Zookeeper在Kafka中的作用
Zookeeper在Kafka中的作用主要体现在分布式协调与管理上,具体包括以下核心功能:
集群元数据管理
- Broker节点注册信息(如
broker.id、地址、端口) - Topic分区分布状态(分区副本与Leader的映射关系)
- 消费者组偏移量(早期版本)
- Broker节点注册信息(如
Zookeeper存储Kafka集群的关键元数据,例如:(1)启动 Zookeeper 客户端。bin/zkCli.sh

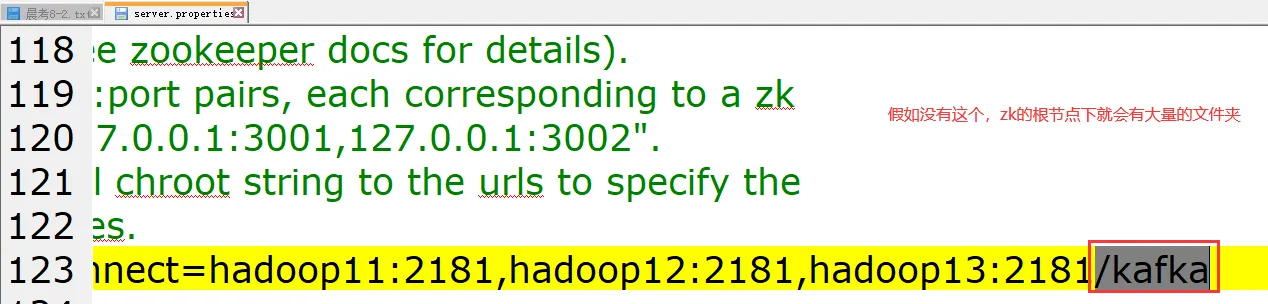
因为你在配置kafka的时候指定了它的名字。
Leader选举
当分区Leader失效时,Zookeeper通过分布式锁机制协调副本选举新Leader,确保高可用性。选举过程遵循多数派原则(Quorum),需满足: $$ \text{存活节点数} \geq \lfloor \frac{\text{总节点数}}{2} \rfloor + 1 $$配置同步
所有Broker通过Zookeeper监听配置变更(如topic创建/删除),实现配置的全局一致性。分布式锁服务
为Controller选举提供协调机制:首个在Zookeeper创建
/controller节点的Broker成为集群Controller,负责分区分配与状态维护。
版本演进:Kafka 2.8+ 已逐步用KRaft协议(基于Raft的分布式共识)替代Zookeeper,实现元数据自管理。但在早期版本中,Zookeeper仍是核心依赖。