数据库三大范式详解
范式
数据库的范式是⼀组规则。在设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数 据库,这些不同的规范要求被称为不同的范式。
关系数据库有六种范式:第⼀范式(1NF)、第⼆范式(2NF)、第三范式(3NF)、巴斯-科德 范式(BCNF)、第四范式(4NF)和第五范式(5NF,⼜称完美范式),越⾼的范式数据库冗余越 ⼩。然⽽,普遍认为范式越⾼虽然对数据关系有更好的约束性,但也可能导致数据库IO更繁忙,因此在实际应⽤中,数据库设计通常只需满⾜第三范式即可。
第⼀范式
定义
- 数据库表的每⼀列都是不可分割的原⼦数据项,⽽不能是集合,数组,对象等⾮原⼦数据。
- 在关系型数据库的设计中,满⾜第⼀范式是对关系模式的基本要求。不满⾜第⼀范式的数据库就不能被称为关系数据库
⽰例
定义⼀个学⽣表,需要记录学⽣信息和学校信息
反例
学校是⼀个对象,可以继续进⾏拆分,所以不满⾜第⼀范式
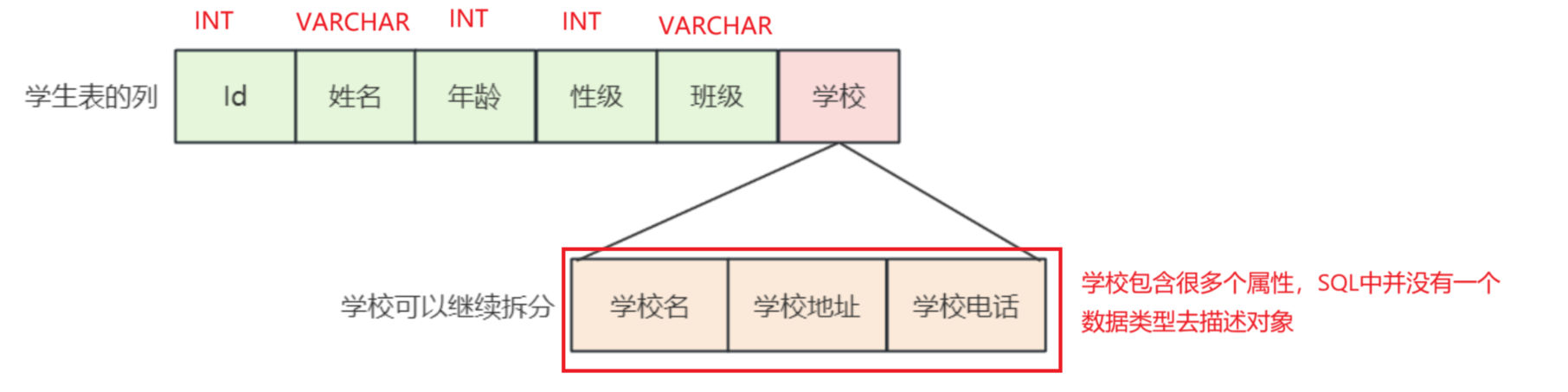
正例
学校信息包含在⼀⾏中,每⼀列都不能再进⾏拆分,此时已满⾜第⼀范式 
第⼆范式
在满⾜第⼀范式的基础上,不存在⾮关键字段对任意候选键的部分函数依赖。存在于表中定义了复合主键的情况下。 候选键:可以唯⼀标识⼀⾏数据的列或列的组合,可以从候选键中选⼀个或多个当做表的主键
在第二范式的概念中,非关键字段是指除了主键(包括复合主键的所有组成列)之外的其他字段,外键也属于非关键字段。
- 主键:用于唯一标识表中记录的字段(或字段组合),是 “关键字段”。
- 非关键字段:表中除主键外的所有字段,包括用于建立表间关联的外键、普通业务字段(如姓名、年龄、学分等)。
- 第二范式的核心要求:非关键字段必须完全依赖于整个主键(不能存在部分函数依赖)。
- 部分函数依赖:复合主键场景下,有些非关键字段不用整个主键,只靠主键里的某一个(或几个)列就能确定。
⽰例
需求:学⽣可以选修课程,课程有对应的学分,学⽣考试后每⻔课程会产⽣相应的成绩
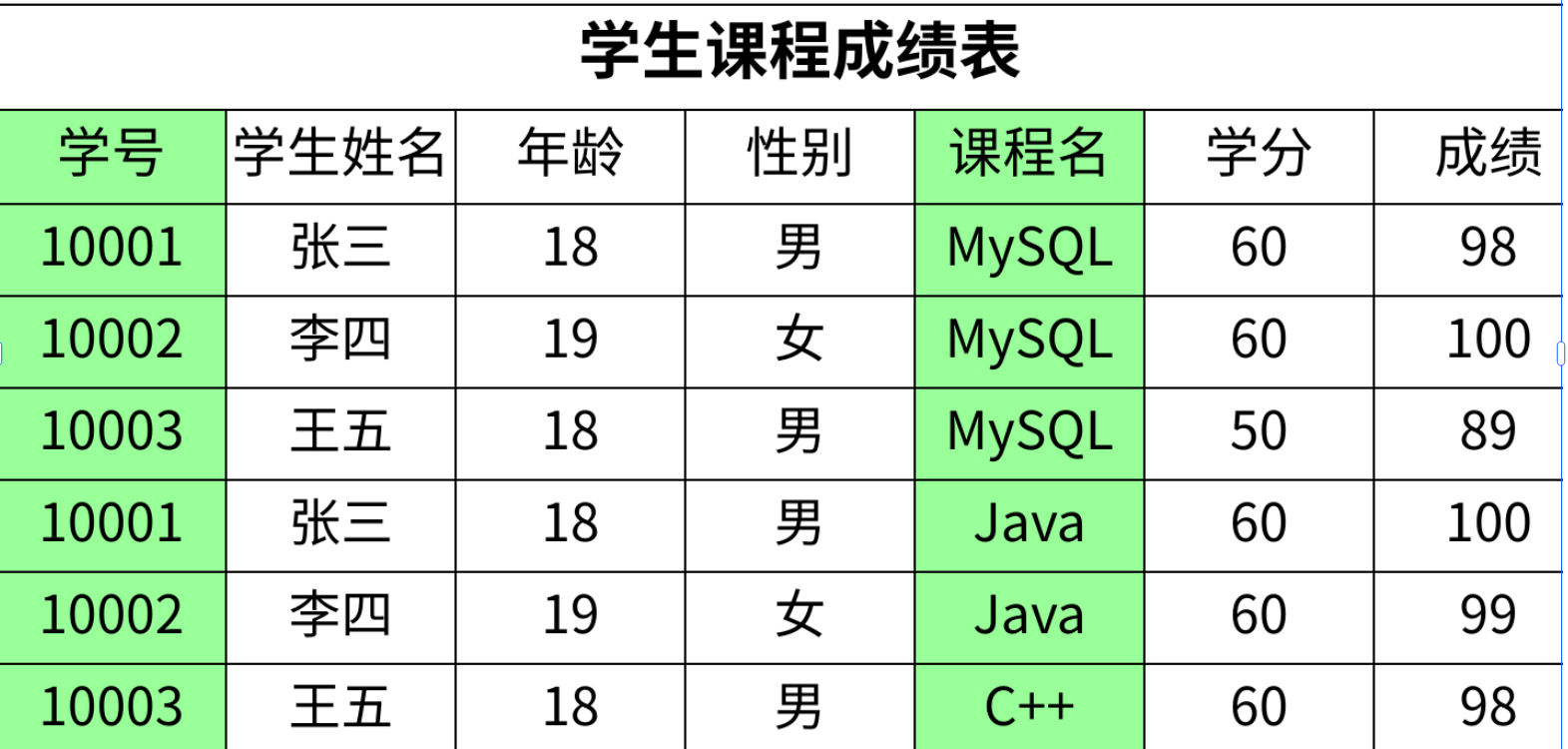
- 这张表中使用学号 + 课程名定义复合主键来唯一标识一个学生某门课程的成绩,这也是这张表的主要作用
- 学生是通过学号来确定的,学生的姓名、年龄和性别和课程没有关系,即学生的信息只依赖学号,不依赖课程名;学分是通过课程来确定的,课程的学分与学生没有关系,即学分只依赖课程名,不依赖学生
- 对于使用复合主键的表,如果一行数据中的有些列只与复合主键中的一个或其中几个列有关系,那么就说它存在部分函数依赖,也就不满足第二范式
正例
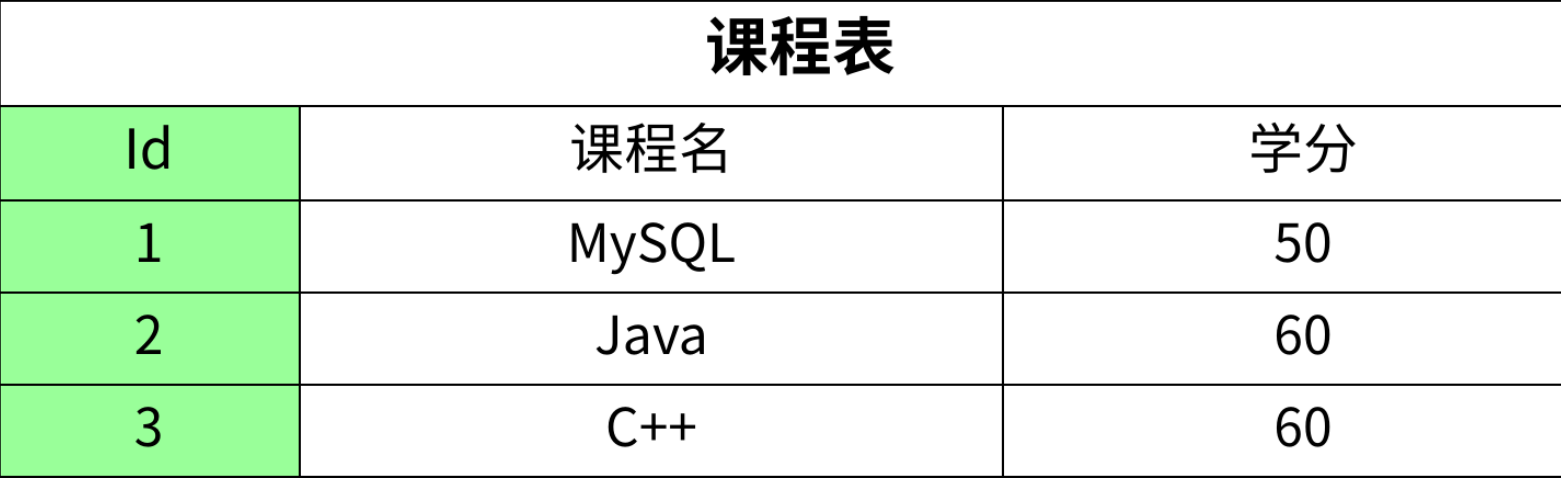
设计表:针对需求应该设计三张表,即:学⽣表、课程表和成绩表
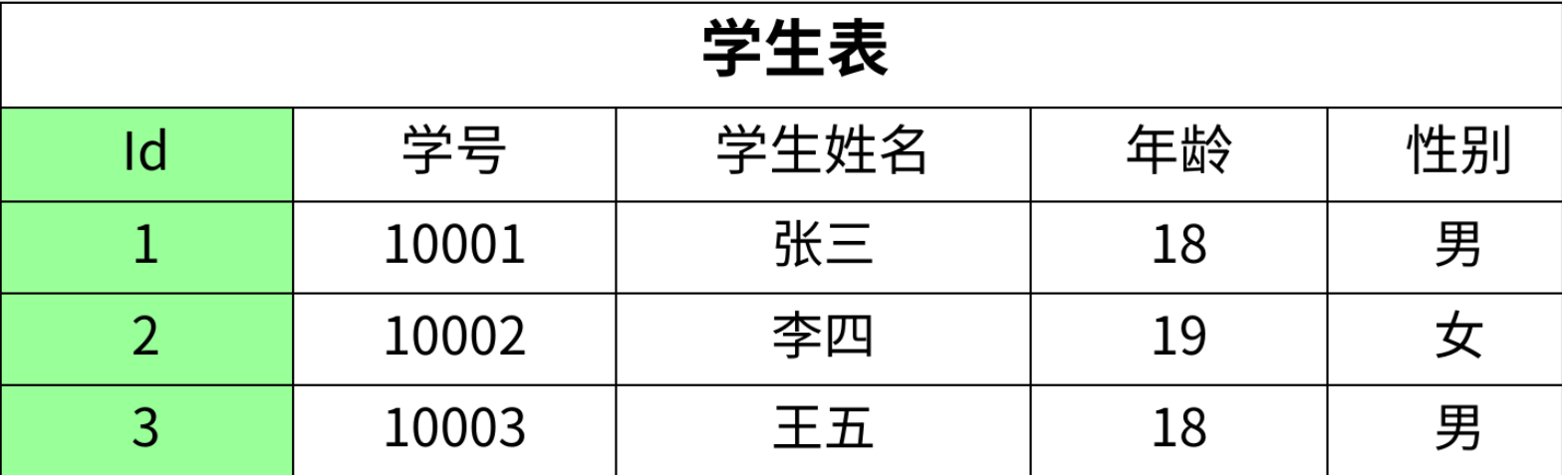
不满⾜第⼆范式时可能出现的问题:
数据冗余学生的姓名、年龄、性别和课程的学分在每行记录中重复出现,造成了大量的数据冗余。
更新异常如果要调整 MySQL 的学分,那么就需要更新表中所有关于 MySQL 的记录,一旦执行中断导致某些记录更新成功,某些数据更新失败,就会造成表中同一门课程出现不同学分的情况,出现数据不一致问题。
插入异常目前这样的设计,成绩与每一门课和学生都有对应关系,也就是说只有学生参加选修课程考试取得了成绩才能生成一条记录。当有一门新课还没有学生参加考试取得成绩之前,那么这门新课在数据库中是不存在的,因为成绩为空时记录没有意义。
删除异常 把毕业学⽣的考试数据全都删除,此时课程和学分的信息也会被删除掉,有可能导致⼀段时间内,数据库⾥没有某⻔课程和学分的信息。
正例三张表的设计
1. 数据冗余的消除
- 学生表:每个学生的信息(学号、姓名、年龄、性别)只存1 条记录,不管他选多少门课,都不会重复存储。
- 课程表:每门课的信息(课程名、学分)也只存1 条记录,不管多少学生选这门课,学分都不会重复。
- 对比未拆分的表,之前 “学生选 3 门课就重复 3 次姓名 / 年龄”“课程被选 N 次就重复 N 次学分” 的冗余问题,现在完全解决了。
2. 表之间的关系与关联逻辑
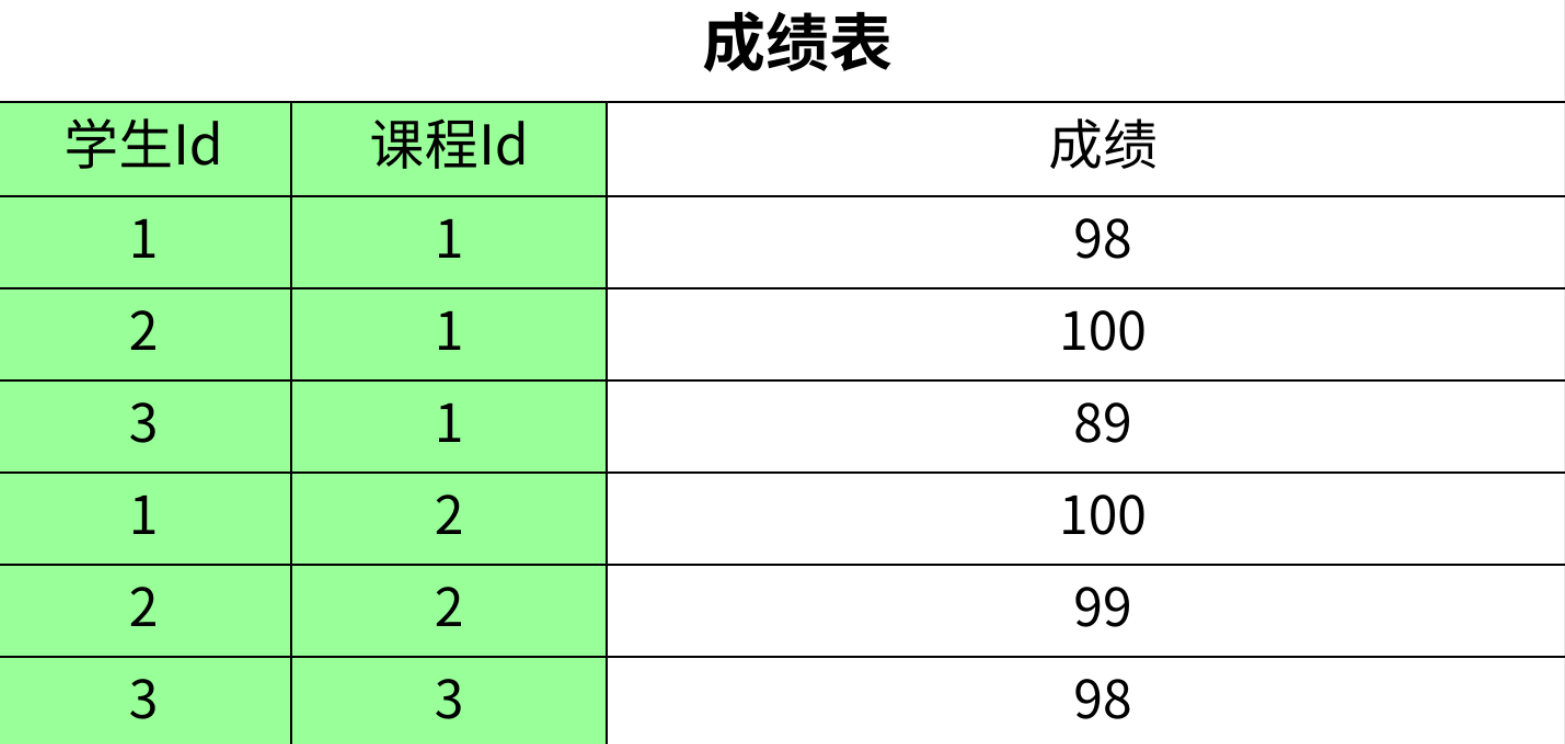
这三张表通过主键 - 外键建立了清晰的关联:
- 学生表的
Id是主键,成绩表的学生Id是外键,关联 “学生 - 成绩” 的关系; - 课程表的
Id是主键,成绩表的课程Id是外键,关联 “课程 - 成绩” 的关系; - 成绩表作为中间表(关联表),通过
学生Id和课程Id的组合,记录 “哪个学生选了哪门课,成绩是多少” 的关系。
3. 操作异常的解决
- 更新异常:如果要修改 “MySQL 的学分”,只需在课程表中改 1 行即可,所有关联到这门课的成绩记录都不会受影响(因为成绩表不存学分)。
- 插入异常:新增一门课(比如 “Python”),只需在课程表中插入 1 行;新增一个学生,只需在学生表中插入 1 行 —— 不需要依赖 “必须有成绩” 才能插入。
- 删除异常:删除一门课的成绩,不会影响课程表的课程信息;删除一个学生的成绩,也不会影响学生表的个人信息。
4. 检索逻辑的灵活性
通过成绩表的学生Id或课程Id,可以很方便地做关联查询:
- 查 “学生张三(学生 Id=1)的所有课程成绩”:关联学生表、成绩表、课程表,就能得到 “张三 + MySQL(98 分)、张三 + Java(100 分)” 等结果;
- 查 “MySQL 课程(课程 Id=1)的所有学生成绩”:关联课程表、成绩表、学生表,就能得到 “张三(98 分)、李四(100 分)、王五(89 分)” 等结果。
这种 “一表管一类事” 的设计,既保证了数据的简洁性,又让增删改查的操作更高效、更不易出错,是数据库设计中 “高内聚、低耦合” 原则的典型体现
第三范式
定义:在满⾜第⼆范式的基础上,不存在⾮关键字段,对任⼀候选键的传递依赖。
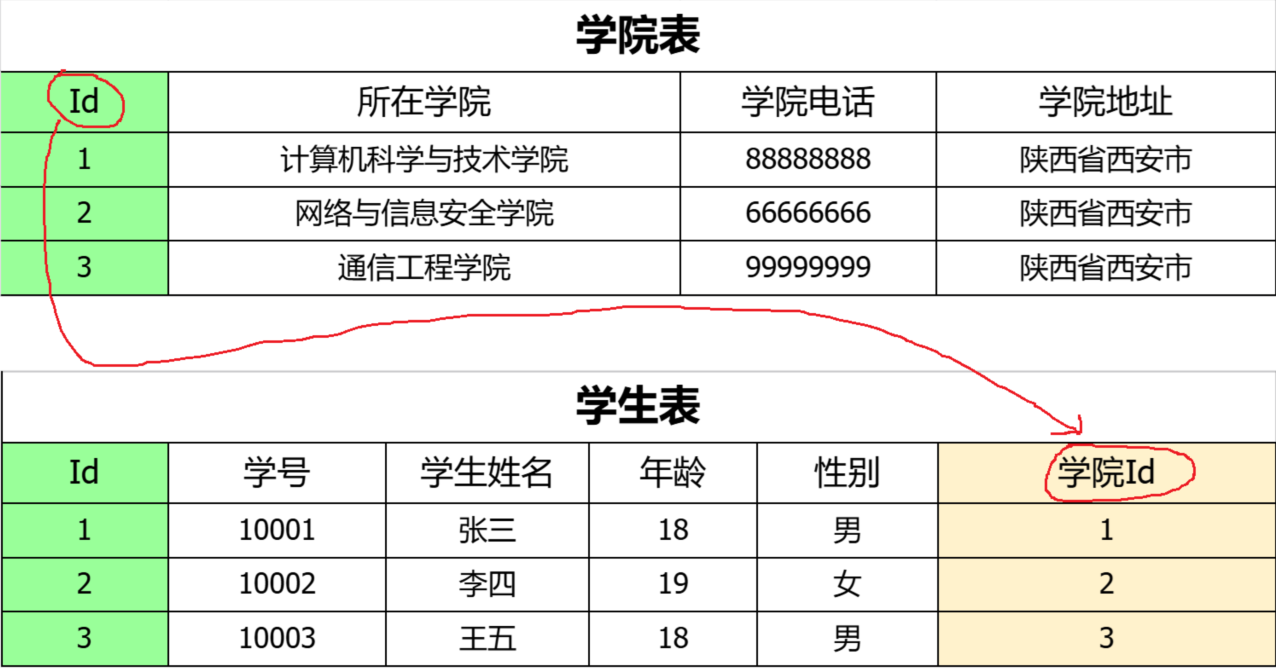
⽰例:要求学⽣表中记录学⽣所属的学院,在满⾜第⼆范式的基础上对学⽣表做出修改
反例:

- 因为是要描述学生信息,并且在表中定义了 Id 为主键,Id 可以明确的标识每条学生信息
- 在这个表结构中,可以看出学生的学号、姓名、年龄、性别与主键 Id 强相关;学院电话、学院地址与学院强相关;在一个表中出现了两个强相关的关系,而且这两个强相关关系又存在传递现象,即通过学生 Id 可以找到学生记录,学生记录中包含学院名,每个学院又有自己的电话和地址
- 这种传递现象称为传递依赖,所以当前的表不满足第三范式
正例:把学院信息拆分出来定义学院表,学⽣表与学院表做关联
设计过程
1.从现实业务中抽象得到概念类
- 概念类是从现实世界中抽象出来的,在需求分析阶段就需要确定下来
- 类对应了数据库设计中的实体,实体对应了数据库中的表
- 类中的属性对应实体中的属性,实体的属性对应了表中的列
2.确定实体与实体之间的关系,并画出E-R画,⽅便项⽬参与⼈员理解与沟通
3.根据E-R图完成SQL语句的编码并创建数据库
实体-关系图
实体-关系图(Entity-RelationshipDiagram)简称E-R图,也称作实体联系模型、实体关系模型,是 ⼀种⽤于描述数据模型的概念图,主要⽤于数据库设计阶段。
E-R图的基本组成
E-R图包含了以下三种基本成分:
- 实体:即数据对象,⽤矩形框表⽰,⽐如⽤⼾、学⽣、班级等。
- 属性:实体的特性,⽤椭圆形或圆⻆矩形表⽰,如学⽣的姓名、年龄等。
- 关系:实体之间的联系,⽤菱形框表⽰,并标明关系的类型,并⽤直线将相关实体与关系连接起来。
关系的类型
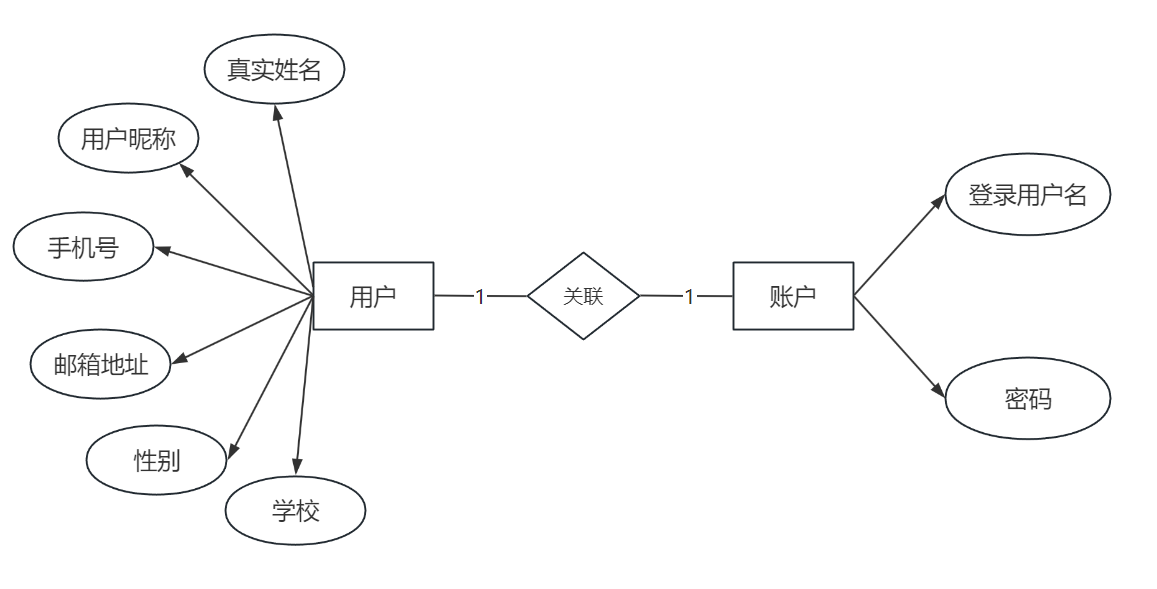
⼀对⼀关系(1:1)
- ⼀个⽤⼾实体包含的属性有:⽤⼾昵称,真实姓名,⼿机号,邮箱地址,性别,学校
- ⼀个账⼾实体包含的属性有:登录⽤⼾名,密码•
- ⽤⼾实体与账⼾实体是⼀对⼀的关系,⽤E-R图表⽰如下:
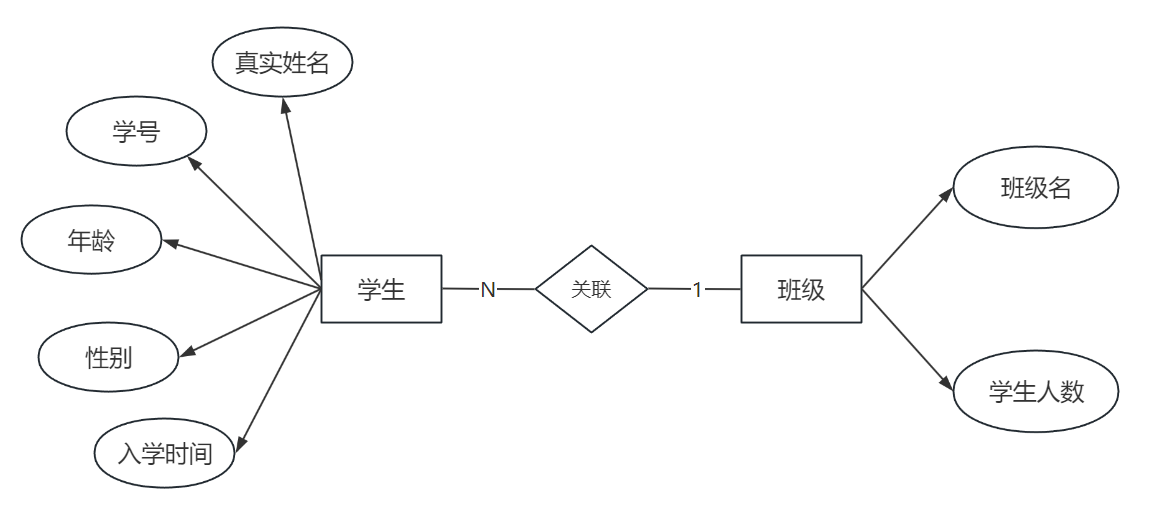
⼀对多关系(1:N)
⼀个学⽣实体包含的属性有:真实姓名,学号,年龄,性别,⼊学时间
⼀个班级实体包含的属性有:班级名,学⽣⼈数
⼀个班级中有多个学⽣,所以班级实体与学⽣实体是⼀对多的关系,反过来说学⽣实体与班级实体是多对⼀的关系,⽤E-R图表⽰如下:
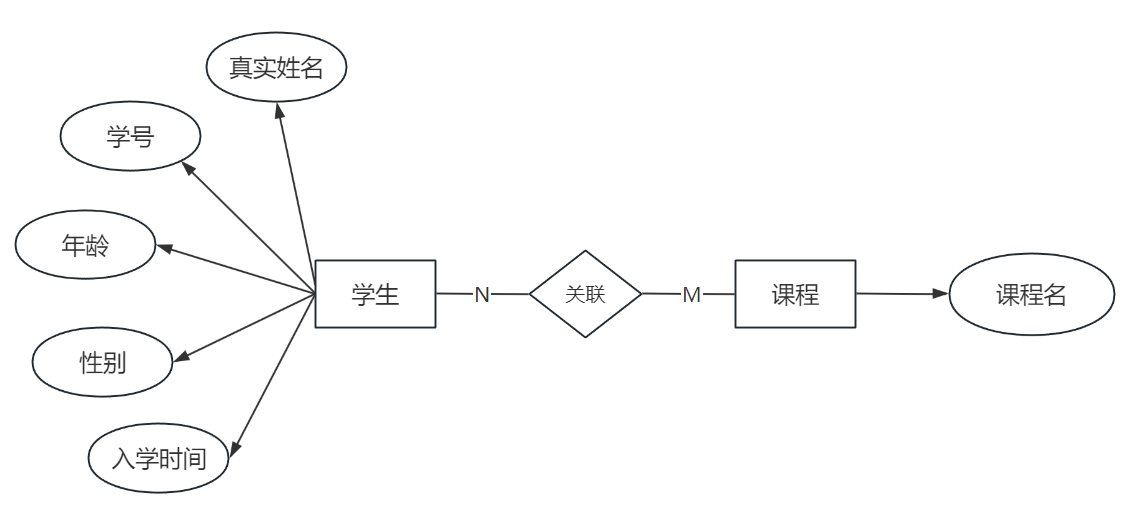
多对多关系(M:N)
- ⼀个学⽣实体包含的属性有:真实姓名,学号,年龄,性别,⼊学时间
- ⼀个课程实体包含的属性有:课程名
- ⼀个学⽣可以选修改多⻔课程,⼀⻔课程也可以被多名学⽣选修改,所以学⽣与课程之间是多对多关系,⽤E-R图表⽰如下:
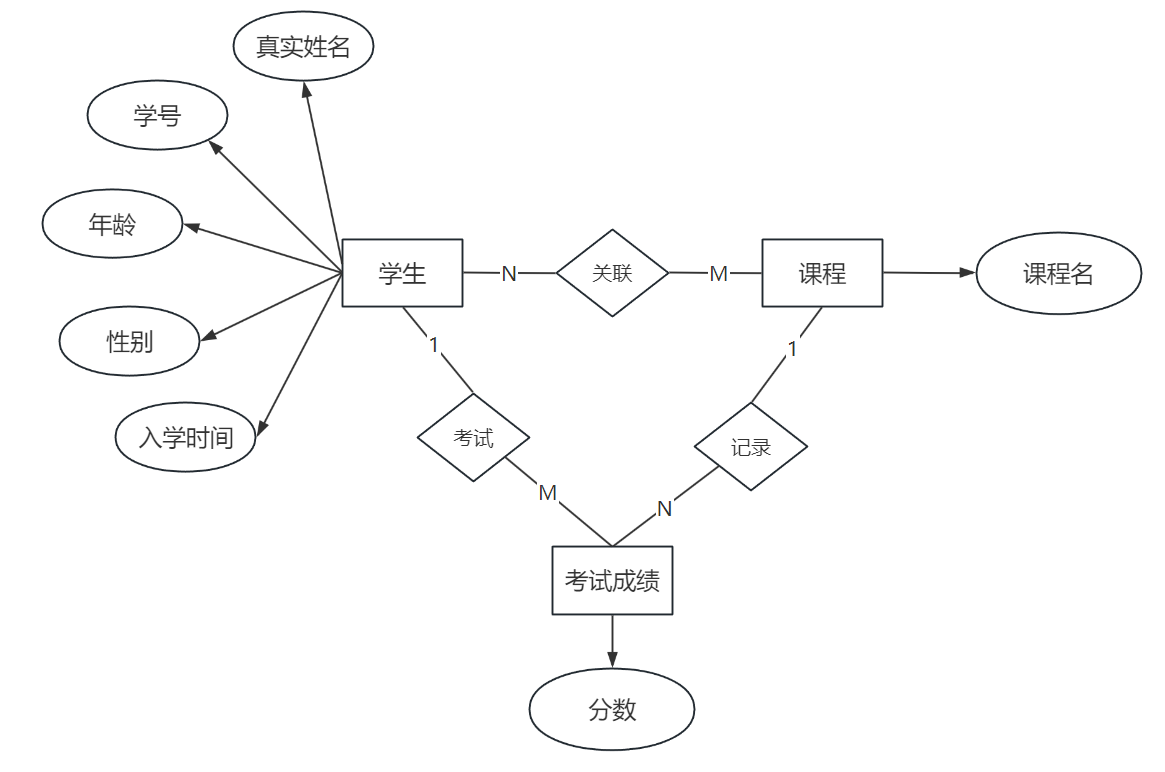
对于多对多关系,可以使⽤中间表进⾏记录,⽐如⼀个学⽣参加了某⼀⻔课程的考试得到了相应的成绩,⽤E-R图表⽰如下:
三种关系的 “双向判断标准”(以甲表、乙表为例)
| 关系类型 | 甲表单个个体 → 乙表个体数量 | 乙表单个个体 → 甲表个体数量 | 核心特征(一句话总结) | 常见示例 |
|---|---|---|---|---|
| 一对一 | 只能对应 1 个 | 只能对应 1 个 | 双方个体 “一一绑定”,互相唯一对应 | 学生与身份证(1 个学生→1 张身份证,1 张身份证→1 个学生) |
| 一对多 | 只能对应 1 个 | 可对应 多个 | 一方 “唯一对应”,另一方 “多端对应”(又称 “多对一”,视角不同) | 学生与宿舍(1 个学生→1 个宿舍,1 个宿舍→多个学生) |
| 多对多 | 可对应 多个 | 可对应 多个 | 双方个体都能 “交叉对应多个”,互相不唯一 | 用户与车辆(1 个用户→多辆车,1 辆车→多个用户)、学生与课程(1 个学生→多门课,1 门课→多个学生) |
关键结论:
- 没有 “单向的关系”:所有关系都是 “双向” 的,必须同时看甲对乙、乙对甲的个体对应规则,才能准确定义类型;
- 避免 “整体数量混淆”:不能用 “甲表有 100 条记录,乙表有 50 条记录” 这种整体数量判断,必须聚焦 “单个个体” 的对应数量(比如 “1 个学生” 对应几个宿舍,而非 “100 个学生” 对应几个宿舍);
- 外键位置由关系决定:
- 一对一:外键可放任意一方(通常放业务上更依赖的表);
- 一对多:外键必须放 “多的一方”(如学生表放
dor_id关联宿舍); - 多对多:必须建 1 张中间表(承载双方外键);若存在多组独立多对多关系(如 A-B、A-C、B-C),则需对应多张中间表。
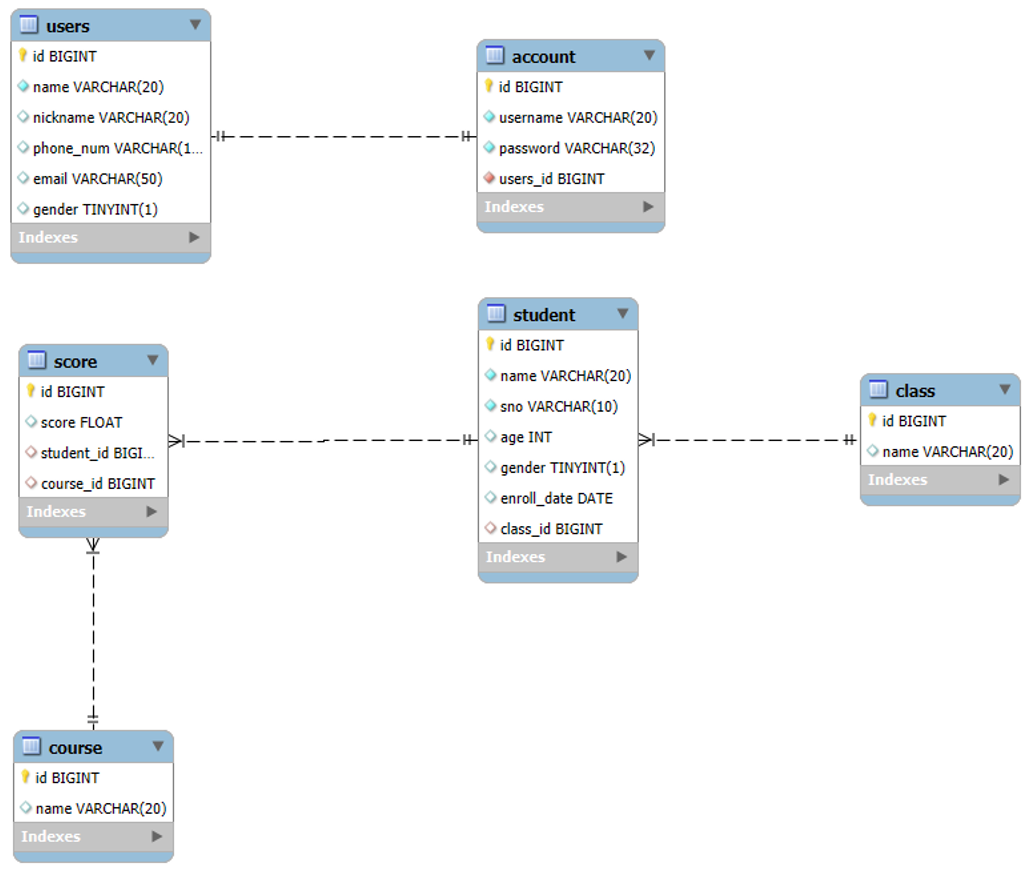
逆向查看EE-R图
- 当表创建完成,并设置了正确的主外键关系之后,可以通过可视化客⼾端⼯具的逆向⽣成数据库模 型(EE-R图)
- 客⼾端⼯具可以使⽤Workbench或Navicat(收费功能)
- 以下⽰例中使⽤的是Workbench
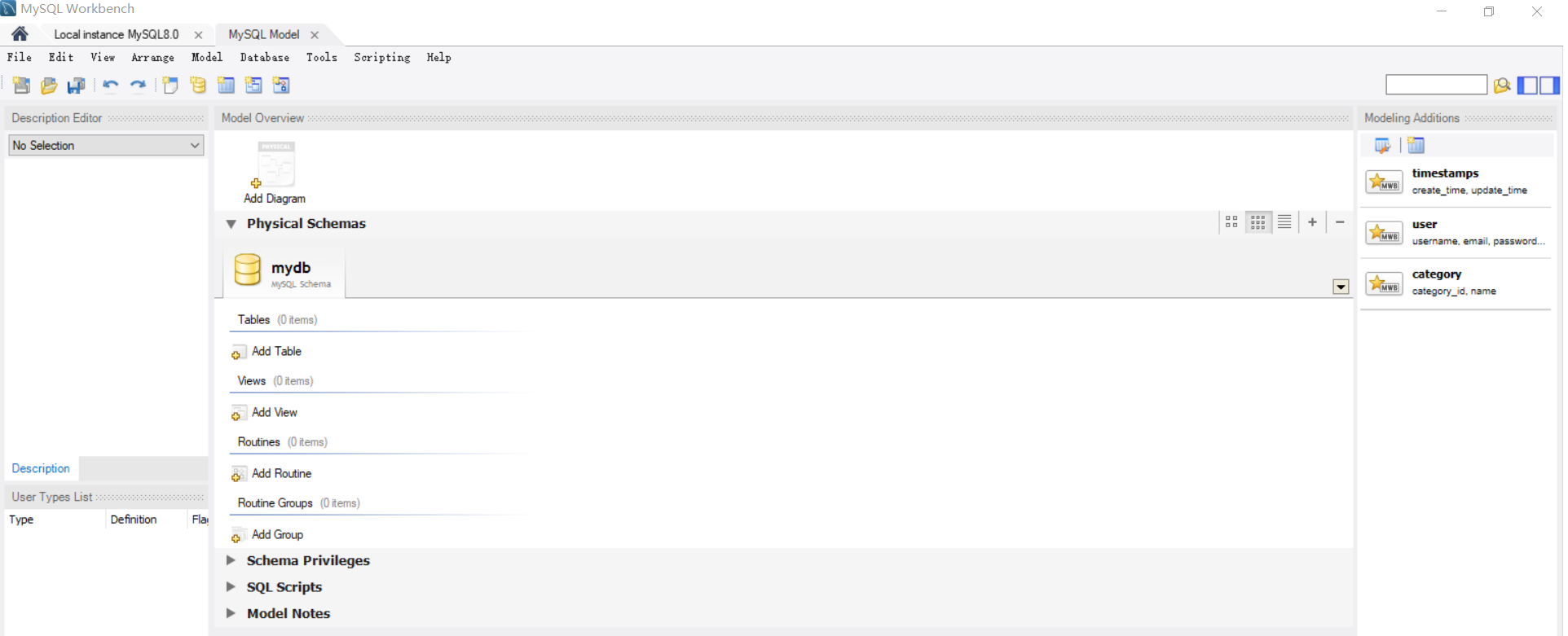
创建Model
Workbench会⾃动新建如下⻚⾯:
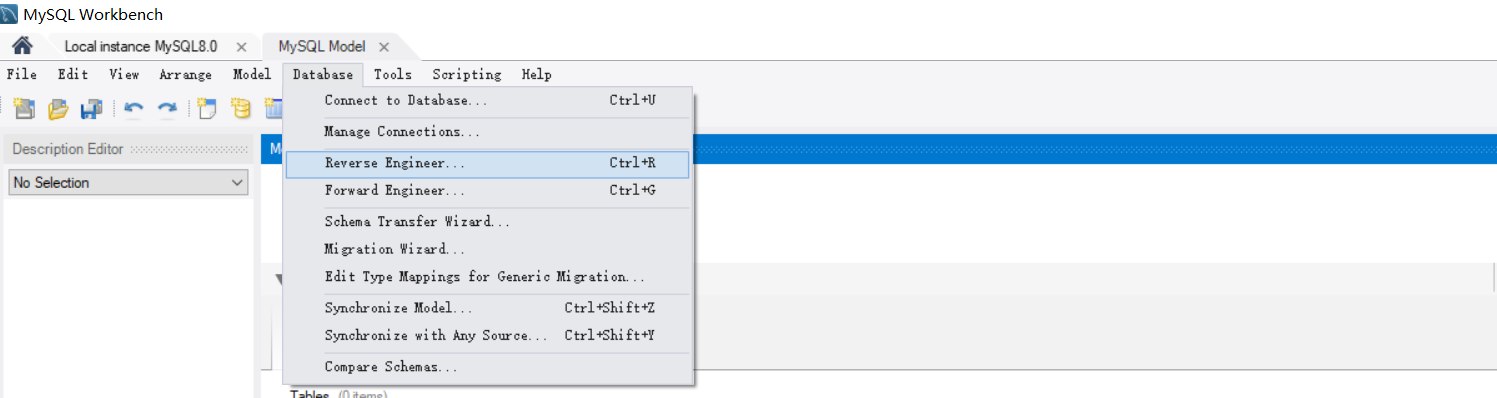
创建逆向⼯程
点击菜单栏中的Database-->ReverseEngineer...
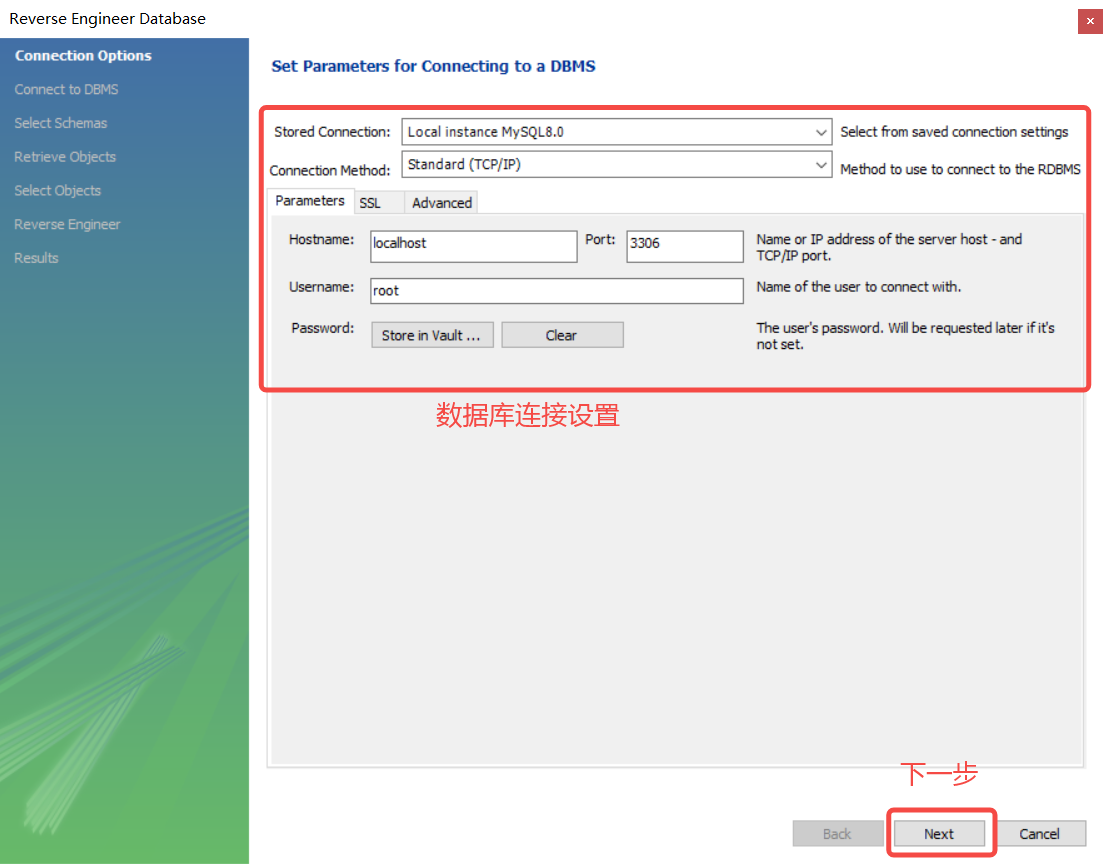
设置数据库连接选项
按实际数据库主机、端⼝号、⽤⼾名、密码设置连接属性
⾃动执⾏逆向建模前的⼀些检查任务,结果显⽰"成功"

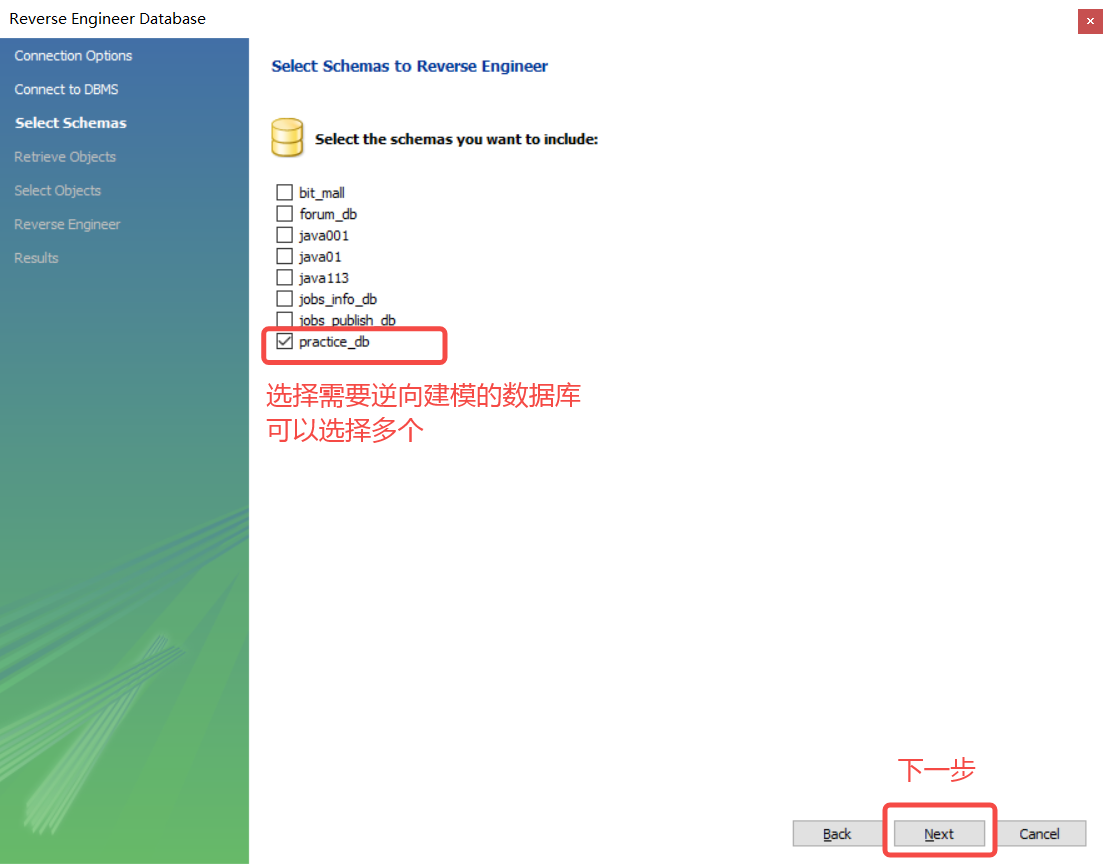
选择⽬标数据库
选择需要逆向建模的数据库,可以选择多个,根据实际需要选择即可
⾃动执⾏检查任务,结果显⽰"成功"
默认选择数据库中所有的表
执⾏逆向建模
显⽰操作结果
整理⻚⾯布局
- ⽣成E-R图之后⻚⾯布局⽐较乱,如下图所⽰
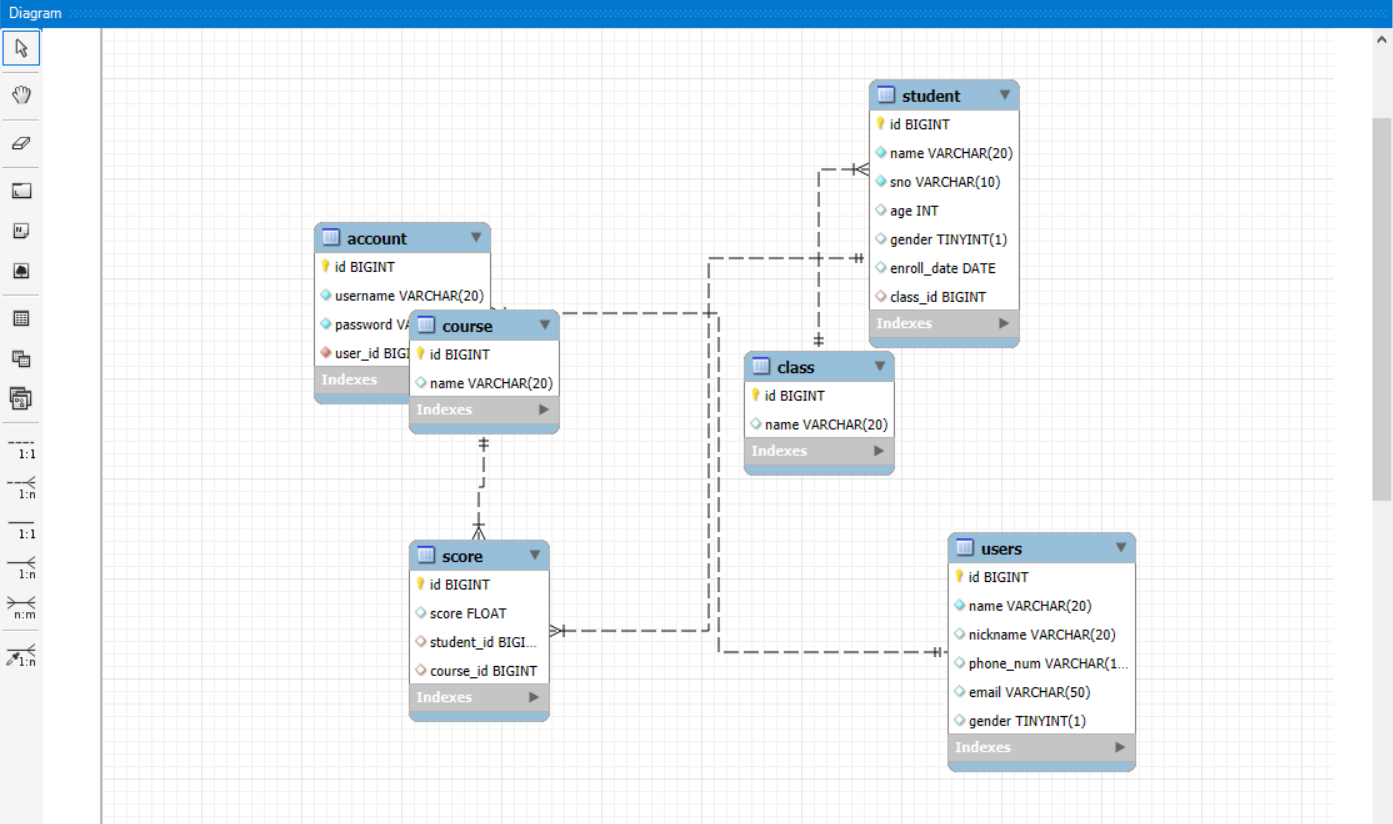
⼿动整理布局
修改关联关系
- 删除错误的关系
- 建⽴正确的关联关系
导出为图⽚
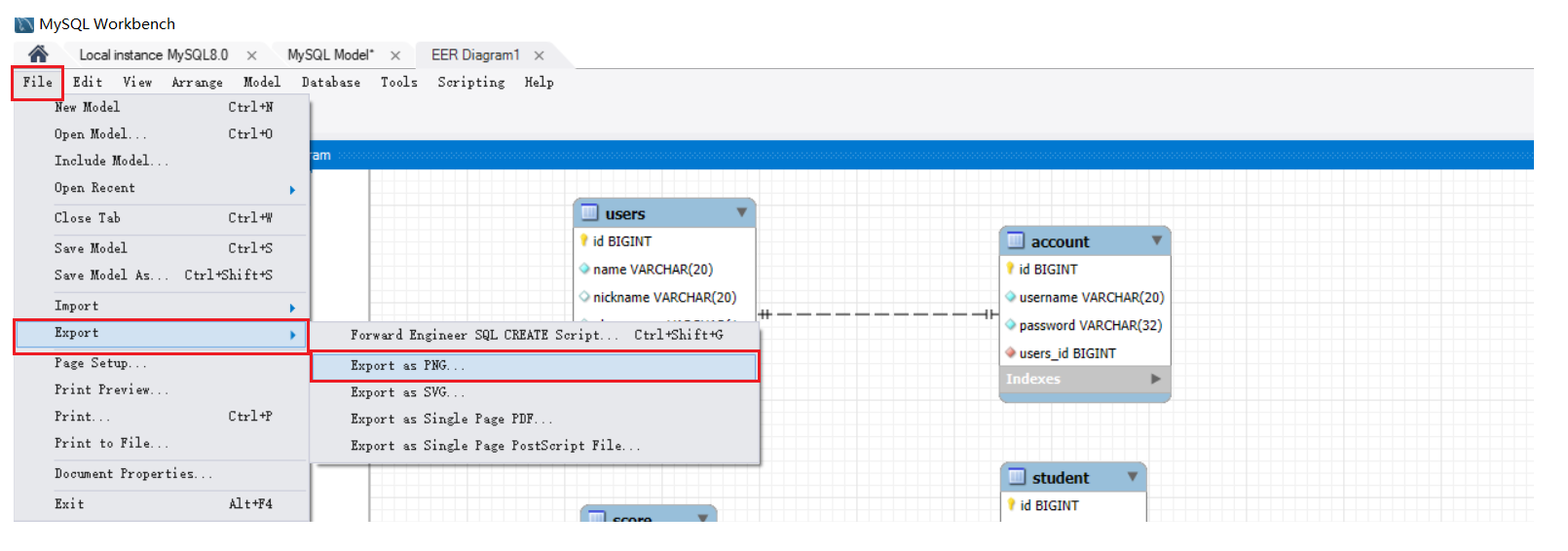
选择⽬录并为图⽚起名,导出完成。在⽬标⽬录下查看图⽚如下所⽰: