码如下
# -*- coding: utf-8 -*-
from torchvision.datasets import ImageFolder
import torch
from torchvision import transforms as T
from tqdm import tqdmtransform = T.Compose([T.RandomResizedCrop(224), T.ToTensor(), ])def getStat(train_data):"""computer mean and variance for training data:param train_data: 自定义类Dataset:return: (mean,std)"""print('Compute mean and variance for training data.')print(len(train_data))train_loader = torch.utils.data.DataLoader(train_data, batch_size=1, shuffle=False, num_workers=0,pin_memory=True)mean = torch.zeros(3)std = torch.zeros(3)for x, _ in tqdm(train_loader):for d in range(3):mean[d] += x[:, d, :, :].mean()std[d] += x[:, d, :, :].std()mean.div_(len(train_data))std.div_(len(train_data))return list(mean.numpy()), list(std.numpy())if __name__ == '__main__':train_dataset = ImageFolder(root=r'./dataset', transform=transform)mean, std = getStat(train_dataset)print(f"mean={mean},std={std}") # mean=[0.5045225, 0.4722667, 0.39059258],std=[0.20998387, 0.20583159, 0.20718254]

代码详解
from torchvision.datasets import ImageFolder
可以自动加载一个文件夹中的图像文件。它假设文件夹的结构是按照类别组织的,即每个子文件夹代表一个类别,子文件夹中的图像文件属于该类别。
是一个简单而强大的工具,适用于加载和处理图像数据集。它能够自动加载图像文件、标注类别,并支持数据增强和与 PyTorch 数据加载器的集成,极大地简化了图像数据集的准备工作。
transform = T.Compose([T.RandomResizedCrop(224), T.ToTensor(), ])
使用了 torchvision.transforms 模块(通常简称为 T)的 Compose 方法来组合多个图像变换操作
T.RandomResizedCrop(224)
随机裁剪图像,并将其大小调整为 224×224 像素。
T.ToTensor()
将图像从 PIL 图像格式或 NumPy 数组格式转换为 PyTorch 的 Tensor 格式。
具体实现:
-
将像素值从 [0, 255] 范围归一化到 [0.0, 1.0] 范围。
-
将图像的通道顺序从 H×W×C(高度×宽度×通道)转换为 C×H×W(通道×高度×宽度),以符合 PyTorch 的张量格式要求。
train_dataset = ImageFolder(root=r'./dataset', transform=transform)
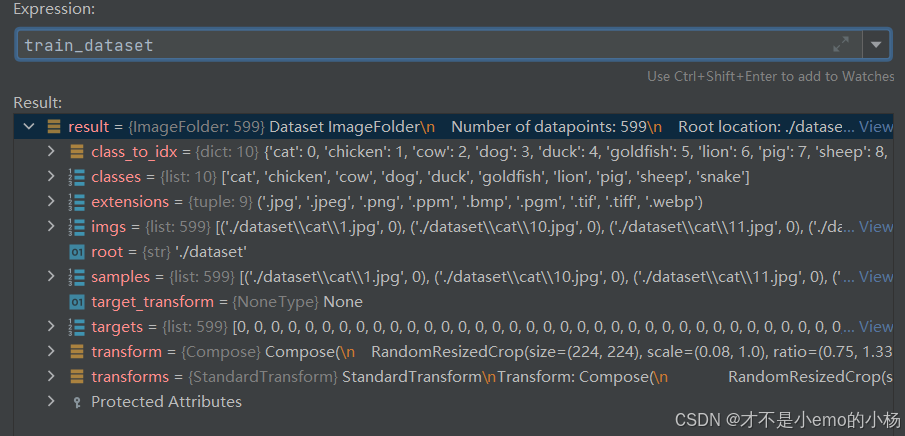
train_loader = torch.utils.data.DataLoader(
train_data, batch_size=1, shuffle=False, num_workers=0,
pin_memory=True)
pin_memory=True
pin_memory=True 的作用是将数据加载到 Pinned Memory(固定内存) 中。在使用 GPU 进行训练时,pin_memory=True 可以显著提高数据传输的效率,减少数据加载的延迟,从而提高整体的训练速度。
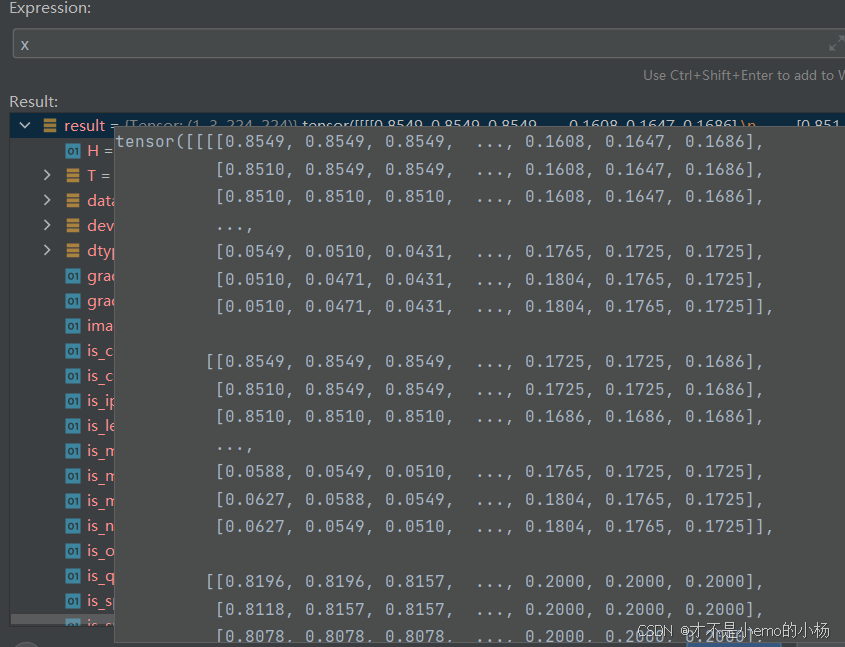
for x, _ in tqdm(train_loader)
x的结果
_的值为,标签值转化为tensor格式
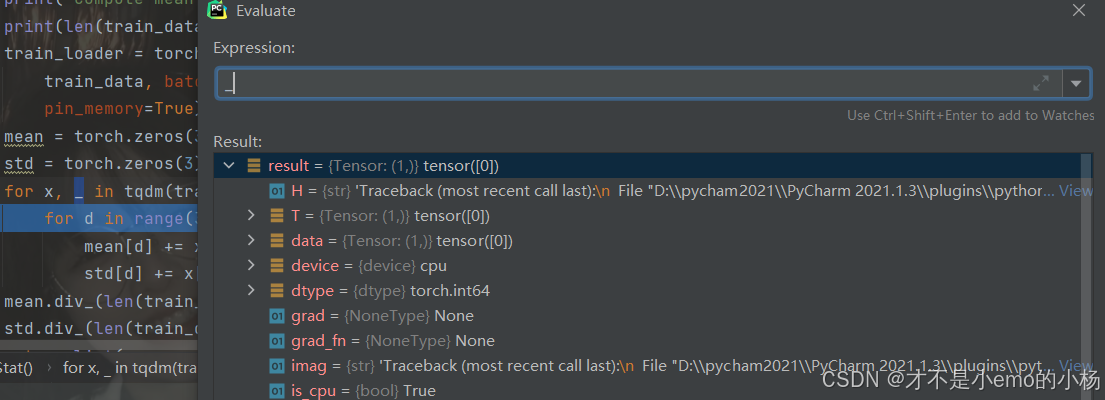
mean.div_(len(train_data))
这段代码的作用是对一个张量(mean)进行原地除法操作,将其每个元素除以 train_data 的长度(即数据集的大小)。这里的 div_ 是 PyTorch 中的原地操作(in-place operation),表示直接在原张量上修改值,而不是创建一个新的张量。
CreateDataset
# -*- coding: utf-8 -*-
"""
生成训练集和测试集,保存到txt文件中
"""
import os
import randomdef CreateTrainingSet(rootdata, train_ratio):train_list, test_list = [], [] # 读取里面每一类的类别data_list = []# 生产train.txt和test.txtclass_flag = -1for a, b, c in os.walk(rootdata):print(a)for i in range(len(c)):data_list.append(os.path.join(a, c[i]))for i in range(0, int(len(c) * train_ratio)):train_data = os.path.join(a, c[i]) + '\t' + str(class_flag) + '\n'train_list.append(train_data)for i in range(int(len(c) * train_ratio), len(c)):test_data = os.path.join(a, c[i]) + '\t' + str(class_flag) + '\n'test_list.append(test_data)class_flag += 1print(train_list)random.shuffle(train_list) # 打乱次序random.shuffle(test_list)with open('train.txt', 'w', encoding='UTF-8') as f:for train_img in train_list:f.write(train_img)with open('text.txt', 'w', encoding='UTF-8') as f:for test_img in test_list:f.write(test_img)if __name__ == '__main__':rootdata = r"./dataset"train_ratio = 0.8CreateTrainingSet(rootdata, train_ratio)

代码详解
os.walk
os.walk 会返回一个生成器,每次迭代返回一个三元组 (a, b, c):
-
a:表示当前正在遍历的目录路径(字符串)。 -
b:表示当前目录下的子目录列表(列表,包含子目录的名称)。 -
c:表示当前目录下的文件列表(列表,包含文件的名称)。
其他没有什么好讲的了
MYDataset
# -*- coding: utf-8 -*-
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import cv2 as cvclass MyDataset(Dataset):def __init__(self, txt_path, img_size=224, train_flag=True):self.imgs_info = self.get_images(txt_path)self.train_flag = train_flag# 图片标准化transform_BZ = transforms.Normalize(mean=[0.5045225, 0.4722667, 0.39059258],std=[0.20998387, 0.20583159, 0.20718254])self.train_tf = transforms.Compose([transforms.ToPILImage(), # 将numpy数组转换位PIL图像transforms.Resize((img_size, img_size)), # 将图片压缩成224*224的大小transforms.RandomHorizontalFlip(), # 对图片进行随机的水平翻转transforms.RandomVerticalFlip(), # 随机的垂直翻转transforms.ToTensor(), # 把图片改成Tensor格式transform_BZ # 图片表转化的步骤])self.val_tf = transforms.Compose([ ##简单把图片压缩了变成Tensor模式transforms.ToPILImage(), # 将 numpy数组转换为PIL图像transforms.Resize((img_size, img_size)),transforms.ToTensor(),transform_BZ # 标准化操作])def get_images(self, txt_path):with open(txt_path, 'r', encoding='utf-8') as f:imgs_info = f.readlines()imgs_info = list(map(lambda x: x.strip().split('\t'), imgs_info))return imgs_info # 返回图片信息def __getitem__(self, index): # 返回真正想返回的东西img_path, label = self.imgs_info[index]img = cv.imread(img_path)img = cv.cvtColor(img, cv.COLOR_BGR2RGB) # 将图片从BGR转换为RGB格式if self.train_flag:img = self.train_tf(img)else:img = self.val_tf(img)label = int(label)return img, labeldef __len__(self):return len(self.imgs_info)if __name__ == '__main__':my_dataset_train = MyDataset("train.txt", train_flag=True)my_dataloader_train = DataLoader(my_dataset_train, batch_size=10, shuffle=True)# 尝试拂去训练集数据print("读取训练集数据")for x, y in my_dataloader_train:print(x.type(), x.shape, y)my_dataset_test = MyDataset("test.txt", train_flag=False)my_dataloader_test = DataLoader(my_dataset_test, batch_size=10, shuffle=False)# 尝试读取训练集数据print("读取测试集数据")for x, y in my_dataloader_test:print(x.shape, y)
list(map(lambda x:x.strip().split('\t'), imgs_info))
-
map是 Python 的内置函数,用于对一个可迭代对象(如列表)中的每个元素应用一个函数,并返回一个新的可迭代对象。
结果为
transform_BZ = transforms.Normalize(
mean=[0.5045225, 0.4722667, 0.39059258],
std=[0.20998387, 0.20583159, 0.20718254]
)
这段代码的作用是定义一个归一化操作,将输入图像的每个通道的像素值减去指定的均值并除以指定的标准差。这种归一化处理有助于提高模型的训练效率和泛化能力。
其他的就没什么好讲的了
MyModel
from torchsummary import summary
import torch.nn as nn
import torch.nn.functional as F# 定义模型
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28 * 28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10))def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logitsclass SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)self.fc1 = nn.Linear(128 * 28 * 28, 512)self.fc2 = nn.Linear(512, 128)self.fc3 = nn.Linear(128, 10)def forward(self, x):# Convolutional layers with ReLU and MaxPoolx = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = self.pool(F.relu(self.conv3(x)))# Flatten the output for the fully connected layersx = x.view(-1, 128 * 28 * 28)# Fully connected layers with ReLUx = F.relu(self.fc1(x))x = F.relu(self.fc2(x))# Output layerx = self.fc3(x)return xif __name__ == '__main__':# Create an instance of the networkmodel = SimpleCNN().cuda()print(model)summary(model, (3, 224, 224))
main函数
# -*- coding: utf-8 -*-
import torch
from torch import nn
from torch.utils.data import DataLoader
from tqdm import tqdm # pip install tqdm
import matplotlib.pyplot as plt
import os
from torchsummary import summaryfrom torch.utils.tensorboard import SummaryWriterimport wandb
import datetimefrom MyModel import SimpleCNN
from MYDataset import MyDataset# # 定义训练函数
def train(dataloader, model, loss_fn, optimizer):# 初始化训练数据集的大小和批次数量size = len(dataloader.dataset)num_batches = len(dataloader)# 设置模型为训练模式model.train()# 初始化总损失和正确预测数量loss_total = 0correct = 0# 遍历数据加载器中的所有数据批次for X, y in tqdm(dataloader):# 将数据和标签移动到指定设备(例如GPU)X, y = X.to(device), y.to(device)# 使用模型进行预测pred = model(X)# 计算正确预测的数量correct += (pred.argmax(1) == y).type(torch.float).sum().item()# 计算预测结果和真实结果之间的损失loss = loss_fn(pred, y)# 累加总损失loss_total += loss.item()# 执行反向传播,计算梯度loss.backward()# 更新模型参数optimizer.step()# 清除梯度信息optimizer.zero_grad()# 计算平均损失和准确率loss_avg = loss_total / num_batchescorrect /= size# 返回准确率和平均损失,保留三位小数return round(correct, 3), round(loss_avg, 3)# 定义测试函数
def test(dataloader, model, loss_fn):# 初始化测试数据集的大小和批次数量size = len(dataloader.dataset)num_batches = len(dataloader)# 设置模型为评估模式model.eval()# 初始化测试损失和正确预测数量test_loss, correct = 0, 0# 不计算梯度,以提高计算效率并减少内存使用with torch.no_grad():# 遍历数据加载器中的所有数据批次for X, y in tqdm(dataloader):# 将数据和标签移动到指定设备(例如GPU)X, y = X.to(device), y.to(device)# 使用模型进行预测pred = model(X)# 累加预测损失test_loss += loss_fn(pred, y).item()# 累加正确预测的数量correct += (pred.argmax(1) == y).type(torch.float).sum().item()# 计算平均测试损失和准确率test_loss /= num_batchescorrect /= size# 返回准确率和平均测试损失,保留三位小数return round(correct, 3), round(test_loss, 3)def writedata(txt_log_name, tensorboard_writer, epoch, train_accuracy, train_loss, test_accuracy, test_loss):# 保存到文档with open(txt_log_name, "a+") as f:f.write(f"Epoch:{epoch}\ttrain_accuracy:{train_accuracy}\ttrain_loss:{train_loss}\ttest_accuracy:{test_accuracy}\ttest_loss:{test_loss}\n")# 保存到tensorboard# 记录全连接层参数for name, param in model.named_parameters():tensorboard_writer.add_histogram(name, param.clone().cpu().data.numpy(), global_step=epoch)tensorboard_writer.add_scalar('Accuracy/train', train_accuracy, epoch)tensorboard_writer.add_scalar('Loss/train', train_loss, epoch)tensorboard_writer.add_scalar('Accuracy/test', test_accuracy, epoch)tensorboard_writer.add_scalar('Loss/test', test_loss, epoch)wandb.log({"Accuracy/train": train_accuracy,"Loss/train": train_loss,"Accuracy/test": test_accuracy,"Loss/test": test_loss})def plot_txt(log_txt_loc):with open(log_txt_loc, 'r') as f:log_data = f.read()# 解析日志数据epochs = []train_accuracies = []train_losses = []test_accuracies = []test_losses = []for line in log_data.strip().split('\n'):epoch, train_acc, train_loss, test_acc, test_loss = line.split('\t')epochs.append(int(epoch.split(':')[1]))train_accuracies.append(float(train_acc.split(':')[1]))train_losses.append(float(train_loss.split(':')[1]))test_accuracies.append(float(test_acc.split(':')[1]))test_losses.append(float(test_loss.split(':')[1]))# 创建折线图plt.figure(figsize=(10, 5))# 训练数据plt.subplot(1, 2, 1)plt.plot(epochs, train_accuracies, label='Train Accuracy')plt.plot(epochs, test_accuracies, label='Test Accuracy')plt.title('Training Metrics')plt.xlabel('Epoch')plt.ylabel('Value')plt.legend()# 设置横坐标刻度为整数plt.xticks(range(min(epochs), max(epochs) + 1))# 测试数据plt.subplot(1, 2, 2)plt.plot(epochs, train_losses, label='Train Loss')plt.plot(epochs, test_losses, label='Test Loss')plt.title('Testing Metrics')plt.xlabel('Epoch')plt.ylabel('Value')plt.legend()# 设置横坐标刻度为整数plt.xticks(range(min(epochs), max(epochs) + 1))plt.tight_layout()plt.show()if __name__ == '__main__':batch_size = 64init_lr = 1e-3epochs = 5log_root = "logs"log_txt_loc = os.path.join(log_root, "log.txt")# 指定TensorBoard数据的保存地址tensorboard_writer = SummaryWriter(log_root)# WandB信息保存地址run_time = datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")wandb.init(dir=log_root,project='Flower Classify',name=f"run-{run_time}",config={"learning_rate": init_lr,"batch_size": batch_size,"model": "SimpleCNN","dataset": "Flower10","epochs": epochs,})if os.path.isdir(log_root):passelse:os.mkdir(log_root)train_data = MyDataset("train.txt", train_flag=True)test_data = MyDataset("test.txt", train_flag=False)# 创建数据加载器train_dataloader = DataLoader(train_data, batch_size=batch_size)test_dataloader = DataLoader(test_data, batch_size=batch_size)for X, y in test_dataloader:print(f"Shape of X [N, C, H, W]: {X.shape}")print(f"Shape of y: {y.shape} {y.dtype}")break# 指定设备device = "cuda" if torch.cuda.is_available() else "cpu"print(f"Using {device} device")model = SimpleCNN().to(device)print(model)summary(model, (3, 224, 224))# 模拟输入,大小和输入相同即可init_img = torch.zeros((1, 3, 224, 224), device=device)tensorboard_writer.add_graph(model, init_img)# 添加wandb的模型记录wandb.watch(model, log='all', log_graph=True)# 定义损失函数loss_fn = nn.CrossEntropyLoss()# 定义优化器optimizer = torch.optim.SGD(model.parameters(), lr=init_lr)best_acc = 0# 定义循环次数,每次循环里面,先训练,再测试for t in range(epochs):print(f"Epoch {t + 1}\n-------------------------------")train_acc, train_loss = train(train_dataloader, model, loss_fn, optimizer)test_acc, test_loss = test(test_dataloader, model, loss_fn)writedata(log_txt_loc, tensorboard_writer, t, train_acc, train_loss, test_acc, test_loss)# 保存最佳模型if test_acc > best_acc:best_acc = test_acctorch.save(model.state_dict(), os.path.join(log_root, "best.pth"))torch.save(model.state_dict(), os.path.join(log_root, "last.pth"))print("Done!")plot_txt(log_txt_loc)tensorboard_writer.close()wandb.finish()
导出数据集的全部预测结果
'''1.单幅图片验证2.多幅图片验证
'''
import torch
from torch.utils.data import DataLoader
from MYDataset import MyDataset
from MyModel import SimpleCNN
import pandas as pd
from tqdm import tqdm
import osdef eval(dataloader, model):pred_list = []model.eval()with torch.no_grad():# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)for X, y in tqdm(dataloader, desc="Model is predicting, please wait"):# 将数据转到GPUX = X.to(device)# 将图片传入到模型当中就,得到预测的值predpred = model(X)pred_softmax = torch.softmax(pred,1).cpu().numpy()pred_list.append(pred_softmax.tolist()[0])return pred_listif __name__ == "__main__":'''加载预训练模型'''# 1. 导入模型结构device = "cuda" if torch.cuda.is_available() else "cpu"# 2. 加载模型参数model = SimpleCNN()model_state_loc = r"logs/best.pth"torch_data = torch.load(model_state_loc, map_location=torch.device(device))model.load_state_dict(torch_data)model = model.to(device)'''加载需要预测的图片'''valid_data = MyDataset("test.txt", train_flag=False)test_dataloader = DataLoader(dataset=valid_data, num_workers=4,pin_memory=True, batch_size=1)'''获取结果'''# 获取模型输出pred = eval(test_dataloader, model)dir_names = []for root,dirs,files in os.walk("dataset"):if dirs:dir_names = dirs# 将输出保存到exel中,方便后续分析label_names = dir_names # 可以把标签写在这里print(label_names)df_pred = pd.DataFrame(data=pred, columns=label_names)df_pred.to_csv('pred_result.csv', encoding='gbk', index=False)print("Done!")图像分类评价指标
- 混淆矩阵
- 准确率
- 查准率
- 查全率
- F1-分数
混淆矩阵
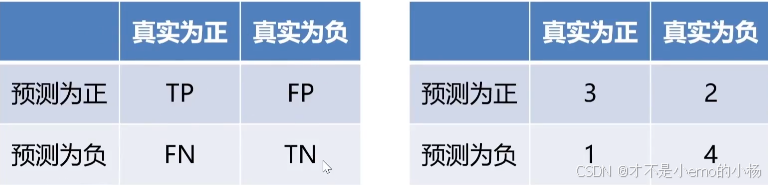
True:正确的 False:错误的 Positive :正例 Negative:反例
准确率
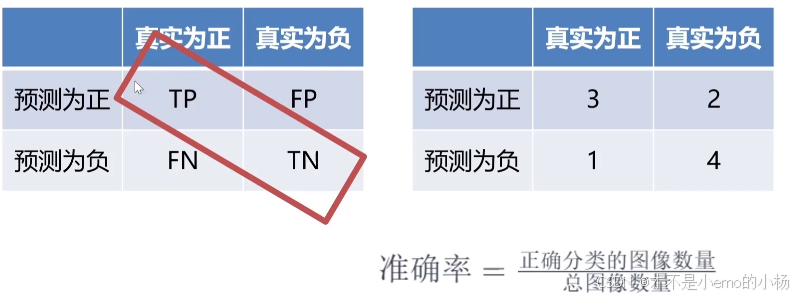
查准率
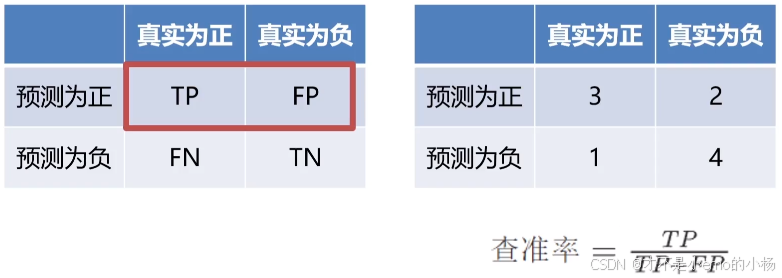
查全率
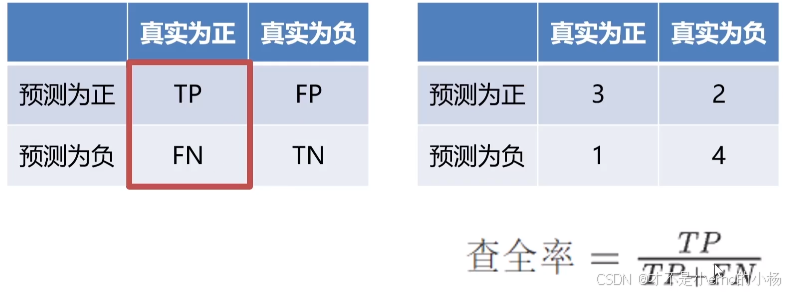
F1-分数
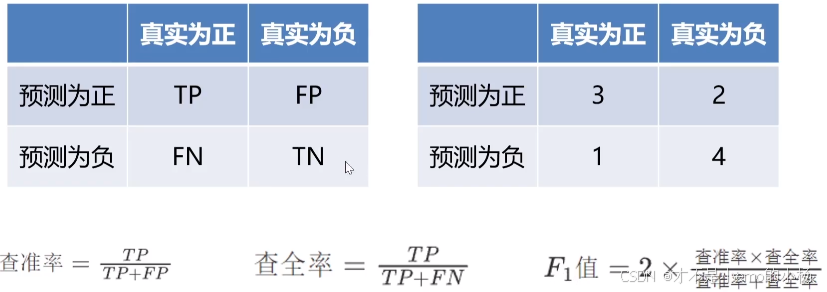
对比实验结果
'''模型性能度量
'''
from sklearn.metrics import * # pip install scikit-learn
import matplotlib.pyplot as plt # pip install matplotlib
import pandas as pd # pip install pandas
import matplotlib
'''
读取数据需要读取模型输出的标签(predict_label)以及原本的标签(true_label)'''matplotlib.rcParams['font.sans-serif']=['SimHei'] # 用黑体显示中文
matplotlib.rcParams['axes.unicode_minus']=False # 正常显示负号target_loc = "test.txt" # 真实标签所在的文件
target_data = pd.read_csv(target_loc, sep="\t", names=["loc","type"])
true_label = [i for i in target_data["type"]]# print(true_label)predict_loc = "pred_result.csv" # 3.ModelEvaluate.py生成的文件
predict_data = pd.read_csv(predict_loc, encoding='gbk')#,index_col=0)
predict_label = predict_data.to_numpy().argmax(axis=1)
# predict_score = predict_data.to_numpy().max(axis=1)'''常用指标:精度,查准率,召回率,F1-Score
'''
report = classification_report(true_label, predict_label)
print("分类报告:\n",report)# 精度,准确率, 预测正确的占所有样本种的比例
accuracy = accuracy_score(true_label, predict_label)
print("精度: ",accuracy)# 查准率P(准确率),precision(查准率)=TP/(TP+FP)
precision = precision_score(true_label, predict_label, labels=None, pos_label=1, average='macro') # 'micro', 'macro', 'weighted'
print("查准率P: ",precision)# 查全率R(召回率),原本为对的,预测正确的比例;recall(查全率)=TP/(TP+FN)
recall = recall_score(true_label, predict_label, average='macro') # 'micro', 'macro', 'weighted'
print("召回率: ",recall)# F1-Score
f1 = f1_score(true_label, predict_label, average='macro') # 'micro', 'macro', 'weighted'
print("F1 Score: ",f1)'''
混淆矩阵
'''
# label_names = ["猫", "鸡", "牛", "狗", "鸭子","金鱼","狮子","猪","绵羊","蛇"]
import os
dir_names = []
for root,dirs,files in os.walk("dataset"):if dirs:dir_names = dirs
# 将输出保存到exel中,方便后续分析
label_names = dir_names # 可以把标签写在这里confusion = confusion_matrix(true_label, predict_label, labels=[i for i in range(len(label_names))])plt.matshow(confusion, cmap=plt.cm.Oranges) # Greens, Blues, Oranges, Reds
plt.colorbar()
for i in range(len(confusion)):for j in range(len(confusion)):plt.annotate(confusion[j,i], xy=(i, j), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.xticks(range(len(label_names)), label_names)
plt.yticks(range(len(label_names)), label_names)
plt.title("Confusion Matrix")
plt.show()