pg_实例架构图解
一. postgresql 实例架构图解
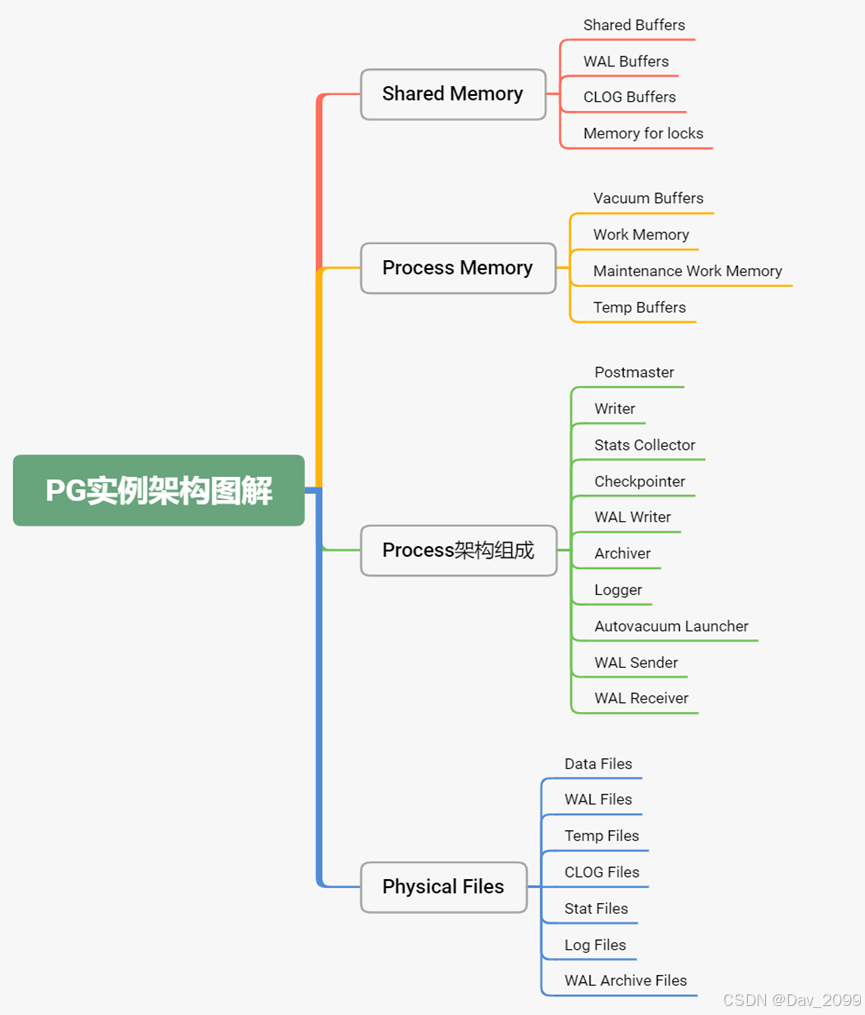
二。内存组件介绍
shared_buffers:
Sets the amount of memory the database server uses for shared memory buffers. The default
is typically 128 megabytes (128MB), but might be less if your kernel settings will not support
it (as determined during initdb). This setting must be at least 128 kilobytes. However, settings
significantly higher than the minimum are usually needed for good performance. If this value is
specified without units, it is taken as blocks, that is BLCKSZ bytes, typically 8kB. (Non-default
values of BLCKSZ change the minimum value.) This parameter can only be set at server start.
If you have a dedicated database server with 1GB or more of RAM, a reasonable starting val-
ue for shared_buffers is 25% of the memory in your system. There are some workloads
where even larger settings for shared_buffers are effective, but because PostgreSQL al-
so relies on the operating system cache, it is unlikely that an allocation of more than 40%
of RAM to shared_buffers will work better than a smaller amount. Larger settings for
shared_buffers usually require a corresponding increase in max_wal_size, in order to
spread out the process of writing large quantities of new or changed data over a longer period
of time.
On systems with less than 1GB of RAM, a smaller percentage of RAM is appropriate, so as to
leave adequate space for the operating system.
设置数据库服务器用于共享内存缓冲区的内存量。默认值通常为 128 MB(),但如果内核设置不支持它(在 initdb 期间确定),则默认值可能会更小。此设置必须至少为 128 KB。但是,通常需要明显高于最小值的设置才能获得良好的性能。如果指定此值时没有单位,则将其视为块,即字节,通常为 8kB。(更改最小值的非默认值。此参数只能在服务器启动时设置。
如果您有一个具有 1GB 或更多 RAM 的专用数据库服务器,则合理的起始值是系统中内存的 25%。在某些工作负载中,甚至更大的设置也是有效的,但由于 PostgreSQL 也依赖于操作系统缓存,因此分配超过 40% 的 RAM 不太可能比分配较小的 RAM 效果更好。较大的设置通常需要相应增加 ,以便在较长的时间段内分散写入大量新数据或更改数据的过程。
在 RAM 小于 1GB 的系统上,较小百分比的 RAM 是合适的,以便为操作系统留出足够的空间。
共享缓冲区充当所有 1O 操作的缓存。该进程对共享缓冲区进行读取和写入。当进程需要读取元组 (一条记录)时,它会前往共享缓冲区来获取它;通常,频繁访问的数据存储在共享缓冲区中,通过从内存读取,该过程可显着减少磁盘读取所消耗的时间 (仅当数据不存在于共享缓冲区中时才会发生磁盘读取),从而提高整体性能和响应时间。
huge_pages:
Controls whether huge pages are requested for the main shared memory area. Valid values are
try (the default), on, and off. With huge_pages set to try, the server will try to request
huge pages, but fall back to the default if that fails. With on, failure to request huge pages will
prevent the server from starting up. With off, huge pages will not be requested.
At present, this setting is supported only on Linux and Windows. The setting is ignored on other
systems when set to try. On Linux, it is only supported when shared_memory_type is set
to mmap (the default).
The use of huge pages results in smaller page tables and less CPU time spent on memory man-
agement, increasing performance. For more details about using huge pages on Linux
Huge pages are known as large pages on Windows. To use them, you need to assign the user
right “Lock pages in memory” to the Windows user account that runs PostgreSQL. You can use
Windows Group Policy tool (gpedit.msc) to assign the user right “Lock pages in memory”. To
start the database server on the command prompt as a standalone process, not as a Windows
service, the command prompt must be run as an administrator or User Access Control (UAC)
must be disabled. When the UAC is enabled, the normal command prompt revokes the user right
“Lock pages in memory” when started.
Note that this setting only affects the main shared memory area.
Operating systems such as Linux,FreeBSD, and Illumos can also use huge pages (also known as “super” pages or “large” pages)
automatically for normal memory allocation, without an explicit request from PostgreSQL.
On Linux, this is called “transparent huge pages” (THP). That feature has been known to cause per-formance degradation with PostgreSQL for some users on some Linux versions, so its use is cur-rently discouraged (unlike explicit use of huge_pages).
huge_page_size:
Controls the size of huge pages, when they are enabled with huge_pages. The default is zero (). When set to , the default huge page size on the system will be used. This parameter can only be set at server start.00
Some commonly available page sizes on modern 64 bit server architectures include: and (Intel and AMD), and (IBM POWER), and , , and (ARM). For more information about usage and support.
Non-default settings are currently supported only on Linux.
temp_buffers :
Sets the maximum amount of memory used for temporary buffers within each database session.
These are session-local buffers used only for access to temporary tables. If this value is specified
without units, it is taken as blocks, that is BLCKSZ bytes, typically 8kB. The default is eight
megabytes (8MB). (If BLCKSZ is not 8kB, the default value scales proportionally to it.) This
setting can be changed within individual sessions, but only before the first use of temporary tables
within the session; subsequent attempts to change the value will have no effect on that session.
A session will allocate temporary buffers as needed up to the limit given by temp_buffers.
The cost of setting a large value in sessions that do not actually need many temporary buffers
is only a buffer descriptor, or about 64 bytes, per increment in temp_buffers. However if a
buffer is actually used an additional 8192 bytes will be consumed for it (or in general, BLCKSZ
bytes).
max_prepared_transactions:
Sets the maximum number of transactions that can be in the “prepared” state simultaneously (see PREPARE TRANSACTION). Setting this parameter to zero (which is the default) disables the prepared-transaction feature. This parameter can only be set at server start.
If you are not planning to use prepared transactions, this parameter should be set to zero to prevent accidental creation of prepared transactions. If you are using prepared transactions, you will probably want to be at least as large as max_connections, so that every session can have a prepared transaction pending.
When running a standby server, you must set this parameter to the same or higher value than on the primary server. Otherwise, queries will not be allowed in the standby server.
work_mem :
Sets the base maximum amount of memory to be used by a query operation (such as a sort or hash table) before writing to temporary disk files. If this value is specified without units, it is taken as kilobytes. The default value is four megabytes (4MB). Note that a complex query might perform several sort and hash operations at the same time, with each operation generally being allowed to use as much memory as this value specifies before it starts to write data into temporary files.
Also, several running sessions could be doing such operations concurrently. Therefore, the total
memory used could be many times the value of work_mem; it is necessary to keep this fact in
mind when choosing the value. Sort operations are used for ORDER BY, DISTINCT, and merge
joins. Hash tables are used in hash joins, hash-based aggregation, memoize nodes and hash-based processing of IN subqueries.
Hash-based operations are generally more sensitive to memory availability than equivalent sort-
based operations. The memory limit for a hash table is computed by multiplying work_mem by
hash_mem_multiplier. This makes it possible for hash-based operations to use an amount
of memory that exceeds the usual work_mem base amount.
执行器使用此区域通过 ORDER BY 和 DISTINCT操作对元组进行排序,并通过合并连接和散列连接操作连接表;
wal buffer:WAL 是 Postgres 的弹性方法,在系统崩溃或故障时,WAL 用于恢复未提交的事务,从而保护数据库的完整性。 WAL 被写入磁盘,为了提高 WAL 的性能,利用了 WAL 缓冲区。后台进程写入 WAL 缓冲区,这些缓冲区会在每次提交时同步写入磁盘,或者定期异步写入磁盘。
Clog buffer:
提交日志(CLOG) 为并发控制 (CC) 机制保留所有事务的状态(例如,进行中、已提交、中止);
Maintenance_work_mem:
某些类型的维护操作 (例如 VACUUM. REINDEX) 使用此区域。
temp_buffers:
执行器使用该区域来存储临时表;
三. pg进程简介
3.1 前台进程
-
Postmaster 主进程
-
职责: 负责启动和关闭数据库实例,管理其他后台进程。
-
功能: 监听连接请求,派生新的服务进程处理客户端请求。
-
-
服务进程 (Postgres)
-
职责: 处理客户端连接和 SQL 查询。
-
功能: 每个客户端连接对应一个服务进程,负责解析、优化和执行 SQL 语句,并返回结果。
-
3.2 后台进程
-
写进程 (Writer Process)
-
职责: 将脏页从共享缓冲区写入磁盘。
-
功能: 定期或在缓冲区满时执行写操作,确保数据持久性。
-
-
预写日志写进程 (WAL Writer)
-
职责: 将预写日志(WAL)缓冲区的内容写入磁盘。
-
功能: 确保事务日志在事务提交前写入磁盘,保障数据一致性。
-
-
检查点进程 (Checkpointer)
-
职责: 执行检查点操作。
-
功能: 定期或在特定条件下将脏页写入磁盘,并更新控制文件中的检查点信息。
-
-
归档进程 (Archiver)
-
职责: 归档 WAL 文件。
-
功能: 在启用 WAL 归档时,将已填充的 WAL 文件复制到归档目录,用于备份和恢复。
-
-
统计信息收集进程 (Stats Collector)
-
职责: 收集数据库统计信息。
-
功能: 收集表和索引的访问统计信息,用于查询优化和监控。
-
-
自动清理进程 (Autovacuum Launcher)
-
职责: 启动自动清理工作进程。
-
功能: 定期检查需要清理的表,并启动清理进程以回收空间和更新统计信息。
-
-
自动清理工作进程 (Autovacuum Worker)
-
职责: 执行实际的清理操作。
-
功能: 清理表中的死元组,更新统计信息,优化性能。
-
-
日志收集进程 (Logger)
-
职责: 收集和写入数据库日志信息。
-
功能: 将日志信息写入日志文件,用于故障排查和审计。
-
-
复制进程 (WAL Sender 和 WAL Receiver)
-
职责: 管理主从复制。
-
功能: WAL Sender 将 WAL 记录发送到从库,WAL Receiver 接收并应用这些记录。
-
-
并行查询进程 (Parallel Worker)
-
职责: 执行并行查询任务。
-
功能: 在并行查询中,多个工作进程协同处理查询任务,提升性能。
-
四. 数据文件结构
这个安装后所见即所得,在此不再赘述。