Hello-agents TASK03 第四章节 智能体经典范式构建
文章目录
- 智能体经典范式构建
- 配置 API 密钥
- 封装基础 LLM 调用函数
- ReAct
- ReAct 的工作流程
- 工具的定义与实现
- ReAct 智能体的编码实现
智能体经典范式构建
- ReAct (Reasoning and Acting): 一种将“思考”和“行动”紧密结合的范式,让智能体边想边做,动态调整。
- Plan-and-Solve: 一种“三思而后行”的范式,智能体首先生成一个完整的行动计划,然后严格执行。
- Reflection: 一种赋予智能体“反思”能力的范式,通过自我批判和修正来优化结果。
pip install openai python-dotenv
配置 API 密钥
为了让我们的代码更通用,我们将模型服务的相关信息(模型ID、API密钥、服务地址)统一配置在环境变量中。
在你的项目根目录下,创建一个名为 .env 的文件。
在该文件中,添加以下内容。你可以根据自己的需要,将其指向 OpenAI 官方服务,或任何兼容 OpenAI 接口的本地/第三方服务。
如果实在不知道如何获取,可以参考Datawhale另一本教程的1.2 API设置
# .env file
LLM_API_KEY="YOUR-API-KEY"
LLM_MODEL_ID="YOUR-MODEL"
LLM_BASE_URL="YOUR-URL"封装基础 LLM 调用函数
为了让代码结构更清晰、更易于复用,我们来定义一个专属的LLM客户端类。这个类将封装所有与模型服务交互的细节,让我们的主逻辑可以更专注于智能体的构建。
import os
from openai import OpenAI
from dotenv import load_dotenv
from typing import List, Dict# 加载 .env 文件中的环境变量
load_dotenv()class HelloAgentsLLM:"""为本书 "Hello Agents" 定制的LLM客户端。它用于调用任何兼容OpenAI接口的服务,并默认使用流式响应。"""def __init__(self, model: str = None, apiKey: str = None, baseUrl: str = None, timeout: int = None):"""初始化客户端。优先使用传入参数,如果未提供,则从环境变量加载。"""self.model = model or os.getenv("LLM_MODEL_ID")apiKey = apiKey or os.getenv("LLM_API_KEY")baseUrl = baseUrl or os.getenv("LLM_BASE_URL")timeout = timeout or int(os.getenv("LLM_TIMEOUT", 60))if not all([self.model, apiKey, baseUrl]):raise ValueError("模型ID、API密钥和服务地址必须被提供或在.env文件中定义。")self.client = OpenAI(api_key=apiKey, base_url=baseUrl, timeout=timeout)def think(self, messages: List[Dict[str, str]], temperature: float = 0) -> str:"""调用大语言模型进行思考,并返回其响应。"""print(f"🧠 正在调用 {self.model} 模型...")try:response = self.client.chat.completions.create(model=self.model,messages=messages,temperature=temperature,stream=True,)# 处理流式响应print("✅ 大语言模型响应成功:")collected_content = []for chunk in response:content = chunk.choices[0].delta.content or ""print(content, end="", flush=True)collected_content.append(content)print() # 在流式输出结束后换行return "".join(collected_content)except Exception as e:print(f"❌ 调用LLM API时发生错误: {e}")return None# --- 客户端使用示例 ---
if __name__ == '__main__':try:llmClient = HelloAgentsLLM()exampleMessages = [{"role": "system", "content": "You are a helpful assistant that writes Python code."},{"role": "user", "content": "写一个快速排序算法"}]print("--- 调用LLM ---")responseText = llmClient.think(exampleMessages)if responseText:print("\n\n--- 完整模型响应 ---")print(responseText)except ValueError as e:print(e)
ReAct
在准备好LLM客户端之后,我们将构建第一个,也是最经典的一个智能体范式ReAct(Reson+Act)
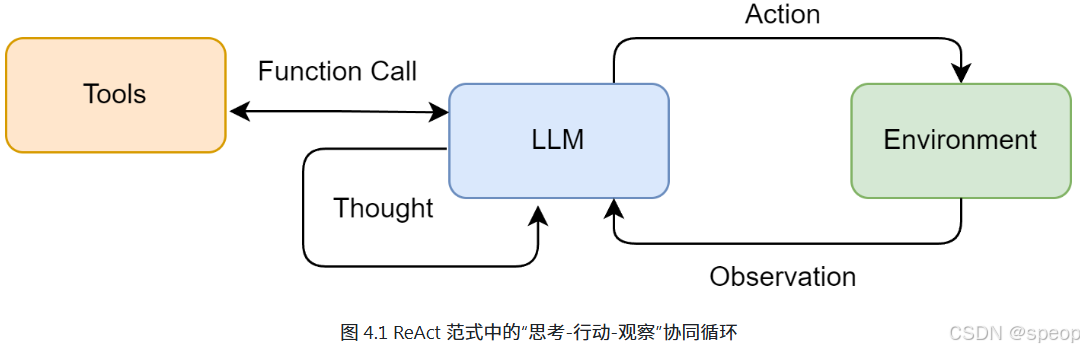
ReAct其核心思想是模仿人类解决问题的方式,将推理 (Reasoning) 与行动 (Acting) 显式地结合起来,形成一个“思考-行动-观察”的循环。
ReAct 的工作流程
在ReAct诞生之前,主流的方法可以分为两类:
一类是“纯思考”型,如思维链 (Chain-of-Thought),它能引导模型进行复杂的逻辑推理,但无法与外部世界交互,容易产生事实幻觉;
另一类是“纯行动”型,模型直接输出要执行的动作,但缺乏规划和纠错能力。
ReAct的巧妙之处在于,它认识到思考与行动是相辅相成的。思考指导行动,而行动的结果又反过来修正思考。为此,ReAct范式通过一种特殊的提示工程来引导模型,使其每一步的输出都遵循一个固定的轨迹:
- Thought (思考): 这是智能体的“内心独白”。它会分析当前情况、分解任务、制定下一步计划,或者反思上一步的结果。
- Action (行动): 这是智能体决定采取的具体动作,通常是调用一个外部工具,例如
Search['华为最新款手机']。 - Observation (观察): 这是执行Action后从外部工具返回的结果,例如搜索结果的摘要或API的返回值。
智能体将不断重复这个 Thought -> Action -> Observation 的循环,将新的观察结果追加到历史记录中,形成一个不断增长的上下文,直到它在Thought中认为已经找到了最终答案,然后输出结果。这个过程形成了一个强大的协同效应:推理使得行动更具目的性,而行动则为推理提供了事实依据。
我们可以将这个过程形式化地表示出来,如图所示。具体来说,在每个时间步t,智能体的策略(即大模型Π)会根据初始问题q和之间所有步骤的“行动-观察”历史轨迹((a1.o1),......,(at−1,ot−1))((a_1.o_1),......,(a_{t-1},o_{t-1}))((a1.o1),......,(at−1,ot−1))
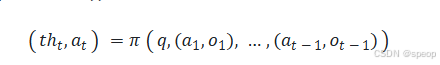
随后,环境中的工具T会执行行动ata_tat,并返回一个新的观察结果oto_tot:
ot=T(at)o_t=T(a_t)ot=T(at)
这个循环不断进行,将新的(at,ot)(a_t,o_t)(at,ot)对追加到历史中,直到模型在思考thtth_ttht中判断任务已完成。
这种机制特别适用于以下场景:
- 需要外部知识的任务:如查询实时信息(天气、新闻、股价)、搜索专业领域的知识等。
- 需要精确计算的任务:将数学问题交给计算器工具,避免LLM的计算错误。
- 需要与API交互的任务:如操作数据库、调用某个服务的API来完成特定功能。
因此我们将构建一个具备使用外部工具能力的ReAct智能体,来回答一个大语言模型仅凭自身知识库无法直接回答的问题。例如:“华为最新的手机是哪一款?它的主要卖点是什么?” 这个问题需要智能体理解自己需要上网搜索,调用工具搜索结果并总结答案。
工具的定义与实现
如果说大语言模型是智能体的大脑,那么工具 (Tools) 就是其与外部世界交互的“手和脚”。为了让ReAct范式能够真正解决我们设定的问题,智能体需要具备调用外部工具的能力。
针对本节设定的目标——回答关于“华为最新手机”的问题,我们需要为智能体提供一个网页搜索工具。在这里我们选用 SerpApi,它通过API提供结构化的Google搜索结果,能直接返回“答案摘要框”或精确的知识图谱信息,
首先,需要安装该库:
pip install google-search-results
同时,你需要前往 SerpApi官网 注册一个免费账户,获取你的API密钥,并将其添加到我们项目根目录下的 .env 文件中:
# .env file
# ... (保留之前的LLM配置)
SERPAPI_API_KEY="YOUR_SERPAPI_API_KEY"接下来,我们通过代码来定义和管理这个工具。我们将分步进行:首先实现工具的核心功能,然后构建一个通用的工具管理器。
(1)实现搜索工具的核心逻辑
一个良好定义的工具应包含以下三个核心要素:
- 名称 (Name): 一个简洁、唯一的标识符,供智能体在 Action 中调用,例如 Search。
- 描述 (Description): 一段清晰的自然语言描述,说明这个工具的用途。这是整个机制中最关键的部分,因为大语言模型会依赖这段描述来判断何时使用哪个工具。
- 执行逻辑 (Execution Logic): 真正执行任务的函数或方法。
我们的第一个工具是 search 函数,它的作用是接收一个查询字符串,然后返回搜索结果。
from serpapi import SerpApiClientdef search(query:str ) -> str:"""一个基于SerpApi的实战网页搜索引擎工具,它会智能的解析搜索结果,优先返回直接答案或知识图谱信息。"""print(f"正在执行[serpaApi]网页搜索:{query}")try:api_key = os.getenv("SERPAPI_API_KEY")if not api_key:return "错误:SERPAPI_API_KEY未设置"params = {"engine":"google","q":query,"api_key":api_key,"gl":"cn",#gl 代表 "geolocation"(地理位置)"hl":"zh-cn",#语言代码 "zh-cn"代表简体中文} client = SerpApiClient(params)results = client.get_dict()#智能解析:优先搜索最直接的答案if "answer_box_list" in results:return "\n".join(results["answer_box_list"])if "answer_box" in results and "answer" in results["answer_box"]:return results["answer_box"]["answer"]if "knowledge_graph" in results and "description" in results["knowledge_graph"]:return results["knowledge_graph"]["description"]#前两项都不存在时,检查是否存在知识图谱if "organic_results" in results and results["organic_results"]:snippets = [f"[{i+1}] {res.get('title','')}\n{res.get('snippet','')}"for i,res in enumerate(results["organic_results"][:3])]return "\n\n".join(snippets)#最低优先级:organic_resultsreturn f"对不起,没有找到关于'{query}'的信息。"except Exception as e:return f"搜索的时候发生错误:{e}"
(2) 构建通用的工具执行器
当智能体需要使用多种工具时(例如,除了搜索,还可能需要计算、查询数据库等),我们需要一个统一的管理器来注册和调度这些工具。为此,我们创建一个 ToolExecutor 类。
from typing import Dict, Anyclass ToolExecutor:"""一个工具执行器,负责管理和执行工具。"""def __init__(self):self.tools: Dict[str, Dict[str, Any]] = {}def registerTool(self, name: str, description: str, func: callable):"""向工具箱中注册一个新工具。"""if name in self.tools:print(f"警告:工具 '{name}' 已存在,将被覆盖。")self.tools[name] = {"description": description, "func": func}print(f"工具 '{name}' 已注册。")def getTool(self, name: str) -> callable:"""根据名称获取一个工具的执行函数。"""return self.tools.get(name, {}).get("func")def getAvailableTools(self) -> str:"""获取所有可用工具的格式化描述字符串。"""return "\n".join([f"- {name}: {info['description']}" for name, info in self.tools.items()])(3)测试
现在,我们将 search 工具注册到 ToolExecutor 中,并模拟一次调用,以验证整个流程是否正常工作。
# --- 工具初始化与使用示例 ---
if __name__ == '__main__':# 1. 初始化工具执行器toolExecutor = ToolExecutor()# 2. 注册我们的实战搜索工具search_description = "一个网页搜索引擎。当你需要回答关于时事、事实以及在你的知识库中找不到的信息时,应使用此工具。"toolExecutor.registerTool("Search", search_description, search)# 3. 打印可用的工具print("\n--- 可用的工具 ---")print(toolExecutor.getAvailableTools())# 4. 智能体的Action调用,这次我们问一个实时性的问题print("\n--- 执行 Action: Search['英伟达最新的GPU型号是什么'] ---")tool_name = "Search"tool_input = "英伟达最新的GPU型号是什么"tool_function = toolExecutor.getTool(tool_name)if tool_function:observation = tool_function(tool_input)print("--- 观察 (Observation) ---")print(observation)else:print(f"错误:未找到名为 '{tool_name}' 的工具。")>>>
工具 'Search' 已注册。--- 可用的工具 ---
- Search: 一个网页搜索引擎。当你需要回答关于时事、事实以及在你的知识库中找不到的信息时,应使用此工具。--- 执行 Action: Search['英伟达最新的GPU型号是什么'] ---
🔍 正在执行 [SerpApi] 网页搜索: 英伟达最新的GPU型号是什么
--- 观察 (Observation) ---
[1] GeForce RTX 50 系列显卡
GeForce RTX™ 50 系列GPU 搭载NVIDIA Blackwell 架构,为游戏玩家和创作者带来全新玩法。RTX 50 系列具备强大的AI 算力,带来升级体验和更逼真的画面。[2] 比较GeForce 系列最新一代显卡和前代显卡
比较最新一代RTX 30 系列显卡和前代的RTX 20 系列、GTX 10 和900 系列显卡。查看规格、功能、技术支持等内容。[3] GeForce 显卡| NVIDIA
DRIVE AGX. 强大的车载计算能力,适用于AI 驱动的智能汽车系统 · Clara AGX. 适用于创新型医疗设备和成像的AI 计算. 游戏和创作. GeForce. 探索显卡、游戏解决方案、AI ...
ReAct 智能体的编码实现
现在,我们将所有独立的组件,LLM客户端和工具执行器组装起来,构建一个完整的 ReAct 智能体。我们将通过一个 ReActAgent 类来封装其核心逻辑。为了便于理解,我们将这个类的实现过程拆分为以下几个关键部分进行讲解。
(1)系统提示词设计
提示词是整个 ReAct 机制的基石,它为大语言模型提供了行动的操作指令。我们需要精心设计一个模板,它将动态地插入可用工具、用户问题以及中间步骤的交互历史。
# ReAct 提示词模板
REACT_PROMPT_TEMPLATE = """
请注意,你是一个有能力调用外部工具的智能助手。可用工具如下:
{tools}请严格按照以下格式进行回应:Thought: 你的思考过程,用于分析问题、拆解任务和规划下一步行动。
Action: 你决定采取的行动,必须是以下格式之一:
- `{{tool_name}}[{{tool_input}}]`:调用一个可用工具。
- `Finish[最终答案]`:当你认为已经获得最终答案时。
- 当你收集到足够的信息,能够回答用户的最终问题时,你必须在Action:字段后使用 finish(answer="...") 来输出最终答案。现在,请开始解决以下问题:
Question: {question}
History: {history}
"""
这个模板定义了智能体与LLM之间交互的规范:
- 角色定义: “你是一个有能力调用外部工具的智能助手”,设定了LLM的角色。
- 工具清单 ({tools}): 告知LLM它有哪些可用的“手脚”。
- 格式规约 (Thought/Action): 这是最重要的部分,它强制LLM的输出具有结构性,使我们能通过代码精确解析其意图。
- 动态上下文 ({question}/{history}): 将用户的原始问题和不断累积的交互历史注入,让LLM基于完整的上下文进行决策。
(2) 核心循环的实现
ReActAgent的核心是一个循环,它不断地"格式化提示词->调用LLM->执行操作->整合结果".直到任务完整或达到最大步数限制。
class ReActAgent:def __init__(self, llm_client: HelloAgentsLLM, tool_executor: ToolExecutor, max_steps: int = 5):self.llm_client = llm_clientself.tool_executor = tool_executorself.max_steps = max_stepsself.history = []def run(self, question: str):"""运行ReAct智能体来回答一个问题。"""self.history = [] # 每次运行时重置历史记录current_step = 0
#while循环是主题while current_step < self.max_steps:#max_steps参数是一个重要的安全阀.防止智能体陷入无限循环耗尽资源.current_step += 1print(f"--- 第 {current_step} 步 ---")# 1. 格式化提示词tools_desc = self.tool_executor.getAvailableTools()history_str = "\n".join(self.history)prompt = REACT_PROMPT_TEMPLATE.format(tools=tools_desc,question=question,history=history_str)# 2. 调用LLM进行思考messages = [{"role": "user", "content": prompt}]response_text = self.llm_client.think(messages=messages)if not response_text:print("错误:LLM未能返回有效响应。")break# ... (后续的解析、执行、整合步骤)run方法是智能体的入口,它的while循环构成了ReAct范式的主体,max_steps参数则是一个重要的安全阀,防止智能体陷入无限循环而耗尽资源。
(3)输出解析器的实现
LLM 返回的是纯文本,我们需要从中精确地提取出Thought和Action。这是通过几个辅助解析函数完成的,它们通常使用正则表达式来实现。
# (这些方法是 ReActAgent 类的一部分)def _parse_output(self, text: str):"""解析LLM的输出,提取Thought和Action。"""thought_match = re.search(r"Thought: (.*)", text)action_match = re.search(r"Action: (.*)", text)thought = thought_match.group(1).strip() if thought_match else Noneaction = action_match.group(1).strip() if action_match else Nonereturn thought, actiondef _parse_action(self, action_text: str):"""解析Action字符串,提取工具名称和输入。"""match = re.match(r"(\w+)\[(.*)\]", action_text)if match:return match.group(1), match.group(2)return None, None
- _parse_output: 负责从LLM的完整响应中分离出Thought和Action两个主要部分。
- _parse_action: 负责进一步解析Action字符串,例如从 Search[华为最新手机] 中提取出工具名 Search 和工具输入 华为最新手机。
(4) 工具调用与执行
# (这段逻辑在 run 方法的 while 循环内)# 3. 解析LLM的输出thought, action = self._parse_output(response_text)if thought:print(f"思考: {thought}")if not action:print("警告:未能解析出有效的Action,流程终止。")break# 4. 执行Actionif action.startswith("Finish"):# 如果是Finish指令,提取最终答案并结束final_answer = re.match(r"Finish\[(.*)\]", action).group(1)print(f"🎉 最终答案: {final_answer}")return final_answertool_name, tool_input = self._parse_action(action)if not tool_name or not tool_input:# ... 处理无效Action格式 ...continueprint(f"🎬 行动: {tool_name}[{tool_input}]")tool_function = self.tool_executor.getTool(tool_name)if not tool_function:observation = f"错误:未找到名为 '{tool_name}' 的工具。"else:observation = tool_function(tool_input) # 调用真实工具这段代码是Action的执行中心。它首先检查是否为Finish指令,如果是,则流程结束。否则,它会通过tool_executor获取对应的工具函数并执行,得到observation。
(5)观测结果的整合
最后一步,也是形成闭环的关键,是将Action本身和工具执行后的Observation添加回历史记录中,为下一轮循环提供新的上下文。
# (这段逻辑紧随工具调用之后,在 while 循环的末尾)print(f"👀 观察: {observation}")# 将本轮的Action和Observation添加到历史记录中self.history.append(f"Action: {action}")self.history.append(f"Observation: {observation}")# 循环结束print("已达到最大步数,流程终止。")return None
通过将Observation追加到self.history,智能体在下一轮生成提示词时,就能“看到”上一步行动的结果,并据此进行新一轮的思考和规划。
(6)运行实例与分析
将以上所有部分组合起来,我们就得到了完整的 ReActAgent 类。完整的代码运行实例可以在本书配套的代码仓库 code 文件夹中找到。
下面是一次真实的运行记录:
工具 'Search' 已注册。--- 第 1 步 ---
🧠 正在调用 xxxxxx 模型...
✅ 大语言模型响应成功:
Thought: 要回答这个问题,我需要查找华为最新发布的手机型号及其主要特点。这些信息可能在我的现有知识库之外,因此需要使用搜索引擎来获取最新数据。
Action: Search[华为最新手机型号及主要卖点]
🤔 思考: 要回答这个问题,我需要查找华为最新发布的手机型号及其主要特点。这些信息可能在我的现有知识库之外,因此需要使用搜索引擎来获取最新数据。
🎬 行动: Search[华为最新手机型号及主要卖点]
🔍 正在执行 [SerpApi] 网页搜索: 华为最新手机型号及主要卖点
👀 观察: [1] 华为手机- 华为官网
智能手机 ; Mate 系列. 非凡旗舰 · HUAWEI Mate XTs. 非凡大师 ; Pura 系列. 先锋影像 · HUAWEI Pura 80 Pro+ ; Pocket 系列. 美学新篇. HUAWEI Pocket 2 ; nova 系列. 专业人像.[2] 2025年华为手机哪一款性价比高?华为手机推荐与市场分析 ...
现在华为手机最大的卖点只剩下鸿蒙HarmonyOS系统,以及饱受争议的品牌信仰。 这里推荐目前值得入手的几款华为系列手机,根据不同预算自行选择:. 华为目前最受欢迎,也是搭载 ...[3] 2025年华为新款手机哪个性价比高?10款华为新款手机推荐
选华为主要还是要推荐高端手机,Mate 70和Pura 70系列是最新发布的旗舰机型。 HUAWEI Mate 70. 优点是,拍照配置依旧顶级,全焦段覆盖,适合专业摄影,做工出色,户外抗摔 ...--- 第 2 步 ---
🧠 正在调用 xxxxxx 模型...
✅ 大语言模型响应成功:
Thought: 根据搜索结果,华为最新发布的旗舰机型包括Mate 70和Pura 80 Pro+。为了确定最新型号及其主要卖点,我将重点放在这些信息上。从提供的链接来看,Mate 70系列和Pura 80 Pro+都是近期发布的产品,但具体哪一个是“最新”还需要进一步确认。同时,我可以从这些信息中提取出它们的主要
卖点。
Action: Finish[根据最新信息,华为的最新手机可能是HUAWEI Pura 80 Pro+或HUAWEI Mate 70。其中,HUAWEI Mate 70的主要卖点包括顶级的拍照配置,全焦段覆盖,适合专业摄影,做工出色,并且具有良好的户外抗摔性能。而HUAWEI Pura 80 Pro+则强调了先锋影像技术。]
🤔 思考: 根据搜索结果,华为最新发布的旗舰机型包括Mate 70和Pura 80 Pro+。为了确定最新型号及其主要卖点,我将重点放在这些信息上。从提供的链接来看,Mate 70系列和Pura 80 Pro+都是近期发布的产品,但具体哪一个是“最新”还需要进一步确认。同时,我可以从这些信息中提取出它们的主要
卖点。
🎉 最终答案: 根据最新信息,华为的最新手机可能是HUAWEI Pura 80 Pro+或HUAWEI Mate 70。其中,HUAWEI Mate 70的主要卖点包括顶级的拍照配置,全焦段覆盖,适合专业摄影,做工出色,并且具有良好的户外抗摔性能。而HUAWEI Pura 80 Pro+则强调了先锋影像技术。