网站建设四段合一百度seo排名在线点击器
前言
随着大语言模型技术的快速发展,越来越多的企业和组织开始考虑在本地私有化部署模型,以满足数据安全、合规性和低延迟等需求。在众多的大模型推理引擎中,vLLM 凭借其卓越的性能和高效的资源利用率,已成为目前最热门的 LLM 推理引擎之一。
虽然 vLLM 本身性能卓越,但要构建一个真正面向生产环境的 vLLM 推理服务仍存在一定挑战。例如,大模型推理服务通常需要应对流量分发、故障转移等高可用性需求,同时在部署层面也面临资源调度、模型加载和服务编排等方面的复杂性。
llmaz 和 Higress 介绍
为应对上述挑战,本文将展示如何通过 llmaz 快速部署 vLLM 实例,并借助 Higress 实现流量控制与可观测性,从而构建一个稳定、高可用的大模型服务平台。
llmaz 是一个基于 Kubernetes 构建的大语言模型推理平台,旨在为多模型、多推理后端的服务场景提供统一且高效的部署解决方案。llmaz 原生支持 vLLM、SGLang、Text-Generation-Inference、llama.cpp、TensorRT-LLM 等多种主流推理引擎,并通过智能调度机制灵活适配异构 GPU,最大化资源利用率与推理性能。llmaz 支持从 HuggingFace、ModelScope 以及对象存储自动加载模型,显著简化模型管理流程,降低部署与使用门槛。
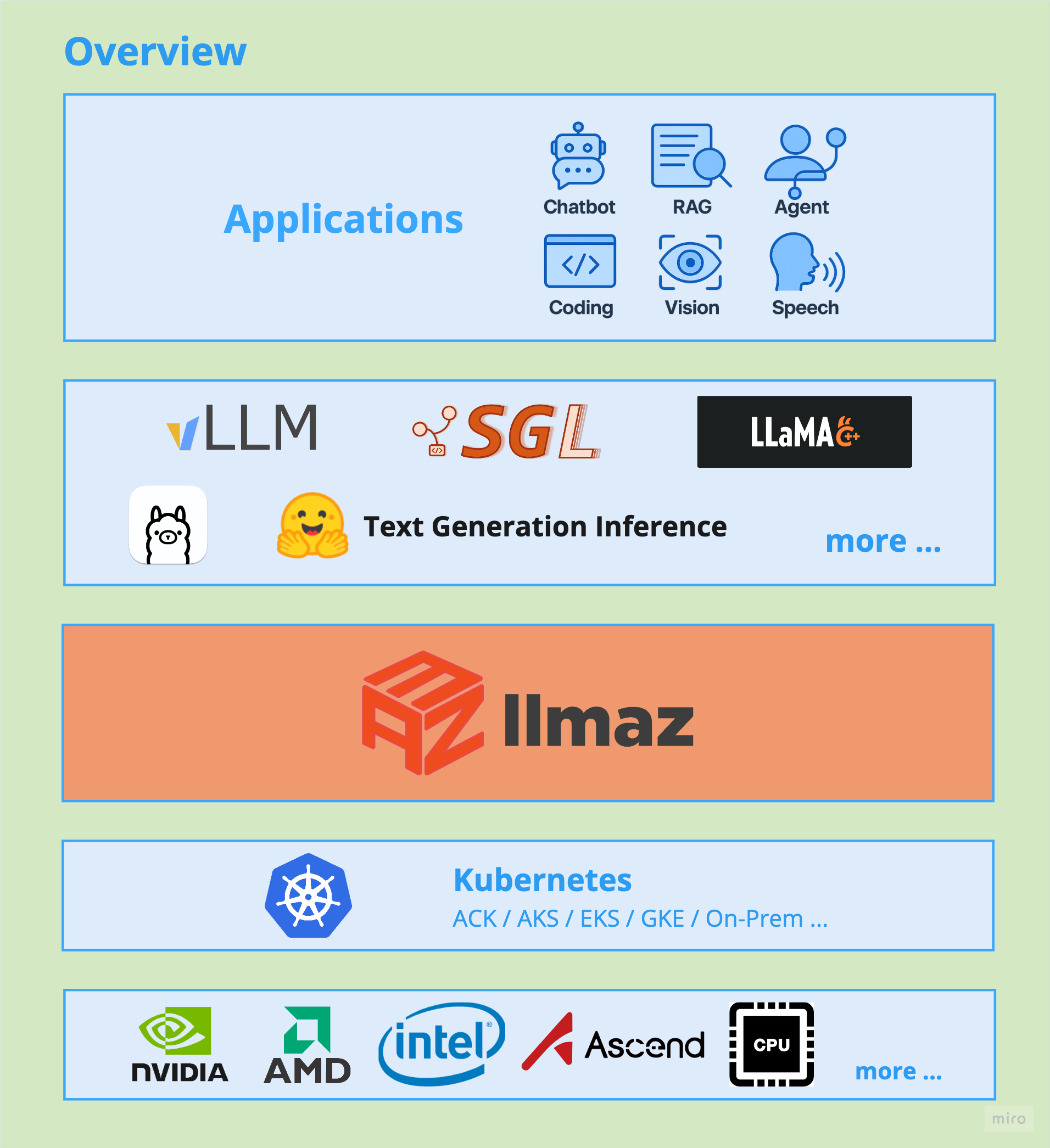
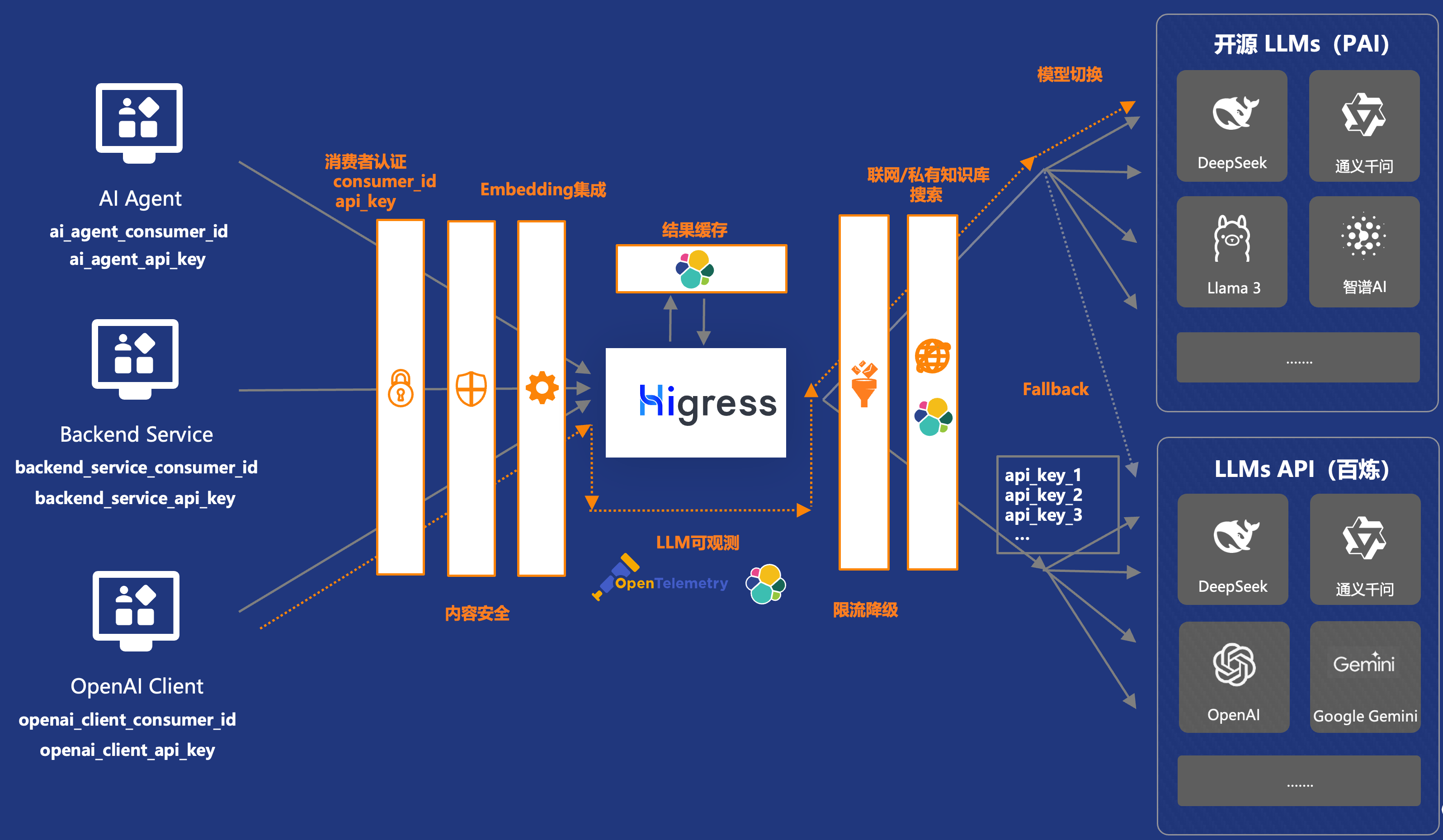
Higress 作为一款云原生 API 网关,可以完美地扮演大模型服务前置的 AI 网关角色。我们可以利用 Higress 的丰富功能实现模型服务的可观测性、流量控制、故障转移等关键能力,为大模型应用提供更加稳定和可靠的基础设施支持。
前提条件
需要准备好一个 GPU Kubernetes 集群,本实验需要用到 2 块 GPU。可以参考该教程部署 GPU 集群:一键部署 GPU Kind 集群,体验 vLLM 极速推理。
安装 Higress
Higress 可以通过 Helm Chart 安装,安装命令如下:
helm repo add higress.io https://higress.cn/helm-charts
helm install higress -n higress-system higress.io/higress --create-namespace --render-subchart-notes
使用 kubectl port-forward 命令将 Higress Console 服务转发到本地端口,方便本地访问控制台。
kubectl port-forward -n higress-system svc/higress-console 8080:8080
打开浏览器访问 http://127.0.0.1:8080,即可访问 Higress Console。首次登录需要初始化控制台的用户名和密码。
安装 llmaz
llmaz 可以通过 Helm Chart 安装,安装命令如下:
helm install llmaz oci://registry-1.docker.io/inftyai/llmaz --namespace llmaz-system --create-namespace --version 0.0.10
如果你的模型需要 HuggingFace Token 才能下载,请执行以下命令创建 modelhub-secret Secret。例如,下面使用的 google/gemma-2-2b-it 模型就需要 HuggingFace Token,并且你还需要在该模型的 HuggingFace 页面 上同意相关许可条款后才能使用。
kubectl create secret generic modelhub-secret --from-literal=HF_TOKEN=<your token>
使用 llmaz 部署 vLLM 推理服务
接下来,我们将使用 llmaz 部署两个不同的大语言模型:阿里云的 Qwen/Qwen2.5-1.5B-Instruct 和 Google 的 google/gemma-2-2b-it。这两个模型都将使用 vLLM 作为推理引擎,每个模型分配一块 GPU 资源。
在 llmaz 中,我们需要创建两种类型的资源:
OpenModel- 定义模型的来源和基本信息。Playground- 定义模型的运行时配置,包括资源分配和推理引擎。Playground中需要配置模型运行的BackendRuntime,llmaz 提供了预定义的vllm(默认)、sglang、tensorrt-llm和llamacpp等多种开箱即用的推理引擎。
将以下 YAML 文件应用到 Kubernetes 集群中。
apiVersion: llmaz.io/v1alpha1
kind: OpenModel
metadata:name: qwen2-1-5b
spec:familyName: qwen2source:modelHub:modelID: Qwen/Qwen2.5-1.5B-Instruct
---
apiVersion: inference.llmaz.io/v1alpha1
kind: Playground
metadata:name: qwen2-1-5b
spec:replicas: 1modelClaim:modelName: qwen2-1-5bbackendRuntimeConfig:backendName: vllmresources:limits:cpu: "4"memory: 16Ginvidia.com/gpu: "1"requests:cpu: "4"memory: 16Ginvidia.com/gpu: "1"
---
apiVersion: llmaz.io/v1alpha1
kind: OpenModel
metadata:name: gemma-2-2b
spec:familyName: gemmasource:modelHub:modelID: google/gemma-2-2b-it
---
apiVersion: inference.llmaz.io/v1alpha1
kind: Playground
metadata:name: gemma-2-2b
spec:replicas: 1modelClaim:modelName: gemma-2-2bbackendRuntimeConfig:backendName: vllmresources:limits:cpu: "4"memory: 16Ginvidia.com/gpu: "1"requests:cpu: "4"memory: 16Ginvidia.com/gpu: "1"
确认 vLLM Pod 都已经成功 Running:
kubectl get pods
NAME READY STATUS RESTARTS AGE
gemma-2-2b-0 1/1 Running 0 16m
qwen2-1-5b-0 1/1 Running 0 13mkubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
gemma-2-2b ClusterIP None <none> <none> 21m
gemma-2-2b-lb ClusterIP 100.108.18.194 <none> 8080/TCP 21m
qwen2-1-5b ClusterIP None <none> <none> 21m
qwen2-1-5b-lb ClusterIP 100.106.253.20 <none> 8080/TCP 21m
配置 Higress 代理 vLLM 推理服务
首先,为两个 vLLM 推理服务分别创建对应的 AI Service Provider。由于 vLLM 原生兼容 OpenAI 协议,因此在创建 AI Service Provider 时可以选择类型为 OpenAI,并设置自定义的 Base URL,分别如下:
http://qwen2-1-5b-lb.default.svc.cluster.local:8080/v1
http://gemma-2-2b-lb.default.svc.cluster.local:8080/v1
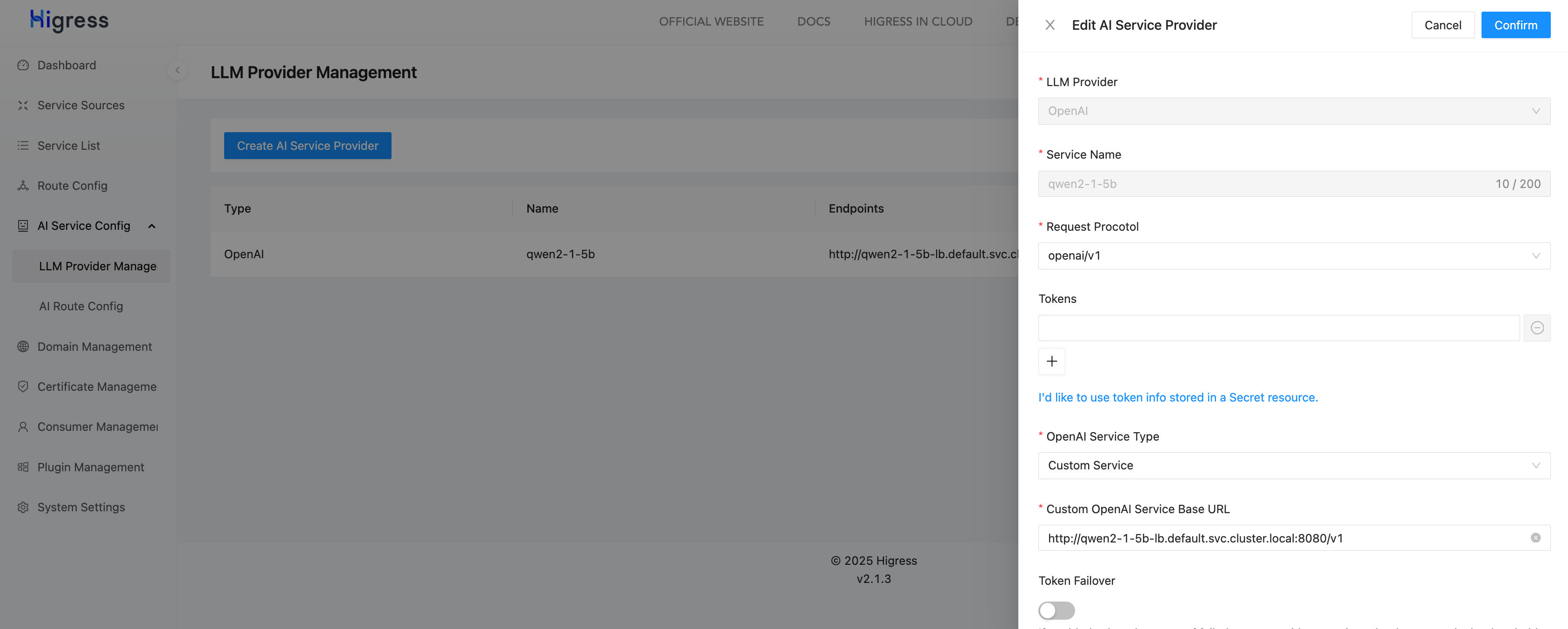
创建好的 AI Service Provider 如下:
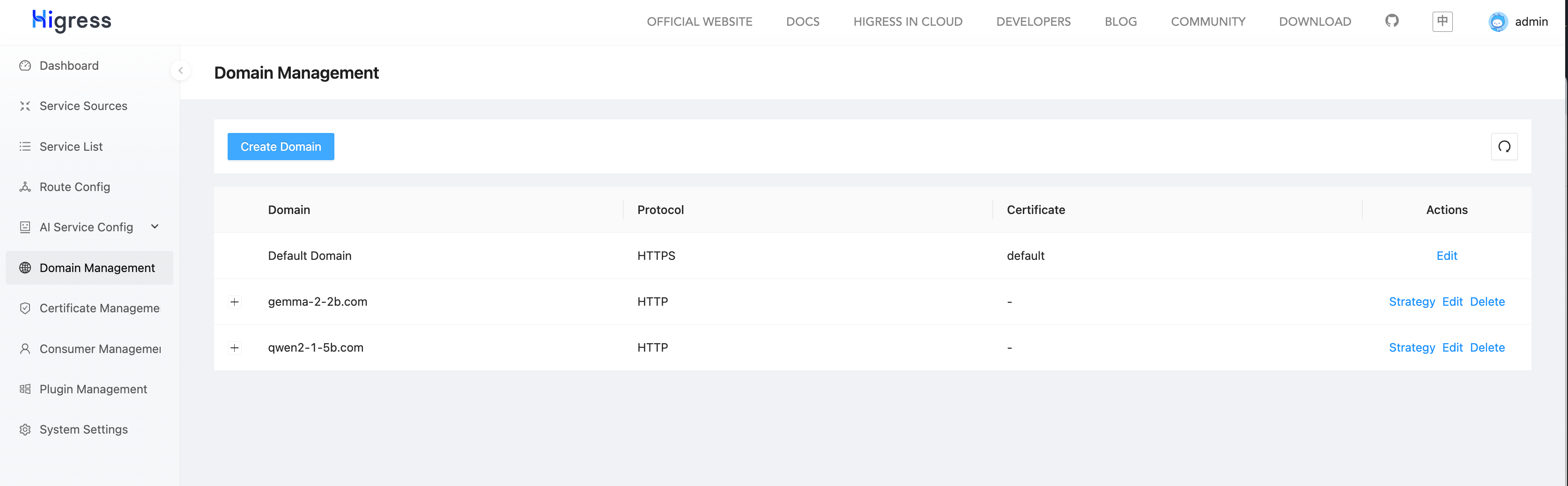
接下来创建对应的 AI Route,根据请求体中的 model 字段进行匹配,将请求路由到对应的模型服务。
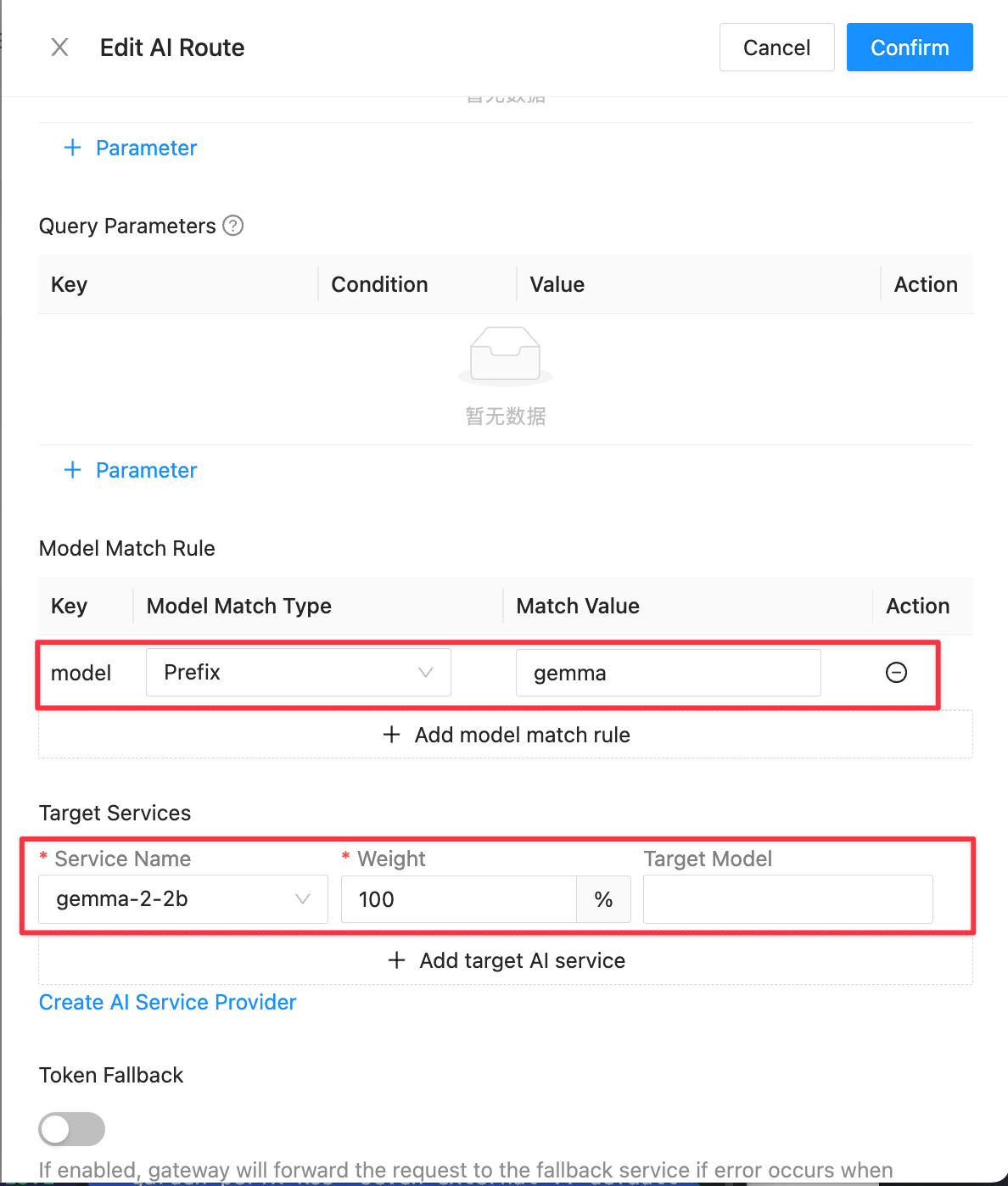
创建好的 AI Route 如下:
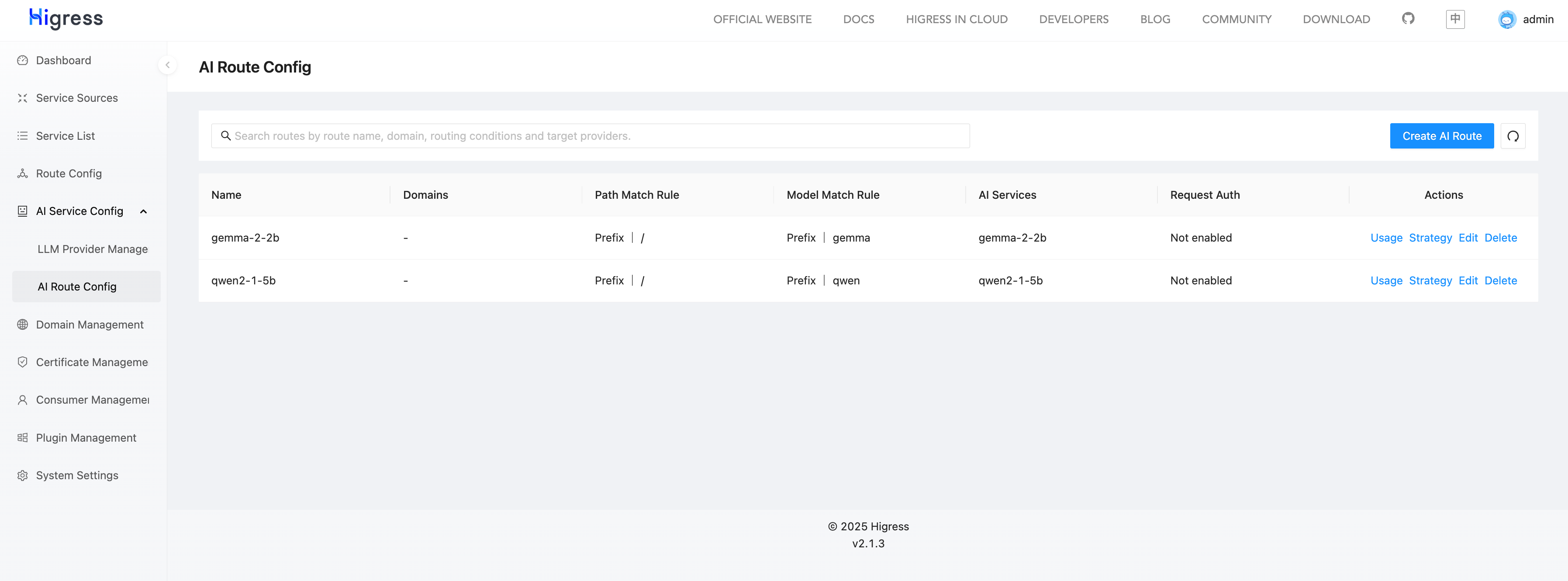
如果你希望使用 Kubernetes YAML 来配置 AI Service Provider 和 AI Route,可以使用以下配置:https://github.com/cr7258/hands-on-lab/blob/main/gateway/higress/ai-proxy/on-premises/ai-route.yaml
通过 Higress AI 网关访问 vLLM 推理服务
使用 kubectl port-forward 命令将 Higress Gateway 服务转发到本地端口,方便进行测试。
kubectl port-forward -n higress-system svc/higress-gateway 18000:80
首先请求 qwen2-1-5b 模型,模型名称确保和 llmaz OpenModel 定义的 modelName 一致。
curl http://localhost:18000/v1/chat/completions \-H 'Content-Type: application/json' \-d '{"model": "qwen2-1-5b","messages": [{"role": "user","content": "Who are you?"}]}'# 响应
{"choices": [{"finish_reason": "stop","index": 0,"logprobs": null,"message": {"content": "I am Qwen, developed by Alibaba Cloud. I am a large language model created to assist with tasks such as answering questions, providing information, and generating text based on the input given. I can help with a variety of topics, including but not limited to, natural language processing, computer vision, and applications of machine learning. Please feel free to ask me any questions you might have or provide feedback on how I can improve my abilities.","reasoning_content": null,"role": "assistant","tool_calls": []},"stop_reason": null}],"created": 1749615329,"id": "chatcmpl-bad4e501-fa2c-4af1-a30f-74b34a6a753d","model": "qwen2-1-5b","object": "chat.completion","prompt_logprobs": null,"usage": {"completion_tokens": 89,"prompt_tokens": 33,"prompt_tokens_details": null,"total_tokens": 122}
}
然后访问 gemma-2-2b 模型,可以看到请求也成功了。
curl http://localhost:18000/v1/chat/completions \-H 'Content-Type: application/json' \-d '{"model": "gemma-2-2b","messages": [{"role": "user","content": "Who are you?"}]}'# 响应
{"choices": [{"finish_reason": "stop","index": 0,"logprobs": null,"message": {"content": "Hello! I am Gemma, an AI assistant created by the Gemma team. I am a large language model, which means I'm very good at understanding and generating human-like text. \n\nHere are some things to keep in mind about me:\n\n* **I'm an open-weights model:** This means I'm transparent, and anyone can access and use my code. \n* **I'm text-only:** I can only communicate through text - I can't see images or videos, or process sound. \n* **I don't have access to the internet:** I can't provide you with real-time information or browse the web. \n* **I'm here to help:** I am ready to answer your questions, generate creative text formats, translate languages, and much more.\n\nHow can I help you today? 😊 \n","reasoning_content": null,"role": "assistant","tool_calls": []},"stop_reason": 107}],"created": 1749615455,"id": "chatcmpl-83cd88b1-2426-4856-b201-6deff1292645","model": "gemma-2-2b","object": "chat.completion","prompt_logprobs": null,"usage": {"completion_tokens": 184,"prompt_tokens": 13,"prompt_tokens_details": null,"total_tokens": 197}
}
你也可以加上 "stream": true 参数来实现流式返回。
curl http://localhost:18000/v1/chat/completions \-H 'Content-Type: application/json' \-d '{"model": "qwen2-1-5b","messages": [{"role": "user","content": "Who are you?"}],"stream": true}'# 响应
data: {"id":"chatcmpl-05d06508-81c9-49ed-8969-1065a9e02417","object":"chat.completion.chunk","created":1749617069,"model":"qwen2-1-5b","choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}]}data: {"id":"chatcmpl-05d06508-81c9-49ed-8969-1065a9e02417","object":"chat.completion.chunk","created":1749617069,"model":"qwen2-1-5b","choices":[{"index":0,"delta":{"content":"I"},"logprobs":null,"finish_reason":null}]}data: {"id":"chatcmpl-05d06508-81c9-49ed-8969-1065a9e02417","object":"chat.completion.chunk","created":1749617069,"model":"qwen2-1-5b","choices":[{"index":0,"delta":{"content":" am"},"logprobs":null,"finish_reason":null}]}......data: {"id":"chatcmpl-05d06508-81c9-49ed-8969-1065a9e02417","object":"chat.completion.chunk","created":1749617069,"model":"qwen2-1-5b","choices":[{"index":0,"delta":{"content":"!"},"logprobs":null,"finish_reason":null}]}data: {"id":"chatcmpl-05d06508-81c9-49ed-8969-1065a9e02417","object":"chat.completion.chunk","created":1749617069,"model":"qwen2-1-5b","choices":[{"index":0,"delta":{"content":""},"logprobs":null,"finish_reason":"stop","stop_reason":null}]}data: {"id":"chatcmpl-05d06508-81c9-49ed-8969-1065a9e02417","object":"chat.completion.chunk","created":1749617069,"model":"qwen2-1-5b","choices":[],"usage":{"prompt_tokens":33,"total_tokens":88,"completion_tokens":55}}data: [DONE]
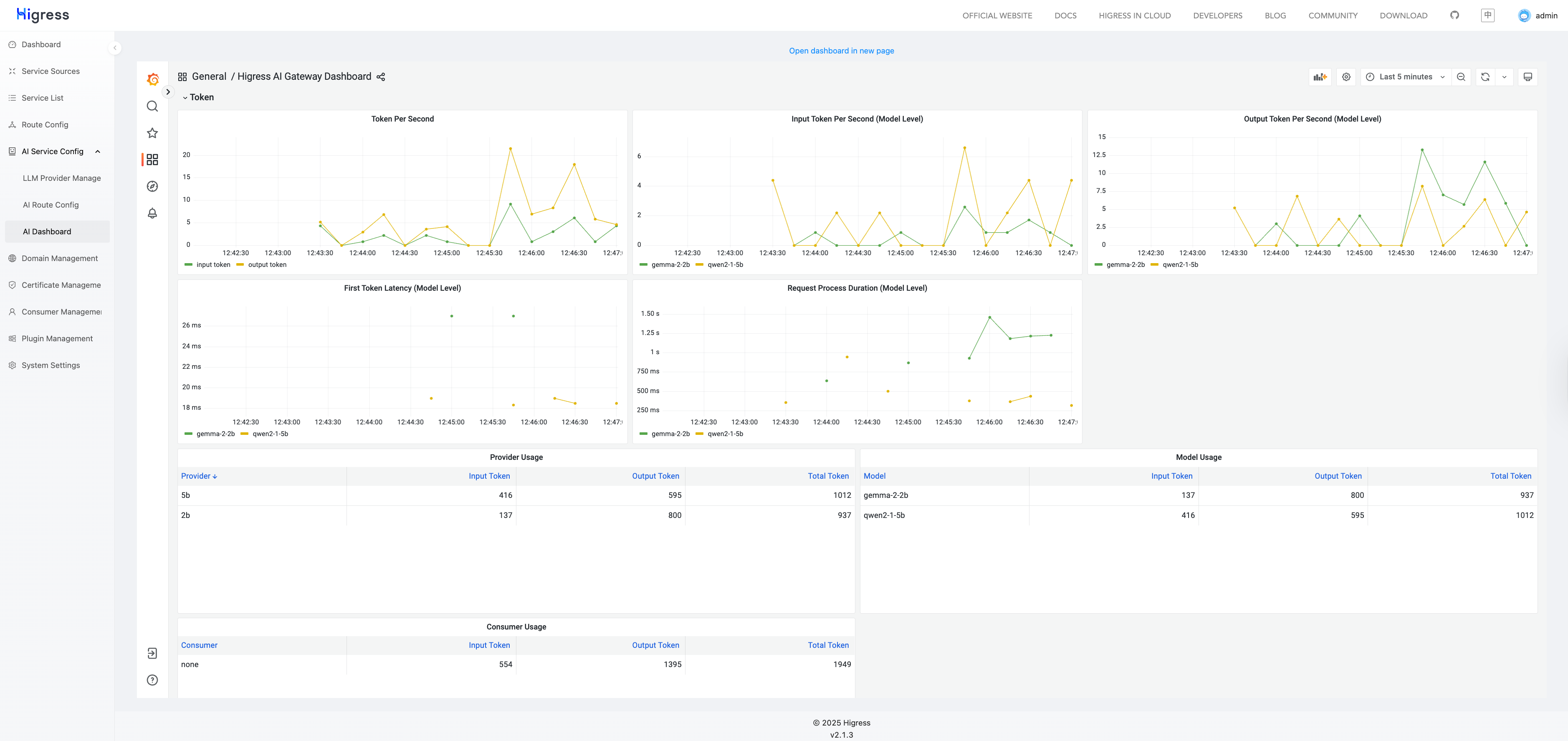
可观测性
Higress 提供了对大模型推理请求的可观测性支持,内置指标包括:输入 Token 数、输出 Token 数、首个 Token 的响应时间(针对流式请求)、请求总响应时间等。
默认 Higress 的可观测套件没有启用,执行以下命令启用可观测套件:
helm upgrade --install higress -n higress-system higress.io/higress --create-namespace --render-subchart-notes \
--set global.o11y.enabled=true --set global.pvc.rwxSupported=false
然后就可以在 Higress Console 的 AI Dashboard 页面中看到大模型推理请求的指标数据了。
Fallback 模型切换
Higress AI 网关支持 Fallback 模型切换,当请求的模型服务不可用时,可以自动切换到备用模型服务。在 qwen2-1-5b 模型的 AI Route 配置中,可指定当返回 5xx HTTP 错误码时,自动切换至 gemma-2-2b 模型服务。切换过程用户是无感的,原本可能失败的请求在切换后可由备用模型成功处理并返回结果。
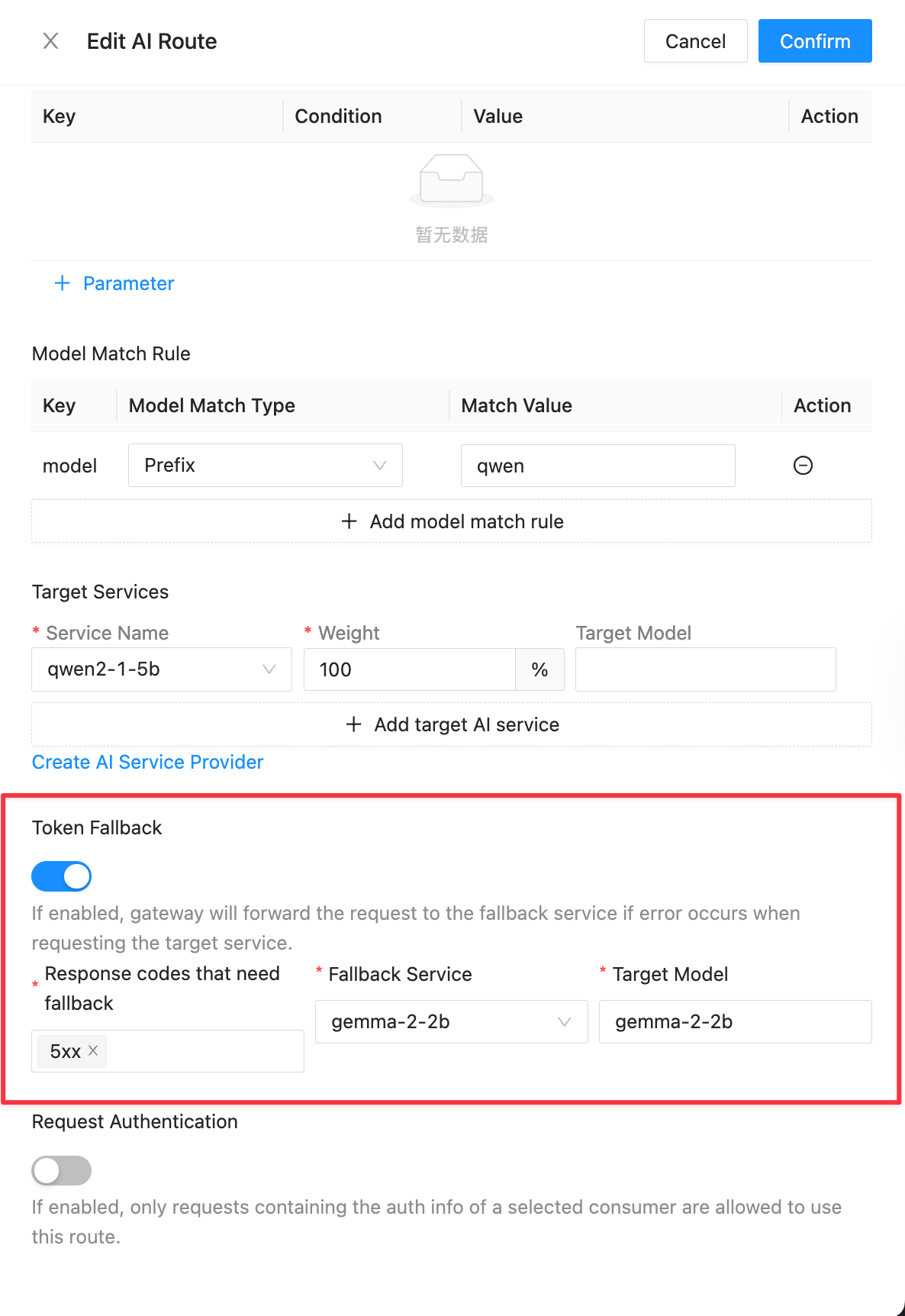
如果你希望使用 Kubernetes YAML 来配置 Fallback 模型切换,可以使用以下配置:https://github.com/cr7258/hands-on-lab/blob/main/gateway/higress/ai-proxy/on-premises/fallback.yaml
接下来删除 qwen2-1-5b 模型 Pod,模拟主模型服务不可用的情况。
kubectl delete pod qwen2-1-5b-0 --force
随后再次请求 qwen2-1-5b 模型服务,从响应内容可以看出请求已成功切换至 gemma-2-2b 模型,说明 Fallback 机制已生效。整个切换过程对用户完全透明,请求未感知到任何失败,确保了服务的连续性与可用性。
curl http://localhost:18000/v1/chat/completions \-H 'Content-Type: application/json' \-d '{"model": "qwen2-1-5b","messages": [{"role": "user","content": "Who are you?"}]}'# 响应
{"choices": [{"finish_reason": "stop","index": 0,"logprobs": null,"message": {"content": "I am Gemma, an open-weights AI assistant developed by the Gemma team. I am a large language model, which means I'm trained on a massive amount of text data. This lets me understand and generate human-like text in response to a wide range of prompts. For example, I can answer your questions, write stories, and have conversations with you. \n\nHowever, remember that I'm still under development, so I don't have access to tools, real-time information, or Google search. I can only tap into what I've been trained on. 😊 \n","reasoning_content": null,"role": "assistant","tool_calls": []},"stop_reason": 107}],"created": 1749617726,"id": "chatcmpl-5df6f105-6da4-4b49-b06c-ffc3c7c75543","model": "gemma-2-2b","object": "chat.completion","prompt_logprobs": null,"usage": {"completion_tokens": 125,"prompt_tokens": 13,"prompt_tokens_details": null,"total_tokens": 138}
}
总结
本文介绍了如何借助 llmaz 快速部署基于 vLLM 的大语言模型推理服务,并结合 Higress AI 网关 实现服务代理、流量调度、可观测性和 Fallback 等关键能力。
欢迎关注
