长春网站排名关键词在线听免费



专栏:算法的魔法世界
个人主页:手握风云
目录
一、递归
二、例题讲解
2.1. 汉诺塔问题
2.2. 合并两个有序链表
2.3. 反转链表
2.4. 两两交换链表中的节点
2.5. Pow(x, n)
三、总结
一、递归
- 递归的概念
一个方法在执行过程中调用自身, 就称为递归。比如前面讲到过的二叉树的前序遍历、快速排序、归并排序。二叉树的前序遍历是按照“根结点、左子树、右子树”的顺序进行遍历,当遍历到一个孩子结点时,又可以看作是一棵新的二叉树,再按照上面的顺序遍历,遇到空则返回;快速排序的思路是,随机选取一个基准值,比基准值小的放到左边,比基准值大的放到右边,然后左边再按照这个过程继续排序,右边也按照这个过程继续排序;归并排序的实录是选取中点值作为基准,将数组划分为两块进行排序,当数组被划分为只有一个元素时,进行合并排序。
- 递归的本质
递归是将主问题划分为解决方法相同的子问题,而子问题又可以划分为解决方法相同的子问题。当我们在解决子问题的时候就依然可以调用该方法来实现。
- 宏观的视角看待递归
这里我们不必在意递归的细节展开图,否则学起来会非常痛苦的。我们把递归的方法当成一个黑盒,只在乎它返回给我们的结果,不去在意这个过程是如何执行的。我们以二叉树的前序遍历为例:我们只需要把根结点传入黑盒中,打印根结点的值;再去遍历左子树,把左孩子结点传入PreOrder方法里面;再去遍历右子树,把右孩子结点传入PreOrder方法里面。我们不必在意那些细节是如何执行的,只需要每一层是如何操作的。当叶子结点的左孩子结点或者右孩子结点为空,就不能再分割成下一个子问题了,此时就是递归方法的出口了。
public void PreOrder(TreeNode root){if(root == null){return;}System.out.print(root.val+" ");PreOrder(root.left);PreOrder(root.right);
}- 如何写好一个递归
1.先找到相同的子问题(重点)!这里涉及到递归方法的方法头设计与子问题的设计是相同的。2.只关心某一个子问题是如何执行的,有关方法体的书写。3.注意递归方法的出口。
二、例题讲解
2.1. 汉诺塔问题

我们先来模拟一下示例1的过程:先将A中的0移动到C上,再将A中的1移动B上,然后将C中的0移动到B上,接着将A的2移动到C上,再把B中的0移动到A上,继续将B中的1移动到C上,最后把0移动到C上。
我们首先要搞懂为什么汉诺塔可以用递归来解决?我们先来看N=1的情况,就可以直接将盘子移动到C上;当N=2时,先利用B进行辅助,将0移动到B上,再将1移动到C上,最后将0移动到C上;当N=3时,把最上面两个的0和1先转移到C上,过程可以参照N=2的过程,再将2转移到C上,B上的两个盘子按照第一步的过程转移到C上;而当N=4时,我们也可以把最上面的3个先转移到B上,再将最大的盘子移到C上,最后将B上的盘子移动到C上。
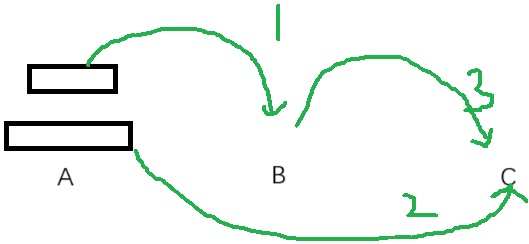
编写递归代码:1.先写出方法的头,该方法的过程都是先将A上的盘子借助B转移到C上,所以我们就可以写作;2.方法体的书写,先将最上面的n-1个盘子转移到B上,接着将最大的盘子转移到C上,最后再把B上的盘子转移到C上;最后确定一下递归的出口,当n=1时,与其他过程不一样,直接把A上的盘子放到C上,不需要借助B。
//方法头
private void dfs(List A,List B,List C,int n);//方法体的书写
dfs(A,C,B,n-1);
C.add(A.remove(A.size() - 1));
dfs(B,A,C,n-1);完整代码实现:
class Solution {public void hanota(List<Integer> A, List<Integer> B, List<Integer> C) {dfs(A, B, C, A.size());}private void dfs(List<Integer> a, List<Integer> b, List<Integer> c, int n) {if (n == 1) {c.add(a.remove(a.size() - 1));return;}dfs(a, c, b, n - 1);c.add(a.remove(a.size() - 1));dfs(b, a, c, n - 1);}
}2.2. 合并两个有序链表

我们在数据结构里面已经讲过:先创建一个傀儡结点当作新链表的头结点,然后利用双指针遍历两个链表,结点值小的放在傀儡结点之后,同时指针向后移动,同时还得需要一个tmp引用永远指向新链表的尾结点,这样方便构建新的链表。
本次我们将以递归的方式来完成这道题。我们还是利用双指针的做法,这里我们不创建傀儡结点,直接以两个链表较小的结点值作为新链表的头结点,然后以两个链表剩下的部分再继续进行合并两个有序链表的操作。递归的过程:先比较结点值的大小,结点值小的结点接入新链表中,同时指针向后移动。当两个指针都为空时,递归结束。
完整代码实现:
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode mergeTwoLists(ListNode list1, ListNode list2) {if(list1 == null) return list2;if(list2 == null) return list1;if(list1.val >= list2.val){list2.next = mergeTwoLists(list1,list2.next);return list2;}else {list1.next = mergeTwoLists(list1.next,list2);return list1;}}
}2.3. 反转链表
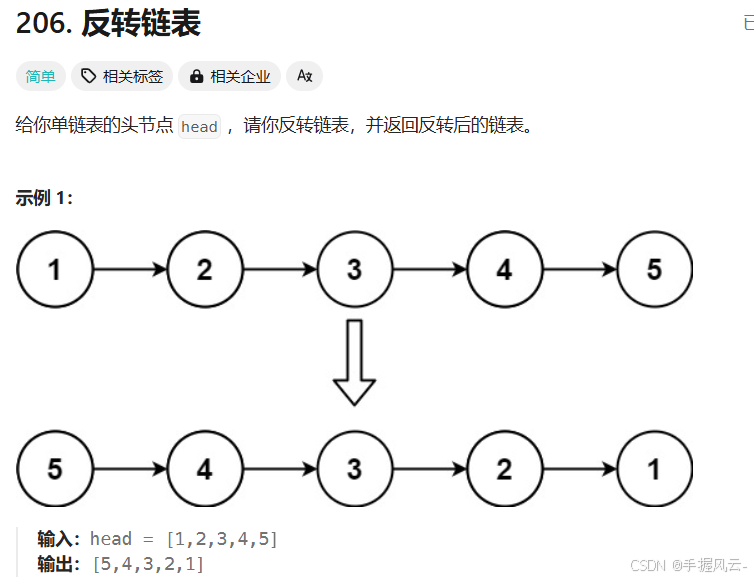
我们在数据结构的部分也分析过这道题:先将链表的头节点置为空,然后将剩下的结点以头插的方式进行反转。
宏观视角:我们先思考如何将前两个结点进行反转,将head.next.next的引用指向head,再将head.next置为空,但这样后面的结点会丢失,所以这种做法不可取。如果我们先将头结点后面的部分进行反转,然后再将反转后的尾结点连上反转前的头节点即可。
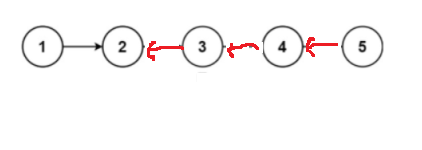
将链表看作一棵树:我们将链表看作一棵只有一个叶子结点的树形结构,先对二叉树进行深度遍历,直到遍历到最后的空结点,然后返回尾结点作为新链表的头结点,然后再返回。当返回上一个结点时,将结点5的next指向4,将结点4的next置为空,因为这样就可以也将结点1的next也同样置为空。这样当我们返回到结点1时,既可以将前面的部分反转,也可以将结点1置为空。

完整代码实现:
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode reverseList(ListNode head) {if(head == null || head.next == null) return head;ListNode newHead = reverseList(head.next);head.next.next = head;head.next = null;return newHead;}
}2.4. 两两交换链表中的节点

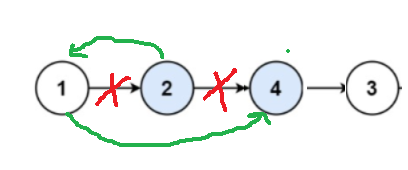
利用上一题的思路,也可以利用宏观视角,传入头结点,直接利用给定的方法当作递归的方法头,先交换前两个结点,后面的看作是一个整体,具体怎么交换我们不关心,只需要相信swapPairs方法一定能够交换。将后面以交换的部分与前两个已经交换的结点连起来,就能得到最终结果。我们先让结点2的next指向结点1,再让结点1的next指向结点4,就可以完成前两个结点交换,并且逆置后的引用也会指向后面剩余的结点。当结点为空时,就是递归的出口。
完整代码实现:
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode swapPairs(ListNode head) {if(head == null || head.next == null) return head;ListNode tmp = swapPairs(head.next.next);ListNode ret = head.next;ret.next = head;head.next = tmp;return ret;}
}2.5. Pow(x, n)

这道题要让我们实现快速幂的算法。比如我们要求,如果利用循环,就需要将3累乘16次,但如果我们采取递归的思路,先将
拆成
与
相乘,再将
拆成
与
……直到将其拆分为1。递归的方法头,也就是题目当中所给的myPow方法,每一个子问题是要求tmp = myPow(x,n/2)。如果n是偶数,就直接返回tmp*tmp;如果n是奇数,最后还得再乘一个x。如果n=0,直接返回1,同时也是递归的出口。如果n是负数,我们只需返回它的倒数即可。
完整代码实现:
class Solution {public double myPow(double x, int n) {return n < 0 ? 1 / pow(x, -n) : pow(x, n);}public double pow(double x, int n) {if (n == 0) return 1.0;double tmp = pow(x, n / 2);return n % 2 == 0 ? tmp * tmp : tmp * tmp * x;}
}三、总结
递归与循环一样,都是去执行相同的子问题,那么二者之间是可以相互转化的,那么我们什么时候用循环迭代效率更好,什么时候用递归效率更高。
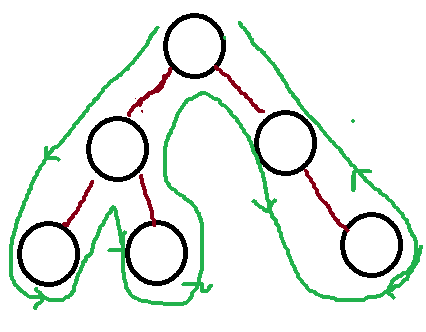
如下图所示,递归的细节展开图与二叉树的深搜极其相似。我们要想将递归转化为循环的话,就得借助栈来实现,因为当我们遍历一个子问题,我们需要保存上一个的信息方便调用方法执行右侧。但一个递归的细节展开图越复杂时,用递归就比较好解决;如果展开图只有一个分支,用循环迭代就比较方便。