【MIT-OS6.S081作业1.5】Lab1-utilities xargs
本文记录MIT-OS6.S081 Lab1 utilities 的xargs函数的实现过程
文章目录
- 1. 作业要求
- xargs(moderate)
- 2. 实现过程
- 2.1 代码实现
- 附录:fork下我们为什么不用深拷贝呢,既然不用深拷贝,那么子进程会深拷贝父进程是嘛?
- 形象地理解 `fork()` (在 xv6 中)
- 这就是为什么不需要 `deepMalloc`
1. 作业要求
xargs(moderate)
Write a simple version of the UNIX xargs program: read lines from the standard input and run a command for each line, supplying the line as arguments to the command. Your solution should be in the file user/xargs.c.
Some hints:
- Use fork and exec to invoke the command on each line of input. Use wait in the parent to wait for the child to complete the command.
- To read individual lines of input, read a character at a time until a newline (‘\n’) appears.
- kernel/param.h declares MAXARG, which may be useful if you need to declare an argv array.
- Add the program to UPROGS in Makefile.
- Changes to the file system persist across runs of qemu; to get a clean file system run make clean and then make qemu.
$ make qemu
…
init: starting sh
$ sh < xargstest.sh
$ $ $ $ $ $ hello
hello
hello
$ $
…
2. 实现过程
根据hint我们可以梳理出基本的步骤:
- 解析 xargs 自身的参数,确定要执行的命令和其初始参数。
- 循环读取标准输入的每一行,作为额外参数。
- 对每行,组合 “命令 + 初始参数 + 行内容” 为完整参数列表。
- 用 fork + exec 执行命令,父进程等待子进程完成后继续处理下一行。
2.1 代码实现
重点是解析xargs自身的参数,这里完整的参数列表定义为:
char* realArgv[MAXARG];
我们知道argv[0]是xargs,我们要传递给exec的参数应该从argv[1]开始,遍历i从1 到 (argc - 1),将argv[i]依次赋值给realArgv的元素,这里使用了一个char**的argvPtr 指针来指向realArgv数组的元素。 这样我们就处理完了初始参数。
然后我们解析从标准输入传过来的行内容的参数,这里分情况讨论:
- 获取的字符是’\n’,当前的命令行参数获取完毕,行参数最后添加’\0’,需要增加一个,并且增加一个命令行参数为0(NULL),并且执行exec。
- 获取的字符是’ ‘,当前的命令行参数获取完毕,行参数最后添加’\0’,需要增加一个。
- 获取的字符不是上面的两种情况,当前的命令行参数还没获取完毕。
#include "user/user.h"
#include "kernel/param.h"
#include "kernel/types.h"
#define bool uint8
#define true 1
#define false 0int main(int argc, char* argv[])
{char argvStr[1024];char* realArgv[MAXARG];char** argvPtr = realArgv;char** argvDiffPtr;char curChar = 'a';for (int i = 1; i < argc; ++i){*argvPtr = argv[i];argvPtr++;}argvDiffPtr = argvPtr;char* argvStrPtr = argvStr;char* argvStrCurArgvPtr = argvStr;bool canRun = false;while (read(0, argvStrPtr, 1) > 0){if (curChar == ' ' || curChar == '\n'){if (curChar == '\n') canRun = true;*argvStrPtr = '\0';*argvPtr = argvStrCurArgvPtr;argvStrCurArgvPtr= argvStrPtr + 1;argvPtr++;}if (canRun){*argvPtr = 0;canRun = false;argvPtr = argvDiffPtr;int ret = fork();if (ret == 0){exec(argv[1], realArgv);exit(0);}}}while (wait(0) != -1) {}exit(0);}
这里写的是一次性把所有的exec派发给子进程,然后在外面用while (wait(0) != -1) {}等待所有的子进程结束。为了子进程能够运行,这里使用静态的char数组argvStr存放从标准输入传过来的命令行参数,不同参数之间用’\0’间隔,我们看一下argvStr的布局,假如命令行读取的参数是12\n34\n45\n,而我们的xargs后面跟的是echo a,理论上我们应该得到:
a12
a34
a56
大概的逻辑为:
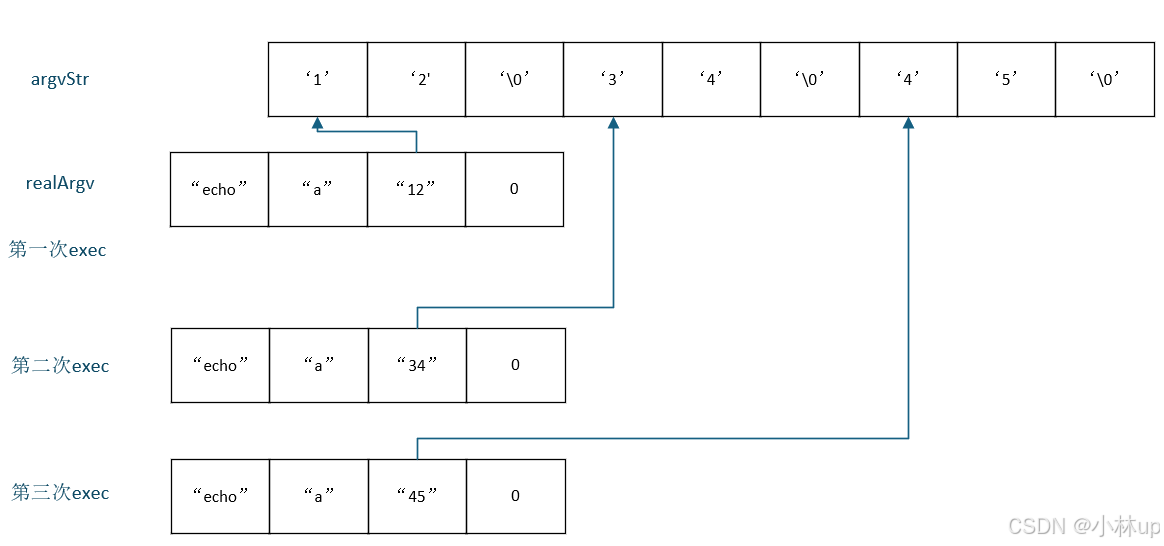
这里有个问题,就是执行完第一次的exec,argvStr的“12”参数其实没有用了,但是还会一直占着数组的位置,如果从输入传过的命令行参数特别多,那我们可能就得为argvStr数组开辟一个特别长的长度。一个思路是我们运行完一个exec,然后就从头开始赋值字符串,但是解析和执行exec都会操作数组,可能导致竞争发生,我们的exec可能会发生错乱(这里是我理解有问题,可以看再后面的代码,不过也记录一下深拷贝的实现,写得还是比较复杂的)。所以我们需要进行深拷贝,不仅拷贝指针,还要把指针指向的字符串也拷贝过去,于是我写了下面的代码,每一次exec以前先深拷贝,这里使用的是动态内存的写法,等到exec结束父进程再释放申请的动态内存。
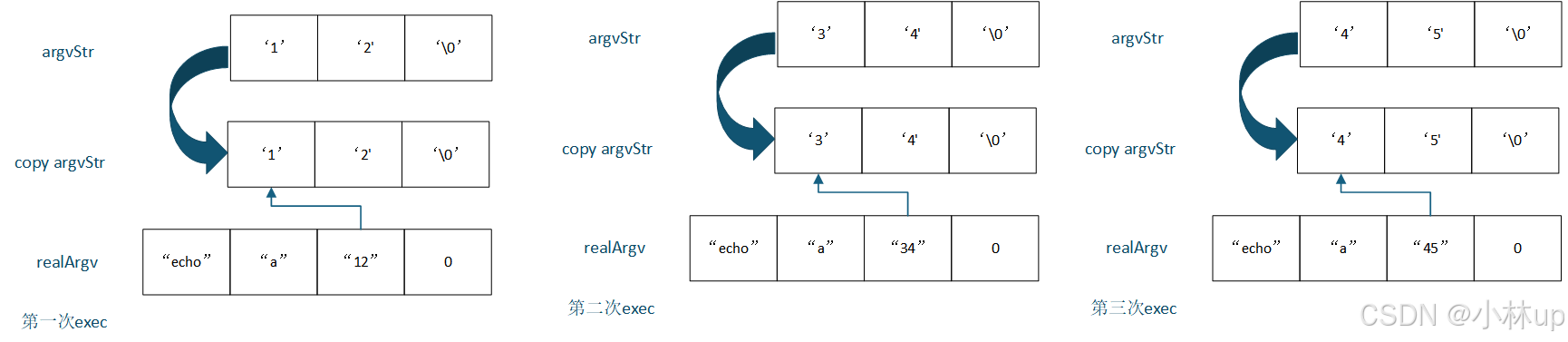
#include "user/user.h"
#include "kernel/param.h"
#include "kernel/types.h"
#define bool uint8
#define true 1
#define false 0void* Malloc(int mallocUnitSize, int mallocLen, bool* success)
{void* ptr = malloc(mallocUnitSize * mallocLen);if (ptr == 0){*success = false;}return ptr;
}void deepFree(char** argv, int argvCnt)
{char** argvPtr = argv;for (int i = 0; i < argvCnt; ++i){if (*argvPtr) free(*argvPtr);argvPtr++;}free(argv);
}char** deepMalloc(char** argvPtr, int argvCnt, bool* successMalloc)
{char** copyArgv = (char**) Malloc(sizeof(char*), argvCnt, successMalloc);if (*successMalloc == false) return 0;char** copyArgvPtr = copyArgv;for (int i = 0; i < argvCnt - 1; ++i){int strLen = strlen(*argvPtr) + 1;*copyArgvPtr = (char*) Malloc(sizeof(char), strLen, successMalloc);if (*successMalloc == false){deepFree(copyArgv, i);return 0;}strcpy(*copyArgvPtr, *argvPtr);++copyArgvPtr;++argvPtr;}*copyArgvPtr = 0;return copyArgv;
}int main(int argc, char* argv[])
{char argvStr[1024];char* realArgv[MAXARG];char** argvPtr = realArgv;char** argvDiffPtr;for (int i = 1; i < argc; ++i){*argvPtr = argv[i];argvPtr++;}argvDiffPtr = argvPtr;char* argvStrPtr = argvStr;char* argvStrCurArgvPtr = argvStr;bool canRun = false;while (read(0, argvStrPtr, 1) > 0){if (*argvStrPtr == ' ' || *argvStrPtr == '\n'){if (*argvStrPtr == '\n') canRun = true;*argvStrPtr = '\0';*argvPtr = argvStrCurArgvPtr;argvStrCurArgvPtr = argvStrPtr + 1;argvPtr++;}if (canRun){*argvPtr = 0;int realArgvCnt = argvPtr - realArgv + 1;bool canMalloc = true;char** copyRealArgv = deepMalloc(realArgv, realArgvCnt, &canMalloc);int ret = fork();if (ret == 0){if (canMalloc)exec(argv[1], copyRealArgv);exit(0);}else{wait(0);if (canMalloc)deepFree(copyRealArgv, realArgvCnt);argvPtr = argvDiffPtr;argvStrPtr = argvStr;argvStrCurArgvPtr = argvStr;canRun = false;}}else++argvStrPtr;}exit(0);}好吧,其实我这里有一个误区:当父进程循环回去准备读取下一行时,它会覆盖 argvStr 缓冲区,而此时子进程可能还在使用它。重新了解一下 fork() 的工作机制:
-
fork() 创建内存副本: 当调用 fork() 时,子进程会得到父进程内存的一个完整副本(在 xv6 中是这样,在现代 OS 中是“写时复制”,但效果类似)。
-
子进程有自己的 argvStr: 子进程得到的副本包括了你栈上的 argvStr[1024] 缓冲区和 realArgv[MAXARG] 数组。
-
exec() 使用副本: 子进程调用 exec() 时,它使用的是它自己的 realArgv 副本,这些指针指向的字符串(无论是来自原始的 argv 还是来自 argvStr 副本)在子进程的地址空间中都是完全有效的。
-
父进程安全地覆盖: 父进程调用 wait(),它会等待子进程完全退出(exec 成功或失败,然后 exit)。当 wait() 返回时,子进程已经彻底结束了。
-
循环复用: 此时,父进程循环回到 read,它可以安全地覆盖 argvStr 缓冲区来处理下一行输入,因为上一个子进程已经不再需要它了。
我们可以进一步简化代码,不用深拷贝了!

#include "user/user.h"
#include "kernel/param.h"
#include "kernel/types.h"
#define bool uint8
#define true 1
#define false 0
int main(int argc, char* argv[])
{char argvStr[1024];char* realArgv[MAXARG];char** argvPtr = realArgv;char** argvDiffPtr;for (int i = 1; i < argc; ++i){*argvPtr = argv[i];argvPtr++;}argvDiffPtr = argvPtr;char* argvStrPtr = argvStr;char* argvStrCurArgvPtr = argvStr;bool canRun = false;while (read(0, argvStrPtr, 1) > 0){if (*argvStrPtr == ' ' || *argvStrPtr == '\n'){if (*argvStrPtr == '\n') canRun = true;*argvStrPtr = '\0';*argvPtr = argvStrCurArgvPtr;argvStrCurArgvPtr = argvStrPtr + 1;argvPtr++;}if (canRun){*argvPtr = 0;int ret = fork();if (ret == 0){exec(realArgv[0], realArgv);exit(0);}else{wait(0);argvPtr = argvDiffPtr;argvStrPtr = argvStr;argvStrCurArgvPtr = argvStr;canRun = false;}}else++argvStrPtr;}exit(0);}
我们在Makefile里加入对这个函数的编译:
UPROGS=\$U/_cat\$U/_echo\$U/_forktest\$U/_grep\$U/_init\$U/_kill\$U/_ln\$U/_ls\$U/_mkdir\$U/_rm\$U/_sh\$U/_stressfs\$U/_usertests\$U/_grind\$U/_wc\$U/_zombie\$U/_sleep\ $U/_pingpong\ $U/_primes\ $U/_find\ $U/_xargs\
重新编译通过,测试xargs,如题所述正确打印:
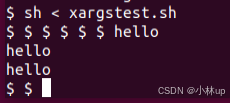
然后我们再使用作业所说的测试命令:
./grade-lab-util xargs

完活!还是要理解fork的含义!可以参考下面的附录~
附录:fork下我们为什么不用深拷贝呢,既然不用深拷贝,那么子进程会深拷贝父进程是嘛?
以下是询问AI得到的答案:
答案是: fork() 所做的,比你代码中的 deepMalloc(深拷贝一个数据结构)要强大得多。
- 你代码中的
deepMalloc是一个用户态操作:你遍历一个数组,在**堆(Heap)**上为每个字符串分配新内存,然后复制字符串内容。 fork()是一个内核态操作:内核创建了一个全新的进程,这个进程的整个虚拟地址空间(包括栈 Stack、堆 Heap 和所有数据)是父进程在fork()时刻的一个完整、独立的副本。
形象地理解 fork() (在 xv6 中)
想象一下 fork() 就像一个神奇的复印机:
-
按下
fork()按钮:- 父进程的内存里有:
- 栈 (Stack): 包含
argvStr[1024]缓冲区,里面存着 “hello\0world\0”;还包含realArgv数组,其指针指向argvStr内部(例如,指向 “hello” 和 “world”)。 - 堆 (Heap): (在你的深拷贝版本中,这里有
malloc来的内存)。 - 代码段 (Code): 你的程序指令。
- 栈 (Stack): 包含
- 父进程的内存里有:
-
复印机工作:
- 内核(复印机)为子进程分配全新的物理内存。
- 内核把父进程的整个栈(包括
argvStr和realArgv)逐字节复制到子进程的新栈中。 - 内核把父进程的整个堆… 逐字节复制到子进程的新堆中。
- …等等。
-
fork()结束:- 现在你有两个独立的进程。
- 父进程有一个
argvStr缓冲区。 - 子进程有另一个完全相同但物理上分离的
argvStr缓冲区。 - 父进程修改它的
argvStr不会影响子进程的argvStr。 - 子进程修改它的
argvStr不会影响父进程的argvStr。
这就是为什么不需要 deepMalloc
因为 fork() 已经为你复制了 argvStr 缓冲区:
- 父进程:在
fork()之前,栈上的argvStr存着 “hello\0”。realArgv指向这个 “hello”。 fork()发生:- 子进程:诞生了。它自己的栈上也有一个
argvStr缓冲区,里面也存着 “hello\0”。它自己的realArgv也指向它自己的 “hello”。 - 子进程:调用
exec(realArgv[0], realArgv)。它使用的是它自己的realArgv和argvStr。 - 父进程:调用
wait(0)等待子进程结束。 - 父进程:
wait()返回后,循环回去,用read覆盖它自己的argvStr来读取下一行(比如 “world\0”)。
这个覆盖动作绝对安全,因为它覆盖的是父进程的内存。而子进程(此时已经 exec 或者退出了)使用的是它自己的、早已被复制走的内存副本。
总结:
你不需要 deepMalloc(在堆上做用户态深拷贝),因为 fork()(在内核态)已经为你做了整个进程内存的“深拷贝”(在xv6中是物理复制,在现代OS中是写时复制COW)。
你只需要使用栈上的 argvStr 缓冲区,fork() 会自动保证子进程得到一个安全的副本供其 exec 使用。