【论文学习】超越自注意力:用于视觉任务的两种线性层外部注意力
arXiv2105.02358v2
前言:不知道什么是外注意力,找了相关论文,学习一下外注意力机制。
有点意思!

超越自注意力:用于视觉任务的两种线性层外部注意力
郭梦豪,刘正宁,穆台江,胡石敏,IEEE高级会员,
摘要: 注意力机制,尤其是自注意力,在视觉任务的深度特征表示中发挥着越来越重要的作用。自注意力通过计算所有位置之间的成对亲和力来更新每个位置的特征,以捕获单个样本内的长距离依赖关系。然而,自注意力具有二次复杂度,并且忽略了不同样本之间的潜在相关性。本文提出了一种新的注意力机制,我们称之为外部注意力,基于两个外部的小型、可学习、共享的内存,可以通过简单地使用两个级联的线性层和两个归一化层来实现;它可以方便地替换现有流行架构中的自注意力。外部注意力具有线性复杂度,并隐式地考虑了所有数据样本之间的相关性。我们进一步将多头机制结合到外部注意力中,为图像分类提供了一个全MLP架构,外部注意力MLP(EAMLPL)。在图像分类、目标检测、语义分割、实例分割、图像生成和点云分析上的大量实验表明,我们的方法提供了与自注意力机制及其一些变体相当或更好的结果,但计算和内存成本要低得多。
索引词-深度学习,计算机视觉,注意力,Transformer,多层感知器。
1引言
由于凭借其捕捉长距离依赖的能力,自注意力机制有助于提高各种自然语言处理 [1], [2] 和计算机视觉 [3], [4] 任务的性能。自注意力机制通过聚合单个样本中所有其他位置的特征来细化每个位置的表示,这导致样本中位置数量的二次计算复杂度。因此,一些变体试图以更低的计算成本 [5], [6], [7], [8] 近似自注意力机制。
此外,自注意力机制专注于单个样本内不同位置之间的自相似性,而忽略与其他样本的潜在相关性。很容易看出,结合不同样本之间的相关性可以帮助改进特征表示。例如,属于同一类别但分布在不同样本中的特征应在语义分割任务中一致处理,图像分类和各种其他视觉任务中也适用类似的观察结果。
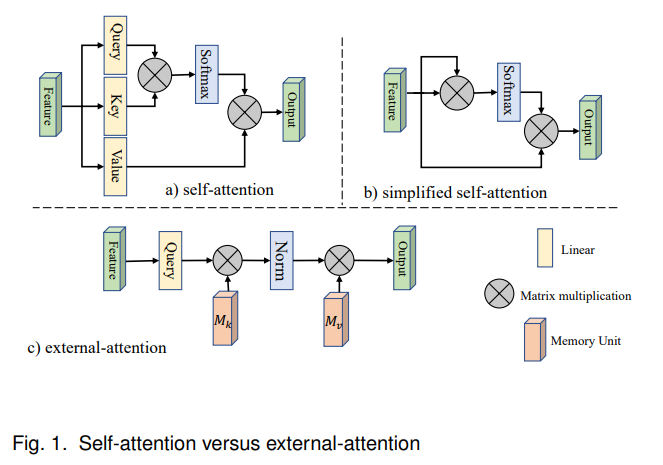
本文提出了一种新型轻量级注意力机制,我们称之为外部注意力(见图1c)。如图1a)所示,计算自注意力需要首先通过计算自查询向量和自键向量之间的亲和度来计算注意力图,然后通过用该注意力图对自值向量进行加权来生成新的特征图。外部注意力工作方式不同。我们首先通过计算自查询向量和外部可学习键内存之间的亲和度来计算注意力图,然后通过将此注意力图与另一个外部可学习值内存相乘来生成精细化的特征图。
在实践中,这两个记忆通过线性层实现,因此可以通过端到端的反向传播进行优化。它们独立于单个样本并在整个数据集上共享,这起到了强大的正则化作用,并提高了注意力机制泛化能力。外部注意力轻量化的关键在于记忆中的元素数量远小于输入特征的元素数量,从而使得计算复杂度与输入元素数量呈线性关系。外部记忆被设计用来学习整个数据集中最具有判别性的特征,捕捉最信息丰富的部分,同时排除来自其他样本的干扰信息。类似的想法可以在稀疏编码[9]或字典学习[10]中找到。然而,与那些方法不同,我们既不尝试重建输入特征,也不对注意力图应用任何显式的稀疏正则化。
尽管所提出的外部注意力方法简单,但它对各种视觉任务都很有效。由于其简单性,它可以很容易地集成到现有的流行基于自注意力的架构中,例如DANet [4],SAGAN [11]和T2T-Transformer [12]。图3展示了一个典型的架构,它用我们的外部注意力替换了自注意力,用于图像语义分割任务。我们在分类、目标检测、语义分割和实例分割与生成等基本视觉任务上进行了广泛的实验,输入模态不同(图像和点云)。结果表明,我们的方法在远低于计算成本的情况下,实现了与原始自注意力机制及其一些变体相当或更好的结果。
为了学习相同输入的不同方面,我们将多头机制整合到外部注意力中,提升其能力。受益于所提出的多头外部注意力机制,我们设计了一种名为EAMLPL的新型全MLP架构,它在图像分类任务中与CNNs和原始Transformers相当。
本文的主要贡献总结如下:
• 一种新的注意力机制,外部注意力,具有 O(n)O(n)O(n) 复杂度;它可以替换现有架构中的自注意力机制。它可以挖掘整个数据集之间的潜在关系,发挥强大的正则化作用,并提高注意力机制的一般化能力。
- 多头外部注意力,使我们能够构建一个全MLP架构;它在ImageNet-1K数据集上实现了 79.4%79.4\%79.4% 的top1准确率。
- 广泛使用外部注意力进行图像分类、目标检测、语义分割、实例分割、图像生成、点云分类和点云分割的实验。在必须保持计算量较低的场景中,它比原始自注意力机制及其一些变体取得了更好的结果。
2相关工作
由于注意力机制的全面综述超出了本文的范围,我们仅讨论与视觉领域最密切相关的文献。
2.1视觉任务中的注意力机制
注意力机制可以被视为根据激活的重要性重新分配资源的机制。它在人类视觉系统中发挥着重要作用。在过去的十年中,该领域取得了蓬勃发展 [3], [13], [14], [15], [16], [17], [18]。Hu等人提出了SENet [15], ,表明注意力机制可以减少噪声并提高分类性能。随后,许多其他论文将其应用于视觉任务。Wang等人提出了用于视频理解的非局部网络 [3],Hue等人 [19]将注意力机制用于目标检测,Fu等人提出了用于语义分割的DANet [4],Zhang等人 [11]证明了注意力机制在图像生成中的有效性,Xie等人提出了用于点云处理的A-SCN [20]。
2.2 自注意力在视觉任务中
自注意力机制是注意力机制的一种特殊情况,许多论文[3], [4], [11], [17], [21], 已经考虑了自注意力机制用于视觉。自注意力机制的核心思想是计算特征之间的亲和力,以捕获长距离依赖关系。然而,随着特征图大小的增加,计算和内存开销呈平方级增长。为了减少计算和内存成本,Huang等人[5]提出了交叉注意力机制,该机制依次考虑行注意力和列注意力以捕获全局上下文。Li等人[6]采用了期望最大化(EM)聚类来优化自注意力机制。Yuan等人[7]提出了使用对象上下文向量来处理注意力;然而,它依赖于语义标签。Geng 等人 [8] 表明矩阵分解是语义分割和图像生成中建模全局上下文的更好方法。其他工作 [22], [23] 也探索了通过使用自注意力机制来提取局部信息。
与自注意力通过计算自查询和自键之间的亲和力来获得注意力图不同,我们的外部注意力计算自查询与一个更小的可学习键内存之间的关系,该内存捕获了数据集的全局上下文。外部注意力不依赖于语义信息,可以通过反向传播算法以端到端的方式优化,而不是需要迭代算法。
2.3 Transformer在视觉任务中
基于Transformer的模型在自然语言处理[1], [2], [16], [24], [25], [26], [27]中取得了巨大成功。最近,它们也展示了在视觉任务中的巨大潜力。Carion等人 [28] 提出了一种端到端的检测Transformer,它将CNN特征作为输入,并使用Transformer生成边界框。Dosovitskiy [18]基于块编码和Transformer提出了ViT,表明在有足够训练数据的情况下,Transformer比传统CNN提供更好的性能。
Chen等人 [29] 基于使用Transformer提出了用于图像生成的iGPT。
随后,transformer方法已被成功地应用于许多视觉任务,包括图像分类[12],[30],[31],[32],目标检测[33],低级视觉[34],语义分割[35],跟踪[36],视频实例分割[37],图像生成[38],多模态学习[39],目标重识别[40],图像描述[41], 点云学习 [42] 和自监督学习 [43]。读者可参考最近的综述 [44], [45], 以获得关于 transformer 方法在视觉任务中应用的更全面回顾。
3方法论
在本节中,我们首先分析原始的自注意力机制。然后我们详细介绍了我们定义注意力的新方法:外部注意力。它可以通过仅使用两个线性层和两个归一化层轻松实现,如算法1中所示。
3.1 自注意力机制和外部注意力
我们首先重新审视自注意力机制(见图1a)。给定一个输入特征图 F∈RN×dF \in \mathbb{R}^{N \times d}F∈RN×d ,其中 NNN 是元素数量(或图像中的像素数量)且 ddd 是特征维度数量,自注意力将输入线性投影到一个查询矩阵 Q∈RN×d′Q \in \mathbb{R}^{N \times d'}Q∈RN×d′ 、一个键矩阵 K∈RN×d′K \in \mathbb{R}^{N \times d'}K∈RN×d′ 和一个值矩阵 V∈RN×dV \in \mathbb{R}^{N \times d}V∈RN×d [16]。然后自注意力可以表示为:
A=(α)i,j=softmax(QKT),(1) A = (\alpha) _ {i, j} = \operatorname {s o f t m a x} \left(Q K ^ {T}\right), \tag {1} A=(α)i,j=softmax(QKT),(1)
Fo u t=AV,(2) F _ {\text {o u t}} = A V, \tag {2} Fo u t=AV,(2)
其中 A∈RN×NA \in \mathbb{R}^{N \times N}A∈RN×N 是注意力矩阵, αi,j\alpha_{i,j}αi,j 是第 iii 个和第 jjj 个元素之间的成对相似度。
自注意力机制的一个常见简化变体(图1b)直接从输入特征 FFF 计算注意力图,其公式为:
A=softmax(FFT),(3) A = \operatorname {s o f t m a x} \left(F F ^ {T}\right), \tag {3} A=softmax(FFT),(3)
Fout=AF.(4) F _ {o u t} = A F. \tag {4} Fout=AF.(4)
在此,注意力图通过在特征空间中计算像素级相似度获得,输出是输入的细化特征表示。
然而,即使简化后, O(dN2)O(dN^2)O(dN2) 的高计算复杂度也显著限制了自注意力机制的使用。输入像素数量的二次复杂度使得直接将自注意力机制应用于图像成为不可能。因此,先前工作 [18] 利用自注意力机制处理图像块而非单个像素,以减少计算量。
自注意力机制可以看作是使用自值的线性组合来细化输入特征。然而,我们是否真的需要 N×NN \times NN×N 个自注意力矩阵和 NNN 个元素自值矩阵在这个线性组合中,远非显而易见。此外,自注意力机制仅考虑数据样本内元素之间的关系,而忽略了不同样本间元素之间潜在的关系,这可能会限制自注意力机制的能力和灵活性。
因此,我们提出了一种名为外部注意力的新型注意力模块,该模块通过以下方式计算输入像素与外部内存单元 M∈RS×dM \in \mathbb{R}^{S \times d}M∈RS×d 之间的注意力:
A=(α)i,j=Norm(FMT),(5) A = (\alpha) _ {i, j} = \operatorname {N o r m} \left(F M ^ {T}\right), \tag {5} A=(α)i,j=Norm(FMT),(5)
Fout=AM.(6) F _ {o u t} = A M. \tag {6} Fout=AM.(6)
与自注意力不同, αi,j\alpha_{i,j}αi,j 在公式(5)中是第 iii 个像素与第 jjj 行 MMM 之间的相似度,其中 MMM 是一个与输入无关的可学习参数,它作为整个训练数据集的记忆。 AAA 是从这种学习到的数据集级先验知识中推断出的注意力图;它以与自注意力类似的方式进行了归一化(见第3.2节)。最后,我们通过 AAA 中的相似度更新来自 MMM 的输入特征。
在实践中,我们使用两个不同的内存单元 MkM_{k}Mk 和 MvM_{v}Mv 作为键和值,以增强网络的能力。这略微改变了外部注意力的计算方式。
A=Norm(FMkT),(7) A = \operatorname {N o r m} \left(F M _ {k} ^ {T}\right), \tag {7} A=Norm(FMkT),(7)
Fout=AMv.(8) F _ {o u t} = A M _ {v}. \tag {8} Fout=AMv.(8)
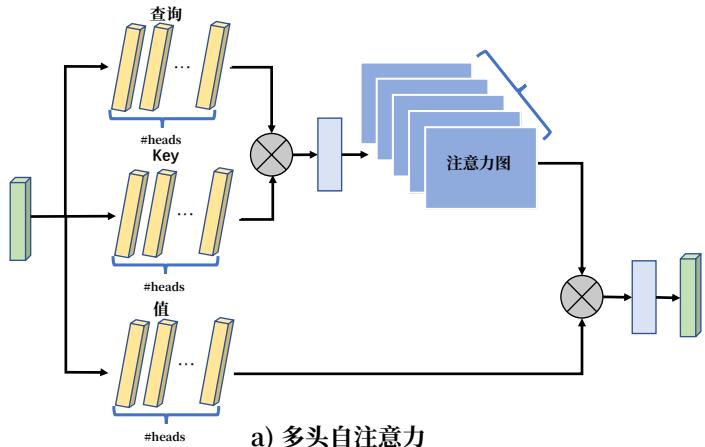
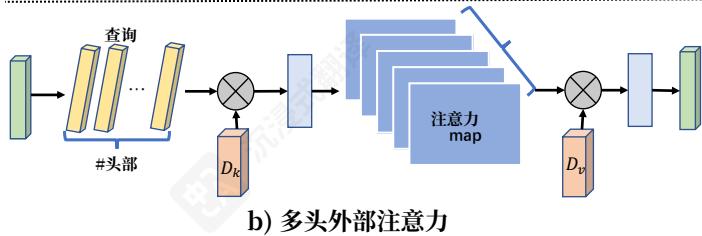
图2:多头自注意力和多头外部注意力。
外部注意力的计算复杂度是 O(dSN)O(dSN)O(dSN) ;由于 ddd 和 SSS 是超参数,所提出的算法在像素数量上是线性的。事实上,我们发现一个小的 SSS ,例如64,在实验中效果很好。因此,外部注意力比自注意力效率高得多,可以直接应用于大规模输入。我们还注意到,外部注意力的计算负载大致相当于一个 1×11 \times 11×1 卷积。

3.2归一化
Softmax在自注意力机制中被用于归一化注意力图,以便 ∑jαij=1\sum_{j}\alpha_{ij} = 1∑jαij=1 。然而,注意力图是通过矩阵乘法计算的。与余弦相似度不同,注意力图对输入特征的尺度敏感。为了避免这个问题,我们选择了[42],中提出的双重归一化方法,该方法分别归一化列和行。

图3.使用我们提出的外部注意力进行语义分割的EANet架构
这种双重归一化表示为:
(α~)i,j=FMkT(9) (\tilde {\alpha}) _ {i, j} = F M _ {k} ^ {T} \tag {9} (α~)i,j=FMkT(9)
α^i,j=exp(α~i,j)/∑kexp(α~k,j)(10) \hat {\alpha} _ {i, j} = \exp \left(\tilde {\alpha} _ {i, j}\right) / \sum_ {k} \exp \left(\tilde {\alpha} _ {k, j}\right) \tag {10} α^i,j=exp(α~i,j)/k∑exp(α~k,j)(10)
αi,j=α^i,j/∑kα^i,k(11) \alpha_ {i, j} = \hat {\alpha} _ {i, j} / \sum_ {k} \hat {\alpha} _ {i, k} \tag {11} αi,j=α^i,j/k∑α^i,k(11)
外注意力的python-style伪代码被列在算法1中。

3.3多头外部注意力
在Transformer [16], 自注意力机制中, 会在不同的输入通道上多次计算自注意力, 这被称为多头注意力。多头注意力可以捕捉不同 token 之间的关系, 提升了单头注意力的能力。我们使用与算法 2 和图 2 中类似的类似方法来实现多头外部注意力。
多头外部注意力可以表示为:
hi=E x t e r n a l A t t e n t i o n(Fi,Mk,Mv),(12)Fout=MultiHead(F,Mk,Mv)(13)=Concat(h1,…,hH)Wo,(14) \begin{array}{l} h _ {i} = \text {E x t e r n a l A t t e n t i o n} \left(F _ {i}, M _ {k}, M _ {v}\right), (12) \\ F _ {o u t} = \operatorname {M u l t i H e a d} (F, M _ {k}, M _ {v}) (13) \\ = \operatorname {C o n c a t} \left(h _ {1}, \dots , h _ {H}\right) W _ {o}, (14) \\ \end{array} hi=E x t e r n a l A t t e n t i o n(Fi,Mk,Mv),(12)Fout=MultiHead(F,Mk,Mv)(13)=Concat(h1,…,hH)Wo,(14)
其中 hih_ihi 是第 iii -个头, HHH 是头的数量, WoW_oWo 是一个线性变换矩阵,使得输入和输出的维度一致。 Mk∈RS×dM_k \in \mathbb{R}^{S \times d}Mk∈RS×d 和 Mv∈RS×dM_v \in \mathbb{R}^{S \times d}Mv∈RS×d 是不同头的共享内存单元。
这种架构的灵活性使我们能够在头 HHH 的数量和元素 SSS 的数量之间取得平衡
表1:PASCAL VOC val 集合上的消融研究
Norm:注意力中的归一化方法。#S:内存单元中的元素数量。OS:输出步长。
backbone. FCN 4d: 全卷积网络. SA: 自注意力.EA: external-attention. DoubleNorm: normalization depicted as Eq. 9
| 方法 | 骨干网络 | Norm | #S | OS | mIoU(%) |
| FCN | ResNet-50 | - | - | 16 | 75.7 |
| FCN + SA | ResNet-50 | Softmax | - | 16 | 76.2 |
| FCN + SA | ResNet-50 | DoubleNorm | - | 16 | 76.6 |
| FCN + EA | ResNet-50 | DoubleNorm | 8 | 16 | 77.1 |
| FCN + EA | ResNet-50 | DoubleNorm | 32 | 16 | 77.2 |
| FCN + EA | ResNet-50 | Softmax | 64 | 16 | 75.3 |
| FCN + EA | ResNet-50 | DoubleNorm | 64 | 16 | 77.4 |
| FCN + EA | ResNet-50 | DoubleNorm | 64 | 8 | 77.8 |
| FCN + EA | ResNet-50 | DoubleNorm | 256 | 16 | 77.0 |
| FCN + EA | ResNet-101 | DoubleNorm | 64 | 16 | 78.3 |
在共享内存单元中。例如,我们可以将 HHH 乘以 kkk ,同时将 SSS 除以 k∘k_{\circ}k∘
4实验部分
我们对图像分类、目标检测、语义分割、实例分割、图像生成、点云分类和点云分割任务进行了实验,以评估我们提出的外部注意力方法的有效性。所有实验均使用Jittor[86]和/或Pytorch[87]深度学习框架实现。
4.1消融实验
为了验证我们完整模型中提出的模块,我们在PASCAL VOC分割数据集[88]上进行了实验。图3描绘了用于消融实验的架构,该架构以FCN[46]作为特征骨干。批大小和总迭代次数分别设置为12和30,000。我们关注内存单元的数量、自注意力与外部注意力、骨干网络、归一化方法和骨干网络的输出步长。如表1所示,我们可以观察到外部注意力在Pascal VOC数据集上比自注意力提供了更高的精度。选择合适的内存单元数量对结果质量非常重要。归一化方法对外部注意力可以产生巨大的正面影响,并使自注意力得到改进。
4.2可视化分析
使用外部注意力进行分割的注意力图(见图3)和多头外部注意力用于分类
表2:在ImageNet上的实验
Top1:Top1准确率。EA:外部注意力。MEA:多头外部注意力。EAMLP:提出的全MLP架构。Failed:无法收敛。EAMLP-BN:在T2T-ViT主干MLP块中用BN替换LN(非外部注意力块)。
| 方法 | T2T-Transformer | T2T-Backbone | 输入大小 | #Heads | #内存单元 | #Params(M) | #吞吐量 | Top1(%) |
| T2T-ViT-7 | Performer | Transformer | 224 x 224 | 1 | - | 4.3 | 2133.3 | 67.4 |
| T2T-ViT-7 | Performer | Transformer | 224 x 224 | 4 | - | 4.3 | 2000.0 | 71.7 |
| T2T-ViT-14 | Performer | Transformer | 224 x 224 | 6 | - | 21.5 | 969.7 | 81.5 |
| T2T-ViT-14 | Transformer | Transformer | 224 x 224 | 6 | - | 21.5 | 800.0 | 81.7 |
| T2T-ViT-19 | Performer | Transformer | 224 x 224 | 6 | - | 39.2 | 666.7 | 81.9 |
| T2T-ViT-7 | EA | Transformer | 224 x 224 | 4 | - | 4.2 | 1777.8 | 71.7 |
| T2T-ViT-14 | EA | Transformer | 224 x 224 | 6 | - | 21.5 | 941.2 | 81.7 |
| T2T-ViT-7 | Performer | MEA | 224 x 224 | 1 | 256 | 4.3 | 2133.3 | 63.2 |
| T2T-ViT-7 | 表演者 | MEA | 224 x 224 | 4 | 256 | 5.9 | 1684.2 | 66.8 |
| T2T-ViT-7 | 表演者 | MEA | 224 x 224 | 16 | 64 | 6.2 | 1684.2 | 68.6 |
| T2T-ViT-7 | 表演者 | MEA | 384 x 384 | 16 | 64 | 6.3 | 615.4 | 70.9 |
| T2T-ViT-7 | 表演者 | MEA | 224 x 224 | 16 | 128 | 6.3 | 1454.5 | 69.9 |
| T2T-ViT-7 | 表演者 | MEA | 224 x 224 | 32 | 32 | 9.9 | 1280.0 | 70.5 |
| T2T-ViT-14 | 表演者 | MEA | 224 x 224 | 24 | 64 | 29.9 | 744.2 | 78.7 |
| T2T-ViT-19 | 表演者 | MEA | 224 x 224 | 24 | 64 | 54.6 | 470.6 | 79.3 |
| MLP-7 | MLP | MLP | 224 x 224 | - | - | 失败 | ||
| EAMLPP-7 | EA | MEA | 224 x 224 | 16 | 64 | 6.1 | 1523.8 | 68.9 |
| EAMLPP-BN-7 | EA | MEA(BN) | 224 x 224 | 16 | 64 | 6.1 | 1523.8 | 70.0 |
| EAMLPP-7 | EA | MEA | 384 x 384 | 16 | 64 | 6.2 | 542.4 | 71.7 |
| EAMLPP-14 | EA | MEA | 224 x 224 | 24 | 64 | 29.9 | 711.1 | 78.9 |
| EAMLPP-BN-14 | EA | MEA(BN) | 224 x 224 | 24 | 64 | 失败 | ||
| EAMLPP-19 | EA | MEA | 224 x 224 | 24 | 64 | 54.6 | 463.8 | 79.4 |
| EAMLPP-BN-19 | EA | MEA(BN) | 224 x 224 | 24 | 64 | 失败 |
在COCO目标检测数据集上的实验。引用的结果来自
来自[47]。框AP:框平均精度。
表3
| 方法 | 骨干网络 | 框AP |
| Faster RCNN [48] | ResNet-50 | 37.4 |
| Faster RCNN + 1EA | ResNet-50 | 38.5 |
| Mask RCNN [49] | ResNet-50 | 38.2 |
| Mask RCNN + 1EA | ResNet-50 | 39.0 |
| RetinaNet [50] | ResNet-50 | 36.5 |
| RetinaNet + 1EA | ResNet-50 | 37.4 |
| 级联 RCNN [51] | ResNet-50 | 40.3 |
| 级联 RCNN + 1EA | ResNet-50 | 41.4 |
| 级联 Mask RCNN [51] | ResNet-50 | 41.2 |
| 级联掩码 RCNN + 1EA | ResNet-50 | 42.2 |
在COCO实例分割数据集上的实验。引用的结果来自[47]。掩码AP:掩码平均精度。
表4
| 方法 | 骨干网络 | 遮罩AP |
| 遮罩RCNN [49] | ResNet-50 | 34.7 |
| 遮罩RCNN + 1EA | ResNet-50 | 35.4 |
| 级联RCNN [51] | ResNet-50 | 35.9 |
| Cascade RCNN + 1EA | ResNet-50 | 36.7 |
(见第4.3节)分别显示在图4和图5中。我们从层的内存单元 MkM_{k}Mk 中随机选择一行 MkiM_{k}^{i}Mki 。然后通过计算 MkiM_{k}^{i}Mki 对输入特征的注意力来描绘注意力图。我们观察到,学习到的注意力图像图4那样,专注于分割任务中的有意义的对象或背景。图5中的最后两行表明, MkM_{k}Mk 的不同行关注不同的区域。多头外部注意力的每个头都可以以不同的程度激活感兴趣的区域,如图5所示,从而改进表示
表5在PASCALVOC测试集上与最先进方法的比较(不使用COCO预训练)。
| 方法 | 骨干网络 | mIoU(%) |
| PSPNet [52] | ResNet-101 | 82.6 |
| DFN [53] | ResNet-101 | 82.7 |
| EncNet [54] | ResNet-101 | 82.9 |
| SANet [55] | ResNet-101 | 83.2 |
| DANet [4] | ResNet-101 | 82.6 |
| CFNet [56] | ResNet-101 | 84.2 |
| SpyGR [57] | ResNet-101 | 84.2 |
| EANet (Ours) | ResNet-101 | 84.0 |
在ADE20K验证集上与最先进方法的比较。
表6
| 方法 | 骨干网络 | mIoU(%) |
| PSPNet [52] | ResNet-101 | 43.29 |
| PSPNet [52] | ResNet-152 | 43.51 |
| PSANet [58] | ResNet-101 | 43.77 |
| EncNet [54] | ResNet-101 | 44.65 |
| CFNet [56] | ResNet-101 | 44.89 |
| PSPNet [52] | ResNet-269 | 44.94 |
| OCNet [17] | ResNet-101 | 45.04 |
| ANN [59] | ResNet-101 | 45.24 |
| DANet [4] | ResNet-101 | 45.26 |
| OCRNet [7] | ResNet-101 | 45.28 |
| EANet (Ours) | ResNet-101 | 45.33 |
外部注意力能力。
4.3图像分类
ImageNet-1K [89]是一个广泛使用的图像分类数据集。我们替换了 Performer [90]和多头

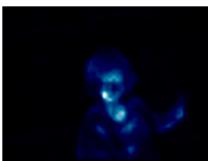










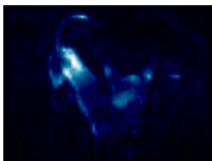
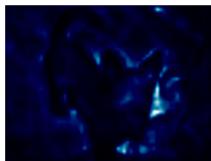


图4.PascalVOC测试集上的注意力图和分割结果。从左到右:输入图像、相对于外部内存中三个选定条目的注意力图、分割结果。
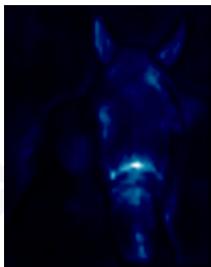
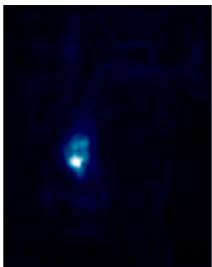


表7
在cityscapes验证集上与最先进方法的比较;引用的结果来自[60]。
| 方法 | 主干mIoU(%) | |
| EncNet [54] | ResNet-101 | 78.7 |
| APCNet [61] | ResNet-101 | 79.9 |
| ANN [59] | ResNet-101 | 80.3 |
| DMNet [62] | ResNet-101 | 80.7 |
| GCNet [63] | ResNet-101 | 80.7 |
| PSANet [58] | ResNet-101 | 80.9 |
| EMANet [6] | ResNet-101 | 81.0 |
| PSPNet [52] | ResNet-101 | 81.0 |
| DANet [4] | ResNet-101 | 82.0 |
| EANet (Ours) | ResNet-101 | 81.7 |
表8
在cifar-10数据集上与GAN方法的比较
| 方法 | FID | IS |
| DCGAN [64] | 49.030 | 6.638 |
| LSGAN [65] | 66.686 | 5.577 |
| WGAN-GP [66] | 25.852 | 7.458 |
| ProjGAN [67] | 33.830 | 7.539 |
| SAGAN [55] | 14.498 | 8.626 |
| EAGAN (Ours) | 14.105 | 8.630 |
T2T-ViT [12] 中的自注意力块为外部注意力和多头外部注意力。为了公平性,其他超参数设置与T2T-ViT相同。表2中的实验结果表明,外部注意力比 Performer [90] 取得了更好的结果,并且比多头注意力低约2个百分点。我们发现多头机
表 9 Tiny-ImageNet 数据集上与 GAN 方法的比较。
| 方法 | FID | IS |
| DCGAN [64] | 91.625 | 5.640 |
| LSGAN [65] | 90.008 | 5.381 |
| ProjGAN [67] | 89.175 | 6.224 |
| SAGAN [55] | 51.414 | 8.342 |
| EAGAN (Ours) | 48.374 | 8.673 |
nism 对自注意力机制和外部注意力机制都是必要的。我们还尝试了 MoCoV3 [43] 提出的策略,用 BatchNorm(BN) [92] 替换 T2T-ViT 主干中 MLP 模块(非外部注意力模块)的 LayerNorm(LN) [91]。我们在 EAMLP-7 上观察到 1%1\%1% 的提升,但在我们的 EAMLP-14 和 EAMLP-19 大模型上产生了失败案例。
4.4 目标检测和实例分割
MS COCO 数据集 [93] 是目标检测和实例分割的流行基准。它包含超过 20 万张图像,其中包含 80 个类别的超过 50 万个标注对象实例。
MMDetection [47] 是一个广泛使用的目标检测和实例分割工具包。我们使用 MMDetection(以 ResNet-50 主干)在 COCO 数据集上进行了目标检测和实例分割实验。我们只在 ResNet 阶段 4 的末尾添加了我们的外部注意力。表 3 和表 4 的结果表明,外部注意力机制在目标检测和实例分割任务上分别带来了约 1%1\%1% 的精度提升。






图5.EAMLP-14在ImageNet验证集上最后一层的多头注意力图。左:输入图像。其他:24头注意力图,用于ImageNet验证集上EAMLP-14的最后一层。最后两行: MkM_{k}Mk 中两行不同的注意力到图像块上。






使用ShaperNet部分分割数据集的比较。pIoU:部分平均交并比。引用的结果来自所引用的论文。
表10
| 方法 | pIoU | air- 平面包盖车椅 | ear- 电话 吉他 刀 灯 笔记本电脑 | 摩托车 马克杯 手枪 火箭 滑板 桌子 | ||||||
| PointNet [68] | 83.7 | 83.478.7 82.574.9 89.6 | 73.0 | 91.5 85.9 80.8 | 95.3 | 65.2 93.0 | 81.2 | 57.9 | 72.8 80.6 | |
| Kd-Net [69] | 82.3 | 80.174.6 74.370.3 88.6 | 73.5 | 90.2 87.2 81.0 | 94.9 | 57.4 86.7 | 78.1 | 51.8 | 69.9 80.3 | |
| SO-Net [70] | 84.9 | 82.8 77.8 88.0 77.3 90.6 | 73.5 | 90.7 83.9 82.8 | 94.8 | 69.1 94.2 | 80.9 | 53.1 | 72.9 83.0 | |
| PointNet++ [71] | 85.1 | 82.479.0 87.777.3 90.8 | 71.8 | 91.0 85.9 83.7 | 95.3 | 71.6 94.1 | 81.3 | 58.7 | 76.4 82.6 | |
| PCNN [72] | 85.1 | 82.480.1 85.579.5 90.8 | 73.2 | 91.3 86.0 85.0 | 95.7 | 73.2 94.8 | 83.3 | 51.0 | 75.0 81.8 | |
| DGCNN [73] | 85.2 | 84.083.4 86.777.8 90.6 | 74.7 | 91.2 87.5 82.8 | 95.7 | 66.3 94.9 | 81.1 | 63.5 | 74.5 82.6 | |
| P2Sequence [74] | 85.2 | 82.6 81.8 87.5 77.3 90.8 | 77.1 | 91.1 86.9 83.9 | 95.7 | 70.8 94.6 | 79.3 | 58.1 | 75.2 82.8 | |
| PointConv [75] | 85.7 | - - - - - - | - - - - - - | - - - - - - | - - - - - - | - - - - - - | - - - - - - | - - - - - - | ||
| PointCNN [76] | 86.1 | 84.186.5 86.080.8 90.6 | 79.7 | 92.3 88.4 85.3 | 96.1 | 77.2 95.2 | 84.2 | 64.2 | 80.0 83.0 | |
| PointASNL [77] | 86.1 | 84.184.7 87.979.7 92.2 | 73.7 | 91.0 87.2 84.2 | 95.8 | 74.4 95.2 | 81.0 | 63.0 | 76.3 83.2 | |
| RS-CNN [78] | 86.2 | 83.584.8 88.879.6 91.2 | 81.1 | 91.6 88.4 86.0 | 96.0 | 73.7 94.1 | 83.4 | 60.5 | 77.7 83.6 | |
| PCT [42] | 86.4 | 85.082.4 89.081.2 91.9 | 71.5 | 91.3 88.1 86.3 | 95.8 | 64.6 95.8 | 83.6 | 62.2 | 77.6 83.7 | |
| Ours | 86.5 | 85.185.7 90.381.6 91.4 | 75.9 | 92.1 88.7 85.7 | 96.2 | 74.8 95.7 | 84.3 | 60.2 | 76.2 83.5 | |

图6。使用我们的方法在cifar-10上生成的图像。
与ModelNet40分类数据集上的最先进方法进行比较。准确率:总体准确率。所有引用的结果均来自所引用的论文。P = 点,N = 法线。
表11
| 方法 | 输入 | #points | Accuracy |
| PointNet [68] | P | 1k | 89.2% |
| A-SCN [20] | P | 1k | 89.8% |
| SO-Net [70] | P, N | 2k | 90.9% |
| Kd-Net [69] | P | 32k | 91.8% |
| PointNet++ [71] | P | 1k | 90.7% |
| PointNet++ [71] | P, N | 5k | 91.9% |
| PointGrid [79] | P | 1k | 92.0% |
| PCNN [72] | P | 1k | 92.3% |
| PointWeb [80] | P | 1k | 92.3% |
| PointCNN [76] | P | 1k | 92.5% |
| PointConv [75] | P, N | 1k | 92.5% |
| A-CNN [81] | P, N | 1k | 92.6% |
| P2Sequence [74] | P | 1k | 92.6% |
| KPConv [82] | P | 7k | 92.9% |
| DGCNN [73] | P | 1k | 92.9% |
| RS-CNN [78] | P | 1k | 92.9% |
| PointASNL [77] | P | 1k | 92.9% |
| PCT [42] | P | 1k | 93.2% |
| EAT (Ours) | P | 1k | 93.4% |
4.5 语义分割
在本实验中,我们采用了图3中的语义分割架构,称之为EANet,并将其应用于Pascal VOC [88], ADE20K [94]和cityscapes [95]数据集。
Pascal VOC 包含 10,582 张图像用于训练,1,449 张图像用于验证和 1,456 张图像用于测试。它有 20 个前景对象类别和一个背景类别用于分割。我们使用了具有输出步长为 8 的扩张 ResNet-101 作为主干网络,所有比较的方法都是这样;它在 ImageNet-1K 上进行了预训练。在训练过程中采用了多项式学习率策略。初始学习率、批大小和输入大小设置为 0.009、16 和 513×513513 \times 513513×513 。我们首先在训练集上训练了 45k 次迭代,然后在 trainval 集上微调了 15k 次迭代。最后我们在测试集上使用了多尺度和翻转测试。可视化结果如图 4 所示,定量结果见表 5:我们的方法可以实现与最先进方法相当的性能。
ADE20K 是一个更具挑战性的数据集,有 150 个类别,分别有 20K、2K 和 3K 张图像用于训练、验证和测试。我们采用了具有输出步长为 8 的扩张 ResNet-101 作为主干网络。实验配置与 mmsegmentation [60], training ADE20K for 160k 次迭代相同。表 6 中的结果表明我们的方法在 ADE20K val 集上优于其他方法。
Cityscapes 包含 5,000 个高质量像素级精细标注的标签,用于城市场景理解。每张图像是 1024×20481024 \times 20481024×2048 像素。它被分为 2,975、500 和 1,525 张图像用于训练、验证和测试。
(它还包含20,000张粗略标注的图像,我们未在实验中使用)。我们采用扩张ResNet-101,输出步长为8,作为所有方法的骨干。实验配置与mmsegmentation相同,使用80k次迭代训练cityscapes。表7的结果表明,我们的方法在cityscapes val集上实现了与最先进方法相当的结果,即DANet [4]。
4.6图像生成
自注意力机制在图像生成中常用,代表性方法是SAGAN[11]。我们将SAGAN中的自注意力机制替换为我们的外部注意力方法,以获得我们的EAGAN模型。所有实验基于流行的PyTorch-StudioGAN仓库[96]。超参数使用SAGAN的默认配置。我们使用Frechet Inception Distance (FID) [97]和Inception Score (IS) [98]作为我们的评估指标。一些生成的图像显示在图6中,定量结果给出在表8和表9中:外部注意力比SAGAN和一些其他GAN提供更好的结果。
4.7点云分类
ModelNet40 [99] 是一个流行的3D形状分类基准,包含40个类别的12,311个CAD模型。它有9,843个训练样本和2,468个测试样本。我们的EAT模型替换了PCT [42]中的所有自注意力模块。我们在每个形状上采样了1024个点,并使用随机平移、各向异性缩放和dropout对输入进行增强,遵循PCT [42]。表11表明我们的方法优于所有其他方法,包括其他基于注意力的方法如PCT。我们提出的方法为2D和3D视觉都提供了出色的骨干。
4.8点云分割
我们在ShapeNet part数据集[100]上进行了点云分割实验。训练集中有14,006个3D模型,评估集中有2,874个。每个形状都被分割成部分,总共有16个对象类别和50个部分标签。我们遵循了PCT[42]中的实验设置。EAT在这个数据集上取得了最佳结果,如表10所示。
4.9计算需求
相对于输入大小的线性复杂度带来了显著的优势效率。我们
表12与自注意力及其变体的计算需求比较。MACs:乘加操作。
| 方法 SA [16] DA [4] A2[83] APC [61] DM [84] ACF [85] Ham [8] EA (我们) | ||||||
| 参数 1.00M 4.82M 1.01M | 2.03M | 3.00M | 0.75M | 0.50M | 0.55M | |
| MACs 292G 79.5G 25.7G | 17.6G | 35.1G | 79.5G | 17.6G | 9.2G | |
将外部注意力(EA)模块与标准自注意力(SA)[16]及其几个变体在参数数量和推理操作方面进行了比较,输入大小为 1×512×128×1281 \times 512 \times 128 \times 1281×512×128×128 ,结果如表12所示。外部注意力只需要自注意力所需参数的一半,并且速度快32倍。与最佳变体相比,外部注意力仍然快约两倍。
5结论
本文介绍了外部注意力机制,这是一种新颖的轻量级且有效的注意力机制,适用于各种视觉任务。外部注意力机制中采用的两个外部内存单元可以被视为整个数据集的字典,并且能够在降低计算成本的同时学习更具代表性的输入特征。我们希望外部注意力机制能够启发其在其他领域(如自然语言处理)的实际应用和研究。