计算图优化技术综述(昇腾GE优化技术)
随着模型复杂度激增,带来计算资源消耗大、执行效率低的痛点。计算图作为深度学习的核心载体,以节点表示算子、边表示数据流,清晰刻画神经网络计算过程。而计算图优化技术通过算子融合、常量折叠等策略,简化图结构、减少冗余计算、提升资源利用率,成为突破 AI 性能瓶颈的关键。本文将系统梳理计算图优化的核心方法,拓展讲解昇腾GE优化技术。
开发者只需要使用PyTorch原生的torch.compile接口,昇腾AI处理器后端就会对PyTorch生成的计算图进行接管、转化为AIR,再进行端到端的图编译深度优化,降低内存需求、提升计算性能,同时最大程度减少开发者的修改工作。
当前业界主流的深度学习框架(例如PyTorch、TensorFlow等)都提供了Eager(Eager Execution,即时执行)模式与图模式。
Eager模式:
- 即时执行:每个计算操作在定义后立即执行,无需构建计算图。
- 动态计算图:每次运行可能生成不同的计算图。
图模式:
- 延迟执行:所有计算操作先构成一张计算图,再在会话中下发执行。
- 静态计算图:计算图在运行前固定。
成图以后,编译器的视角更广,计算操作可以更好地化简、优化,从而获得更好的执行性能。GE针对图进行了系列优化,包括通用的图优化技术“公共子表达式消除”、“剪枝”、“死边消除”,以及特有的Shape优化技术、内存优化技术等。下面对GE的图优化技术详细展开介绍。
通用图优化技术
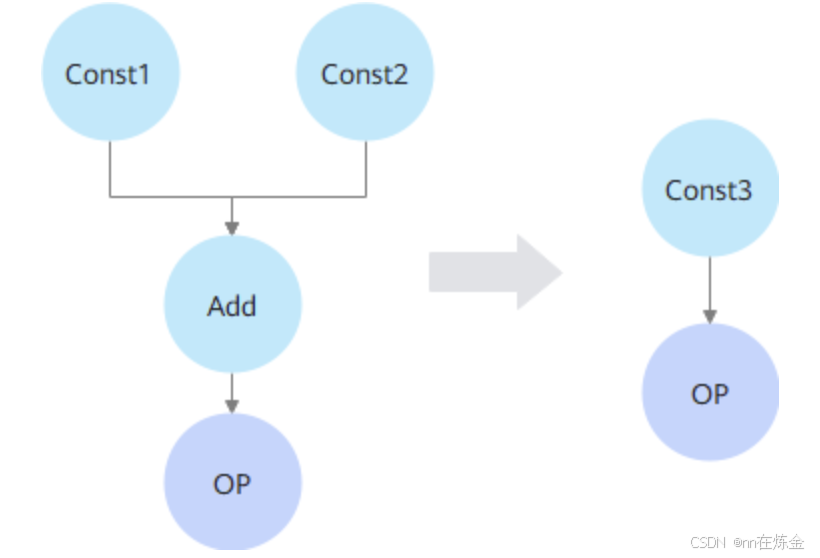
1)常量折叠
在编译阶段直接计算并替换常量表达式的值,从而减少运行时的计算负担
注:
1. Shape计算类算子(如Shape、Rank、Size等)。当Shape计算类算子的输入Shape为静态时,可以将其计算结果替换为Const。
2. Shape调整类算子(ExpandDims、Squeeze、Unsqueeze等)。当Shape调整类算子的输入Shape为静态时,可以将其从图中删除。
3. 所有输出均为空Tensor的算子。空Tensor的特点为Shape中包含0,意味着Tensor中无数据。因此可将其替换为Const,该Const仅用于承载描述原算子的输出Shape信息。
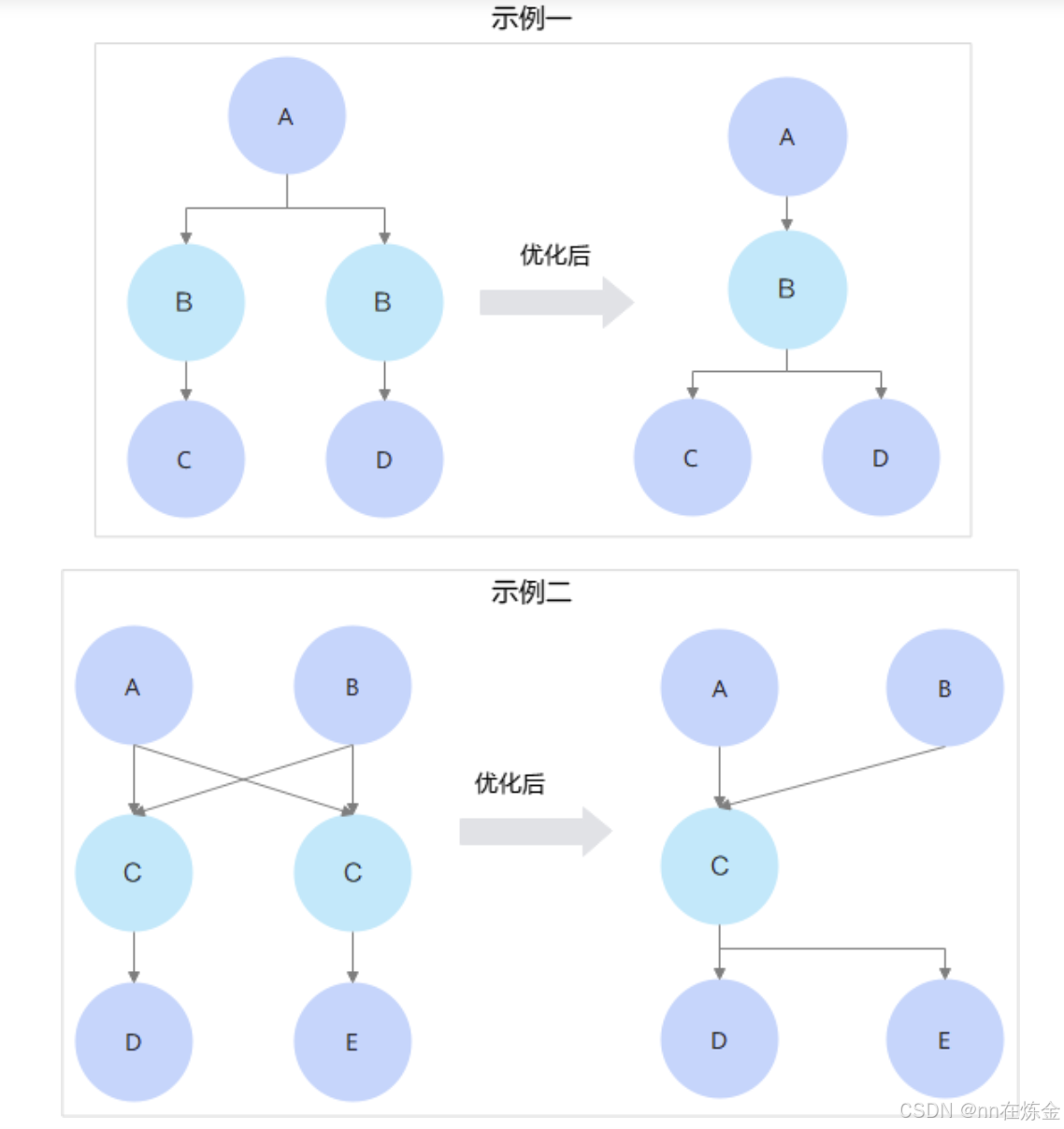
2)公共子表达式消除
消除识别图中相同的子表达式,将其合并为一份公共表达式
3)剪枝
在编译前指定输出节点,只保留对输出数据有贡献的节点,从而缩小模型大小,提升编译性能
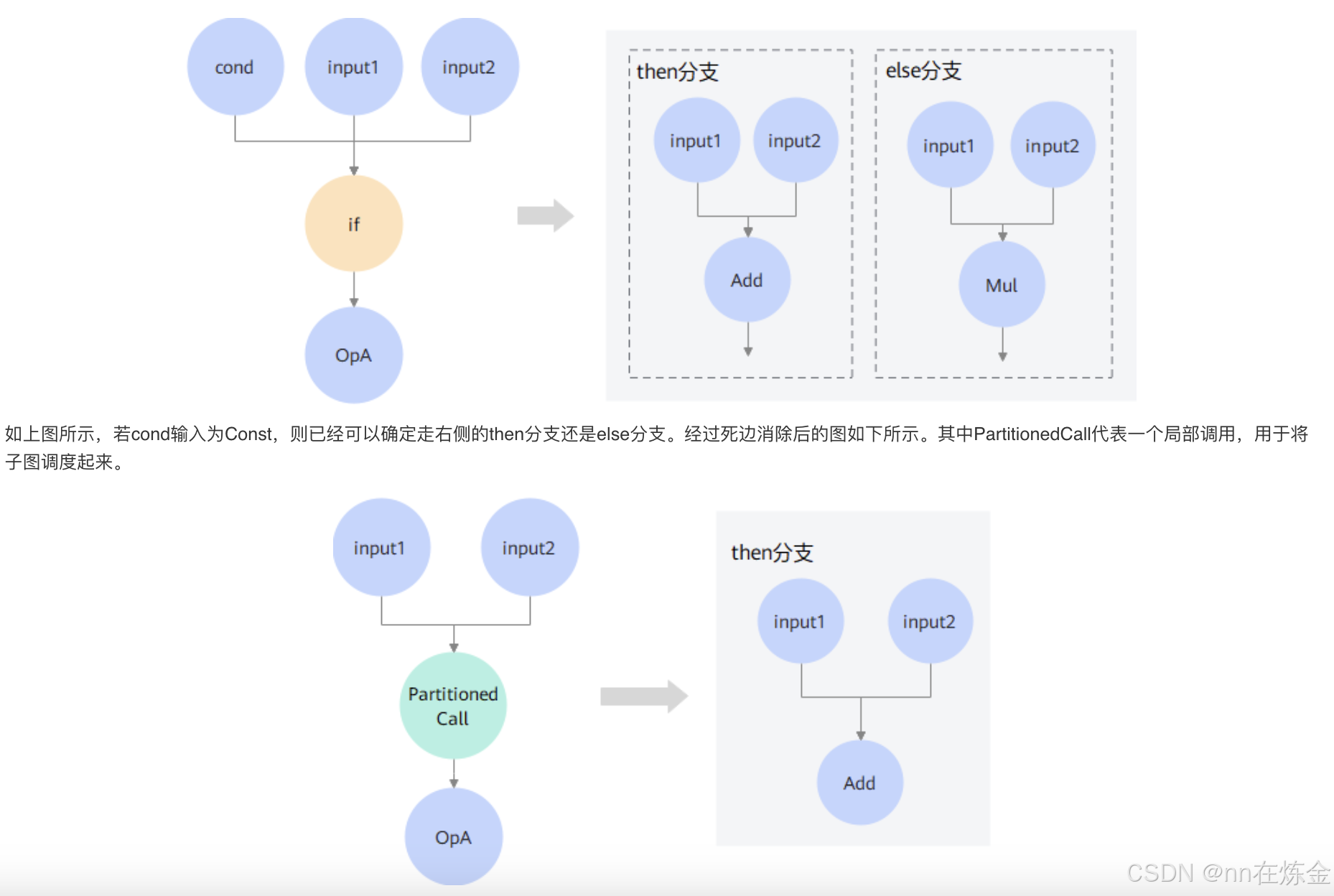
4)控制流优化 / 死边消除
原理:对图中的条件分支(如 If、Switch、While 等控制流算子)进行优化,包括分支合并、分支消除、循环展开等操作,减少控制流带来的额外开销。
价值:减少控制流决策的时间开销,提升模型执行的流畅性,尤其在推理场景中,可让模型执行更高效。
示例:
- 分支消除:如果通过分析发现某个条件分支的触发概率极低(比如小于 1%),且该分支对模型整体精度影响很小,就可以直接将这个分支消除,避免每次都要进行分支判断的开销。
- 循环展开:对于小型的循环(如循环次数较少的 While 循环),将循环体展开,减少循环控制的开销。
5)算子融合
原理:把多个功能上可以串联的算子合并成一个复合算子。因为原本多个算子执行时,每个算子都要单独处理输入输出的内存申请、数据搬运等操作,融合后这些开销会大幅减少
价值:减少内存访问次数和数据搬运时间,提升计算效率,同时也减少了算子调度的开销。
示例:
- 经典的 “卷积(Conv)+ 批量归一化(BN)+ 激活函数(Relu)” 三算子融合。原本 Conv 输出要存到内存,再作为 BN 的输入读取,BN 输出又存到内存作为 Relu 的输入,融合后三个操作在一个算子里完成,中间数据直接在寄存器级传递,无需内存搬运。
- 还有 “全连接(FC)+ Relu” 融合等,只要算子之间是顺序依赖且没有复杂的分支逻辑,都可尝试融合。
其他优化技术(与compile的编译后端强相关)
并行化优化、内存规划优化、精度优化与 TorchInductor 、torchair等这类编译后端高度强相关。这类后端作为计算图与硬件执行的中间核心层,其核心职责就是将抽象的计算图转化为高效代码,而这三种优化正是实现该目标的关键手段,且优化逻辑深度依赖后端的架构设计与硬件适配能力。
1)内存规划优化
原理:分析图中所有 Tensor 的生命周期(即从被创建到被销毁的时间段),然后根据这些信息来规划内存的分配和释放,让内存可以被重复利用,避免内存碎片化。
价值:降低内存占用,减少内存分配释放的耗时,提升内存使用效率,这对内存资源紧张的场景(如移动端推理)非常关键。
示例:
- 假设有 Tensor A 在算子 1 创建,在算子 3 销毁;Tensor B 在算子 2 创建,在算子 4 销毁。如果它们的生命周期没有重叠,就可以复用同一块内存区域来存储 A 和 B。
- 对于循环结构的图,比如 While 循环里的 Tensor,会分析循环内 Tensor 的创建销毁规律,规划循环内的内存复用。
2)并行化优化
原理:根据硬件的多核、多设备等并行能力,以及图中算子或子图之间的依赖关系,将可以并行执行的部分安排在不同的计算单元上同时执行。
价值:充分利用硬件的计算资源,提升整体的计算速度,缩短模型训练或推理的时间。
示例:
- 在多 CPU 核的环境下,若图中有两个算子 A 和 B,它们之间没有数据依赖(即 A 的输出不是 B 的输入),就可以将 A 分配到核 1,B 分配到核 2 并行执行。
- 在多 GPU 或多昇腾设备的环境下,对于大模型的分布式训练,会将不同的层或不同的 Batch 数据分配到不同设备上并行计算。
3)精度优化
原理:在保证模型精度损失可接受的前提下,降低部分算子或整个模型的计算精度,比如从单精度浮点(FP32)降低到半精度浮点(FP16),甚至是整数精度(INT8、INT4)。
价值:减少计算量,降低内存占用,提升模型在端侧设备(如手机、边缘设备)的推理速度,同时也能降低功耗。
示例:
- 模型量化是典型的精度优化手段,包括权重量化和激活量化。比如将训练好的模型中卷积层的权重从 FP32 量化为 INT8,推理时用 INT8 进行计算,大幅减少内存占用和计算量。
- 对于一些对精度不敏感的任务,如图像分类中的某些中间层,也可单独降低其计算精度。
GE特有增强图优化技术
Shape优化技术
通过多种手段将动态 Shape 转化为静态,解锁更多优化空间:
1)常量折叠与 Shape 推导协同
a. 背景
InferShape 本质是 “Shape 推导” 工具,核心作用是根据节点的输入信息和算子逻辑,算出该节点输出 Tensor 的具体 Shape,是深度学习编译器(GE 图引擎)的核心基础能力。
b. 流程
- 先执行一轮常量折叠:把图中能直接计算的常量节点(比如固定的 Shape 值、常量算子输入)替换为 Const,为 Shape 推导(InferShape)提供明确的输入依据。
- 基于折叠结果做 Shape 推导(InferShape):用已知的 Const 输入,计算依赖它的节点的具体 Shape(比如 Reshape 算子的输入 Shape 是 Const,就能推导出它的输出 Shape)。
- 再基于推导结果二次折叠:新推导出的静态 Shape 会让更多算子满足 “输入全为常量” 的条件,再次执行常量折叠,删除或替换这些算子。
- 循环直至稳定:重复 “折叠→推导” 步骤,直到没有新的常量节点可折叠、所有能静态化的 Shape 都已确定,流程终止。
c. 举例
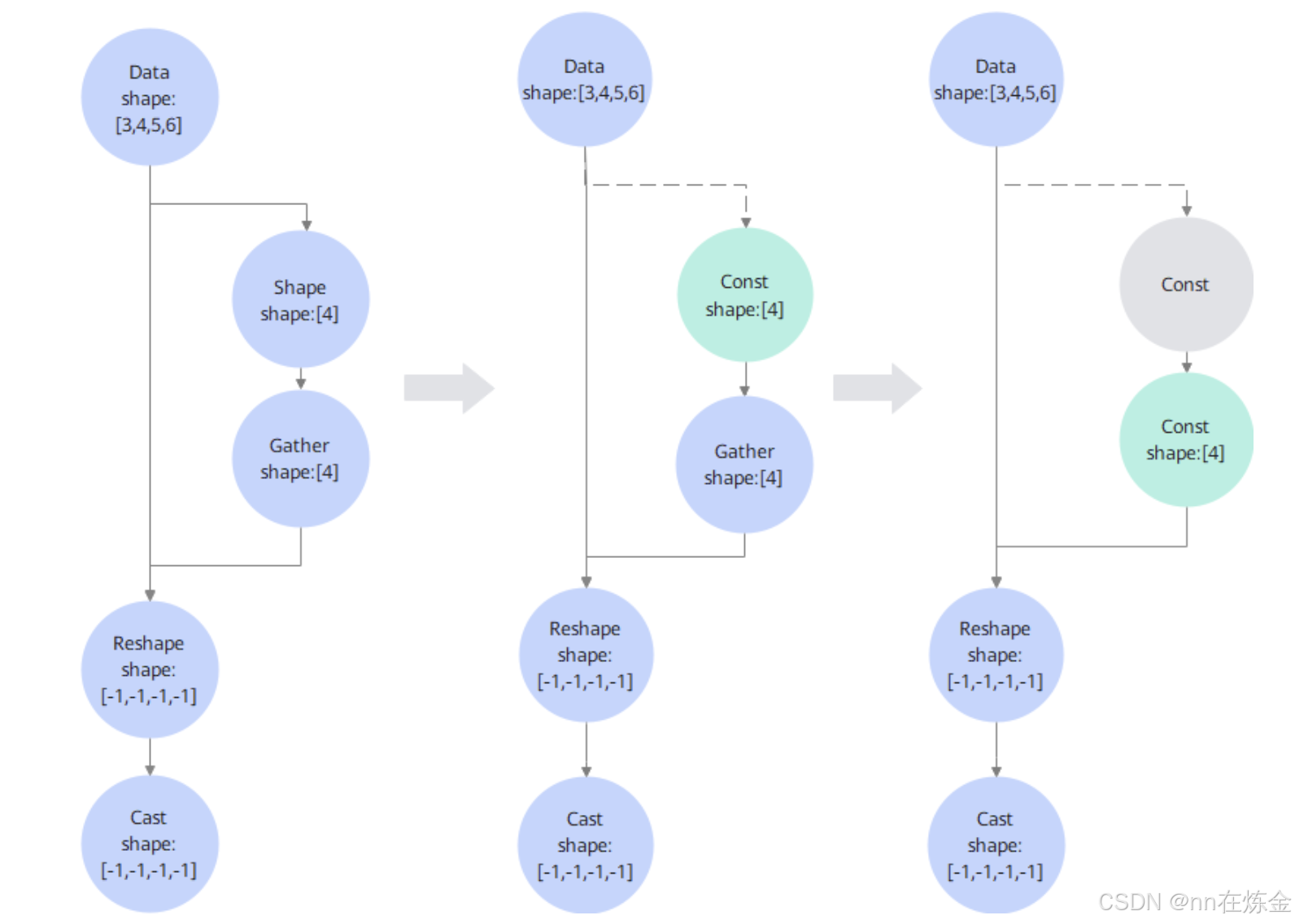
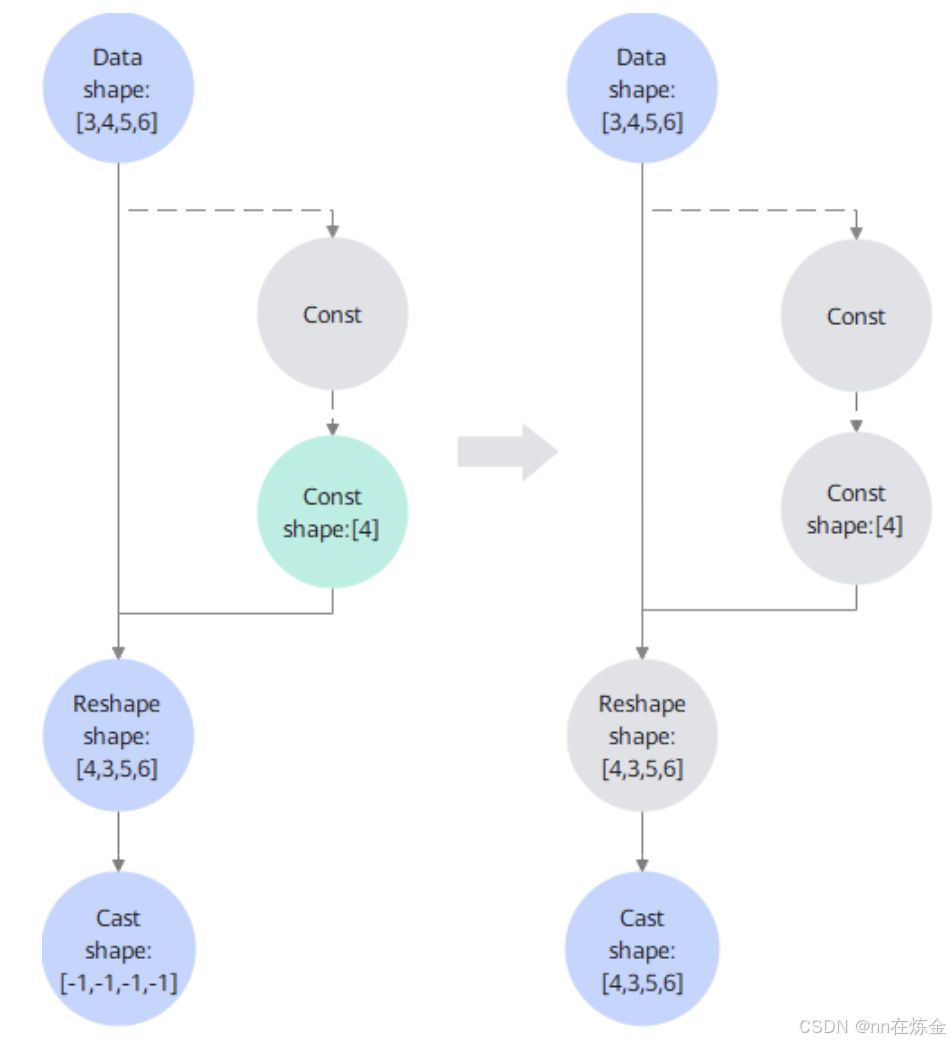
以 “Data→Shape→Gather→Reshape→Cast” 的流程为例:
- 初始状态:Data 的 Shape 是 [3,4,5,6](已知),但 Reshape 的输入 Shape 来自 Gather 算子,且 Gather 的 indices 是常量 [1,0,2,3]。
- 第一次折叠:先对 Gather 做常量折叠(输入是常量),得到固定的 Shape 输入 [4](原本是动态的 [-1,-1,-1,-1])。
- 第一次推导:用 Gather 输出的 Const Shape [4],对 Reshape 做 InferShape,算出 Reshape 的输出 Shape 是 [4,3,5,6](从动态变静态)。
- 第二次折叠:Reshape 的输出 Shape 已静态,其下游的 Cast 算子输入 Shape 明确,再对 Cast 做 InferShape,得出 Cast 的输出 Shape 也是 [4,3,5,6]。
- 终止条件:此时所有节点的 Shape 都已静态化,没有可继续折叠的节点,协同流程结束。
2)循环算子多次模拟推导输出静态Shape
a. 背景
While 循环算子是循环执行 body 子图(循环体)的算子,编译时存在如下关键问题:
- 循环次数不确定,无法直接知道 body 子图执行多少次。
- body 子图中若有维度调整算子(如 Reshape、Gather),可能导致每次执行后输出 Shape 变化,最终输出 Shape 呈 “Unknown Rank”(维度数都不确定)或完全动态。动态 Shape 会限制算子融合、模型下沉等优化,还可能降低调度效率。
b. 流程
核心思路是 “模拟循环执行,直到 Shape 稳定收敛”,具体步骤如下:
- 初始化输入 Shape:用编译时已知的初始输入 Shape(比如第一次进入循环的 Tensor 维度),作为 body 子图的初始输入。
- 第一次推导:执行 body 子图的 Shape 推导(InferShape),得到第一次循环后的输出 Shape(记为 Shape1)。
- 迭代推导:把上一次的输出 Shape(Shape1)作为新的输入 Shape,再次推导 body 子图的输出 Shape(记为 Shape2)。
- 收敛判断:对比前后两次的输出 Shape(Shape1 和 Shape2),如果完全一致,说明 Shape 不再变化,达到稳定状态。
- 确定最终 Shape:将稳定后的 Shape 作为 While 算子的最终输出 Shape;若未收敛(极端情况),则保留关键维度信息(如已知维度数,仅数值不确定),避免完全动态。
3)动态分档
a. 背景
很多实际场景中,模型输入 Shape 无法固定。比如智能交通的应用中,需要视频结构化的应用框架,往往需要先做人机非目标检测,再针对每一个行人、机动车、非机动车目标做相对应的属性识别。这类应用场景中,检测模型往往输入的个数不固定,检测到的目标分辨率大小不固定,因此相应的属性识别模型的输入也就不固定。导致:
- 动态 Shape 难以触发算子融合、模型下沉等优化,性能受限;
- 若为每个可能的 Shape 单独编译模型,会增加加载开销和内存占用。动态分档就是在 “动态输入需求” 和 “静态优化性能” 之间找平衡。
b. 原理
将可变输入 Shape(如 BatchSize、ImageSize)映射为离散固定档位,加载一次模型即可支持多档位动态输入,仍以静态方式下沉执行。
- 兼顾灵活性与性能:支持动态输入 Shape,但执行时走静态子图流程,性能接近纯静态模型。
- 降低部署成本:只需加载一次模型(包含所有档位子图),无需为每个 Shape 单独部署,减少内存占用和加载耗时。
- 适配复杂场景:尤其适合 BatchSize、ImageSize 有规律变化(如倍数关系)的推理场景,覆盖多数动态输入需求。
c. 举例
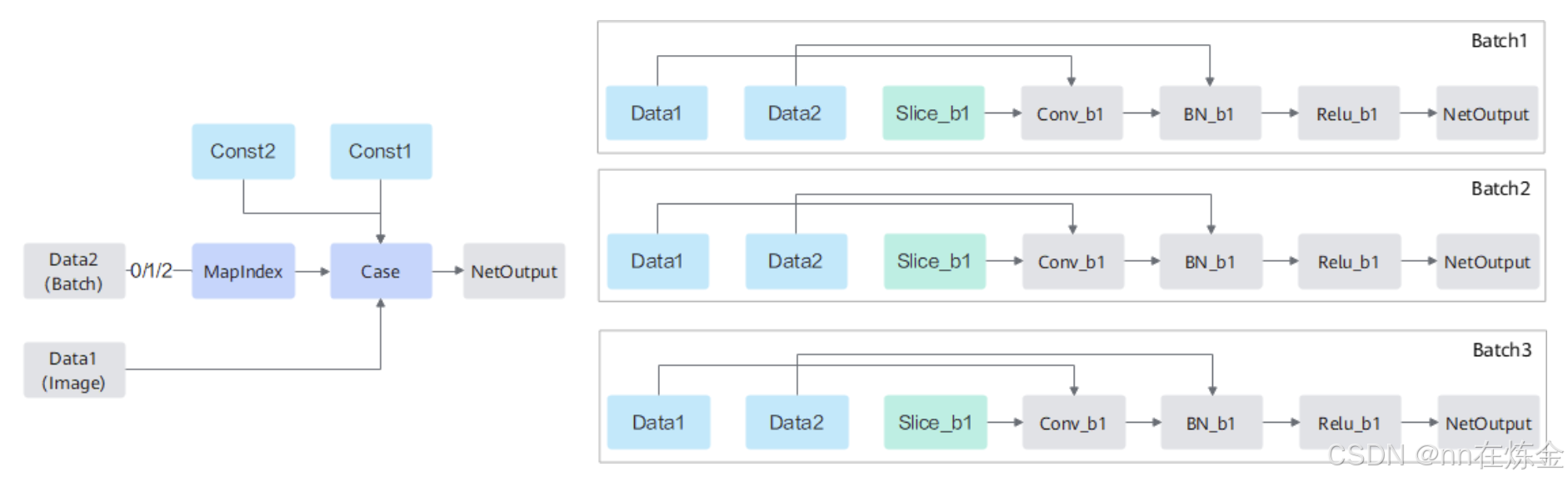
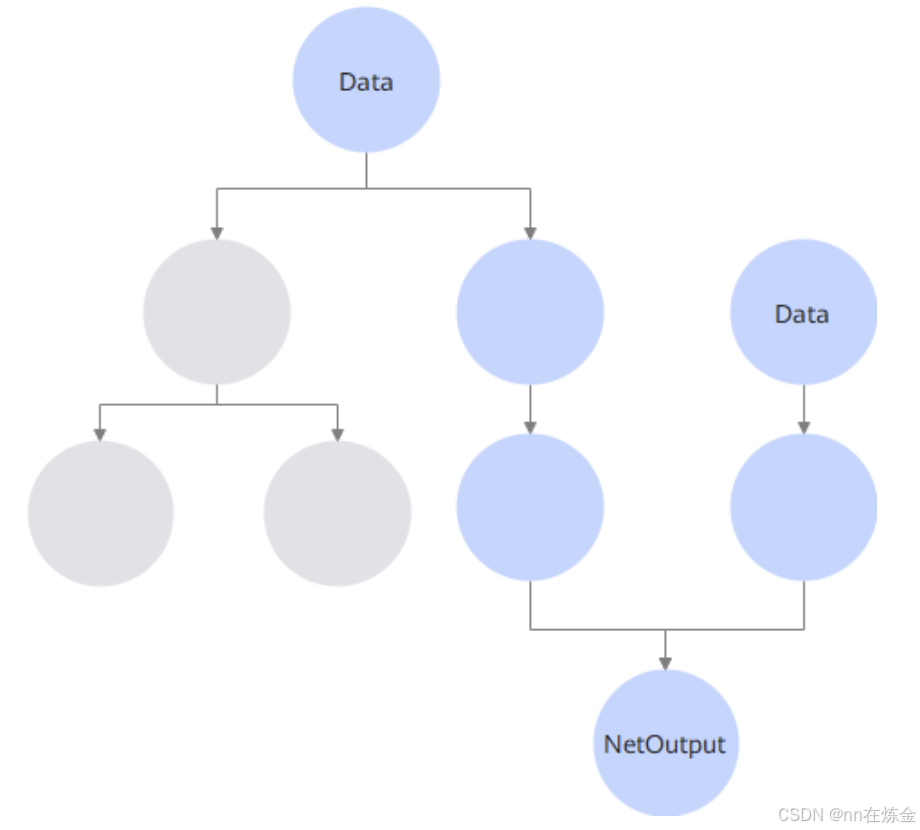
左图是动态分档的逻辑入口:
- Data1(Image):网络原始输入,其
shape被设置为最大档位值(比如支持 BatchSize 1~8,则 Data1 的 Batch 维度设为 8),确保能覆盖所有档位的输入范围。 - Data2(Batch):真实业务的动态档位输入(比如实际 BatchSize 是 3),自动加入 Graph 中传递真实维度信息。
- MapIndex 算子:核心 “翻译官”,接收 Data2 的真实档位值,计算出对应的索引(index)(比如 BatchSize 3 对应索引 1),为后续子图选择提供依据。
- Case 算子:“分支选择器”,根据 MapIndex 输出的索引,从多个预编译的子图中选择对应档位的子图执行。
- Const1/Const2:编译时确定的档位配置常量(比如预设的 BatchSize 档位列表 [1,2,4,8]),为 MapIndex 的映射逻辑提供参考。
右图是静态子图分支(以 Batch1、Batch2、Batch3 为例):
- 每个子图都是对原图的静态化复制,且针对对应档位的 Shape 做了全量优化(比如算子融合、模型下沉)。
- 以 “Slice→Conv→BN→Relu” 的流程为例,每个子图的算子都基于该档位的固定 Shape 编译,执行时无需再做动态调整,性能接近纯静态模型。
d. 流程
- 输入阶段:Data1(最大档位 Shape)和 Data2(真实动态 Shape)同时输入 Graph。
- 映射阶段:MapIndex 根据 Data2 的真实值和 Const 配置,计算出对应档位的索引(如 BatchSize 3→索引 1)。
- 选择阶段:Case 算子根据索引,选择对应的子图(如 Batch2 子图)。
- 执行阶段:选中的子图以静态 Shape 执行推理,输出 NetOutput。
内存优化技术
GE 的内存优化技术核心是对 Const 节点(主要存储模型权重)进行内存去重,从图优化阶段和Device 拷贝阶段两个层面减少 Host 与 Device 的内存占用。
1)图优化阶段,精准去重
这一阶段的核心是从逻辑到二进制的分层验证,确保只删除真正冗余的 Const:
- 权重描述相同:先比对权重的元信息(如维度、数据类型、初始化方式),快速过滤明显不同的 Const。
- 所有属性相同:再检查 Const 的全部属性(如是否可训练、是否参与量化),进一步缩小范围。
- 权重二进制比对相同:最后对权重的二进制内容做逐字节比对,确保数值完全一致(比如两个 Const 都存储
[0.5, 0.5]的二进制流完全相同)。只有同时满足这三级条件,才会删除冗余 Const,保留其中一个。
2)Device 拷贝阶段,兜底内存共享
这一步是对图优化阶段的补充,解决两类特殊场景的冗余:
- 图结构限制:比如某些 Const 因算子融合后形成循环依赖,图优化阶段无法删除,此时在 Device 拷贝前通过二进制比对,仍可共享内存。
- Shape 描述差异:若两个 Const 的 Shape 表面不同但实际存储权重二进制相同(比如一个是
[2,2]、另一个是[4]但数值完全一样),也能通过二进制比对实现共享。