做DNN的建议--激活函数篇
当我们做deep learning 训练结果坏掉了的时候,应该怎么处理
在之前的机器学习中,我们如果在训练集上得不到一个好的正确率,那就需要回过头去看我们的模型选择,损失函数的定义,梯度下降方法的选取等,如果在训练集结果好但测试集坏掉了,这种就是过拟合了,这套在dl里面也适用,在测试集上得到不好的结果不总是overfitting,只有training set上结果很好时,这种才是过拟合
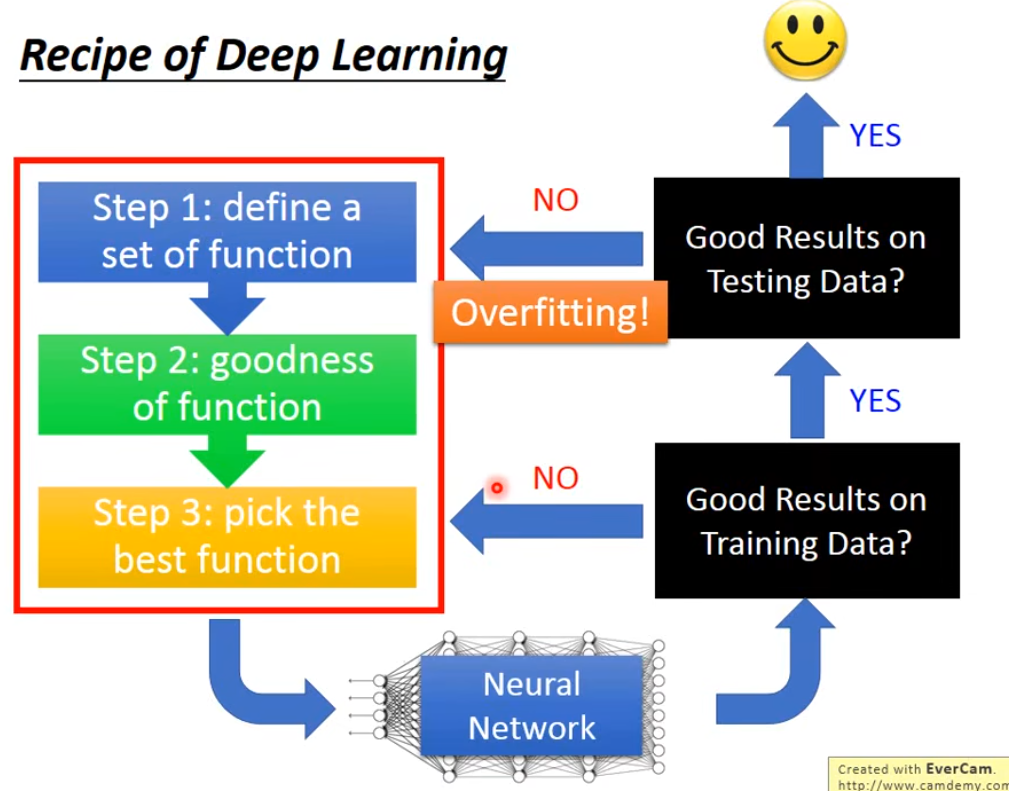
当我们遇到结果坏掉的情况,我们要很清晰的知道,我们要找的方法是为了提升训练集上的表现还是测试集上的表现。不同的方法效果是不一样的,有的方法对训练集有效,有的方法对测试集有效;
当我们在训练集上得到的结果已经不好的时候,如果通过去调整参数,增加网络层数发现结果也无法变好,甚至在增加网络层数时结果还变差了,这种情况下通常就需要去调整我们的激活函数了。而导致这种场景产生的原因,通常是因为输入参数的微分,在经过多层的变化,每一层都会变小,导致在最后一层的梯度对参数的微分值很小,然后再反馈到第一层,它的作用就很小,无法快速地收敛到local minimal。这种场景我们也可以通过改dynamic learning来获得一个比较好的结果

当我们在实际做训练的时候,我们想要评估一个参数对loss function的影响,一个小技巧是通过改变该参数值,小小地变化一下,观察下loss 的变化,如果loss变化大,说明影响比较大
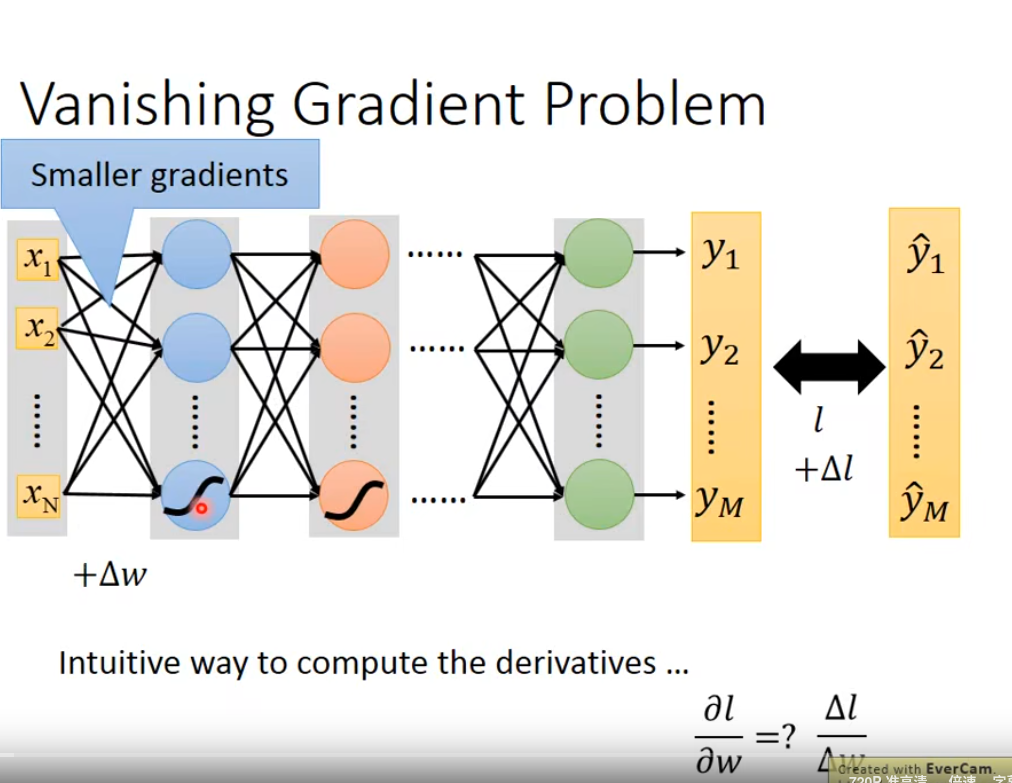
为了解决我们使用sigmod激活函数,经过多层网络,它的连乘效果导致最终的梯度变化趋近于0从而训练效果很差的情况,有一种比较好的方案是使用relu激活函数(修正线性单元)

ReLU 是一个非常简单的数学函数:它只对输入进行一个非常基础的非线性操作。
数学定义:
f(x) = max(0, x)
换句话说:
如果输入 x 是正数,输出就是 x 本身。如果输入 x 是负数,输出就是 0。
它的图像是一条折线,在原点处拐弯:
当 x < 0 时,y = 0(一条水平线)。当 x >= 0 时,y = x(一条斜率为1的直线)。
在神经网络中,如果没有激活函数,那么无论堆叠多少层,整个网络都等价于一个单层线性模型,无法学习复杂的非线性模式。激活函数的作用就是引入非线性,使神经网络成为“万能的函数逼近器”。
ReLU 的成功源于它几个关键的优点:
优点:
缓解梯度消失问题在它出现之前,常用的激活函数是 Sigmoid 和 Tanh。当输入值很大或很小时,这些函数的梯度会接近于0(饱和区)。在反向传播中,梯度会通过网络层连乘。如果每一层的梯度都很小,连乘之后梯度会指数级减小,导致靠近输入层的网络参数几乎得不到更新,这就是梯度消失。ReLU 在正区间的梯度恒为1,因此在反向传播时,梯度不会因为连乘而迅速减小,极大地缓解了梯度消失问题,使得训练非常深的网络成为可能。计算效率极高它只涉及简单的比较和赋值操作(max(0, x)),没有像 Sigmoid 或 Tanh 那样的指数运算。这在训练大型神经网络时,能节省巨大的计算成本。具有稀疏激活性当输入为负时,ReLU 的输出为0。这意味着网络中会有很多神经元被“关闭”。这种稀疏性类似于我们大脑的工作方式(只有部分神经元被激活),使得网络更加高效,并且可能有助于缓解过拟合。
- 它的缺点与改进版本
尽管ReLU非常强大,它也有一个著名的缺陷:Dying ReLU Problem。
缺点:Dying ReLU
问题描述:如果一个神经元在训练过程中,其权重更新后,对于所有训练数据的输入都落在了负半区(即 x < 0),那么这个神经元将永远输出0,并且梯度也为0。后果:一旦神经元“死亡”,它的权重很可能再也不会被更新,因为它对应的梯度永远是0。这个神经元在后续的训练中就完全失效了。
改进版本:
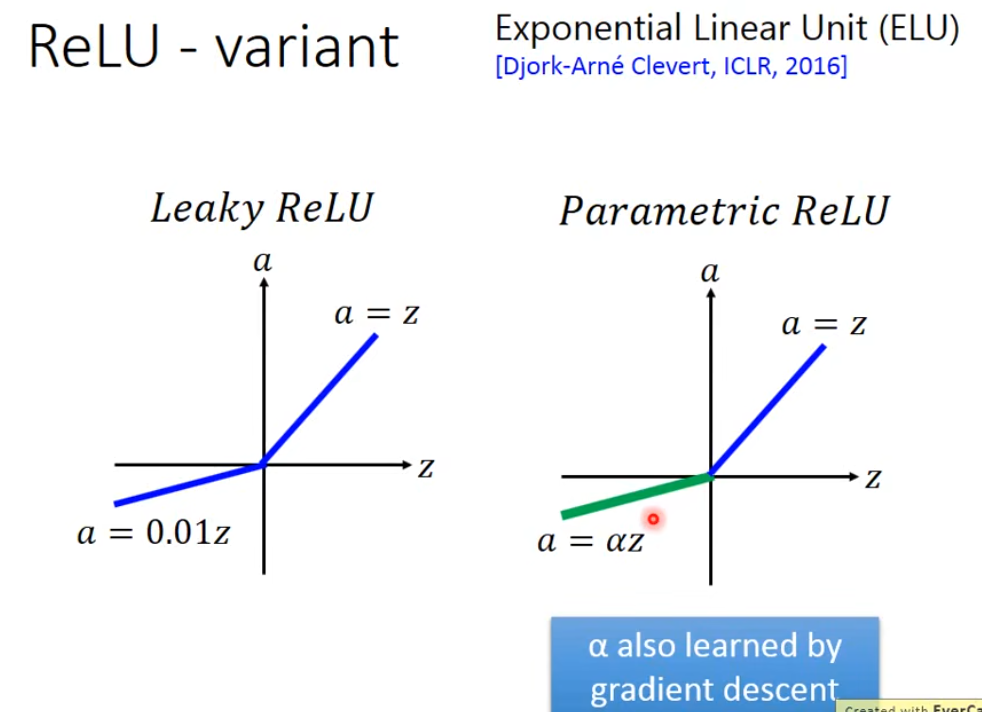
为了解决“死亡ReLU”问题,研究者们提出了一些变体:
Leaky ReLU当 x < 0 时,它不再输出0,而是输出一个很小的斜率(比如 0.01x)。公式:f(x) = max(αx, x),其中 α 是一个很小的常数(如0.01)。这确保了在负区间也有一个很小的梯度,使得神经元有机会被重新激活。Parametric ReLU这是 Leaky ReLU 的升级版。它不把斜率 α 当作一个固定的超参数,而是将其作为模型的一个参数,在训练中学习得到。Exponential Linear Unit (ELU)它试图让激活函数的均值更接近0,从而加快收敛速度。它在负区间使用一个指数曲线,平滑地过渡。
当我们使用relu的时候,里面的每个神经元都是线性的,但整个网络并不是,因为每层级的变换值并不是线性的,所以整体不是线性的
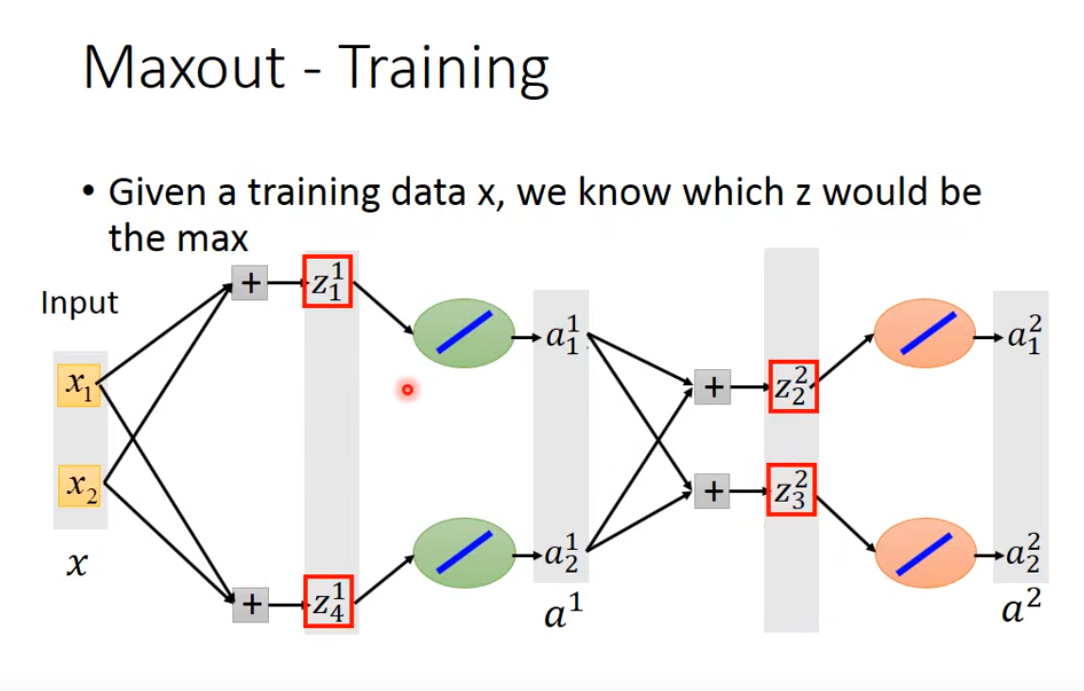
如果我们让神经网络自动去学习自己的激活函数,一种方法是maxout 网络,它可以为每一个神经元选一个自己的激活函数
maxout network的运作原理是,对我们每个神经元的输出进行分组,如下假定第一第二个为一组,第三第四个为一组,我们的激活函数选取分组里面的最大值输出,一个分组有几个元素,几层的网络放一起,这是预先定好的

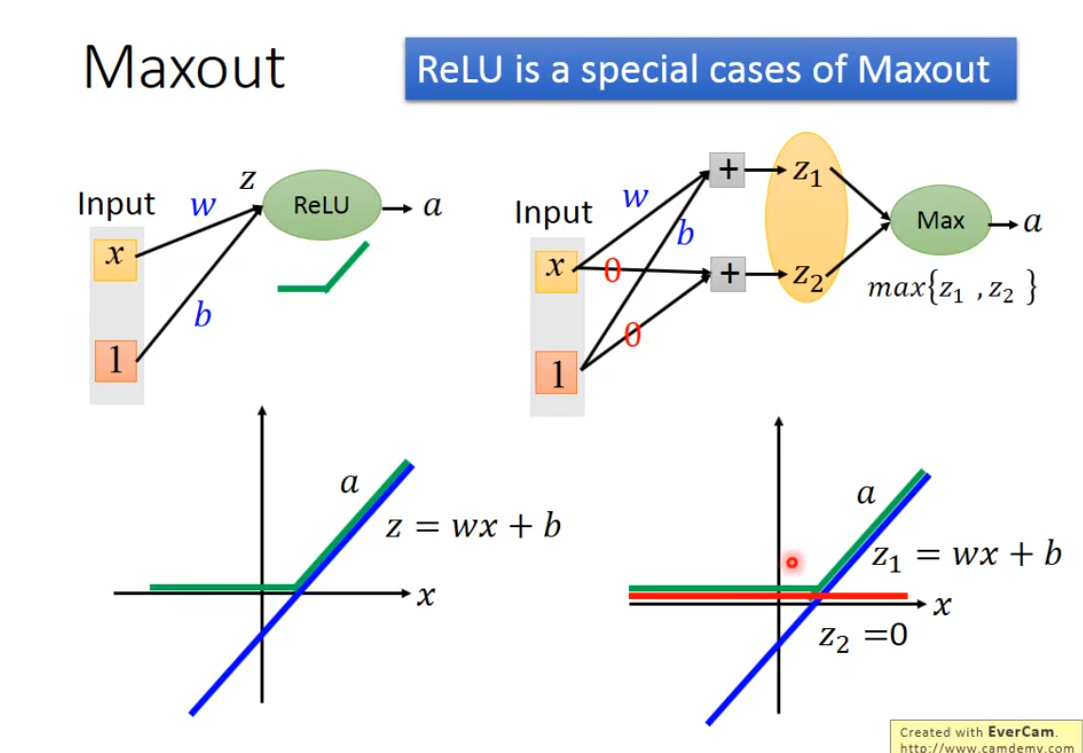

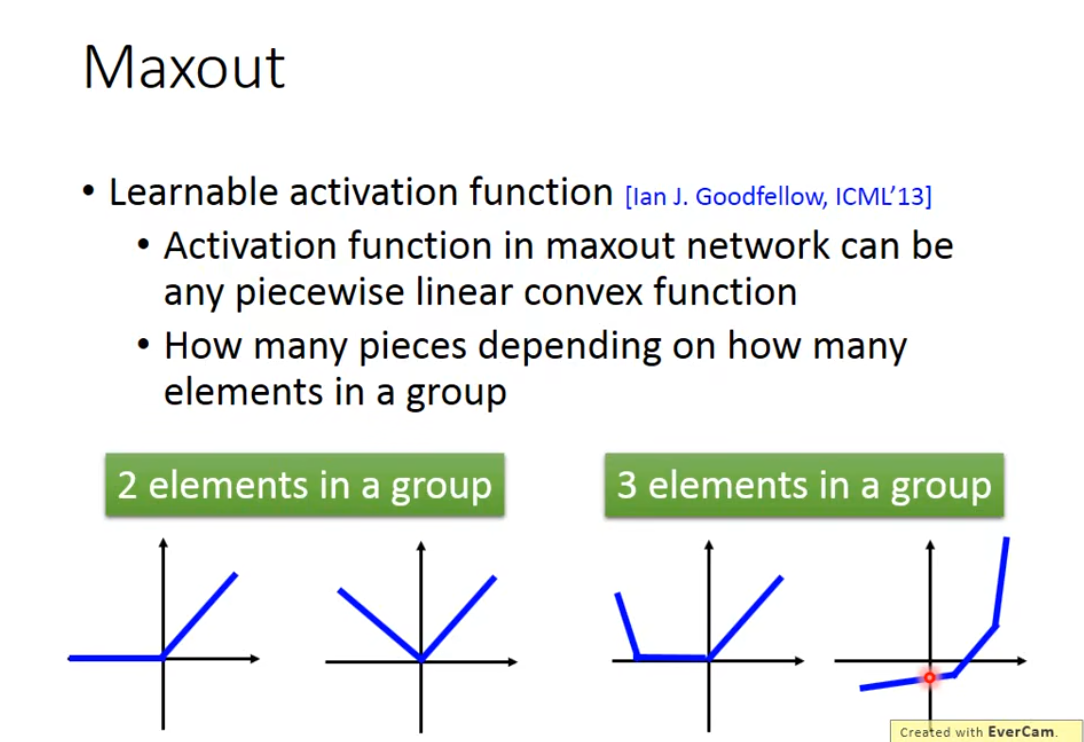
Maxout的特点:
可学习的激活函数 [Ian J. Goodfellow, ICML’13]Maxout 网络中的激活函数可以是任意分段线性凸函数。分段数量取决于一个组中有多少个元素。
当我们已知输入时,对输出结果我们只需要关注最大那个值,对其对应的L做微分即可,这样就能训练和做梯度下降