个人做网站流程图站长工具seo综合查询5g
背景
为了系统实时更新数据库信息,让大模型可以看到最新的数据信息,并基于最新的数据库进行用户回答
插件制作
插件的输入包括:上传文件的excel表格地址;指定数据库的库名,指定数据库的表头名称,值得注意的是得保持一致【数据库的表头和excel表头保持一致】
我设计的工作流中
放入之前的插件
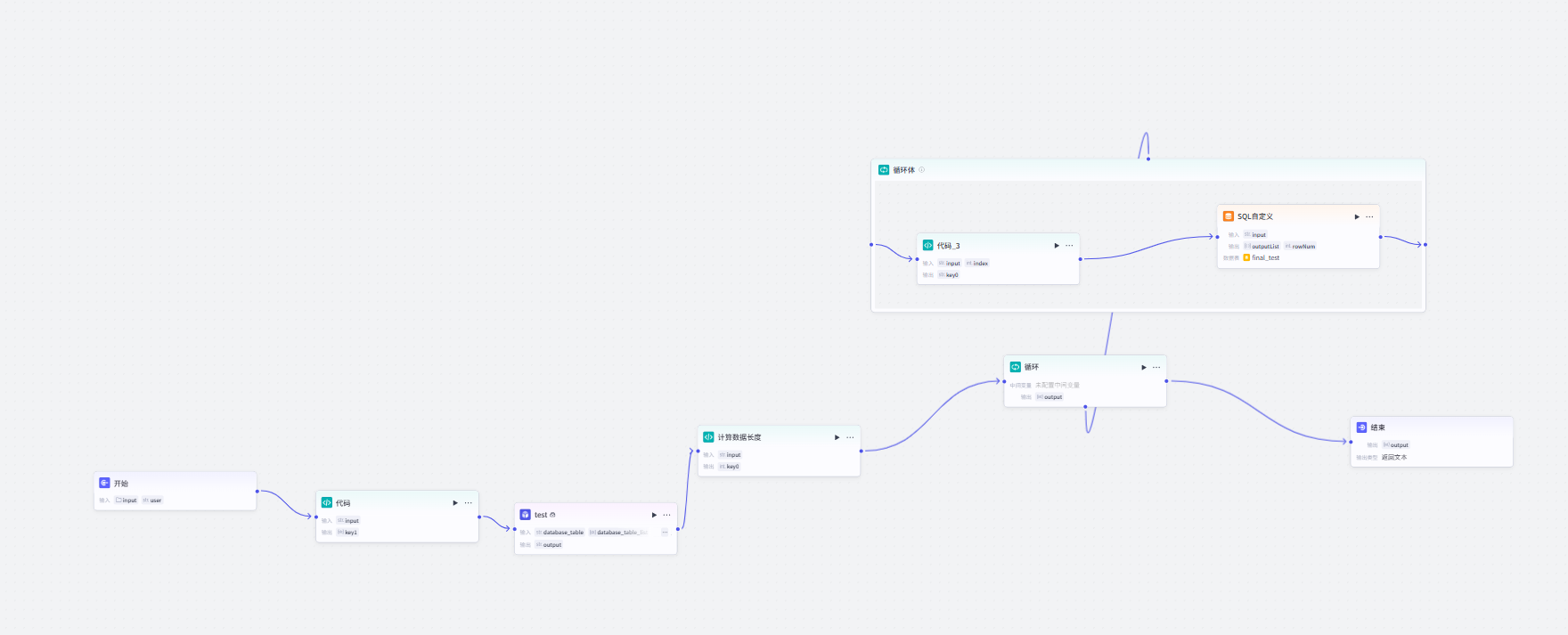
首先,直接通过SQL自定义批量上传会出现超出工作流处理长度的限制,因此,我想了一种办法,那就是遍历循环一条一条上传,结果,我发现也行不通,因为客服说整个工作流处理次数单轮不能超过1000次,不然会中断。
因此,我最终的解决方案就是每20个20个上传,这样既可以解决1000次的桎梏,也能解决SQL自定义节点处理次数的限制
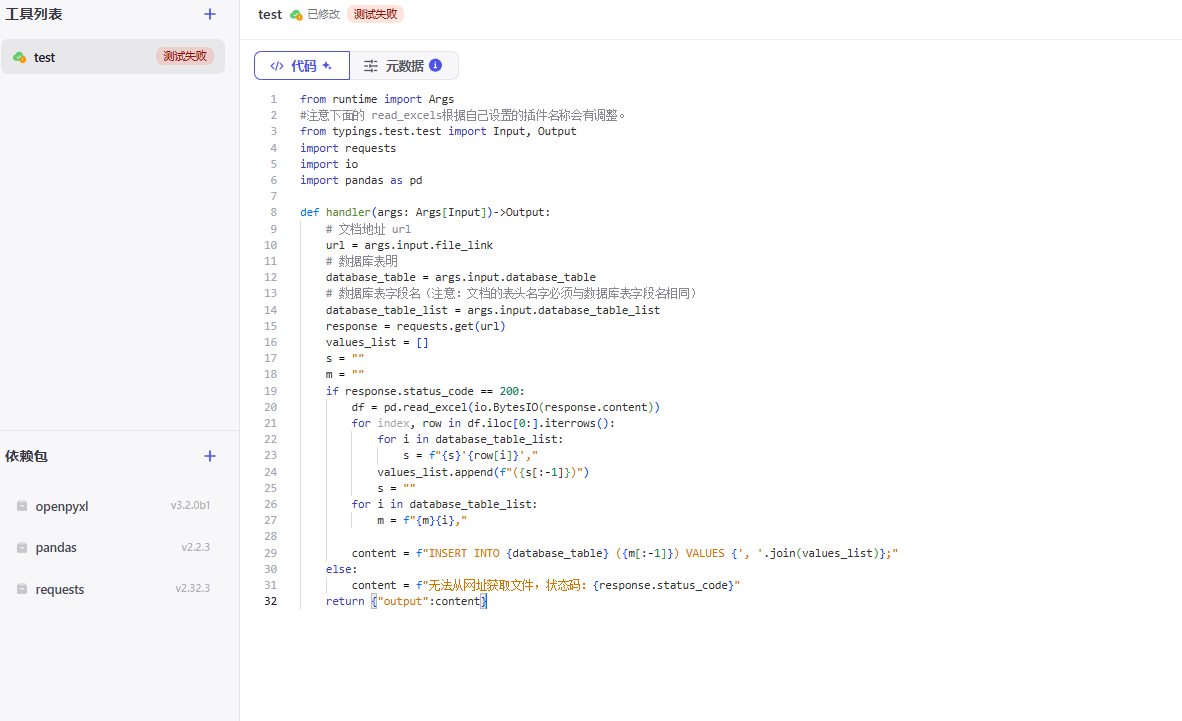
工作流中的代码块内容
代码
async def main(args: Args) -> Output:params = args.paramsarray = params["input"].split(",")ret: Output = arrayreturn ret
代码_3
async def main(args: Args) -> Output:params = args.params# 构建输出对象obj_list = params['input'].split('), (')if params["index"] == 0:sql_sentence = obj_list[0] + "),"else:sql_sentence = "INSERT INTO final_test (******) VALUES "for i, temp in enumerate(obj_list[20*params["index"]:20*(params["index"] + 1)]):if params["index"] == 0:if i != 0:s = "(" + temp + "),"sql_sentence += selse:s = "(" + temp + "),"sql_sentence += sret: Output = sql_sentence[:-1] + ";"return ret
至此,在线的批量上传数据到指定数据库就全部完成了
效果展示
但是当我们发布模型后,通过API接口调用我们的智能体,发现智能体没有办法搜索到我们的数据库内容。这是因为,各个数据库中的数据是独立的,即api调用智能体,访问的是api的数据库,平台在线智能体访问的是平台数据库。我也不知道为什么字节要搞的这么复杂,真要命,因此,我们必须通过api调工作流重新上传数据,那么问题来了,如何通过api接口调用工作流,以及多模态数据上传【我这里既包含文件还包含用户的话】
API接口访问工作流
import requests
import json
from upload_file import main
# API URL
url = 'https://api.coze.cn/v1/workflow/run'
file_id = main(ACCESS_TOKEN="Bearer ***********************", file_path='*******final.xlsx')
print(type(file_id))
# Headers
headers = {'Authorization': 'Bearer ************************', 'Content-Type': 'multipart/form-data'
}parameters = {"input": "{\"file_id\":\"7504552124957851687\"}","user": "********************"
}
# 请求数据
data = {"workflow_id": "*********", # 替换为实际的workflow_id"parameters": parameters
}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.status_code)
print(response.json())文件上传
首先大模型无法访问本地的图片路径,那么我们需要将它上传到coze上得到一个file_id,这个很重要,然后执行上一节的代码:
from datetime import datetime
import os
import requests
class CozeFileAPI:def __init__(self, access_token):self.base_url = "https://api.coze.cn/v1"self.access_token = access_tokenself.headers = {"Authorization": f"{access_token}"}def upload_file(self, file_path):"""上传文件到Coze"""if not os.path.exists(file_path):raise FileNotFoundError(f"文件不存在: {file_path}")# 检查文件大小file_size = os.path.getsize(file_path)if file_size > 512 * 1024 * 1024: # 512MBraise ValueError("文件大小超过512MB限制")url = f"{self.base_url}/files/upload"# 准备文件files = {'file': (os.path.basename(file_path), open(file_path, 'rb'))}try:response = requests.post(url,headers=self.headers,files=files)# 确保文件被正确关闭files['file'][1].close()# 检查响应response.raise_for_status()result = response.json()if result.get('code') == 0:print("文件上传成功!")return result['data']else:raise Exception(f"上传失败: {result.get('msg', '未知错误')}")except requests.exceptions.RequestException as e:raise Exception(f"请求错误: {str(e)}")def retrieve_file(self, file_id):"""获取文件详情"""url = f"{self.base_url}/files/retrieve"headers = {**self.headers,"Content-Type": "application/json"}params = {"file_id": file_id}try:response = requests.get(url,headers=headers,params=params)response.raise_for_status()result = response.json()if result.get('code') == 0:print("获取文件信息成功!")return result['data']else:raise Exception(f"获取文件信息失败: {result.get('msg', '未知错误')}")except requests.exceptions.RequestException as e:raise Exception(f"请求错误: {str(e)}")@staticmethoddef format_file_info(file_info):"""格式化文件信息显示"""created_time = datetime.fromtimestamp(file_info['created_at']).strftime('%Y-%m-%d %H:%M:%S')size_mb = file_info['bytes'] / (1024 * 1024)return f"""文件信息:- ID: {file_info['id']}- 文件名: {file_info['file_name']}- 大小: {size_mb:.2f} MB- 上传时间: {created_time}"""def main(ACCESS_TOKEN, file_path):# 创建API实例api = CozeFileAPI(ACCESS_TOKEN)try:# 上传文件测试print(f"\n开始上传文件: {file_path}")upload_result = api.upload_file(file_path)print(api.format_file_info(upload_result))# 获取文件信息测试file_id = upload_result['id']print(f"\n获取文件信息: {file_id}")file_info = api.retrieve_file(file_id)print(api.format_file_info(file_info))return file_idexcept Exception as e:print(f"错误: {str(e)}")
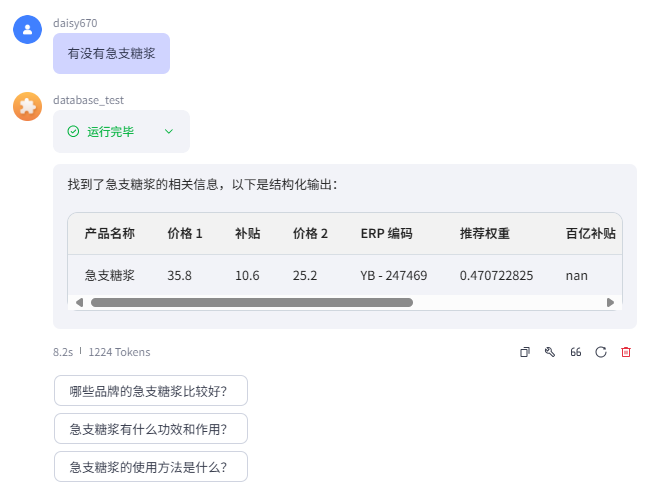
很好,到这里你就发现自己上传的文档不再是测试数据,而是线上数据,结果如下,自动写入数据库成功!
API结果展示