企业网站建设公司名称个人博客网页制作
P169 pyecharts 基本介绍 2025/3/23
一、基本介绍
- 参考文档1:https://pyecharts.org/#/zh-cn/
- 参考文档2:https://gallery.pyecharts.org/#/README
- 概况:
Echarts是一个由百度开源的数据可视化技术,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而Python很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts诞生了。
- 特性:
- 简洁的API设计,使用如丝滑般流畅,支持链式调用
- 囊括了30+种常见图表,应有尽有
- 支持主流Notebook 环境,Jupyter Notebook和JupyterLab可轻松集成至Flask,Django等主流Web 框架
- 高度灵活的配置项,可轻松搭配出精美的图表详细的文档和示例,帮助开发者更快的上手项目
- 多达400+地图文件以及原生的百度地图,为地理数据可视化提供强有力的支持
二、能做出怎样的图表效果

P170 pyecharts 快速入门 2025/3/23
一、快速入门
-
参考文档:https://pyecharts.org/#/zh-cn/quickstart
-
安装pyecharts:
pip install pyecharts -
查看版本:
import pyechartsprint(pyecharts.__version__) -
案例代码:
from pyecharts.charts import Barbar = Bar()
bar.add_xaxis(["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"])
bar.add_yaxis("商家A", [5, 20, 36, 10, 75, 90])
# render 会生成本地 HTML 文件,默认会在当前目录生成 render.html 文件
# 也可以传入路径参数,如 bar.render("mycharts.html")
bar.render()
pyecharts所有方法均支持链式调用:
from pyecharts.charts import Barbar = (Bar().add_xaxis(["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"]).add_yaxis("商家A", [5, 20, 36, 10, 75, 90]).render("myrender2.html")
)
- 后续可以直接参考:https://pyecharts.org/#/zh-cn/quickstart
- 使用标题:
.set_global_opts(title_opts=opts.TitleOpts(title="主标题", subtitle="副标题"))
- 更改主题:
Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
P171 pyecharts开发图表 2025/3/24
- 参考文档:https://gallery.pyecharts.org/#/Pie/pie_set_color
# @Author :zjc
# @File :02_pie_sale.py
# @Time :2025/3/24 16:06from pyecharts import options as opts
from pyecharts.charts import Pie
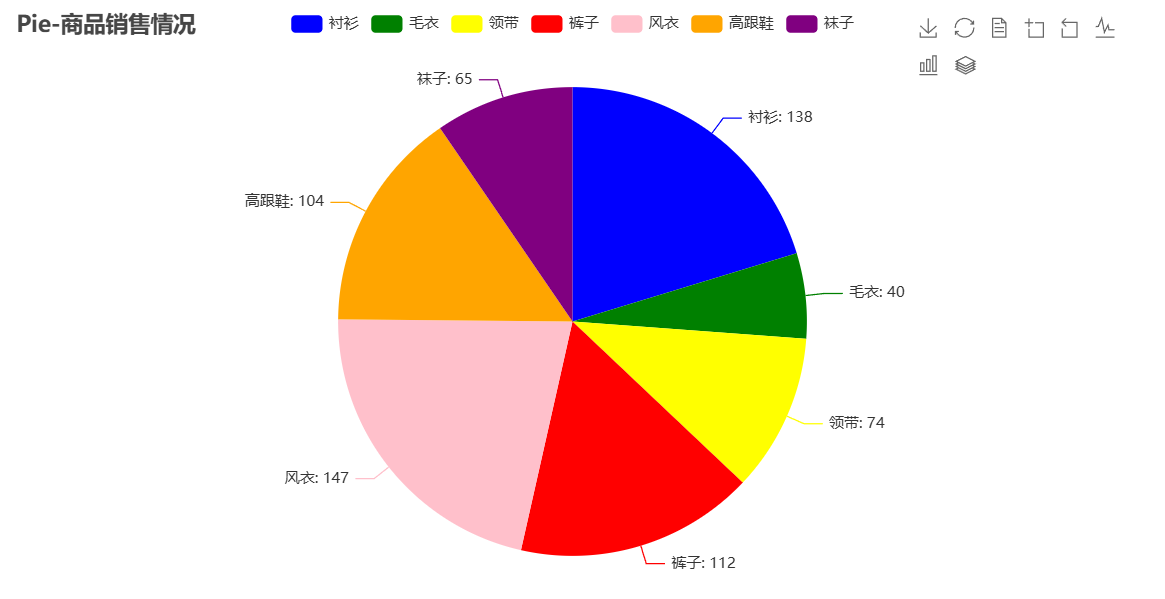
from pyecharts.faker import Faker"""解读:1. Pie() 创建Pie对象2. .add("", [list(z) for z in zip(Faker.choose(), Faker.values())])就是给饼状图添加数据3. .set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])设置全局配置项4. .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))设置系列配置项formatter="{b}: {c}" 标签显示的形式为 名称:值5. .render("pie_sale.html") 生成对应的网页文件 pie_sale.html
"""data = [['衬衫', 138], ['毛衣', 40], ['领带', 74], ['裤子', 112],['风衣', 147], ['高跟鞋', 104], ['袜子', 65]];c = (Pie().add("", data).set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"]).set_global_opts(title_opts=opts.TitleOpts(title="Pie-商品销售情况"), toolbox_opts=opts.ToolboxOpts(is_show=True)).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}",font_size=12)).render("pie_sale.html")
)
P172 pyecharts开发折线图 2025/3/2
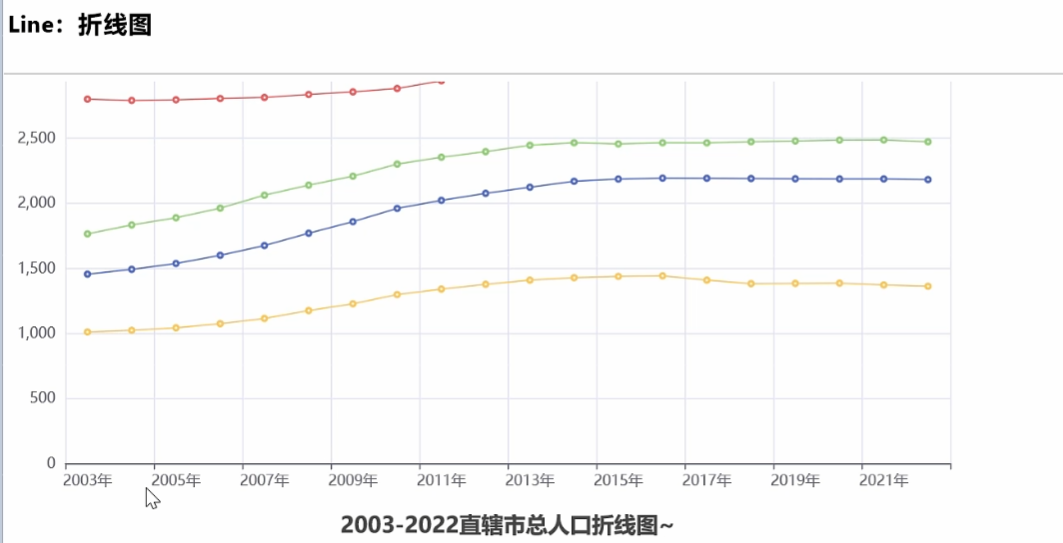
- 参考文档:https://gallery.pyecharts.org/#/Line/basic_line_chart
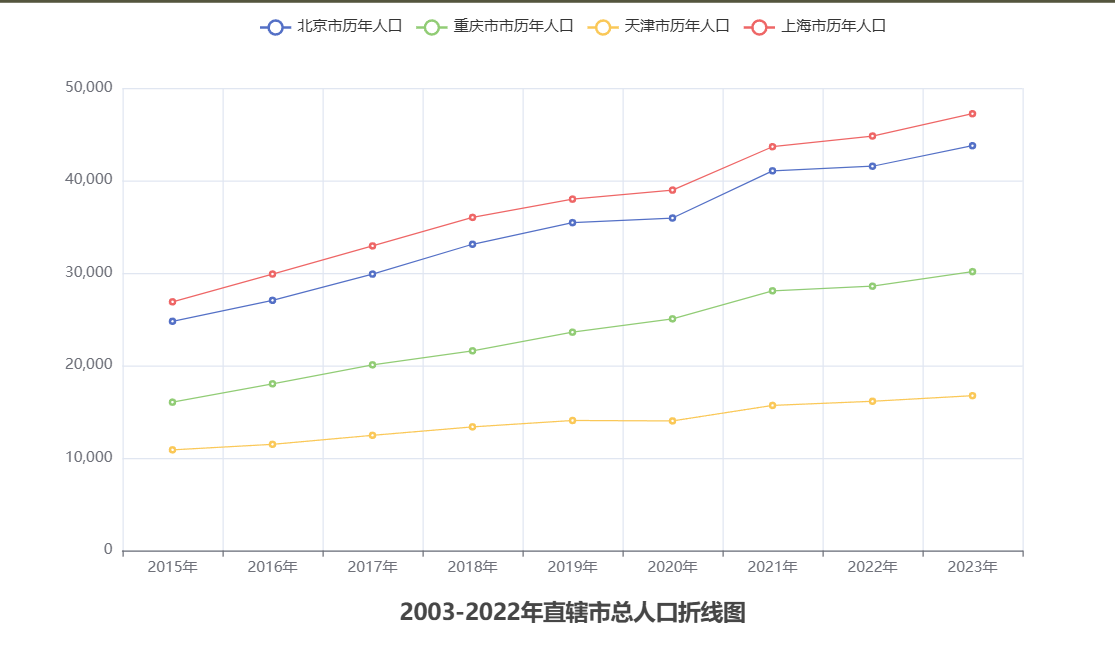
- 对北京市,天津市,上海市,重庆市的近20年人口,做出折线图,效果
- 要求从文件分省年度数据.csv读取数据,数据可从 https://data.stats.gov.cn/easyquery.htm获取
- 代码分析:
import pyecharts.options as opts
from pyecharts.charts import Line# 1. 创建Line对象,折线图对象
line = Line()# 准备数据
# 打开文件:UnicodeDecodeError: 'utf-8' codec can't decode
# 不能使用utf-8编码
f = open("分省年度数据.csv",mode="r",encoding="gbk")
# 先输出文件的内容
# for line in f:
# print(line,end="")
# f.close()# 2. 给x轴添加数据
"""分析:数据就是[2002,2003...2023]
"""# 读取到所有行数据
line_datas = f.readlines()
# print(line_datas)
f.close() # 数据已经接收到可以关闭了# 先删除前面三个行(元素)
for _ in range(3):line_datas.pop(0) # 下标从0开始,循环三次默认从0开始print("line_datas",line_datas)# 得到x轴的数据
# 使用.pop(0)得到数据,然后使用.replace将最后一个换行截取掉,.split使用","进行先拆分
x_data_year = line_datas.pop(0).replace("\n","").split(",")
print(x_data_year)
# 将"地区"删除掉
x_data_year.pop(0)
# 此时得到年份数据
print(x_data_year)
# 将年份颠倒,从小到大
x_data_year.reverse()
print(x_data_year)# 3. 给y轴添加数据
"""分析:这里头四组数据,分别是北京,上海,天津,重庆20年的的人口数据
"""print(line_datas) # '北京市,43760.7,41540.9,41045.6,35
# 创建四个列表,存放 北京,上海,天津,重庆20年的的人口数据
y_data_bj = []
y_data_sh = []
y_data_tj = []
y_data_cq = []# 遍历line_datas得到 北京,上海,天津,重庆20年的的人口数据for line_data in line_datas:line_data = line_data.replace("\n","").split(",")# 不需要第一个元素”北京“,只要后面的数字数据# print(line_data)if line_data[0]=="北京市":line_data.pop(0)line_data.reverse() # 年份从小进行排序y_data_bj = line_dataelif line_data[0]=="上海市":line_data.po
P173 pyecharts开发地图 2025/3/30
- 参考文档:
- 代码案例:
from pyecharts import options as opts
from pyecharts.charts import Map
from pyecharts.faker import Faker"""准备数据"""
with open("分省年度数据.csv", "r", encoding="gbk") as f:# 每行作为一个列表,读取完存在列表中data_lines = f.readlines()# print(data_lines)# 删除data_lines列表的前4个元素(行)
for _ in range(4):# 每次循环删除下标为0的元素(第一个)data_lines.pop(0)# 创建一个空的列表,存放地图数
# 分析map_data_list格式 [[省市名,人口数量],[省市名,人口数量]...]
map_data_list = []for data_line in data_lines:# 用","号进行分割,然后给到列表map中data_line_list = data_line.split(",")# 在某些情况下,数据添加不成功的情况,使用异常处理try:map_data_list.append([data_line_list[0], data_line_list[1]])except Exception as e:# 如果添加数据到map_data_list中数据异常,我们就continue不去处理出问题的这一行continueprint("map", map_data_list)"""创建map对象"""
map = Map()"""添加数据并配置"""
map.add("2023年各省市的人口分布情况", map_data_list, "china")# 全局配置
map.set_global_opts(title_opts=opts.TitleOpts(title="2023年各省市的人口分布情况"),# VisualMapOpts:视觉映射配置项visualmap_opts=opts.VisualMapOpts(# 指定 visualMapPiecewise 组件的最小值。min_=2000,# 指定 visualMapPiecewise 组件的最大值。max_=150000,# 指定组件位置pos_left="10%", # 距离左边10%pos_bottom="50%")
)# 系列配置(标签字体大配置)
map.set_series_opts(label_opts=opts.LabelOpts(font_size=8))"""生成文件"""
map.render("map_data_list.html")
- 结果图:

P174 pyecharts开发轮播图[1] 2025/3/31
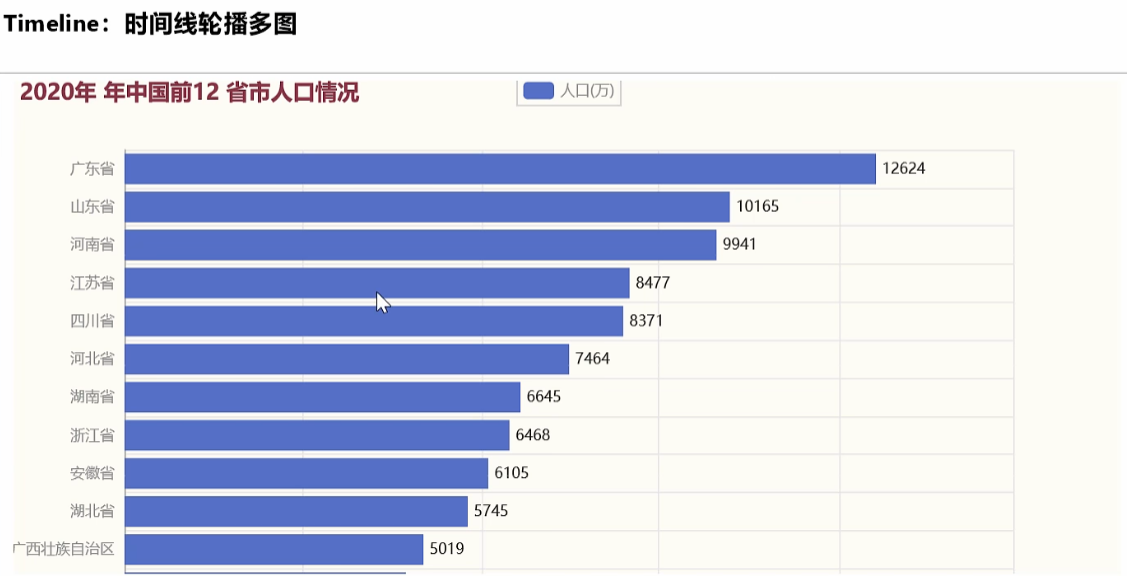
- 对全国2003-2022年各省市的人口,做出动态柱状图/时间线轮播多图,即每隔一定时间间隔,自动的切换显示2003、2004、…、2022各省市的人口(即2003-2022年中国省市人口排名前12的情况),具体如下图:
- 代码部分:已完成对数据添加到字典
# @Author :zjc
# @File :05_timeline_bar_city_population.py
# @Time :2025/3/31 22:12"""
x = Faker.choose() # ["河马", "蟒蛇", "老虎", "大象", "兔子", "熊猫", "狮子"]
tl = Timeline() # 创建对象
for i in range(2015, 2020): # 循环5次,创建了5个bar柱状图bar = (Bar().add_xaxis(x) # 添加x轴数据.add_yaxis("商家A", Faker.values()) # 添加y轴数据,[值1,值2].add_yaxis("商家B", Faker.values()).set_global_opts(title_opts=opts.TitleOpts("某商店{}年营业额".format(i))))tl.add(bar, "{}年".format(i))
tl.render("timeline_bar.html")
"""from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
from pyecharts.faker import Faker"""准备数据"""
# 确定需要创建多少Bar对象,根据文件提供的年份 2015-2023
with open("分省年度数据.csv","r",encoding="gbk") as f:data_lines = f.readlines()# 删除data_lines列表前三个元素,顺便替换掉\n
for _ in range(3):data_lines.pop(0)# 删除data_lines最后一个元素
data_lines.pop(-1)# 取出第一个元素(年份数据)
years = data_lines.pop(0).replace("\n","").split(",")# 去掉地区这个元素"地区"
years.pop(0)
# 此时数据:['2023年', '2022年', '2021年', '2020年', '2019年', '2018年', '2017年', '2016年', '2015年']# 遍历 data_lines 生成我们需要的数据
# 难度-需要我们设计一些
# 把数据放在一个字典对象中 data_dict = {年份:[[省市名,人口数],[省市名,人口数]...]}
# 具体案例:{2003:[["北京市",2184],["天津市",2184]],2004:[["北京市",1184],["天津市",2884]]}# 创建字典对象
data_dict = {}for data_line in data_lines:data_line_list = data_line.replace("\n","").split(",")# 数据:['北京市', '43760.7', '41540.9', '41045.6# print(data_line_list)# 遍历years给各个城市的各个年份的人口数据添加到data_dictindex = 0for year in years:index += 1try:# 将每个年份作为字典的键"key",data_dict[year].append([data_line_list[0],data_line_list[index]])except Exception as e:# 如果出现了异常,说明是第一次添加数据# 那就将第一个 key 创建起来,值为空;继续添加data_dict[year] = []data_dict[year].append([data_line_list[0], data_line_list[index]])print(data_dict)"""创建Timeline对象""""""创建Bar对象 并加入到Timeline 还有进行配置""""""生成对应的文件"""
P175 pyecharts开发轮播图[2] 2025/4/1
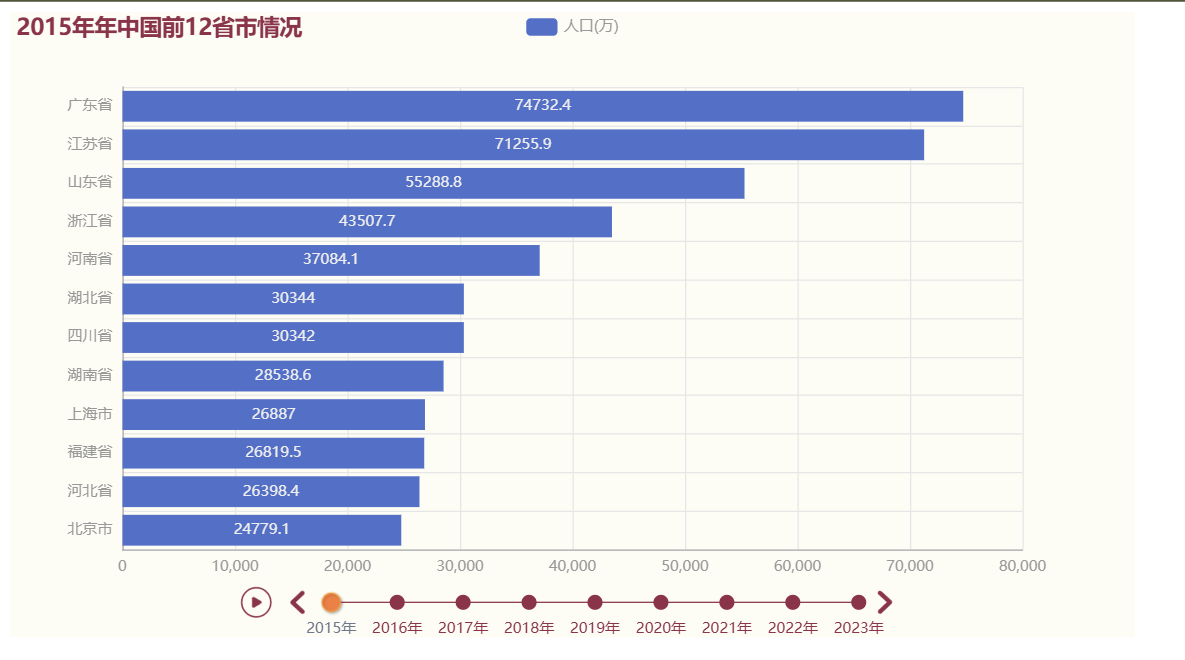
- 结果展示:
- 最终代码:
# @Author :zjc
# @File :05_timeline_bar_city_population.py
# @Time :2025/3/31 22:12"""
x = Faker.choose() # ["河马", "蟒蛇", "老虎", "大象", "兔子", "熊猫", "狮子"]
tl = Timeline() # 创建对象
for i in range(2015, 2020): # 循环5次,创建了5个bar柱状图bar = (Bar().add_xaxis(x) # 添加x轴数据.add_yaxis("商家A", Faker.values()) # 添加y轴数据,[值1,值2].add_yaxis("商家B", Faker.values()).set_global_opts(title_opts=opts.TitleOpts("某商店{}年营业额".format(i))))tl.add(bar, "{}年".format(i))
tl.render("timeline_bar.html")
"""from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
from pyecharts.faker import Faker
from pyecharts.globals import ThemeType"""准备数据"""
# 确定需要创建多少Bar对象,根据文件提供的年份 2015-2023
with open("分省年度数据.csv", "r", encoding="gbk") as f:data_lines = f.readlines()# 删除data_lines列表前三个元素,顺便替换掉\n
for _ in range(3):data_lines.pop(0)# 删除data_lines最后一个元素
data_lines.pop(-1)# 取出第一个元素(年份数据)
years = data_lines.pop(0).replace("\n", "").split(",")# 去掉地区这个元素"地区"
years.pop(0)
# 此时数据:['2023年', '2022年', '2021年', '2020年', '2019年', '2018年', '2017年', '2016年', '2015年']# 遍历 data_lines 生成我们需要的数据
# 难度-需要我们设计一些
# 把数据放在一个字典对象中 data_dict = {年份:[[省市名,人口数],[省市名,人口数]...]}
# 具体案例:{2003:[["北京市",2184],["天津市",2184]],2004:[["北京市",1184],["天津市",2884]]}# 创建字典对象
data_dict = {}for data_line in data_lines:data_line_list = data_line.replace("\n", "").split(",")# 数据:['北京市', '43760.7', '41540.9', '41045.6# print(data_line_list)# 遍历years给各个城市的各个年份的人口数据添加到data_dictindex = 0for year in years:index += 1try:# 将每个年份作为字典的键"key",data_dict[year].append([data_line_list[0], float(data_line_list[index])])except Exception as e:# 如果出现了异常,说明是第一次添加数据# 那就将第一个 key 创建起来,值为空;继续添加data_dict[year] = []data_dict[year].append([data_line_list[0], float(data_line_list[index])])"""创建Timeline对象"""
timeline = Timeline({"theme":ThemeType.ESSOS})
years.reverse()"""创建Bar对象 并加入到Timeline对象 还有进行配置"""
for year in years:# 下面我们需要取出每一年按照人口数量排序的前12省市# 1. 先排序 2.在切片# 采用人口数量进行排序,所以索引对应的为1,(适用于列表中的元素还是列表的情况)data_dict[year].sort(key=lambda ele: ele[1], reverse=True)rank_12_city_data = data_dict[year][0:12] # 只切片12个省市# print(year,rank_12_city_data)# rank_12_city_data:[['广东省', 74732.4], ['江苏省', 71255.9], ['山东省', 55288.8]# 定义Bar的x轴数据x_data = []# 定义Bar的x轴数据y_data = []for city in rank_12_city_data:x_data.append(city[0]) # 对应各省市名称y_data.append(city[1]) # 对应的人口数量# 创建Bar对象bar = Bar()# 对x_data和y_data数据进行翻转x_data.reverse()y_data.reverse()bar.add_xaxis(x_data)bar.add_yaxis("人口(万)", y_data)# 转换x轴和y轴bar.reversal_axis()# 全局设置bar.set_global_opts(title_opts=opts.TitleOpts(title=f"{year}年中国前12省市情况"))# 将创建好的bar添加到Timeline对象timeline.add(bar, str(year))# 对时间线进行配置
timeline.add_schema(play_interval=500, # 毫秒单位,半秒is_auto_play=True
)"""生成对应的文件"""timeline.render("2015-2023排名前十二省市情况.html")