DiT block学习
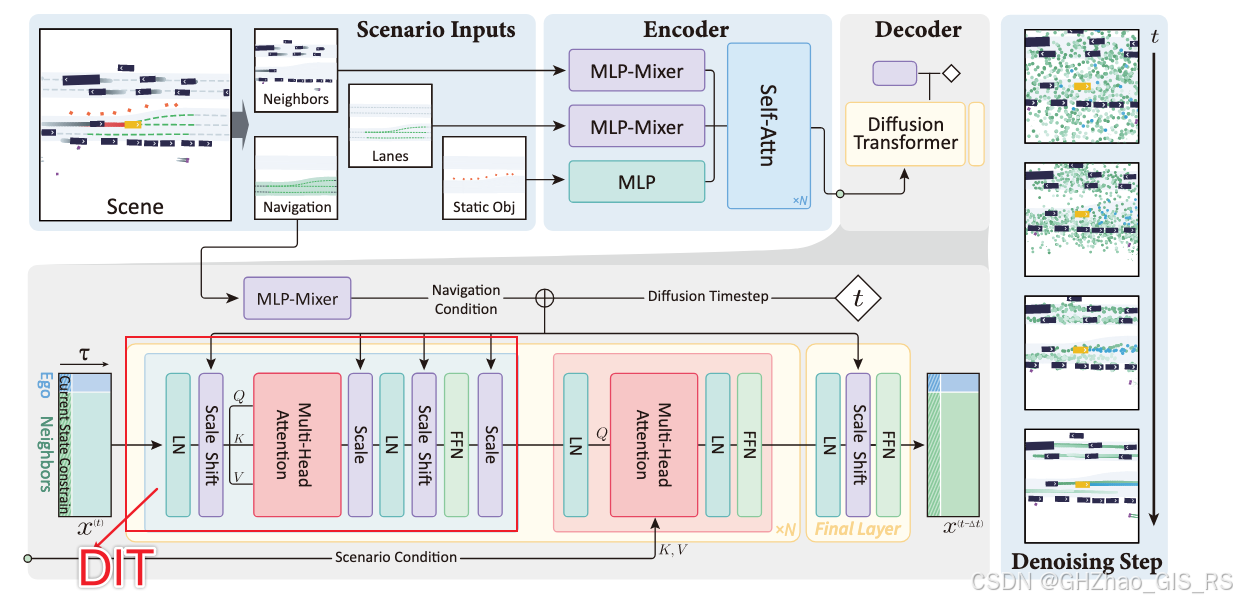
最近在做DIffusion-Planner的相关工作,其中用到了Dit模块,这个模块来自论文《Scalable Diffusion Models with Transformers 》,主要是开发了一种基于Transformer的扩散模型,Diffusion Transformers(DiT),这篇文章记录一下对DiT结构的学习。
架构设计
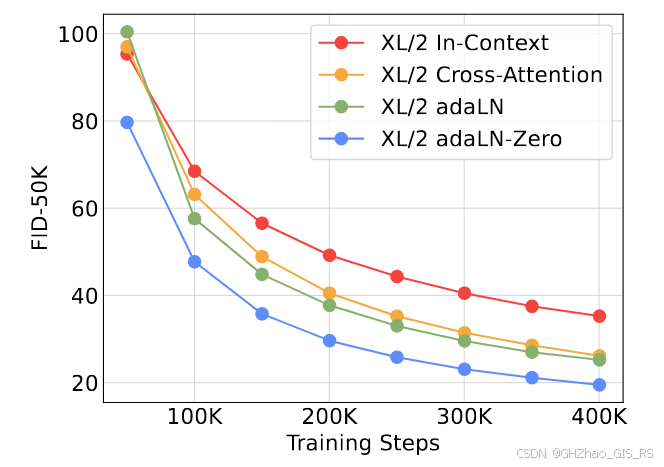
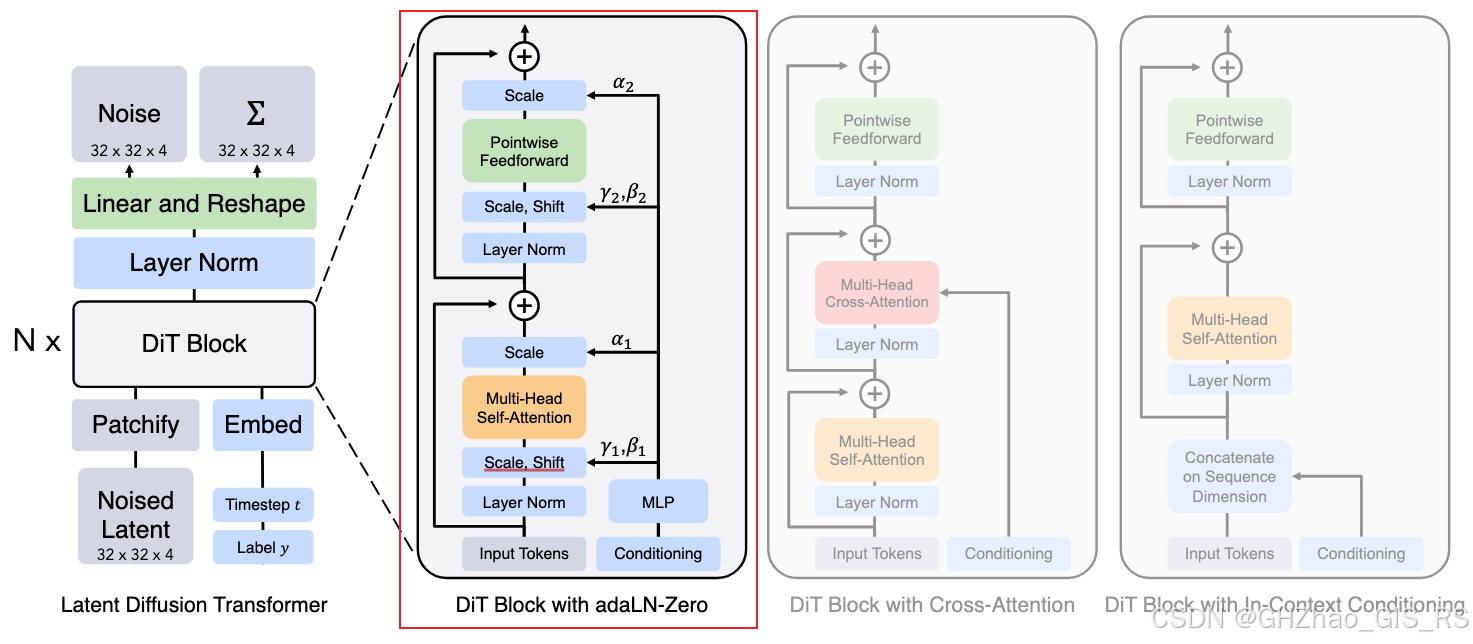
在这里只关注其中的DiT Block部分,这也是DiT的核心内容。对于DiT Block的网络结构设计,作者做了四个尝试。
1)In-context conditioning
这是一种简单直观的条件注入方法,即将时间t和其他条件(如图像生成中的类别C,轨迹规划中的route信息)与token(patch后的图像,真实专家轨迹)进行拼接,然后就可以用标准的ViT模型了,在最后一个Transformer块之后,移除条件token。
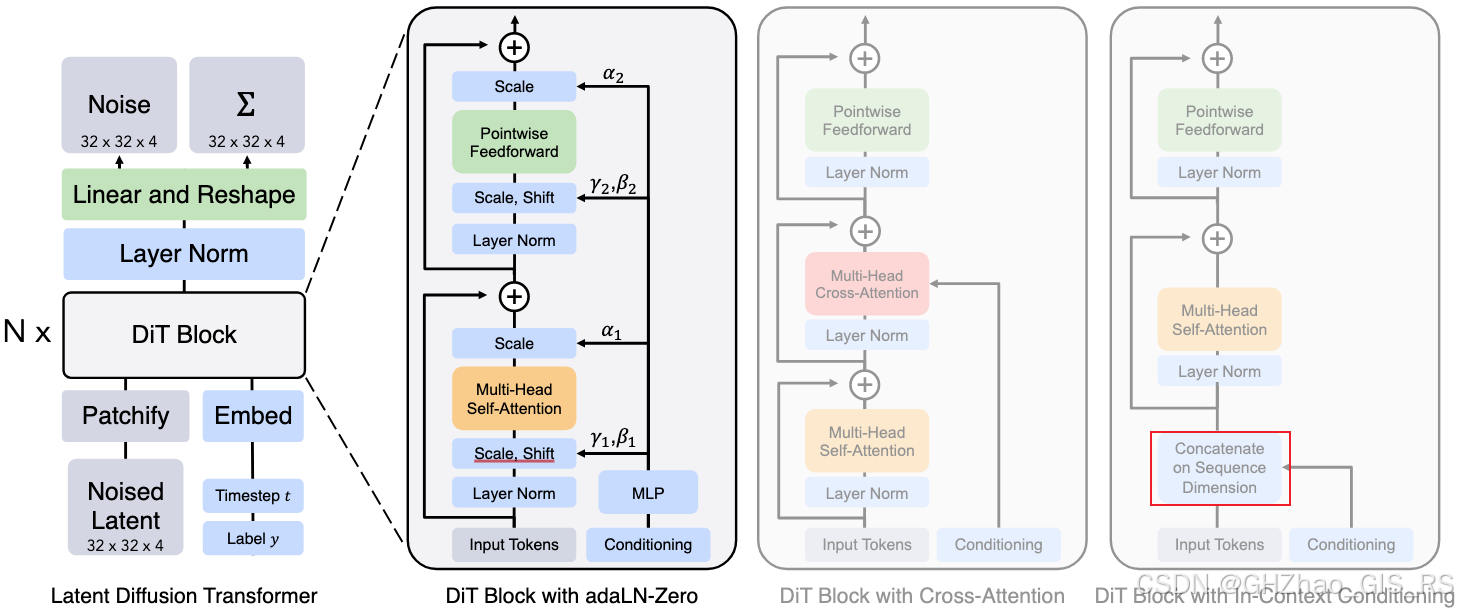
2)Cross-Attention
这个设计是将时间步t和类别标签c的嵌入拼接为长度为2的序列,作为key和value,图像token经过self-attention模块后作为query,和条件组成的序列做cross-attention操作。这种设计最大会增加15%的计算开销。
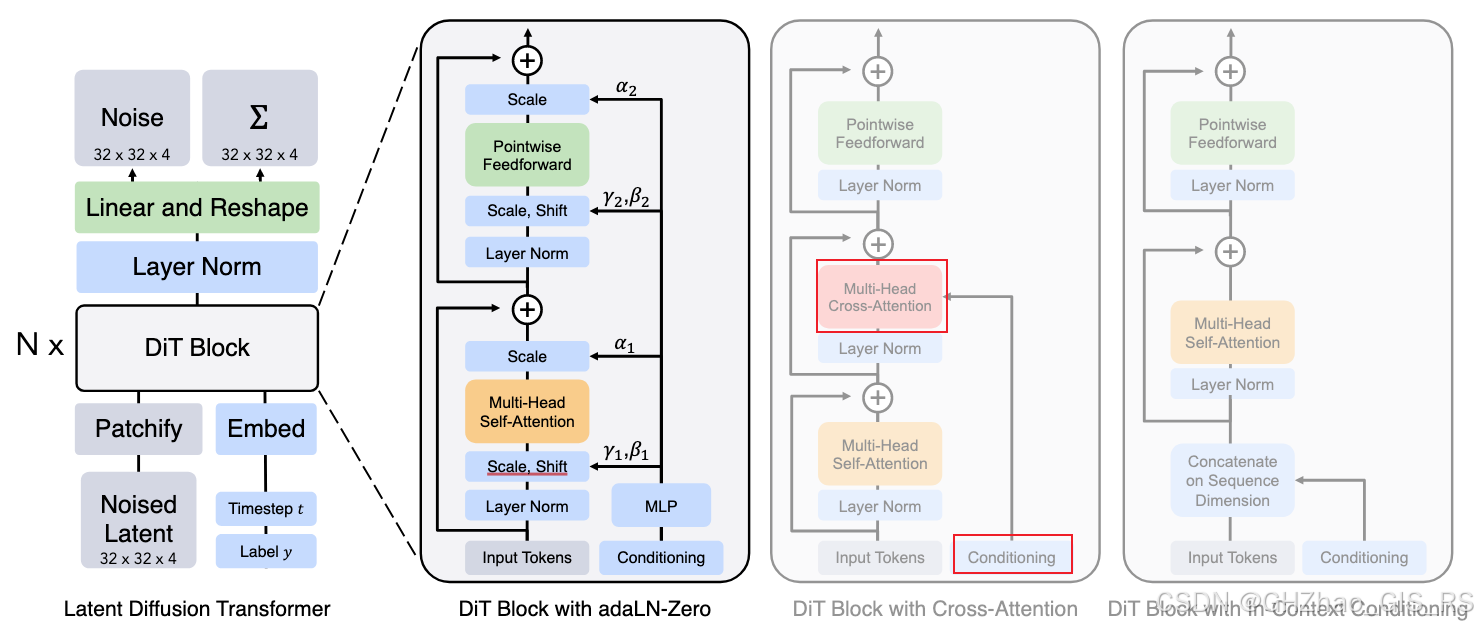
3) Adaptive layer norm(addLN) block
这个结构中借鉴了在 GANs 和基于 U-Net 的扩散模型中广泛使用的自适应归一化层。核心在于用条件信息来调制归一化层(layer norm)的参数。
标准的Layer norm
# 标准LayerNorm:γ和β是可学习参数
output = (input - mean) / std * γ + β # γ, β 是固定参数
自适应 LayerNorm (adaLN)
#adaLN:γ和β从条件信息动态生成
γ, β = MLP(embedding(t) + embedding(c)) # 从条件回归得到
output = (input - mean) / std * γ + β # γ, β 是条件相关的
具体过程如下
将时间步 t 和类别 c 分别嵌入为向量
将两个嵌入向量相加:condition = embed(t) + embed©
通过一个小型 MLP 从 condition 回归出 γ 和 β。
在前三种方法中,adaLN 增加的计算开销最小,因此是计算效率最高的,
4)adaLN-Zero block
作者基于adaLN结构,将 ResNet 和 U-Net 中成功的零初始化策略应用到 Transformer 架构中。此外,除了回归 γ 和 β 之外,作者还回归维度级的缩放参数 α,这些参数被应用于 DiT 块内任何残差连接之前。
class DiTBlockWithAdaLNZero(nn.Module):def forward(self, x, condition):# 从条件回归多个调制参数params = self.condition_mlp(condition) # [batch, hidden_size*6]gamma1, beta1, gamma2, beta2, alpha1, alpha2 = params.chunk(6, dim=1)# 注意力路径(带门控残差)h = self.adaLN(x, gamma1, beta1)h = self.attention(h)x = x + alpha1.unsqueeze(1) * h # α1 控制注意力残差# 前馈路径(带门控残差) h = self.adaLN(x, gamma2, beta2)h = self.mlp(h)x = x + alpha2.unsqueeze(1) * h # α2 控制前馈残差return x
其中alpha1, alpha2初始化为0。这是作者最终使用的结构。
四个网络结构的对比