算法笔记 11
1 用链表加强哈希表(LinkedHashMap)详解(C++ 实现)
算法笔记 05-CSDN博客(有java版本的解释,但是当时没有学得很细)
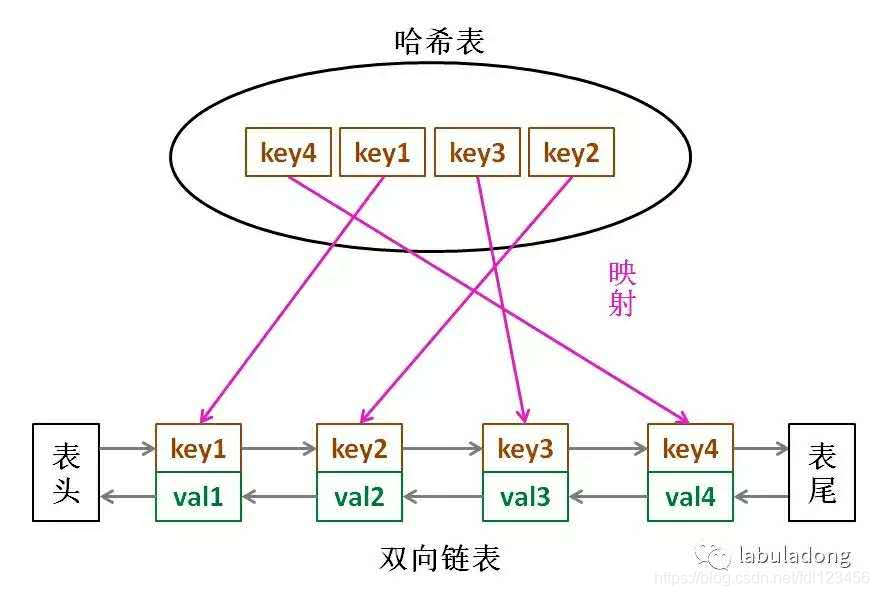
一、什么是 LinkedHashMap?
LinkedHashMap 是哈希表(HashMap)的增强版,它在哈希表的基础上,通过双向链表记录元素的插入顺序或访问顺序,解决了普通哈希表遍历顺序无序的问题。
- 普通哈希表:元素存储位置由哈希函数决定,遍历顺序与插入顺序无关
- LinkedHashMap:既保留哈希表的 O (1) 查找效率,又能按顺序遍历元素
二、核心原理
-
哈希表部分:数组 + 链表(解决哈希冲突)
- 数组每个位置称为 "桶(Bucket)"
- 哈希冲突时,桶内元素用单链表连接
-
双向链表部分:记录顺序
- 每个元素同时属于哈希表的桶链表和全局双向链表
- 双向链表维护元素的插入 / 访问顺序
三、C++ 实现步骤
1. 定义节点结构
每个节点需要包含:
- 键(key)和值(value)
- 哈希表中的前后指针(解决冲突)
- 双向链表中的前后指针(维护顺序)
template <typename K, typename V>
struct Node {K key; // 键V value; // 值Node* next; // 哈希表桶内的下一个节点(解决冲突)Node* prev; // 双向链表的前一个节点Node* next_order;// 双向链表的后一个节点// 构造函数Node(const K& k, const V& v) : key(k), value(v), next(nullptr), prev(nullptr), next_order(nullptr) {}
};
2. 定义 LinkedHashMap 类
需要包含:
- 哈希表数组(桶数组)
- 双向链表的头和尾指针(维护顺序)
- 容量、大小等基本属性
template <typename K, typename V>
class LinkedHashMap {
private:Node<K, V>** buckets; // 桶数组(哈希表主体)Node<K, V>* head; // 双向链表头(最早插入的元素)Node<K, V>* tail; // 双向链表尾(最新插入的元素)int capacity; // 哈希表容量int size; // 当前元素数量// 哈希函数(简化版)int hash(const K& key) const {// 对于整数键直接取模,其他类型需重载return (int)key % capacity;}public:// 构造函数LinkedHashMap(int cap = 16) : capacity(cap), size(0) {buckets = new Node<K, V>*[capacity](); // 初始化桶数组为nullptrhead = tail = nullptr;}// 析构函数(释放所有节点)~LinkedHashMap() {clear();delete[] buckets;}
};
补充(c++中 ~ 的语法):
在C++ 里,~ 是一个特殊符号,主要有两种常见用法:
1. 按位取反运算符(针对二进制)
~ 可以对一个整数的二进制位进行「取反」操作(0 变 1,1 变 0)。比如:
int a = 5; // 二进制是 00000101(简化为 8 位)
int b = ~a; // 对 a 取反,结果是 11111010(十进制是 -6,暂时不用纠结负数表示)
这个用法在底层二进制操作中会用到,平时写业务代码不常用。
2. 析构函数的标志(最常见)
在类中,~ 加在类名前,表示「析构函数」。析构函数的作用是:当类的对象被销毁时(比如程序结束、对象超出作用域),自动执行一些清理工作(比如释放内存、关闭文件等)。
举个例子:
class MyClass {
public:// 构造函数(创建对象时自动调用)MyClass() {cout << "对象创建了" << endl;}// 析构函数(对象销毁时自动调用)~MyClass() { // 这里的 ~ 就是析构函数的标志cout << "对象销毁了,清理工作完成" << endl;}
};int main() {MyClass obj; // 创建对象,会调用构造函数(输出:对象创建了)// ... 做一些操作return 0; // 程序结束,obj 被销毁,调用析构函数(输出:对象销毁了...)
}
简单说:~类名() 就像对象的「临终清理函数」,负责收拾残局,避免内存泄漏等问题。
你之前看到的 LinkedHashMap 类中的 ~LinkedHashMap() 就是析构函数,作用是释放链表节点和哈希表数组占用的内存,防止内存泄漏。
3. 核心操作实现
(1)插入元素(put)
步骤:
- 计算键的哈希值,找到对应的桶
- 检查桶中是否有相同键,有则更新值
- 没有则创建新节点,插入哈希表和双向链表
void put(const K& key, const V& value) {int index = hash(key);Node<K, V>* curr = buckets[index];// 1. 检查是否已存在该键while (curr) {if (curr->key == key) {curr->value = value; // 更新值return;}curr = curr->next;}// 2. 创建新节点Node<K, V>* newNode = new Node<K, V>(key, value);// 3. 插入哈希表(头插法)newNode->next = buckets[index];buckets[index] = newNode;// 4. 插入双向链表尾部(保持插入顺序)if (!head) { // 链表为空head = tail = newNode;} else {tail->next_order = newNode;newNode->prev = tail;tail = newNode;}size++;
}
(2)获取元素(get)
步骤:
- 计算哈希值找到桶
- 遍历桶内链表查找键
- 找到则返回值,否则返回默认值
V get(const K& key, const V& defaultValue = V()) const {int index = hash(key);Node<K, V>* curr = buckets[index];while (curr) {if (curr->key == key) {return curr->value; // 找到返回值}curr = curr->next;}return defaultValue; // 未找到返回默认值
}
(3)删除元素(remove)
步骤:
- 找到元素在哈希表中的位置并删除
- 同时从双向链表中删除该元素
bool remove(const K& key) {int index = hash(key);Node<K, V>* curr = buckets[index];Node<K, V>* prev = nullptr;// 1. 在哈希表中查找并删除while (curr) {if (curr->key == key) {// 从哈希表桶中移除if (prev) {prev->next = curr->next;} else {buckets[index] = curr->next;}// 2. 从双向链表中移除if (curr->prev) {curr->prev->next_order = curr->next_order;} else {head = curr->next_order; // 是头节点}if (curr->next_order) {curr->next_order->prev = curr->prev;} else {tail = curr->prev; // 是尾节点}delete curr;size--;return true;}prev = curr;curr = curr->next;}return false; // 未找到该键
}
(4)按顺序遍历
利用双向链表的顺序性遍历:
void traverse() const {Node<K, V>* curr = head;while (curr) {cout << "(" << curr->key << ", " << curr->value << ") ";curr = curr->next_order;}cout << endl;
}
4. 完整示例代码
#include <iostream>
using namespace std;// 节点结构定义
template <typename K, typename V>
struct Node {K key;V value;Node* next; // 哈希表桶内指针Node* prev; // 双向链表前驱Node* next_order; // 双向链表后继Node(const K& k, const V& v) : key(k), value(v), next(nullptr), prev(nullptr), next_order(nullptr) {}
};// LinkedHashMap类
template <typename K, typename V>
class LinkedHashMap {
private:Node<K, V>** buckets;Node<K, V>* head;Node<K, V>* tail;int capacity;int size;int hash(const K& key) const {return (int)key % capacity;}public:LinkedHashMap(int cap = 16) : capacity(cap), size(0) {buckets = new Node<K, V>*[capacity]();head = tail = nullptr;}~LinkedHashMap() {clear();delete[] buckets;}void put(const K& key, const V& value) {int index = hash(key);Node<K, V>* curr = buckets[index];// 检查是否已存在while (curr) {if (curr->key == key) {curr->value = value;return;}curr = curr->next;}// 创建新节点Node<K, V>* newNode = new Node<K, V>(key, value);// 插入哈希表newNode->next = buckets[index];buckets[index] = newNode;// 插入双向链表尾部if (!head) {head = tail = newNode;} else {tail->next_order = newNode;newNode->prev = tail;tail = newNode;}size++;}V get(const K& key, const V& defaultValue = V()) const {int index = hash(key);Node<K, V>* curr = buckets[index];while (curr) {if (curr->key == key) {return curr->value;}curr = curr->next;}return defaultValue;}bool remove(const K& key) {int index = hash(key);Node<K, V>* curr = buckets[index];Node<K, V>* prev = nullptr;while (curr) {if (curr->key == key) {// 从哈希表移除if (prev) {prev->next = curr->next;} else {buckets[index] = curr->next;}// 从双向链表移除if (curr->prev) {curr->prev->next_order = curr->next_order;} else {head = curr->next_order;}if (curr->next_order) {curr->next_order->prev = curr->prev;} else {tail = curr->prev;}delete curr;size--;return true;}prev = curr;curr = curr->next;}return false;}void traverse() const {Node<K, V>* curr = head;while (curr) {cout << "(" << curr->key << ", " << curr->value << ") ";curr = curr->next_order;}cout << endl;}void clear() {Node<K, V>* curr = head;while (curr) {Node<K, V>* next = curr->next_order;delete curr;curr = next;}head = tail = nullptr;for (int i = 0; i < capacity; i++) {buckets[i] = nullptr;}size = 0;}int getSize() const { return size; }
};// 测试代码
int main() {LinkedHashMap<int, string> map;// 插入元素map.put(1, "苹果");map.put(2, "香蕉");map.put(3, "橙子");cout << "插入顺序遍历:";map.traverse(); // 输出:(1, 苹果) (2, 香蕉) (3, 橙子)// 获取元素cout << "键2对应的值:" << map.get(2) << endl; // 输出:香蕉// 删除元素map.remove(2);cout << "删除键2后遍历:";map.traverse(); // 输出:(1, 苹果) (3, 橙子)return 0;
}
四、关键特点总结
- 时间复杂度:插入、查找、删除均为 O (1)(平均情况)
- 顺序性:遍历顺序与插入顺序一致
- 空间开销:比普通哈希表多存储两个指针(prev 和 next_order)
- 应用场景:需要保持插入顺序的哈希表场景(如 LRU 缓存、配置解析等)
通过这个实现,你可以直观看到:哈希表负责快速查找,双向链表负责维护顺序,两者结合形成了 LinkedHashMap 的核心功能。
2 LRU 缓存淘汰算法(C++ 实现)
#include <unordered_map>
using namespace std;struct Node {int key, val;Node *prev, *next;Node(int k, int v) : key(k), val(v), prev(nullptr), next(nullptr) {}
};class DoubleList {
private:Node *head, *tail;int size;public:DoubleList() {head = new Node(0, 0); // 虚拟头节点tail = new Node(0, 0); // 虚拟尾节点head->next = tail;tail->prev = head;size = 0;}// 添加节点到尾部(最近使用)void addLast(Node* x) {x->prev = tail->prev;x->next = tail;tail->prev->next = x;tail->prev = x;size++;}// 删除指定节点void remove(Node* x) {x->prev->next = x->next;x->next->prev = x->prev;size--;}// 删除并返回第一个节点(最久未使用)Node* removeFirst() {if (head->next == tail) return nullptr;Node* first = head->next;remove(first);return first;}int getSize() { return size; }
};class LRUCache {
private:unordered_map<int, Node*> map; // key -> 节点DoubleList cache; // 维护使用顺序int cap; // 容量// 将节点移到尾部(标记为最近使用)void makeRecently(int key) {Node* x = map[key];cache.remove(x);cache.addLast(x);}// 添加新节点到尾部void addRecently(int key, int val) {Node* x = new Node(key, val);cache.addLast(x);map[key] = x;}// 删除指定key的节点void deleteKey(int key) {Node* x = map[key];cache.remove(x);map.erase(key);delete x; // 释放内存}// 删除最久未使用的节点void removeLeastRecently() {Node* x = cache.removeFirst();if (x) {map.erase(x->key);delete x; // 释放内存}}public:LRUCache(int capacity) : cap(capacity) {}int get(int key) {if (!map.count(key)) return -1;makeRecently(key);return map[key]->val;}void put(int key, int value) {if (map.count(key)) {// 已存在,先删除再添加(更新)deleteKey(key);addRecently(key, value);return;}// 不存在,检查容量if (cache.getSize() == cap) {removeLeastRecently(); // 容量满,删除最久未使用}addRecently(key, value); // 添加新节点}
};/*** Your LRUCache object will be instantiated and called as such:* LRUCache* obj = new LRUCache(capacity);* int param_1 = obj->get(key);* obj->put(key,value);*/算法就像搭乐高:手撸 LRU 算法 | labuladong 的算法笔记
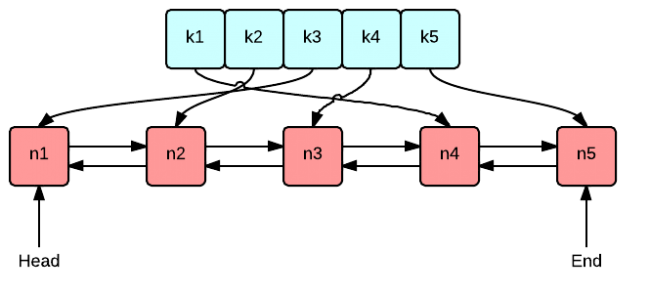
一、什么是 LRU?
LRU 是 Least Recently Used(最近最少使用)的缩写。
它是一种缓存淘汰策略:当缓存满了之后,会优先删除「最久没被使用」的元素,腾出空间给新元素。
生活例子:你的书桌只能放 3 本书(缓存容量 3),现在放着 A、B、C。
- 你用了 A(最近使用),书桌还是 A、B、C(A 变成「最近用的」)
- 你新买了 D,书桌满了,必须扔掉最久没碰的(B 最久没被用),现在书桌是 A、C、D
- 你又用了 C,C 变成「最近用的」,书桌顺序变成 A、D、C
二、核心需求
- 快速查找:根据 key 快速找到对应的值(像哈希表一样快)
- 快速插入:新元素要能快速加到缓存中
- 快速删除:缓存满时,要能快速删掉「最久没使用」的元素
- 维护顺序:始终知道哪个元素是「最久没使用的」,哪个是「最近使用的」
三、用什么数据结构实现?
哈希表 + 双向链表 组合:
- 双向链表:按「使用时间」排序,头节点是「最久没使用的」,尾节点是「最近使用的」。
- 刚插入或刚被访问的元素,移到链表尾部(变成「最近使用」)
- 缓存满时,直接删链表头部(「最久没使用」)
- 哈希表:key 映射到链表中的节点,实现 O (1) 时间查找。
四、步骤拆解(以容量 2 为例)
-
初始状态:缓存空,链表空,哈希表空。
-
插入 key=1, value=1:
- 链表为空,直接在尾部插入节点 (1,1)(现在链表:1(既是头也是尾))
- 哈希表记录:1 → 节点 1
-
插入 key=2, value=2:
- 链表尾部插入节点 (2,2)(现在链表:1 → 2,头 = 1,尾 = 2)
- 哈希表记录:2 → 节点 2
-
访问 key=1:
- 哈希表找到节点 1,将它移到链表尾部(变成「最近使用」)
- 现在链表:2 → 1(头 = 2,尾 = 1)
-
插入 key=3, value=3:
- 缓存满了(容量 2),先删链表头部(节点 2,最久没使用)
- 哈希表删除 key=2 的记录
- 链表尾部插入节点 3(现在链表:1 → 3)
- 哈希表记录:3 → 节点 3
五、C++ 代码实现(超详细注释)
#include <iostream>
#include <unordered_map> // 哈希表(C++自带)
using namespace std;// 1. 定义双向链表节点
struct Node {int key; // 键(删除时需要用key从哈希表中移除)int value; // 值Node* prev; // 前一个节点Node* next; // 后一个节点// 构造函数:创建节点时初始化键和值Node(int k, int v) : key(k), value(v), prev(nullptr), next(nullptr) {}
};// 2. LRU缓存类
class LRUCache {
private:int capacity; // 缓存最大容量unordered_map<int, Node*> map; // 哈希表:key → 节点(快速查找)Node* head; // 双向链表头(最久没使用的元素)Node* tail; // 双向链表尾(最近使用的元素)// 辅助函数:把节点移到链表尾部(标记为最近使用)void moveToTail(Node* node) {// 如果节点已经是尾节点,不用动if (node == tail) return;// 第一步:从原位置移除节点// a. 处理前节点的指针if (node->prev) {node->prev->next = node->next; // 前节点的next指向当前节点的next} else {head = node->next; // 如果当前节点是头节点,头指针要更新}// b. 处理后节点的指针if (node->next) {node->next->prev = node->prev; // 后节点的prev指向当前节点的prev}// 第二步:把节点加到尾部node->prev = tail; // 当前节点的prev指向原来的尾节点node->next = nullptr; // 当前节点变成新尾,next为nulltail->next = node; // 原来的尾节点的next指向当前节点tail = node; // 尾指针更新为当前节点}// 辅助函数:删除头节点(最久没使用的元素)void removeHead() {Node* oldHead = head;// 更新头指针head = head->next;if (head) {head->prev = nullptr; // 新头的prev设为null} else {tail = nullptr; // 如果删完之后链表空了,尾指针也设为null}// 从哈希表中删除这个keymap.erase(oldHead->key);// 释放内存delete oldHead;}// 辅助函数:在尾部插入新节点void addToTail(Node* node) {if (!head) { // 链表为空时,头和尾都是这个节点head = tail = node;} else { // 链表非空,加到尾部tail->next = node;node->prev = tail;tail = node;}}public:// 构造函数:初始化容量和链表LRUCache(int cap) : capacity(cap) {head = nullptr;tail = nullptr;}// 析构函数:释放所有节点内存~LRUCache() {Node* curr = head;while (curr) {Node* next = curr->next;delete curr;curr = next;}}// 3. 获取key对应的值int get(int key) {// 哈希表中找不到key,返回-1if (map.find(key) == map.end()) {return -1;}// 找到节点,把它移到尾部(标记为最近使用)Node* node = map[key];moveToTail(node);return node->value;}// 4. 插入或更新key-valuevoid put(int key, int value) {// 情况1:key已存在(更新值,并标记为最近使用)if (map.find(key) != map.end()) {Node* node = map[key];node->value = value; // 更新值moveToTail(node); // 移到尾部return;}// 情况2:key不存在(需要插入新节点)Node* newNode = new Node(key, value);// 情况2.1:缓存已满,先删最久没使用的(头节点)if (map.size() == capacity) {removeHead();}// 情况2.2:插入新节点到尾部,并加入哈希表addToTail(newNode);map[key] = newNode;}
};// 测试代码
int main() {// 创建一个容量为2的LRU缓存LRUCache cache(2);cache.put(1, 1); // 缓存:{1=1}(链表:1)cache.put(2, 2); // 缓存:{1=1, 2=2}(链表:1→2)cout << cache.get(1) << endl; // 访问1,返回1(链表变为2→1)cache.put(3, 3); // 缓存满,删最久的2,插入3(链表:1→3)cout << cache.get(2) << endl; // 2已被删,返回-1cache.put(4, 4); // 缓存满,删最久的1,插入4(链表:3→4)cout << cache.get(1) << endl; // 1已被删,返回-1cout << cache.get(3) << endl; // 访问3,返回3(链表变为4→3)cout << cache.get(4) << endl; // 访问4,返回4(链表变为3→4)return 0;
}
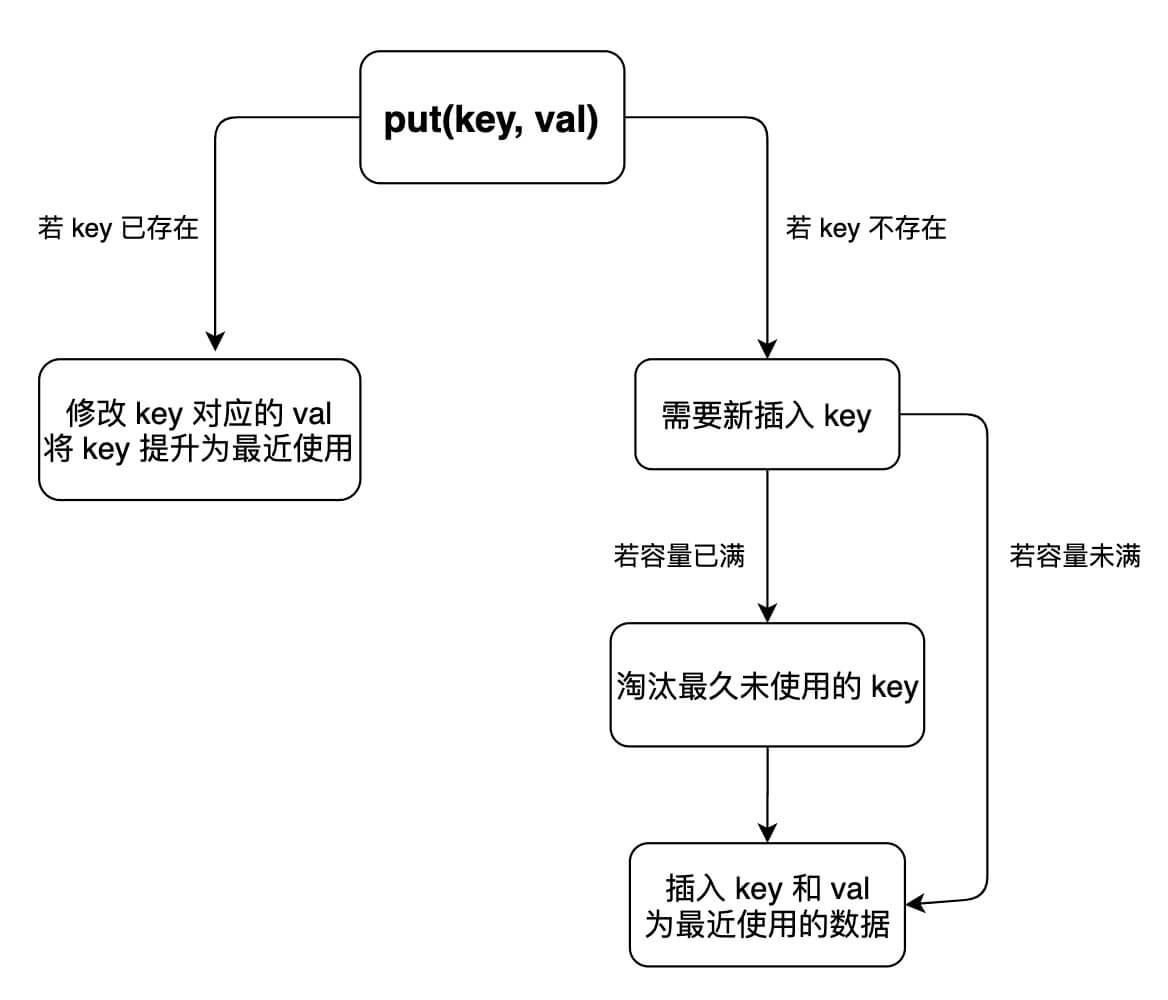
put方法的思路
六、代码运行结果
1
-1
-1
3
4
七、关键总结
- 双向链表的作用:用顺序记录「使用时间」,头 = 最久不用,尾 = 最近用。
- 哈希表的作用:O (1) 时间找到节点,避免遍历链表查找。
- 核心操作:
- 访问或更新元素时,移到链表尾部(变最近使用)。
- 缓存满时,删链表头部(最久不用)。
这样的设计能让所有操作(插入、查找、删除)都达到 O (1) 时间复杂度,非常高效。