Python---文件操作
目录
文件
文件路径
文件操作
打开文件
关闭文件
写文件
读文件
上下文管理器
文件
变量是把数据保存到内存中 . 如果程序重启 / 主机重启 , 内存中的数据就会丢失;要想能让数据被持久化存储 , 就可以把数据存储到硬盘中 . 也就是在 文件 中保存;在 Windows " 此电脑 " 中 , 看到的内容都是 文件。
- 现在的电脑基本没有扩展名的后缀显示。
此电脑--查看--文件扩展名

文件路径
一个机器上, 会存在很多文件 , 为了让这些文件更方面的被组织 , 往往会使用很多的 " 文件夹 "( 也叫做 目录 ) 来整理文件.实际一个文件往往是放在一系列的目录结构之中的.为了 方便确定一个文件所在的位置 , 使用 文件路径 来进行描述
述以 盘符 开头的路径 , 我们也称为 绝对路径相对路径. 相对路径需要先指定一个基准目录 , 然后以基准目录为参照点, 间接的找到目标文件
文件操作
- 要使用文件, 主要是通过文件来保存数据, 并且在后续把保存的数据读取出来.
- 但是要想读写文件, 需要先 "打开文件", 读写完毕之后还要 "关闭文件".
打开文件
使用内建函数
open
打开一个文件
.
f = open('d:/test.txt', 'r')- 第一个参数是一个字符串, 表示要打开的文件路径
- 第二个参数是一个字符串, 表示打开方式.
- 其中:
- r 表示按照读方式打开.
- w 表示按照写方式打开.
- a 表示追加写方式打开.
- 如果打开文件成功, 返回一个文件对象. 后续的读写文件操作都是围绕这个文件对象展开.
- 如果打开文件失败(比如路径指定的文件不存在), 就会抛出异常

关闭文件
使用
close
方法关闭已经打开的文件
.
f.close()使用完毕的文件要记得及时关闭 !打开文件,其实就是在申请一定的系统资源~不再使用文件的时候,资源就应该及时释放。做到“有借有还,再借不难”~否则就可能造成文件 资源泄露 ,进一步的导致其他部分的代码无法顺利打开文件了~~正是因为一个系统的资源是有限的,因此一个程序能打开的文件个数也是有上限的~
- 一个程序能同时打开的文件个数, 是存在上限的.
alist = []
count = 0
while True:
f = open('d:/pythontwo/test.txt', 'r')
alist.append(f)
count += 1
print(f'打开的文件个数 {count}') 
在系统中,是可以通过一些设置项,来配置能打开文件的最大数目~
但是无论配置多少,都还不是无穷无尽的,就需要记得要及时关闭,释放资源~
8189 + 3 = 8192(2的13次方)
这里的3是指:
每个程序在启动的时候会默认打开三个文件~
1.标准输入 键盘 input
2.标准输出 显示器 print
3.标准错误 显示器

如上面代码所示, 如果一直循环的打开文件, 而不去关闭的话, 就会出现上述报错.
当一个程序打开的文件个数超过上限, 就会抛出异常.
注意: 上述代码中, 使用一个列表来保存了所有的文件对象. 如果不进行保存, 那么
Python 内置的垃
圾回收机制(GC)
,自动的把不使用的变量,给进行释放, 会在文件对象销毁的时候自动关闭文件.
但是由于垃圾回收操作不一定及时, 所以我们写代码仍然要考虑手动关闭, 尽量避免依赖自动关闭.
写文件
- 文件打开之后, 就可以写文件了.
- 写文件, 要使用写方式打开, open 第二个参数设为 'w'
使用
write 方法
写入文件
f = open('d:/pythontwo/test.txt','w')
f.write('hello,world')
f.close()运行结果是不显示的,得去你写的路径下去找 test.txt 文件

- 如果是使用 'r' 方式打开文件, 则写入时会抛出异常.

- 使用 'w' 一旦打开文件成功, 就会清空文件原有的数据.
- 使用 'a' 实现 "追加写", 此时原有内容不变, 写入的内容会存在于之前文件内容的末尾
f = open('d:/pythontwo/test.txt','w')
f.write('12345')
f.close()
f = open('d:/pythontwo/test.txt','a')
f.write('12345')
f.close()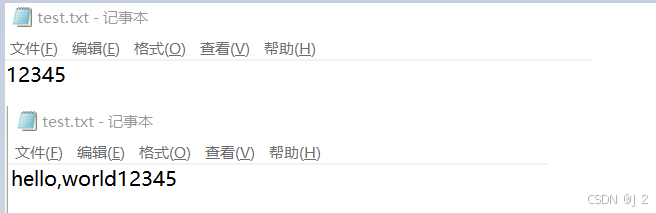
- 针对已经关闭的文件对象进行写操作, 也会抛出异常
f = open('d:/pythontwo/test.txt','w')
f.write('hello,world')
f.close()
f.write('你好')
读文件
读文件内容需要使用 'r' 的方式打开文件使用 read 方法完成读操作 . 参数表示 " 读取几个字符 "
f = open('d:/pythontwo/test.txt','r')
result =f.read(2)
print(result)
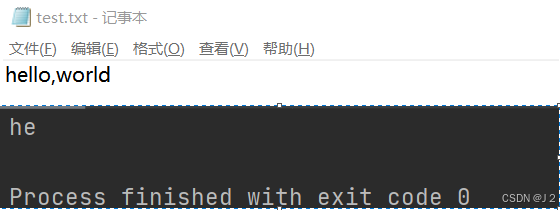
- 如果文件是多行文本, 可以使用 for 循环一次读取一行

先构造一个多行文件
.
f = open('d:/pythontwo/test.txt', 'r' )
for line in f:
print(f'line = {line}')
f.close()
上述报错是说gbk解析不了.中文和英文类似,在计算机中,都是使用“数字”来表示字符的哪个数字,对应哪个汉字?其实在计算机中 ,可以有多个版本~~但是要想表示汉字, 就需要一个更大的码表.一般常用的汉字编码方式, 主要是 GBK 和 UTF-8
- GBK
- UTF8
在实际开发的时候就需要保证,文件内容的编码方式和代码中操作文件的编码方式,匹配!!上述的代码是在尝试按照gbk来解析,就确认一下,文件格式是否是gbk呢?在Python3 中默认打开文件的字符集跟随系统, 而 Windows 简体中文版的字符集采用了 GBK, 所以
- 如果文件本身是 GBK 的编码, 直接就能正确处理.
- 如果文件本身是其他编码(比如 UTF-8), 那么直接打开就可能出现上述问题
在创建的 test.txt 的右下角 有标注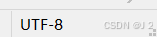 所以应该让代码按照utf8来进行处理~相比gbk,utf8是使用更广泛的编码方式~
所以应该让代码按照utf8来进行处理~相比gbk,utf8是使用更广泛的编码方式~
f = open('d:/pythontwo/test.txt', 'r',encoding='utf8')就能正常的解析出来

这样看起来中间多了空行,是因为本来读到的文件内容(这一行内容,末尾就带有 \n),此处使用print 来打印,优惠自动加一个换行符~
可以给print 再多设定一个参数,修改 print 自动添加换行的行为
print(f'line = {line}',end='')- end 参数 就表示每次打印之后要在末尾加工啥(默认是 \n )修改成 ' ' 也就是啥也不加!

- 还可以使用readlines 方法直接把整个文件所有内容都读出来,按照行组织到一个列表里。
f = open('d:/pythontwo/test.txt', 'r',encoding='utf8')
lines = f.readlines()
print(lines)
f.close()
for循环是一行一行的读取,readlines是一口气全读取。
上下文管理器
打开文件之后, 是容易忘记关闭的 .Python 提供了 上下文管理器 , 来帮助程序猿自动关闭文件 .使用 with 语句 打开文件 .当 with 内部的代码块执行完毕后 , 就会自动调用关闭方法
with open('d:/pythontwo/test.txt', 'r', encoding='utf8') as f:
lines = f.readlines()
print(lines)上下文管理器起到的作用效果:
当 with 对应的代码块执行结束,就会自动的执行f的close。