(4)Kafka消费者分区策略、Rebalance、Offset存储机制
1.Kafka消费者分区分配策略
Kafka主要有三种分区分配策略:Range(范围分配策略)、RoundRobin(轮询)和Sticky(粘性)。消费者端的配置参数 partition.assignment.strategy用于设置策略。
以下分区分配策略均基于这两个主题和消费者组开展:Order订单主题有7个分区(P0-P6),Stock库存主题有5个分区,一个消费者组G1有3个消费者(C1, C2, C3)。
1.1Range(范围分配策略)
这是默认的策略。它首先将主题的分区按名称排序,然后将消费者按名称排序,最后以“范围”的方式将分区分配给消费者。分配过程:
(1)分区排序:Order[P0, P1, P2, P3, P4, P5, P6]、Stock[P0, P1, P2, P3, P4]
(2)消费者排序:[C1, C2, C3]
(3)计算每个消费者应分配的分区数:Order[7 / 3 = 2,余数1]、Stock[5 / 3 = 1,余数2]。
根据公式,Order订单主题分区前1个消费者(即C1)多分配一个分区,Stock库存主题分区前两个消费者(即C1、C2)多分配两个分区。如下图所示:
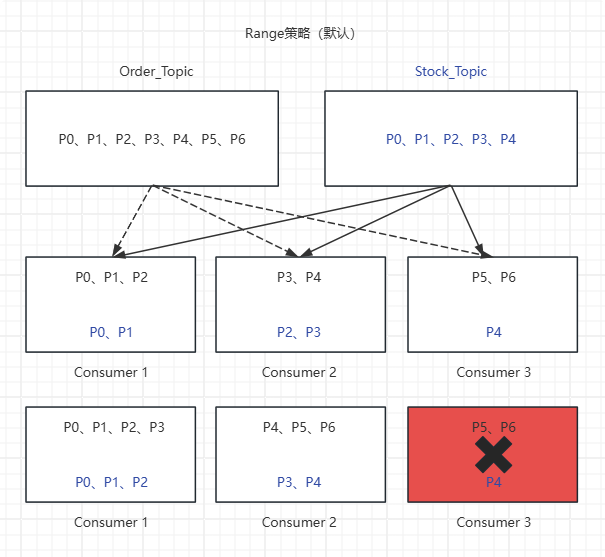
(4)触发重平衡,假设消费者C3崩溃退出,重平衡后结果对比如下:
触发重平衡前:
C1 -> Order主题:P0, P1,P2、Stock主题:P0, P1
C2 -> Order主题:P3, P4、Stock主题:P2, P3
C3 -> Order主题:P5, P6、Stock主题:P4
触发重平衡后:
C1 -> Order主题:P0, P1,P2,P3、Stock主题:P4, P5, P6
C2 -> Order主题:P0, P1, P2、Stock主题:P3, P4
(5)优缺点分析
| 优点 | 缺点 |
| 实现简单,逻辑直观。 | 容易导致数据倾斜:当订阅多个主题时,分区数少的主题可能全部分配给少数消费者。例如,Order_Topic有7个分区,Stock_Topic有5个分区,C1将分配到Order_Topic(3个) + Stock_Topic(2个)=5个,C2将分配到Order_Topic(2个) + Stock_Topic(2个)=4个,而C3只有Order_Topic(2个)+Stock_Topic(1个)=3个。 |
| - | 在消费者组元数据变更(重平衡)时,可能会导致不必要的分区移动,即使部分消费者没有变化。 |
1.2RoundRobin(轮询分配器)
该策略将消费者组内所有消费者和所有主题的分区进行全局排序,然后依次以轮询的方式分配给每个消费者。分配过程:
(1)所有分区全局排序:Order[P0, P1, P2, P3, P4, P5, P6]、Stock[P0, P1, P2, P3, P4]。
(2)所有消费者全局排序:[C1, C2, C3]。
从第一个分区开始,依次轮询分配给消费者。如下图所示:

(4)触发重平衡,假设消费者C3崩溃退出,重平衡后结果对比如下:
触发重平衡前:
C1 -> Order主题:P0, P3,P6、Stock主题:P0, P3
C2 -> Order主题:P1, P4、Stock主题:P1, P4
C3 -> Order主题:P2, P5、Stock主题:P2
触发重平衡后:
C1 -> Order主题:P0, P2,P4,P6、Stock主题:P0, P2, P4
C2 -> Order主题:P1, P3, P5、Stock主题:P1, P3
(5)优缺点分析
| 优点 | 缺点 |
| 负载均衡性好:在消费者性能相近的情况下,能实现最均匀的分配。 | 依赖前置条件:必须保证所有消费者订阅相同的主题。如果订阅信息不同,会导致分配混乱。 |
| 全局最优分配:对于单个主题或多个主题但分区数相近的情况,分配非常均衡。 | 在消费者组元数据变更(重平衡)时,可能会导致不必要的分区移动,即使部分消费者没有变化。 |
1.3Sticky(粘性分配策略)
Sticky意为粘性,是RoundRobin的增强版。它有两个目标:
(1)尽可能实现均衡分配(与RoundRobin类似)。
(2)在发生重平衡时,尽可能地保留之前的分配关系,只进行最小必要的调整。如下图所示:
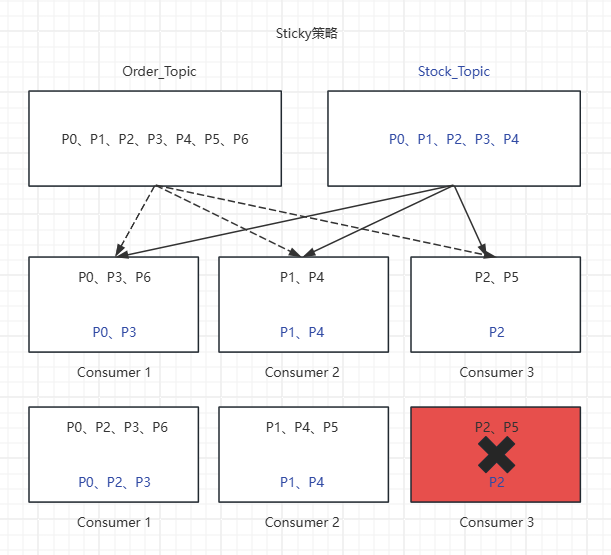
(3)触发重平衡,假设消费者C3崩溃退出,重平衡后结果对比如下:
触发重平衡前:
C1 -> Order主题:P0, P3,P6、Stock主题:P0, P3
C2 -> Order主题:P1, P4、Stock主题:P1, P4
C3 -> Order主题:P2, P5、Stock主题:P2
触发重平衡后:
C1 -> Order主题:P0, P2,P3,P6、Stock主题:P1, P4, P5
C2 -> Order主题:P0, P2, P3、Stock主题:P1, P4
虽然结果和RoundRobin一样,但分配过程不同。Sticky策略会先尝试保留C3原有的Order主题分区P0,P1,P3,P4,P6,Stock主题分区P0, P1,P3,然后将Order主题“孤儿分区”P2,P5,Stock主题“孤儿分区”P2,分别以均衡的方式分配给C1与C2。在更复杂的场景下(例如新增消费者),Sticky能显著减少分区的移动。
(5)优缺点分析
| 优点 | 缺点 |
| 实现了负载均衡。 | 算法相对复杂。 |
| 最大程度减少重平衡:在消费者失效或加入时,能最小化分区移动,从而减少系统开销和恢复时间。 | 是较新的策略,可能在非常老的客户端版本中不支持(但现在已广泛支持)。 |
| 兼顾了公平性和效率,是现代Kafka环境下的推荐策略。 | - |
2.重平衡(Rebalance)
Rebalance由组协调者负责触发。组协调者是Kafka集群中某个Broker(由Group ID的哈希值决定)。触发条件主要有以下四种:
(1)组成员变化(最常见):
●新消费者加入组:例如,你扩容了消费者实例。
●消费者主动离开组:例如,消费者被正常关闭(consumer.close())。
●消费者崩溃或被动离开:例如,消费者进程挂掉、网络中断、或长时间无法向协调者发送心跳。
(2)订阅的Topic分区数发生变化:
●管理员使用kafka-topics.sh脚本增加了主题的分区数量。这时,新增加的分区需要被分配给组内的消费者。
(3)订阅的Topic本身发生变化:
●消费者使用正则表达式订阅主题(如test-*),此时有匹配该正则的新主题被创建,也会触发Rebalance。
3.Offset存储机制
Offset是Kafka的核心概念之一,它表示消费者在某个分区(Partition)中当前消费到的位置。Offset存储机制的核心问题是:消费者消费到了哪里?这个位置需要被持久化,以便在消费者重启、崩溃或再平衡后能够从正确的位置继续消费。Kafka的Offset存储机制主要经历了两个阶段:
●默认存储在ZooKeeper中(旧版本)
●默认存储在Kafka内部的__consumer_offsets主题中(新版本)
3.1存储在Kafka内部主题__consumer_offsets(现行默认方案)
这是目前推荐且默认的 Offset 存储方式。Kafka创建了一个名为__consumer_offsets的特殊、内部的Kafka主题来存储所有消费者组的位移信息。
(1)__consumer_offsets主题详解
●本质:一个普通的Kafka Topic,但由Kafka自身自动管理。
●分区数:默认50个分区(由offsets.topic.num.partitions配置)。这保证了高并发写的性能,分散了写入压力。
●副本数:默认3个副本(由offsets.topic.replication.factor配置),保证了高可用性。
●日志清理策略:设置为compact(压缩)。这意味着它只保留每个Key的最新值。对于Offset场景,Key是[group_id, topic, partition],Value就是最新的offset及相关元数据。这种设计可以保证主题不会无限增长,并且能快速定位到某个消费者组在某个分区的最终位移。
(2)键(Key)和值(Value)的结构
提交到 __consumer_offsets 的消息有其固定的格式:
●Key: [group_id, topic, partition_id]
唯一标识了“哪个消费者组”对“哪个主题的哪个分区”的位移。
●Value: [offset, metadata, timestamp, ...]
◎offset:提交的位移值。
◎metadata:一些附属信息,通常为空。
◎timestamp:提交时间戳。
(3)工作流程
●消费消息:消费者从Broker拉取消息并进行处理。
●提交位移:
◎自动提交:消费者客户端默认每隔5秒(enable.auto.commit=true)自动向__consumer_offsets主题提交一次位移。这个提交是异步的。
◎手动提交:开发者可以调用consumer.commitSync()(同步)或consumer.commitAsync()(异步)来精确控制位移(enable.auto.commit=false)手动提交的时机,实现“至少一次”或“仅一次”语义。
●Broker处理:Kafka Broker接收到位移提交请求后,就像处理普通消息一样,将其写入__consumer_offsets主题的对应分区。
◎分区选择:根据group_id的哈希值对50取模,决定写入到__consumer_offsets的哪个分区。这保证了同一个消费者组的全部位移信息都存储在同一个分区内,便于管理和查找。
●位移查询:当消费者启动或发生再平衡时,它需要知道从哪个位置开始消费。它会向Broker发送一个“获取位移”的请求,Broker会从__consumer_offsets主题中查找该消费者组对应的最新位移并返回。
(4)优势
●高性能与高吞吐:利用Kafka自身的高性能特性,可以轻松应对海量的位移提交请求。
●内置与统一:无需依赖外部系统,所有数据(消息和位移)都在Kafka集群内,简化了运维和架构。
●容错性好:由于__consumer_offsets本身就是一个多副本的Topic,其数据是持久化和高可用的。
参考文献:
Kafka官网https://kafka.apache.org/documentation/#gettingStarted