技术观察 | 语音增强技术迎来新突破!TFCM模型如何攻克“保真”与“降噪”的难题?
OpenLoong开源社区技术观察
当人形机器人在喧嚣的工厂里执行操作,或在热闹的家庭中回应指令时,背景噪声就像一堵无形的墙,阻挡了它与人类的交流。传统方法如果强力降噪,虽然能降低噪声,却容易让语音失真,关键指令丢失;而如果保留语音完整性,又难以在复杂环境下准确捕捉声音。这种“保真”与“降噪”的矛盾,一直制约着机器人在真实场景中的表现。

新一代语音增强模型 TFCM 带来了突破。它通过时间和频率两个维度的协同卷积和轴向注意力机制,有效抑制环境噪声,同时尽可能保留语音的关键特征,为机器人在嘈杂环境中理解自然语言指令提供了更清晰的输入。换句话说,TFCM 不只是简单的“降噪工具”,它让机器在复杂声学环境下能够“听得更清楚”,为智能机器人实现更自然、更可靠的语音交互打下了坚实基础。
在本篇文章中,小Loong 将从技术演进、模型原理、应用场景以及工程挑战四个维度,全面解读语音增强领域的核心问题:解析多通道与深度学习结合的必要性,剖析 TFCM 模型在嘈杂环境下如何提升语音可懂度与保真度,并揭示前端硬件、算法设计与识别系统之间隐藏的挑战。通过这四个视角,小Loong 希望带你系统理解语音增强技术的发展脉络、现实价值,以及开源协作在推动行业进步中的关键作用。
语音增强三十年:从谱减法到深度学习的进化之路
语音增强,其本质就是语音降噪,旨在从被噪声污染的语音中恢复出我们想要的干净语音。自20世纪70年代起,语音增强技术经历了从传统数字信号处理方法到基于深度学习的现代方法的演变,跨越了五十余年的发展历程。这一进化之路不仅反映了技术的革新,更体现了多学科交叉融合的推动力。
01 | 传统方法的奠基与局限
语音增强技术的探索最早可以追溯到数字信号处理的时代。那时,研究者们相信,只要在数学上准确地建模语音与噪声的关系,就能“滤”出更干净的声音。于是,谱减法(Spectral Subtraction) 应运而生——它通过在静音或低语音段估计噪声频谱,再从带噪语音的频谱中减去这部分估计,实现了最初的降噪尝试。此后,维纳滤波(Wiener Filtering) 和基于统计模型的方法(如 最小均方误差 MMSE 估计)进一步改进了性能:通过更细致地建模语音与噪声的功率谱分布,计算出最优的滤波增益,让降噪和语音保真之间达到更好的平衡。可以说,这一阶段的技术为后来的语音增强奠定了坚实的信号处理基础。
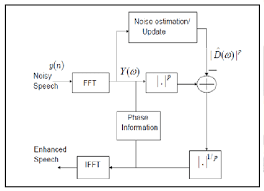
谱减法基本原理示意图
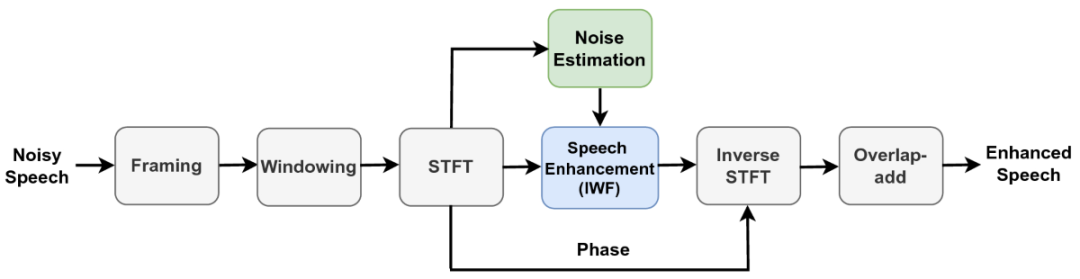
维纳滤波基本原理示意图
不过,这些“传统派”方法也有明显短板。它们往往假设噪声是平稳的、可预测的,而在街头、地铁、会议室等复杂环境中,这种假设显然站不住脚;再加上单通道系统只能依赖时频特征,无法利用空间信息,降噪效果自然受限。为了突破这些瓶颈,研究者开始引入多通道语音增强技术——通过麦克风阵列捕捉声源的空间线索(如到达方向、时延差),结合波束形成(Beamforming) 和空间滤波等方法,使系统能够“聚焦”于目标语音,显著提升了在嘈杂环境下的语音清晰度与可懂度。这类技术如今已广泛应用于助听器、会议系统、智能语音设备等场景,不过,它也带来了阵列设计、信号同步和房间声学等新的挑战。
02 | 深度学习的革命与突破
21世纪以来,随着计算硬件的升级和大数据的普及,深度学习为语音增强带来了革命性变化。基于神经网络的语音增强方法能够直接从数据中学习带噪语音与纯净语音之间的复杂映射关系,无需对噪声特性进行强假设。深度学习模型(如DNN、CNN、RNN乃至Transformer)通过端到端训练,在时频域或时域上实现了更精准的噪声抑制和语音重建。这一领域的突破与众多学者的努力密不可分,其中,俄亥俄州立大学的汪德亮教授及其团队作出了关键贡献,他们推动了深度学习在语音增强中的理论创新与应用落地。与此同时,语音增强的范畴从单一的降噪扩展至语音分离、解混响等综合任务,覆盖了单通道与多通道(如双麦克风系统)等多种场景。
03 | 走向 TFCM 的技术脉络
深度学习推动了语音增强技术的范式转变。从最初基于 DNN 的幅度谱映射模型,到能够捕捉时间动态的 RNN 与 LSTM,再到利用 CNN 在时频域提取局部结构特征的卷积架构,模型的表达能力不断增强。2018 年以后,U-Net 与 CRN 等混合网络通过结合卷积与递归结构,实现了对语音时频特征的更精细建模,显著改善了语音重建质量。随着 Transformer 与自注意力机制的引入,语音增强开始具备全局上下文建模能力,但高计算复杂度与实时性限制成为瓶颈。在此背景下,TFCM 模型应运而生——它通过时间-频率双尺度卷积与轴向注意力机制(Axial Attention)的融合,在保持局部特征敏感度的同时,实现了更高效的全局建模,为深度语音增强模型的结构演进带来了新方向。
TFCM 模型拆解:它是怎么让语音更清晰的?
在语音增强这条不断进化的技术赛道上,Multi-Scale Temporal Frequency Convolutional Network with Axial Attention(TFCM)已成为近年来备受关注的创新模型。与传统依赖数学假设的降噪算法不同,TFCM 摆脱了对噪声类型和统计特性的理想化假设,转而借助深度学习,直接从大量数据中“学习”带噪语音与纯净语音之间的复杂映射关系。它的核心在于同时兼顾时间与频率两个维度的特征建模:通过多尺度卷积结构捕捉短时语音细节与长期语境关联,再结合轴向自注意力机制,在时间轴与频率轴上分别聚焦关键信息,从而高效理解语音的全局特征。此外,TFCM 还能同时处理幅度谱与相位谱,并支持多通道输入与空间信息融合,让它在回声、混响、复杂噪声等真实环境中,依然能稳定地重建出清晰、自然的语音。
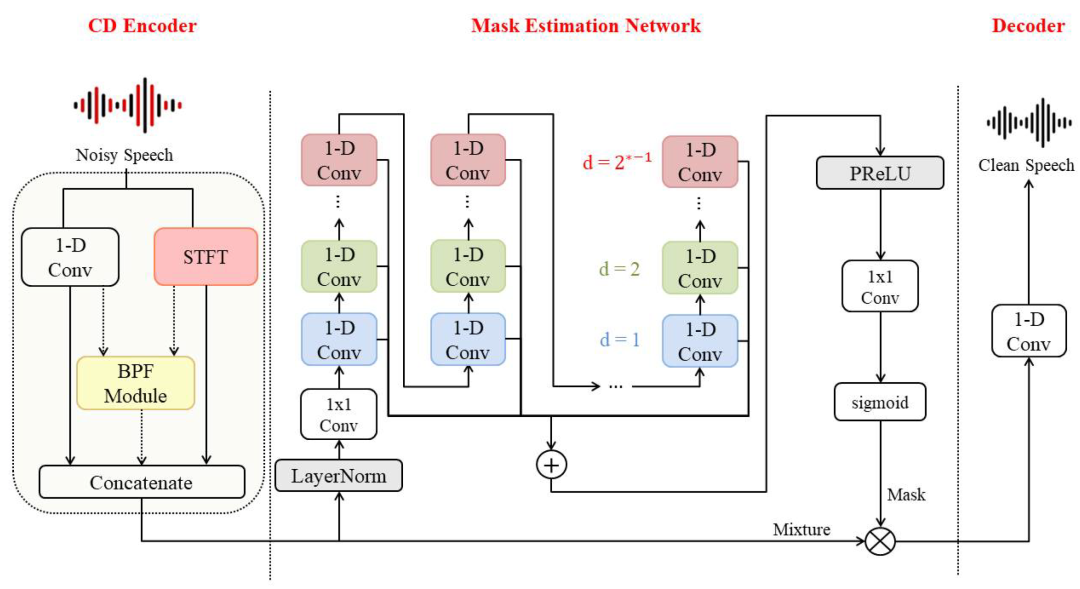
TFCM模型架构图
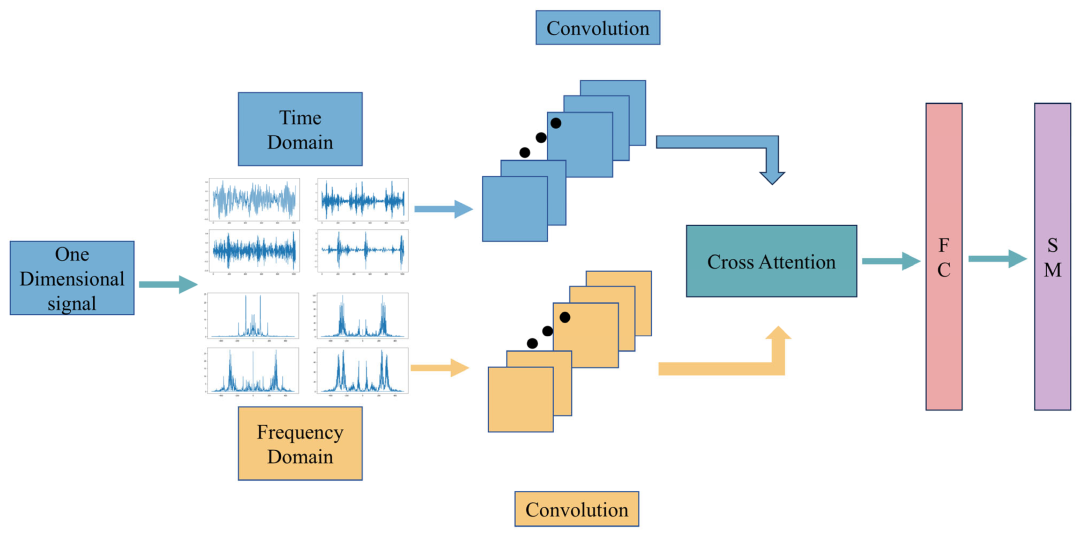
TFCM模型架构图
虽然目前 TFCM 在商用人形机器人中的具体部署尚未公开,但基于其技术原理,我们可以推演一个典型应用场景:假设人形机器人在嘈杂的工厂车间执行巡检任务,或在热闹的家庭环境中回应语音指令,TFCM 模型可以实时抑制环境噪声,同时保留语音的关键特征,从而让机器人准确识别和执行操作命令。这样的应用展示了 TFCM 在多干扰环境下的潜在价值,为未来机器人实现更自然、更可靠的语音交互提供了技术可能性。
相比谱减法、维纳滤波及基于统计模型的传统语音增强方法,TFCM 在复杂多干扰场景下表现更为出色。它降低了对噪声平稳性的依赖,具备更强的特征表达与上下文建模能力,并在多项国际评测(如 ICASSP 2022)中取得领先成绩。可以说,TFCM 代表了语音增强技术从“假设驱动 + 信号处理”向“数据驱动 + 深度网络”的一次重要跃迁。当然,这类模型仍面临训练数据质量、模型规模与实时性等挑战,但它无疑为智能语音、会议系统与助听设备等应用场景打开了新的可能,也预示着语音增强正迈向更智能、更灵活的新时代。
多通道语音增强的三大技术难点
要让机器在嘈杂的世界中“听懂人话”,并不是一件容易的事。即便拥有强大的算法,大多数语音增强研究仍要跨过三道“硬门槛”——从硬件采集到算法设计,再到识别系统匹配,每一步都藏着不小的挑战。
01 | 多通道同步采集硬件
首先是多通道同步采集硬件。想研究前端降噪算法,必须先有高质量的多麦克风阵列数据。但现实是,主流的音频芯片通常只能支持 4 通道同步采集,而像智能音箱这类设备往往需要 7 个麦克风加 1 个参考通道,至少要 8 通道才能满足需求。为了让两颗芯片保持严格同步,还得借助 FPGA 芯片协同控制,并配合一整套滤波放大电路。更麻烦的是,这类多通道硬件在消费级产品中并不常见,设计经验少、调试难、周期长,也让研究门槛水涨船高。
02 | 前端麦克风陈列降噪算法
接着是前端麦克风阵列降噪算法。这部分是语音增强的“灵魂”,要解决的包括播放状态下的回声消除、房间混响、非平稳噪声干扰等典型难题。例如,回声消除虽然在手机上早已成熟,但用于远场语音识别时容易带来语音失真;混响则让语音信号拖尾、模糊,显著影响识别率。近年来,日本 NTT 的多步线性预测方法在去混响上取得了不错的效果;而针对非平稳噪声,研究者普遍采用波达方向估计(DOA)+ 自适应波束形成的方式,让系统自动对准目标说话人,在噪声方向形成“零点”,实现动态抑噪。
03 | 前后端算法的匹配问题
最后是前后端算法的匹配问题。语音识别的效果很大程度上取决于训练数据与测试数据的一致性。如今主流识别引擎多基于“近讲语音”训练,对远场语音的适配性较差。要想真正提升远场识别率,就必须让前端降噪算法输出的数据用于训练识别模型,让系统从一开始就学会理解“嘈杂环境下的真实语音”。
语音识别的两条主流路线
在远场语音识别领域,目前主要有两种技术思路在并行发展:
-
信号处理派:依靠多麦克风阵列,通过物理手段(如波束形成)抑制噪声、去除混响。主流产品都走这条路线——Echo 用 7 个麦克风、叮咚用 8 个、Google Home 用 2 个——实验证明,这种方法在复杂环境下非常可靠。
-
深度学习派:希望通过端到端的神经网络模型直接实现去噪和去混响,尽量不依赖硬件辅助。但目前来看,面对远场、复杂噪声环境,单靠 DNN 仍难以媲美人脑的听觉能力。正如人类拥有大脑和双耳才能分辨环境声,多麦克风提供的空间信息仍是现阶段不可或缺的“助听神器”。
因此,远场语音识别的挑战已不只是算法创新,而是硬件、算法、数据与系统集成的协同问题。未来,随着深度学习能力提升,或许只需两三个麦克风就能解决远场语音识别,但在当下,多麦克风阵列仍然是最稳妥的选择。
让机器更聪明地“听”:技术突破与开源协作
语音增强正经历一场从传统方法到深度学习范式的深刻变革。以 TFCM 为代表的新一代模型,通过时域与频域双分支协同、智能互补,实现了对语音信号更精细的修复与重建,让机器在复杂环境中也能“听得清、听得懂”。相比传统降噪方法,它不仅抑制噪声,更兼顾语音的高保真和高可懂度,标志着语音增强迈出了关键一步。
这场技术革命正在迅速落地:在通信中,它带来无噪通话体验;在助听器中,它让智能增强取代单纯放大,帮助听障人士清晰接收信息;在智能家居的远场交互里,它成为回声、混响与噪声干扰的克星,有效提升语音识别准确率与用户体验。
当然,要让这些技术在各种场景中稳健落地,我们仍面临硬件设计、算法优化与系统集成等挑战。这些难题的解决,无法仅靠少数团队闭门造车,而需要更多开发者和研究者的集体智慧。为此,我们诚挚地邀请您加入 OpenLoong 开源社区。 在这里,无论您是专注于硬件架构、算法创新,还是系统集成,都可以找到志同道合的伙伴。让我们共同构建更优质的语音数据集,切磋与优化前沿模型,在交流碰撞中解决那些最棘手的技术挑战。我们相信,只有通过开放的协作,才能加速突破技术瓶颈,共同推动机器听觉技术向前发展,让更清晰的语音体验,真正赋能每一台设备,惠及每一位用户。