Kafka 消费积压影响写入?试试 Pulsar
1. Pulsar 特性
Apache Pulsar 的设计背景,是雅虎为了替代团队内部多个业务线搭建小规模 Kafka 集群,带来的维护成本,于2012年开源。
因此 Pulsar 的多租户和集群容灾是所有开源MQ中最好的。
Kafka | Pulsar | |
存储架构 | 存算一体 本地磁盘存储 | 存算分离 存储服务BookKeeper,扩容简单 |
Kafka生态 | 完全兼容 | 有Pulsar生态,支持flink |
关键优势 |
|
|
Pulsar 支持最全的消息队列 API,支持复杂业务场景。
功能 | 特性 | 说明 |
消息队列 | 延迟消息* 顺序消息 事物 | Pulsar 支持任意延迟时间的延迟消息 |
消费者订阅模式 | 共享模式* Key 共享模式 独占模式 故障转移 | Pulsar 支持1个分区被多个消费者客户端消费 |
单条消息大小 | 无限制* | Pulsar 支持超大消息客户端自动拆包和组合 |
保存策略 | 支持长期存储 | 支持冷热数据分层存储 |
1.1 极限性能
单分区 topic 写性能极限测试。
- 低延迟:单条同步发送,生产者发送一条消息收到回包,仅需0.3ms,服务端完成 2 副本持久化到磁盘。
- 高吞吐:赞批发送,单客户端单线程,可实现150万写QPS
客户端(异步/同步) | 消息大小 | QPS上限 | 吞吐 | 平均耗时 |
同步 | 128 byte | 4146 | 4.0 Mbit/s | 0.3 ms |
同步 | 1 KB | 3200 | 25 Mbit/s | 0.3 ms |
同步 | 16KB | 3411 | 416.5 Mbit/s | 0.3 ms |
同步 | 512 KB | 704 | 2750.9 Mbit/s | 1.4 ms |
异步 | 128 byte | 1499826 | 1464.7 Mbit/s | 5ms |
异步 | 1 KB | 1060184 | 8282 Mbit/s | 5 ms |
异步(开启压缩) | 1 KB | 1500126 | 1536.7 Mbit/s | 6ms |
异步 | 16 KB | 78708 | 9542.9 Mbit/s | 6ms |
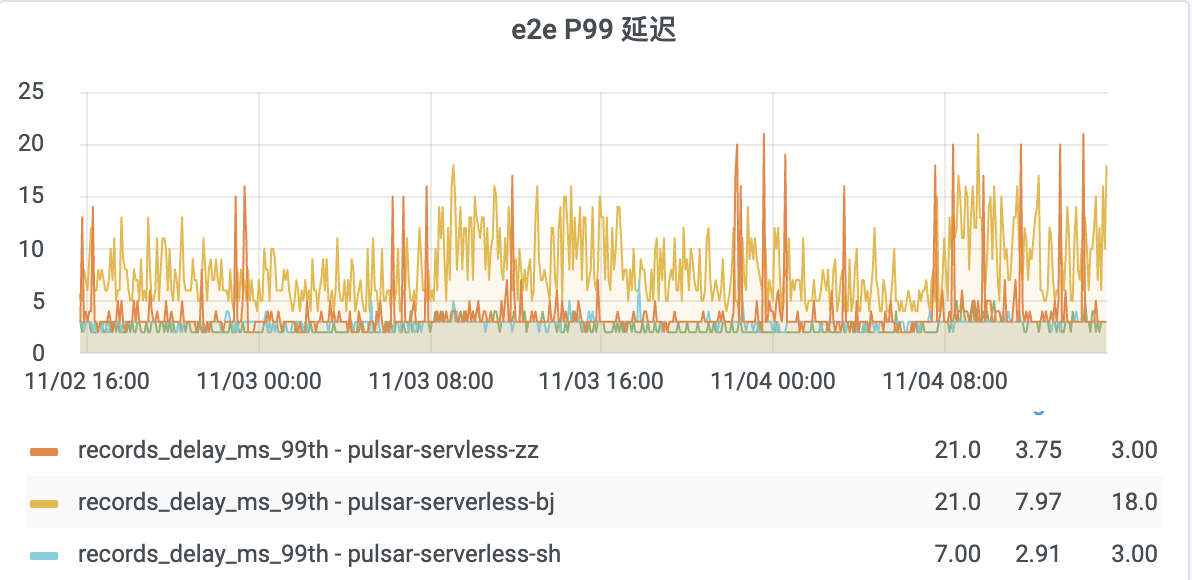
线上 Pulsar 集群端到端读写延迟P99耗时监控如下,平均延迟再10ms以下,最高 P99 耗时再 20ms 以内:
1.2 长期存储
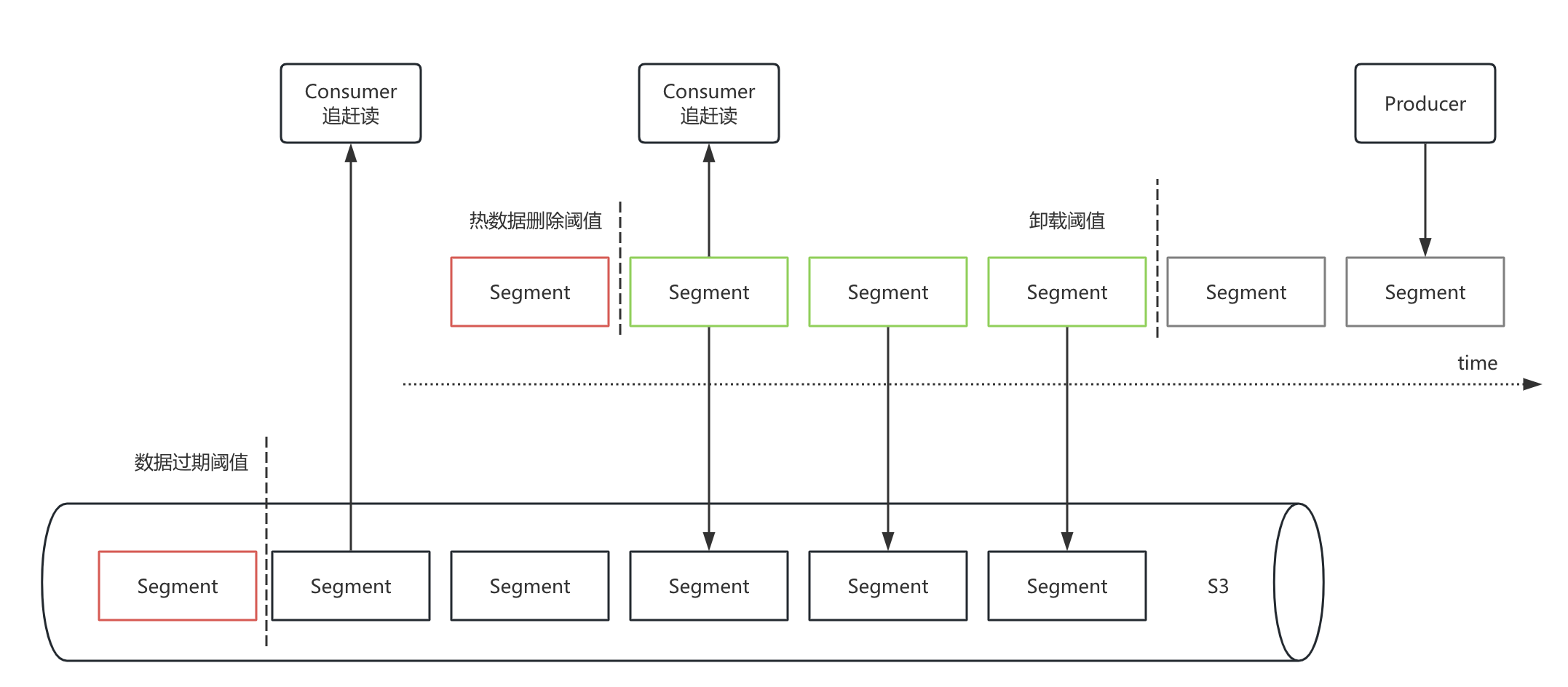
Pulsar 使用 SSD 磁盘存储热数据,冷数据存储在S3,Pulsar分层存储的实现原理是:
- 卸载阈值:Topic 的数据随着时间,生成很多 Segment,当 Segment 关闭时,触发上传 S3,已经上传完的Segment不删除,消费者可优先从磁盘读取数据进行消费,性能更好。
- 热数据删除阈值:到达热数据删除阈值后,本地磁盘上的 Segment 数据被删除,消费者只能从S3消费数据。此阈值支持按业务属性个性化配置。
- 数据过期阈值:即数据的保存周期,当 Segment 到达保存阈值后,删除S3上的Segment。
使用注意事项
- 冷数据消费性能上限:默认超过4小时的数据,需要从S3拉取,单分区读性能上限:60MB/s,可通过扩展分区数线性扩展冷数据消费能力。
- 支持个性化配置:分层存储的热数据阈值、数据过期阈值支持自定义配置,支持关闭分层存储
1.3 延迟队列
目前智汇云内部 Pulsar 版本对应 Apache Pulsar 4.0.x 版本,支持将延迟消息的索引持久化到磁盘,从而实现更大规模、更长延迟时间的延迟消息。
Pulsar 延迟消息的使用非常简单,普通类型 Topic 即可支持收发定时/延时消息,调用 SDK 的 API 即可发送定时/延时消息。
//定时消息
producer.newMessage().value(value.getBytes()).deliverAt(timeStamp).send();//延时消息
producer.newMessage().value(value.getBytes()).deliverAfter(delayTime, TimeUnit.SECONDS).send();使用延迟消息时需要注意:
1) topic 的 TTL 自动确认时间需要比延时消息的时间更长,否则延迟消息会在TTL后自动确认,不投递给消费者。
2) 生产者不可以使用 batch 模式发送,在创建 producer 的时候把 enableBatch 参数设为 false。
3) 消费模式仅支持使用 Shared 模式进行消费,否则会失去定时效果(Key-shared 也不支持)。
// 构建消费者
Consumer<byte[]> consumer = pulsarClient.newConsumer().topic("persistent://pulsar-xxx/sdk_java/topic1").subscriptionName("sub_topic1")// 声明消费模式为Shared(共享)模式.subscriptionType(SubscriptionType.Shared).subscribe()2. 产品特点
2.1 Serverless
按需创建资源,成本的最优解
- Kafka 扩缩容困难,因此需预留资源,整体磁盘利用率低
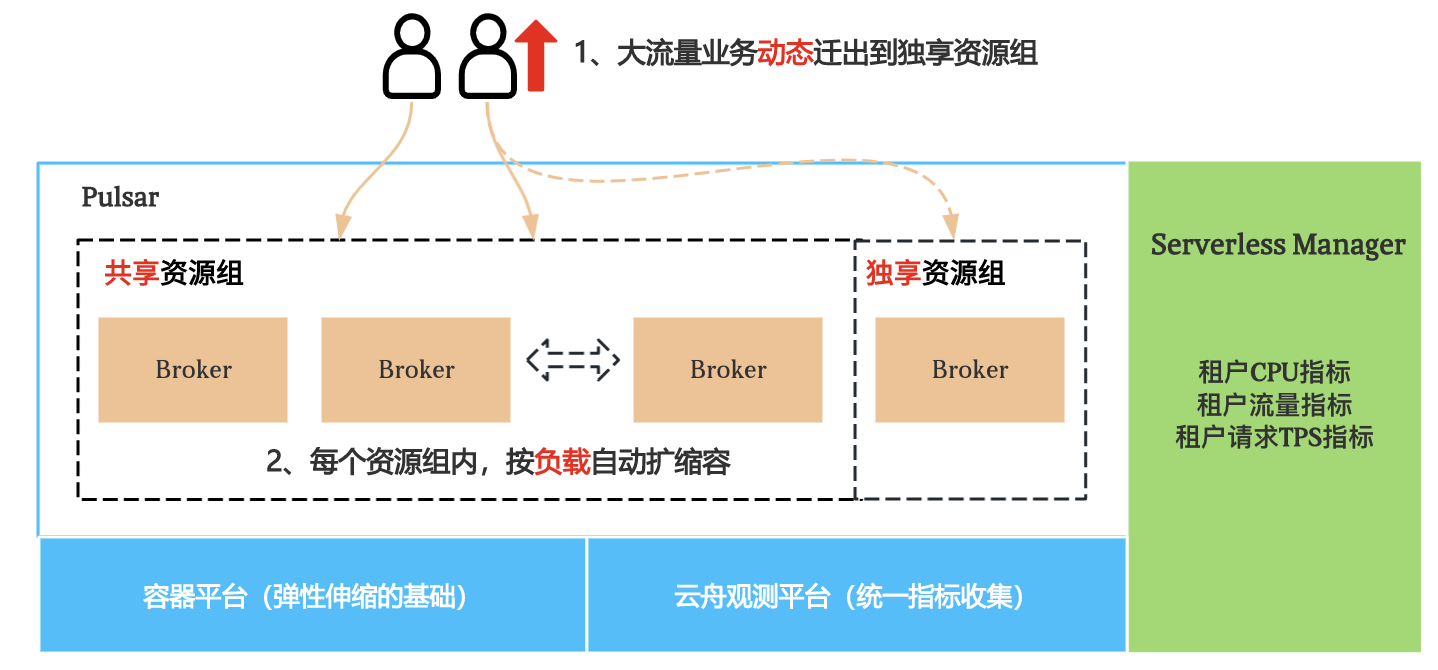
- Pulsar 计算节点无状态,部署在容器,按需分配资源,小流量场景可共享
- 服务端实现了按需秒级分配资源
租户隔离
Kafka 无租户隔离,一个用户积压数据过多,混合随机读写严重影响 broker 性能,集群里其他 topic 受影响。
Pulsar 支持为 namespace 配置资源组,不同资源组之间,计算节点broker和存储节点bookie都可以做到物理隔离。
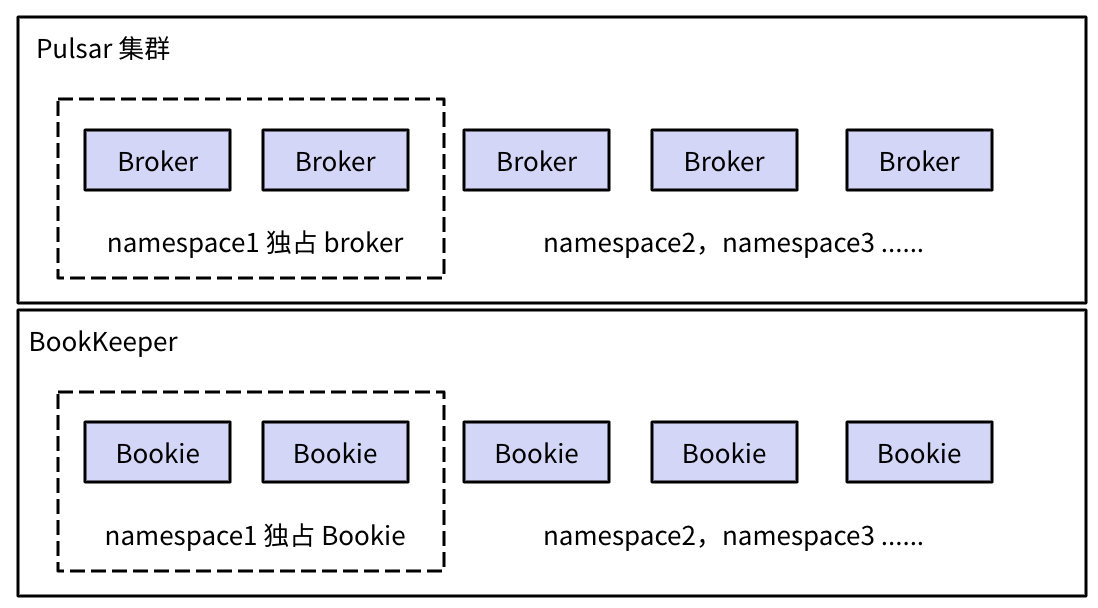
读写IO隔离
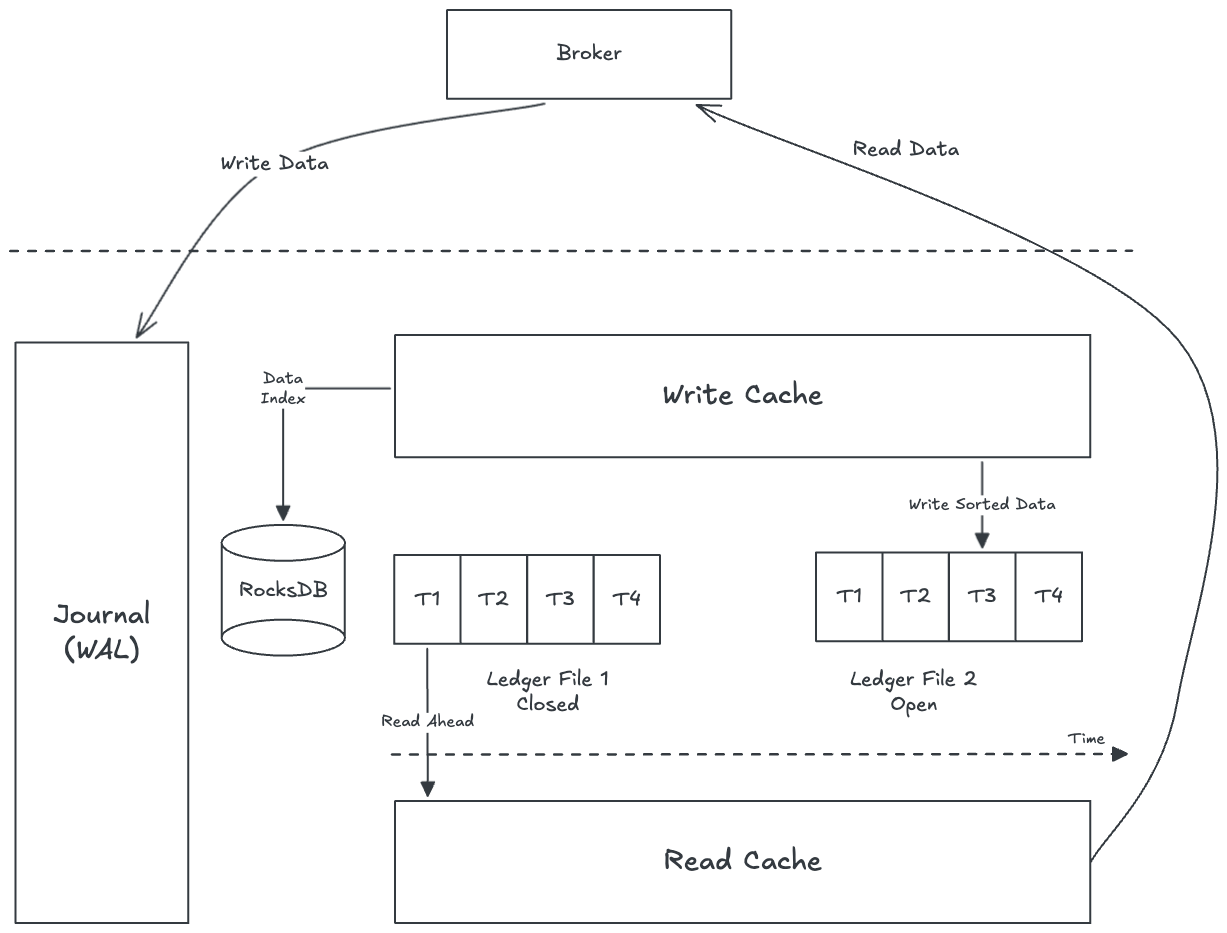
Pulsar 中 topic 消费积压不会导致写超时,Pulsar 读写磁盘分开,写数据使用WAL磁盘,顺序写,WAL的数据会在内存中赞批刷到Ledger磁盘,数据消费时,如果没命中缓存,从Ledger磁盘读取,因此实现了读写IO隔离,互不影响。
2.2 成本优势
Pulsar 相比 Kafka 最高能达到45倍成本节约。主要得益于:
- Pulsar 底层按需创建资源
- Pulsar 按成本定价
某 topic 吞吐 100MB/s,保存 1 天,使用 Kafka 和 Pulsar,折扣前价格对比:
读写流量 | 带宽费用/月 | 存储费用/月 | |
Kafka | 100MB/s | 25920 | 1728 |
Pulsar | 100MB/s | 864 | 259 |
案例1: 金融某业务团队之前使用MQ,吞吐是 25MB/s,在 Kafka 中,内结价10385/月,切换到Pulsar后,当前内结价228/月,成本降低约45倍。
2.3 故障容灾
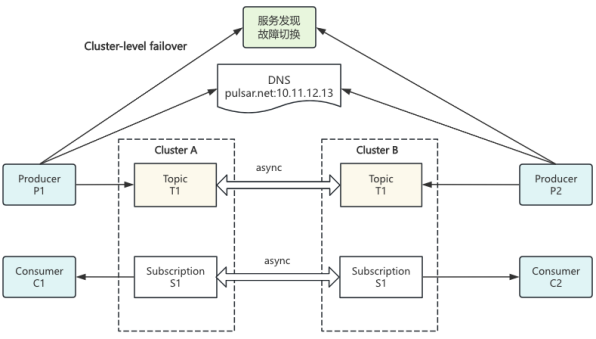
Pulsar 支持跨地域复制,支持 namespace 级别和 topic 级别开启,可以实现:
- 无感机房迁移:业务通过域名连接集群,运维会做DNS解析替换,topic被批量unload后,客户端会自动重连,切换到新集群。
- 集群级别故障容灾:集群双活,数据和消费位点双向同步,当其中一个集群故障后可轻松切换到另一个集群。