从 API 到应用:用 Rust 和 SQLx 为 Axum 服务添加持久化数据库
引言
在上一篇文章中,我们使用 Axum 框架构建了一个功能完备、结构清晰的 To-Do List API。它拥有优雅的错误处理、数据验证和日志系统,可以说是一个非常健壮的“骨架”。然而,它有一个在真实世界中堪称“致命”的弱点:所有的数据都依赖于服务进程的内存。这意味着,无论是计划内的更新部署,还是计划外的意外宕机,只要服务重启,所有用户的待办事项都会烟消云散。这对于任何期望提供稳定服务的应用来说,都是完全不可接受的。
本文是 robust_todo_api 项目的直接续篇,我们将正面迎击这个核心问题:数据持久化。我们将彻底告别存储在内存中的 HashMap,转而拥抱强大且开源的 PostgreSQL 关系型数据库。而连接我们 Rust 应用与数据库之间的桥梁,则是 Rust 生态中最受欢迎的异步 SQL 工具库 sqlx。通过这次升级,我们的 API 将蜕变为一个真正意义上的、能够持久存储数据的 Web 应用。
为什么是 SQLx?一场关于安全的哲学共鸣
在选择数据库工具时,我们并非只是简单地寻找一个“驱动程序”。我们寻求的是一个能够融入并增强我们现有技术栈核心价值的伙伴。sqlx 正是这样的伙伴。
它并不仅仅是一个数据库驱动,而是一个现代、完全异步的工具库。其最大的“杀手级”特性无疑是编译时查询检查。这是一个革命性的概念:通过一个名为 sqlx-cli 的可选工具,sqlx 可以在你编译 Rust 代码的阶段(cargo build 或 cargo check),就主动连接到你的开发数据库。它会逐一检查你的 SQL 语句,验证以下几点:
- SQL 语法是否正确? 杜绝了简单的拼写错误。
- 引用的表名、列名是否存在? 告别因数据库结构变更导致运行时错误的窘境。
- 查询返回的数据类型和数量,是否与你的 Rust 结构体类型完美匹配? 确保了数据在从数据库到应用的传递过程中类型安全无虞。
这个特性 incredible 地将数据库层面的、通常只有在运行时才能发现的错误,提前到了编译阶段。这与 Rust 语言本身的设计哲学——在编译时尽可能多地发现和消灭错误,从而保证运行时安全、可靠——形成了完美的共鸣。选择 sqlx,就是选择将 Rust 的安全边界延伸至数据库交互的每一个角落。
读完本文,你将不仅仅是学会了如何连接数据库,而是掌握了一整套现代化的后端开发工作流:
- 基础设施即代码:使用 Docker 快速、可复现地搭建本地开发数据库。
- Schema 版本控制:通过
sqlx-cli进行专业的数据库迁移(Migrations),让你的数据库结构像代码一样被追踪和管理。 - 高性能连接管理:在 Axum 应用中配置并管理异步数据库连接池,这是构建高并发服务的基础。
- 类型安全的数据库交互:使用
sqlx的编译时宏重构所有 API handler,实现与真实数据库的高效、安全交互。
让我们启程,为我们的应用注入真正的、永不磨灭的“记忆”!
第一步:环境准备 - 基础建设的艺术
在编写任何触及数据库的代码之前,我们需要一个稳定运行的 PostgreSQL 实例和一套称手的命令行工具。这是一个“磨刀不误砍柴工”的过程,坚实的基础设施将为后续的开发带来极大的便利。
-
使用 Docker 启动 PostgreSQL:一键启动你的专属数据库
在现代软件开发中,Docker 已经成为管理服务依赖的事实标准。它允许我们将应用(如此处的 PostgreSQL)及其所有依赖打包到一个轻量、可移植的“容器”中。这确保了无论是在你的 Mac、Windows 还是同事的 Linux 笔记本上,数据库环境都是完全一致的,从而彻底告别了“在我机器上是好的”这类经典难题。
如果你尚未安装 Docker,请先根据其官网指引完成安装。之后,打开你的终端,运行以下命令:
docker run --name robust-postgres -e POSTGRES_PASSWORD=password -e POSTGRES_USER=user -e POSTGRES_DB=todos -p 5432:5432 -d postgres让我们逐一解析这个命令的含义:
docker run: 这是启动一个新容器的基本命令。--name robust-postgres: 为这个容器赋予一个人类可读的名字。这样,将来我们可以用docker start robust-postgres或docker stop robust-postgres来轻松地启停它。-e ...:-e参数用于设置容器内的环境变量。这里我们设置了三个至关重要的变量,PostgreSQL 镜像在首次启动时会读取它们来完成初始化:POSTGRES_PASSWORD=password: 设置超级用户的密码。POSTGRES_USER=user: 创建一个名为user的新用户。POSTGRES_DB=todos: 创建一个名为todos的新数据库,并将其所有权赋予user用户。
-p 5432:5432: 这是端口映射。它将你本机(宿主机)的5432端口与容器内部的5432端口连接起来。5432是 PostgreSQL 的标准监听端口。这样设置后,我们本地的 Rust 应用就能通过连接localhost:5432来访问容器中的数据库了。-d: 代表 “detach”(分离模式)。这会让容器在后台运行,并将容器的 ID 打印出来,而不会占用你当前的终端会话。postgres: 这是我们要使用的 Docker 镜像的名称。Docker 会首先在本地查找postgres镜像,如果找不到,会自动从 Docker Hub(官方镜像仓库)拉取最新版本。
命令执行成功后,你可以通过
docker ps命令看到一个名为robust-postgres的容器正在运行,这意味着你的专属数据库已经准备就绪。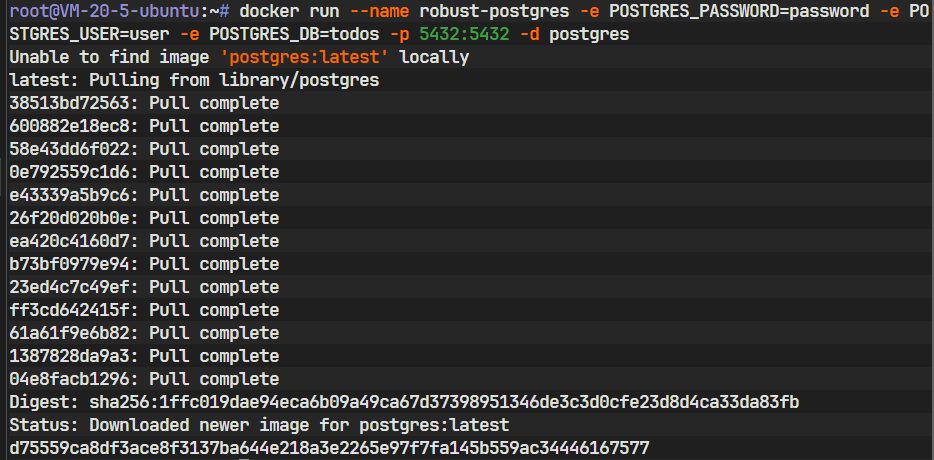
-
安装
sqlx-cli:你的数据库守护神sqlx-cli是sqlx生态系统的重要组成部分,它是一个独立的命令行工具,主要负责两件事:数据库迁移管理和辅助编译时检查。我们将使用 cargo 来安装它:cargo install sqlx-cli这个命令会将
sqlx-cli安装到你的 cargo二进制文件目录(通常是~/.cargo/bin),使其成为一个全局可用的命令。
注意:潜在的编译障碍
sqlx-cli在编译时需要链接到 PostgreSQL 的客户端库(通常称为libpq)。这是一个 C 语言库,提供了与 PostgreSQL 服务器通信的基础功能。如果你的系统上缺少这个库的开发文件(头文件等),cargo install可能会失败。根据你的操作系统,解决方法如下:
- Ubuntu/Debian:
sudo apt-get install libpq-dev - CentOS/Fedora/RHEL:
sudo yum install postgresql-devel或sudo dnf install postgresql-devel - macOS (使用 Homebrew):
brew install libpq(可能还需要手动将其路径添加到环境变量中,请遵循 brew 的提示)
- Ubuntu/Debian:
-
创建
.env文件:安全配置的基石将数据库连接字符串、API 密钥等敏感信息硬编码在代码中是一种非常危险的做法。一个更好的实践是遵循“十二要素应用”(The Twelve-Factor App)的原则,将配置存储在环境中。
.env文件是一种在开发环境中模拟环境变量的便捷方式。在你的项目根目录(与
Cargo.toml同级)下,创建一个新文件,命名为.env,并写入以下内容:DATABASE_URL=postgres://user:password@localhost:5432/todos这个
DATABASE_URL是一个标准格式的连接URI,sqlx和许多其他数据库工具都能识别它。它的结构是:postgres://<用户名>:<密码>@<主机>:<端口>/<数据库名>。这与我们之前在docker run命令中设置的环境变量完全对应。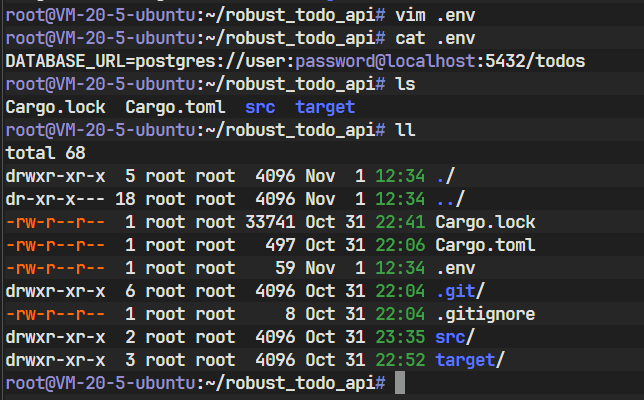
-
添加新的依赖:为项目注入新能力
现在,我们需要告诉 Rust 的包管理器 Cargo,我们的项目需要哪些新的库。打开
Cargo.toml文件,在[dependencies]部分添加sqlx和dotenvy:[package] name = "robust_todo_api" version = "0.1.0" edition = "2024"[dependencies] axum = "0.7" tokio = { version = "1", features = ["full"] } serde = { version = "1", features = ["derive"] } serde_json = "1" uuid = { version = "1", features = ["v4", "serde"] }# 日志 & 追踪 tracing = "0.1" tracing-subscriber = { version = "0.3", features = ["env-filter"] } tower-http = { version = "0.5.0", features = ["trace"] }# 数据验证 validator = { version = "0.18", features = ["derive"] }# 新增依赖 sqlx = { version = "0.7", features = ["runtime-tokio-rustls", "postgres", "macros", "uuid"] } dotenvy = "0.15"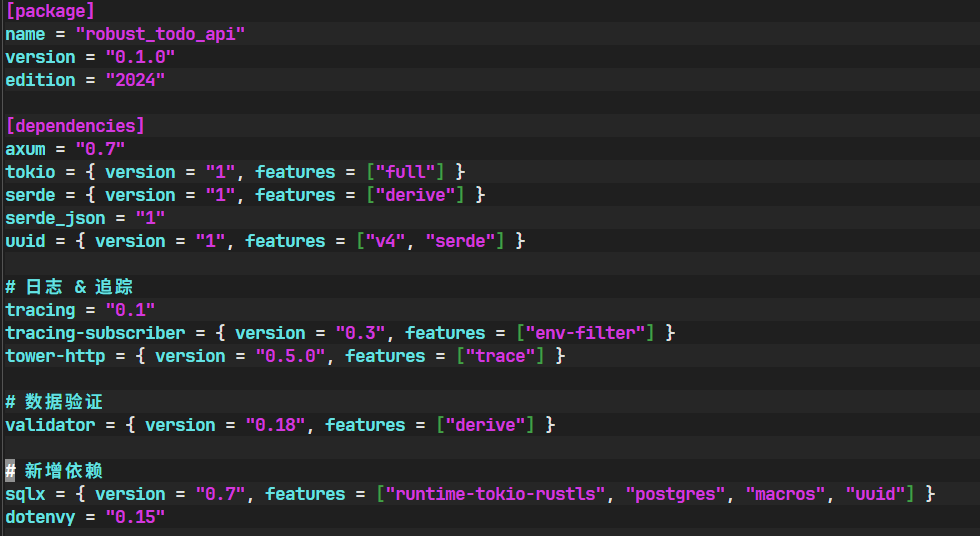
让我们深入理解
sqlx的这些features标志:runtime-tokio-rustls: 这是一个组合特性。runtime-tokio: 明确告诉sqlx我们使用的异步运行时是tokio。sqlx也支持async-std。rustls: 指定使用rustls作为 TLS (传输层安全) 的后端,用于加密数据库连接。rustls是一个纯 Rust 实现的现代 TLS 库,使用它意味着我们的应用编译后不依赖于系统上的 OpenSSL 库,使二进制文件更具可移植性。另一个选项是native-tls,它会使用操作系统提供的 TLS 实现(如 OpenSSL on Linux)。
postgres: 启用针对 PostgreSQL 数据库的特定驱动和协议支持。macros: 这是启用sqlx“杀手级特性”的关键。它会引入query!,query_as!等宏,这些宏是实现编译时查询检查的核心。uuid: 启用sqlx对uuid类型的原生支持。这使得sqlx可以在 Rust 代码中的uuid::Uuid类型和 PostgreSQL 的UUID类型之间进行无缝、自动的转换,无需我们手动处理。dotenvy: 这是一个轻量级的库,它的作用非常专一:在程序启动时读取.env文件,并将其中的键值对加载到当前进程的环境变量中。
第二步:数据库迁移 - 用代码管理你的表结构
数据库迁移是一种以编程方式、可版本控制地管理数据库 schema(结构)演变的过程。 我们绝对不应该手动连接到生产数据库去 CREATE 或 ALTER 表。这种做法是不可追踪、不可复现且极易出错的。相反,我们应该通过迁移文件来精确地定义每一次数据库结构的变更。
-
创建迁移文件
请确保你的终端位于项目根目录,并且
.env文件已正确配置。然后,运行以下命令:sqlx migrate add create_todos_table这个命令指示
sqlx-cli做几件事情:- 它会读取
.env文件中的DATABASE_URL来确定我们正在使用 PostgreSQL。 - 它会在项目根目录下创建一个名为
migrations的新文件夹。 - 在这个文件夹里,它会生成一个以当前UTC时间戳和我们提供的描述
create_todos_table命名的.sql文件。
在较新版本的
sqlx-cli(v0.7 左右) 中,为了简化操作,默认只创建一个合并的 SQL 文件。文件中会用注释-- Add up migration script here和-- Add down migration script here来区分“向上”和“向下”的脚本。- Up Migration (
up.sql): 定义应用此迁移时需要执行的 SQL 命令。例如,创建一张新表、添加一个新列。 - Down Migration (
down.sql): 定义撤销此迁移时需要执行的 SQL 命令。例如,删除up中创建的表、移除添加的列。编写down脚本是良好实践,它使得我们可以在开发过程中轻松地回滚错误的变更。

- 它会读取
-
编写迁移 SQL
现在,打开刚才生成的 SQL 文件。我们将分别在
up和down的部分写入相应的 SQL 语句。在
-- Add up migration script here下方,写入CREATE TABLE语句:-- migrations/{timestamp}_create_todos_table.sql -- Add up migration script here CREATE TABLE todos (id UUID PRIMARY KEY NOT NULL,text TEXT NOT NULL,completed BOOLEAN NOT NULL DEFAULT FALSE );这里需要特别注意,我们将
id的类型设置为UUID。这是一种通用唯一标识符,非常适合用作分布式系统中的主键。它与我们 Rust 代码中使用的uuid::Uuid类型完美对应。接着,在
-- Add down migration script here下方,写入DROP TABLE语句,这是CREATE TABLE的逆操作:-- Add down migration script here DROP TABLE todos;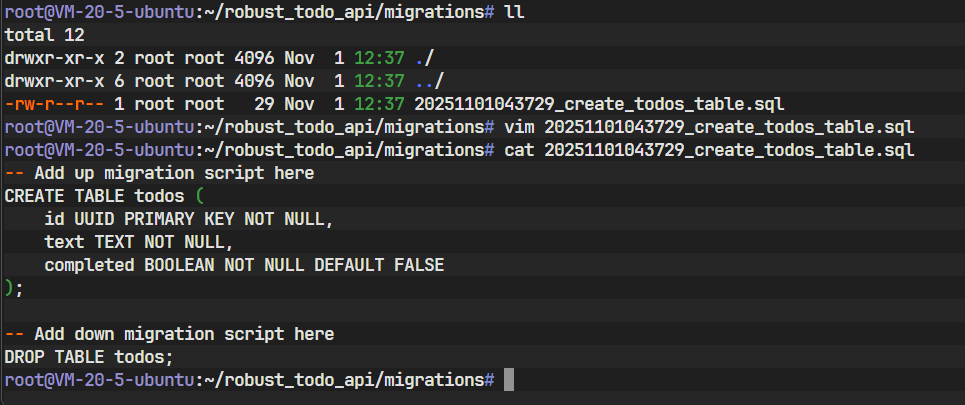
-
执行迁移
保存好迁移文件后,回到终端,运行:
sqlx migrate run
sqlx-cli 会连接到 DATABASE_URL 指定的数据库,并检查一张名为 _sqlx_migrations 的特殊表(如果不存在,它会自动创建)。这张表记录了所有已经成功运行过的迁移文件。然后,它会按时间顺序,执行所有在 migrations 文件夹中但尚未在 _sqlx_migrations 表里记录的迁移文件。
成功执行后,你的 PostgreSQL 数据库的 todos 数据库中就已经有了一张我们定义的 todos 表。数据库的结构现在是明确的、受版本控制的了。

第三步:改造应用核心 - 拥抱异步数据库操作
基础设施准备就绪,现在是时候进入最激动人心的部分了:我们将用与真实数据库的交互,来替换掉所有基于内存 HashMap 的操作逻辑。
-
创建数据库连接池并更新应用状态
对于一个 Web 服务来说,为每个进来的 HTTP 请求都新建一个数据库连接是一种巨大的性能浪费。建立数据库连接是一个相对耗时的操作,涉及到网络握手和认证过程。 连接池 (Connection Pool) 是一种标准解决方案。应用启动时,它会预先创建并维护一定数量的数据库连接。当需要执行查询时,应用会从池中“借用”一个连接,用完后再“归还”给池子,而不是关闭它。这极大地减少了连接建立和销毁的开销,显著提升了应用性能。
我们需要修改
src/main.rs,让 Axum 应用在启动时创建sqlx提供的PgPool(PostgreSQL 连接池),并将其作为共享状态注入到我们的Router中,以便所有 handler 都能访问它。// src/main.rsuse axum::{routing::{get, post, put, delete}, Router}; use std::net::SocketAddr; use tower_http::trace::TraceLayer; use tracing_subscriber::{layer::SubscriberExt, util::SubscriberInitExt};// 引入 sqlx 和 dotenvy use sqlx::postgres::PgPoolOptions; use sqlx::PgPool; use dotenvy::dotenv; use std::env;mod models; mod handlers; mod errors;// 定义一个新的应用状态结构体,用于持有数据库连接池 // derive(Clone) 是 Axum 状态共享的要求 #[derive(Clone)] pub struct AppState {pool: PgPool, }#[tokio::main] async fn main() {// 在程序启动时从 .env 文件加载环境变量dotenv().ok();// 初始化日志系统tracing_subscriber::registry().with(tracing_subscriber::EnvFilter::new("robust_todo_api=debug,tower_http=debug,sqlx=debug" // 增加 sqlx 的 debug 日志)).with(tracing_subscriber::fmt::layer()).init();// 从环境变量中获取数据库 URL,如果不存在则 paniclet db_url = env::var("DATABASE_URL").expect("DATABASE_URL must be set");// 创建数据库连接池let pool = PgPoolOptions::new().max_connections(5) // 设置池中的最大连接数.connect(&db_url).await.expect("Failed to create pool.");// 创建 AppState 实例let app_state = AppState { pool };// 定义路由,并将 AppState 注入let app = Router::new().route("/todos", get(handlers::get_all_todos).post(handlers::create_todo)).route("/todos/:id",get(handlers::get_todo_by_id).put(handlers::update_todo).delete(handlers::delete_todo),).with_state(app_state) // 使用 .with_state() 将状态注入到路由中.layer(TraceLayer::new_for_http());// 启动服务let addr = SocketAddr::from(([127, 0, 0, 1], 3000));tracing::debug!(">> 服务正在监听 http://{}", addr);let listener = tokio::net::TcpListener::bind(addr).await.unwrap();axum::serve(listener, app).await.unwrap(); }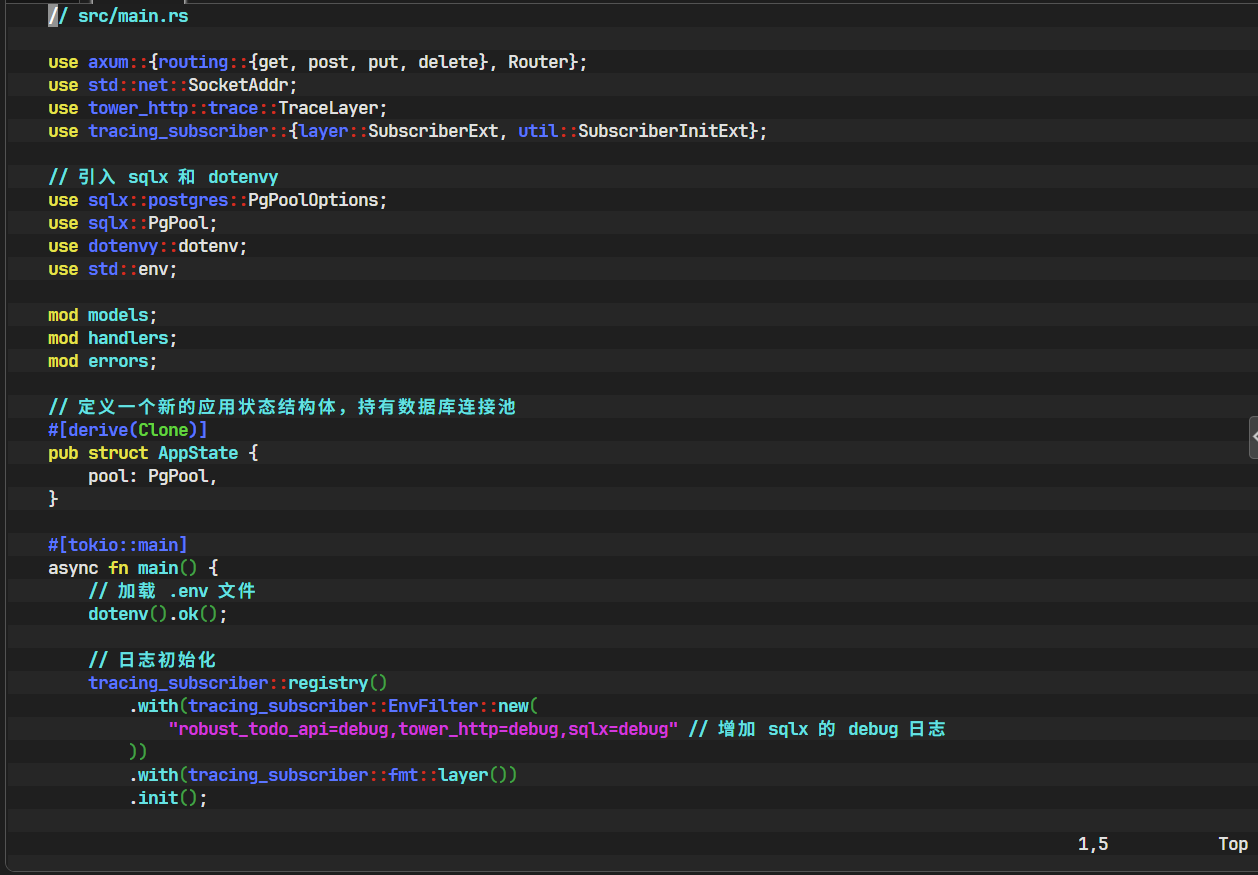
核心改动深度解析:
dotenv().ok();: 我们在main函数的开头就调用它,确保在后续代码(如读取DATABASE_URL)执行之前,所有环境变量都已加载完毕。AppState结构体:我们定义了一个新的AppState结构体来专门持有所有需要共享的应用状态。目前它只包含pool: PgPool,但未来可以轻松扩展,加入配置、缓存客户端等。#[derive(Clone)]是必需的,因为 Axum 会为每个处理请求的 worker 线程克隆一份状态。PgPool内部使用了Arc(原子引用计数指针),所以克隆它本身是非常廉价的,只是复制一个指针。PgPoolOptions:sqlx提供了链式 API 来配置连接池。.max_connections(5)是一个重要的性能调优参数,它限制了应用能同时打开的数据库连接数量,防止耗尽数据库资源。.with_state(app_state): 这是 Axum 注入共享状态的关键方法。它会将app_state的一个副本分发给它所应用到的所有路由处理器(handler)。sqlx=debug: 在日志过滤器中加入sqlx=debug,可以让sqlx打印出详细的运行时信息,包括它执行的每一条 SQL 语句、连接获取和释放等,这在开发和调试阶段非常有用。
-
让数据模型与 SQLx 兼容
我们需要告诉
sqlx如何将从数据库查询到的一行数据,映射到我们的Todo结构体实例上。sqlx通过一个名为FromRow的 trait 来实现这一点。最简单的方式就是使用派生宏。打开
src/models.rs,为Todo结构体派生sqlx::FromRow。// src/models.rsuse serde::{Deserialize, Serialize}; use uuid::Uuid; use validator::Validate;// 为 Todo 结构体派生 sqlx::FromRow // 这个宏会自动生成代码,使得 sqlx 能够根据列名将数据库行记录 // 映射到这个结构体的同名字段上。 #[derive(Debug, Serialize, Clone, sqlx::FromRow)] pub struct Todo {pub id: Uuid,pub text: String,pub completed: bool, }// CreateTodo 结构体保持不变,因为它只用于从 HTTP 请求体中反序列化 JSON #[derive(Deserialize, Validate)] pub struct CreateTodo {#[validate(length(min = 1, message = "Todo text cannot be empty"))]pub text: String, }// UpdateTodo 结构体也保持不变 #[derive(Deserialize, Validate)] pub struct UpdateTodo {#[validate(length(min = 1, message = "Todo text cannot be empty"))]pub text: Option<String>,pub completed: Option<bool>, }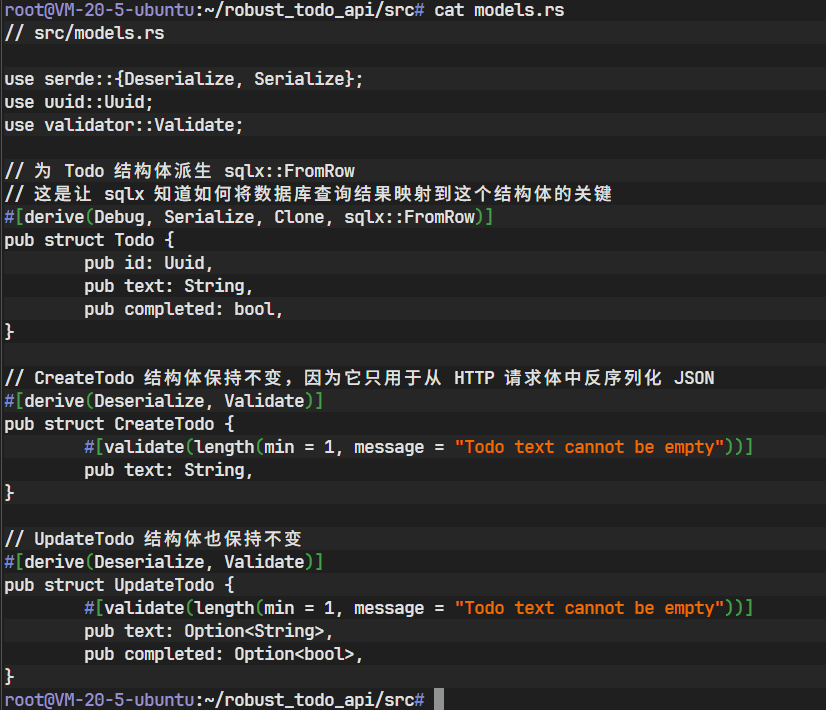
这个小小的
#[derive(sqlx::FromRow)]背后蕴含了sqlx强大的宏能力。在编译时,它会检查Todo结构体的字段名(id,text,completed),并生成将数据库查询结果中同名列的值赋给这些字段的代码。 -
重写所有 Handlers:与 SQLx 的共舞
这是本次重构的核心。我们将打开
src/handlers.rs,用sqlx的异步查询替换掉所有的HashMap操作。首先,更新文件开头的
use语句,并准备好从 Axum 的State提取器中获取我们的AppState。// src/handlers.rsuse axum::{extract::{Path, State},http::StatusCode,Json, }; use uuid::Uuid; use validator::Validate;use crate::models::{CreateTodo, Todo, UpdateTodo}; use crate::errors::AppError; use crate::AppState; // 引入新的 AppState// ----- Handlers -----// GET /todos pub async fn get_all_todos(State(state): State<AppState>, ) -> Result<Json<Vec<Todo>>, AppError> {let todos = sqlx::query_as!(Todo, "SELECT id, text, completed FROM todos ORDER BY id").fetch_all(&state.pool).await.map_err(|e| {tracing::error!("Failed to fetch todos: {:?}", e);AppError::InternalServerError})?;Ok(Json(todos)) }// POST /todos pub async fn create_todo(State(state): State<AppState>,Json(input): Json<CreateTodo>, ) -> Result<(StatusCode, Json<Todo>), AppError> {input.validate().map_err(|e| AppError::ValidationError(e.to_string()))?;let todo = sqlx::query_as!(Todo,"INSERT INTO todos (id, text) VALUES ($1, $2) RETURNING id, text, completed",Uuid::new_v4(),input.text).fetch_one(&state.pool).await.map_err(|e| {tracing::error!("Failed to create todo: {:?}", e);AppError::InternalServerError})?;Ok((StatusCode::CREATED, Json(todo))) }// GET /todos/:id pub async fn get_todo_by_id(State(state): State<AppState>,Path(id): Path<Uuid>, ) -> Result<Json<Todo>, AppError> {let todo = sqlx::query_as!(Todo, "SELECT * FROM todos WHERE id = $1", id).fetch_optional(&state.pool).await.map_err(|e| {tracing::error!("Failed to fetch todo by id: {:?}", e);AppError::InternalServerError})?.ok_or_else(|| AppError::NotFound(format!("Todo with ID {} not found", id)))?;Ok(Json(todo)) }// PUT /todos/:id pub async fn update_todo(State(state): State<AppState>,Path(id): Path<Uuid>,Json(input): Json<UpdateTodo>, ) -> Result<Json<Todo>, AppError> {input.validate().map_err(|e| AppError::ValidationError(e.to_string()))?;let todo = sqlx::query_as!(Todo, "SELECT * FROM todos WHERE id = $1", id).fetch_optional(&state.pool).await.map_err(|_| AppError::InternalServerError)?.ok_or_else(|| AppError::NotFound(format!("Todo with ID {} not found", id)))?;let text = input.text.unwrap_or(todo.text);let completed = input.completed.unwrap_or(todo.completed);let updated_todo = sqlx::query_as!(Todo,"UPDATE todos SET text = $1, completed = $2 WHERE id = $3 RETURNING *",text,completed,id).fetch_one(&state.pool).await.map_err(|_| AppError::InternalServerError)?;Ok(Json(updated_todo)) }// DELETE /todos/:id pub async fn delete_todo(State(state): State<AppState>,Path(id): Path<Uuid>, ) -> Result<StatusCode, AppError> {let result = sqlx::query!("DELETE FROM todos WHERE id = $1", id).execute(&state.pool).await.map_err(|_| AppError::InternalServerError)?;if result.rows_affected() == 0 {Err(AppError::NotFound(format!("Todo with ID {} not found", id)))} else {Ok(StatusCode::NO_CONTENT)} }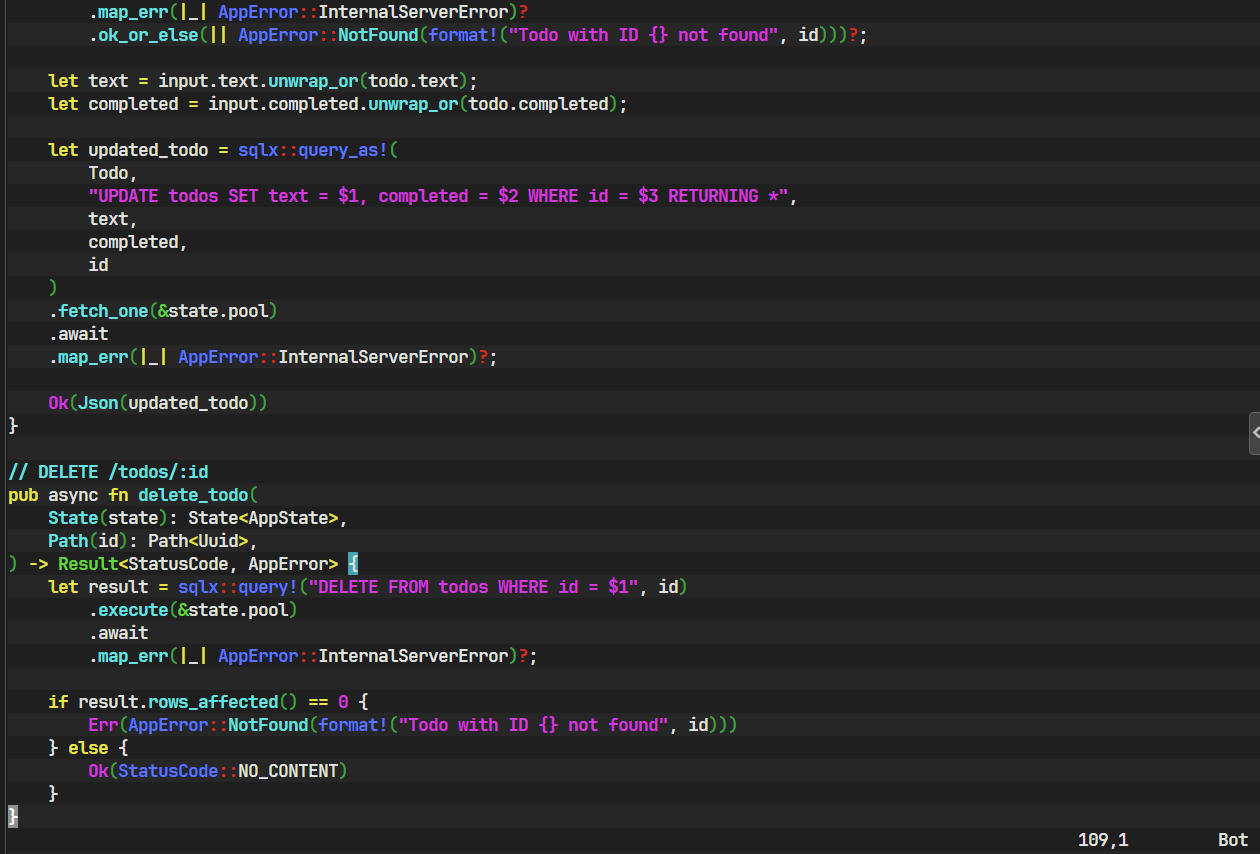
深度解析
sqlx的查询模式:- 提取状态:
State(state): State<AppState>Axum 的提取器现在为我们提供了AppState的实例,我们可以通过state.pool访问连接池。 - 编译时安全宏:
sqlx::query_as!(Todo, ...): 这是我们最常用的宏。它接收一个目标类型(Todo)和 SQL 查询字符串。在编译时,它会连接数据库,验证 SQL 语法,并确保SELECT子句返回的列与Todo结构体的字段在名称和类型上都兼容。sqlx::query!(...):delete_todo中使用的宏。它不映射到指定的结构体,而是返回一个匿名的、字段已正确类型的结构体。它同样会进行编译时检查。
- 参数绑定:
$1, $2这种语法是参数化查询的占位符。sqlx会安全地将我们后续提供的值(如id,input.text)绑定到这些占位符上。这是一种防止 SQL 注入攻击的根本方法。它确保了用户输入永远被当作数据处理,而不会被错误地解析为 SQL 代码的一部分。 - 执行器方法 (Fetcher Methods):
.fetch_all(&state.pool): 执行查询并异步地将所有返回的行收集到一个Vec<Todo>中。适合返回列表的场景。.fetch_one(&state.pool): 执行查询并期望返回恰好一行。如果数据库返回 0 行或多于 1 行,它将返回一个错误。非常适合INSERT ... RETURNING或根据唯一键查询的场景。.fetch_optional(&state.pool): 执行查询并期望返回零行或一行。它的返回值是Result<Option<Todo>, Error>,完美匹配我们“根据 ID 查找单个资源”的场景,因为资源可能存在,也可能不存在。.execute(&state.pool): 用于执行不返回数据行的 SQL 命令(如DELETE或没有RETURNING子句的UPDATE)。它返回一个QueryResult,其中包含了rows_affected()等元信息。
RETURNING *: 这是 PostgreSQL 的一个极其有用的特性。 它允许INSERT、UPDATE或DELETE语句直接返回被操作行的内容。这为我们省去了一次额外的SELECT查询。例如,在create_todo中,我们INSERT一条新记录后,可以直接通过RETURNING *获得数据库生成的完整Todo对象(包括默认值等),效率极高。
- 提取状态:
第四步:最终测试 - 验证持久化的力量
所有代码已经改造完毕。现在,是时候通过实践来检验我们的劳动成果了。
-
启动应用
在终端中运行cargo run。由于我们在main.rs的日志配置中添加了sqlx=debug,现在你的终端会变得非常“热闹”。你会看到sqlx打印出大量有用的调试信息,包括它如何从连接池中获取连接、执行的每一条具体的 SQL 语句以及执行耗时。这对于理解应用底层行为和性能调试非常有帮助。
-
执行一系列
curl命令我们将模拟客户端与 API 的交互,来完整地测试一次数据的生命周期。
-
创建一个新的 Todo:
打开另一个终端窗口,执行以下curl命令。-X POST指定请求方法,-H "Content-Type: application/json"告诉服务器我们发送的是 JSON 数据,-d '...'是请求体内容。curl -X POST -H "Content-Type: application/json" -d '{"text": "学习 SQLx"}' http://127.0.0.1:3000/todos如果一切顺利,你应该会收到一个包含新创建的 Todo 对象的 JSON 响应,其中
id是一个新生成的 UUID。

-
获取所有 Todos (验证创建成功):
现在,让我们获取列表,看看我们刚创建的项目是否在其中。curl http://127.0.0.1:3000/todos返回的 JSON 数组中应该包含了 “学习 SQLx” 这一项。

-
重启服务 (关键步骤):
这是验证持久化的核心步骤。回到运行cargo run的终端,按下Ctrl+C来优雅地停止服务。此时,内存中的所有状态都已丢失。然后,再次运行cargo run重启应用。 -
再次获取所有 Todos (验证持久化):
服务重启后,再次执行获取所有 Todo 的curl命令:curl http://127.0.0.1:3000/todos见证奇迹的时刻! 尽管服务已经彻底重启,但 “学习 SQLx” 这个待办事项依然被返回了。它安静地躺在我们的 PostgreSQL 数据库中,等待着被查询。这有力地证明了,我们的数据被成功地持久化了。

-
结论:一个新的起点
恭喜你!通过本教程的引导,我们完成了一次意义重大的升级。我们的 robust_todo_api 项目已经从一个基于内存的原型 API,蜕变为一个使用真实数据库进行数据持久化的、更接近生产级别的 Web 应用。
我们收获的不仅仅是代码的改变,更重要的是,我们引入并实践了一整套专业、可靠的数据库开发工作流:
- 隔离与可复现的环境: 使用 Docker,我们为开发环境创建了一个一致且与主机系统隔离的数据库实例。
- 版本化的数据库 Schema: 使用
sqlx-cli和迁移文件,我们让数据库的结构演变变得像 Git 提交一样清晰、可追溯和可自动化。 - 安全与高性能的交互: 使用
sqlx的异步 API、连接池以及革命性的编译时检查,我们在享受 Tokio 带来的高并发性能的同时,获得了前所未有的数据库操作安全性,将大量潜在的运行时错误消灭在了萌芽阶段。
我们的 robust_todo_api 现在已经名副其实。从这里出发,你已经为构建更复杂、更健壮的系统打下了坚实的基础。下一步的探索方向可以是:
- 用户认证与授权: 集成 JWT (JSON Web Tokens) 或其他认证机制,实现多用户隔离。
- 更完善的配置管理: 引入专门的配置库,管理不同环境(开发、测试、生产)的配置。
- 应用容器化: 为我们的 Rust 应用编写
Dockerfile,将其也打包成一个 Docker 镜像,为将来的云原生部署铺平道路。
Rust 后端开发的道路充满挑战与机遇,而你,已经迈出了坚实而漂亮的一步。继续探索,继续构建吧!