双人对话生成模型 MOSS 上线,支持零样本语音克隆
在语音生成这一领域,文本到语音(TTS)模型已经能够合成出高度清晰、音色动人的单人朗读语音,极大地推动了内容创作与人机交互的进步。然而,当我们试图将这项技术应用于一些更具动态和表现力的多人对话场景——如播客对话、影视配音或长篇叙事时,传统的单说话人 TTS 模型便显得有些力不从心了。
针对于此,上海创智学院、复旦大学和模思智能的 OpenMOSS 团队携手推出了 MOSS-TTSD 模型。MOSS-TTSD 是专为口语对话生成而设计的开创性模型。它不仅能实现零样本下的双人音色克隆与区分,更能精准地模拟出真实对话中特有的语气、停顿和情感流动,将生硬的文本脚本转化为富有生命力的自然交谈。
MOSS-TTSD 基于 Qwen3-1.7B-base 模型进行继续训练,采用离散化的语音序列建模方法,在约 100 万小时单说话人语音数据和 40 万小时对话语音数据上进行训练,因此它能够一次性生成长达数十分钟的连贯语音,更是为 AI 播客、有声书和虚拟角色配音打开了全新的大门。
教程链接:https://go.openbayes.com/K8xHG
使用云平台:OpenBayes
http://openbayes.com/console/signup?r=sony_0m6v
登录 http://OpenBayes.com,在「公共教程」页面,选择一键部署 「MOSS:文本到口语对话生成」教程。
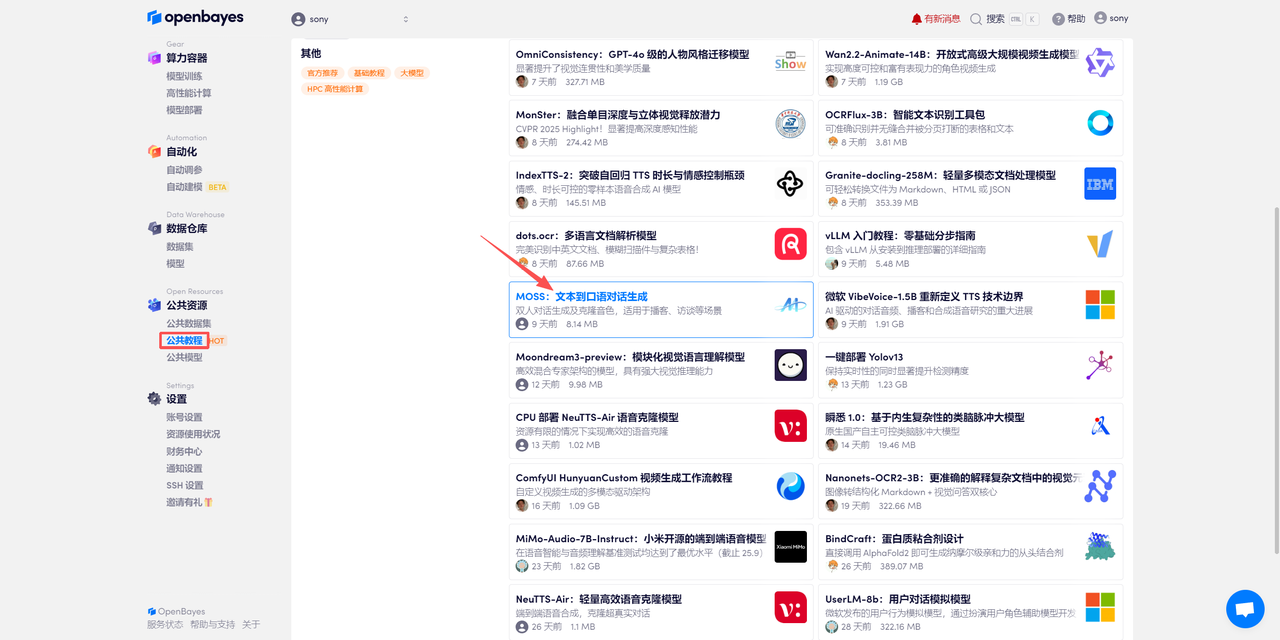
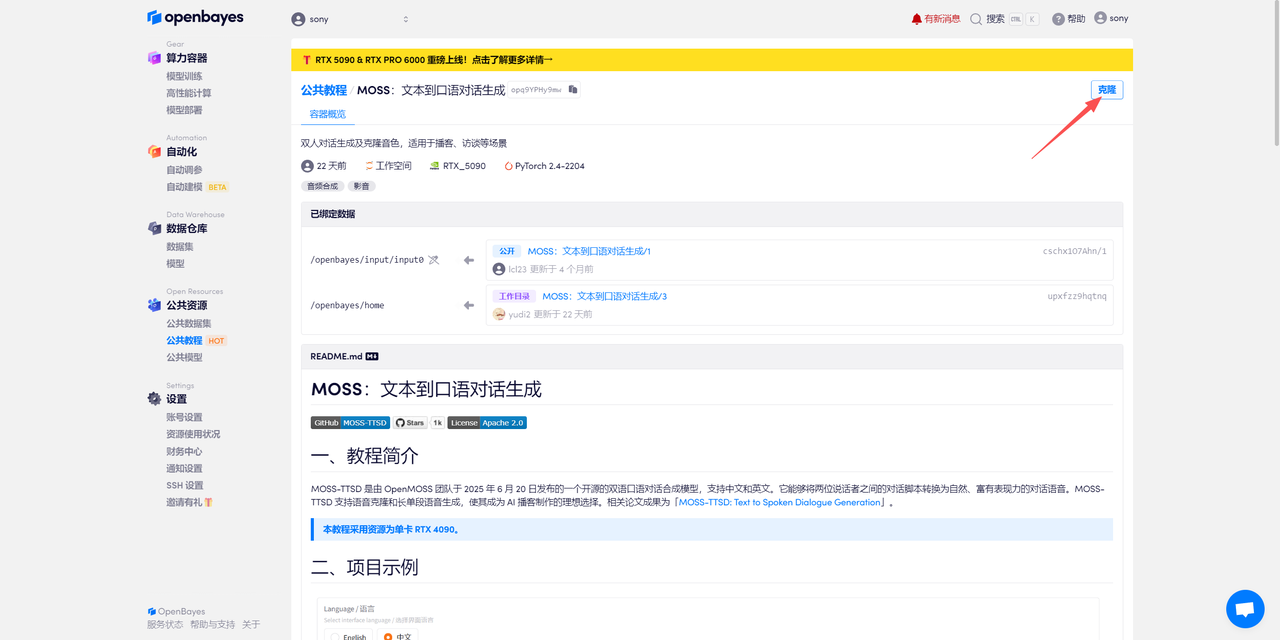
页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
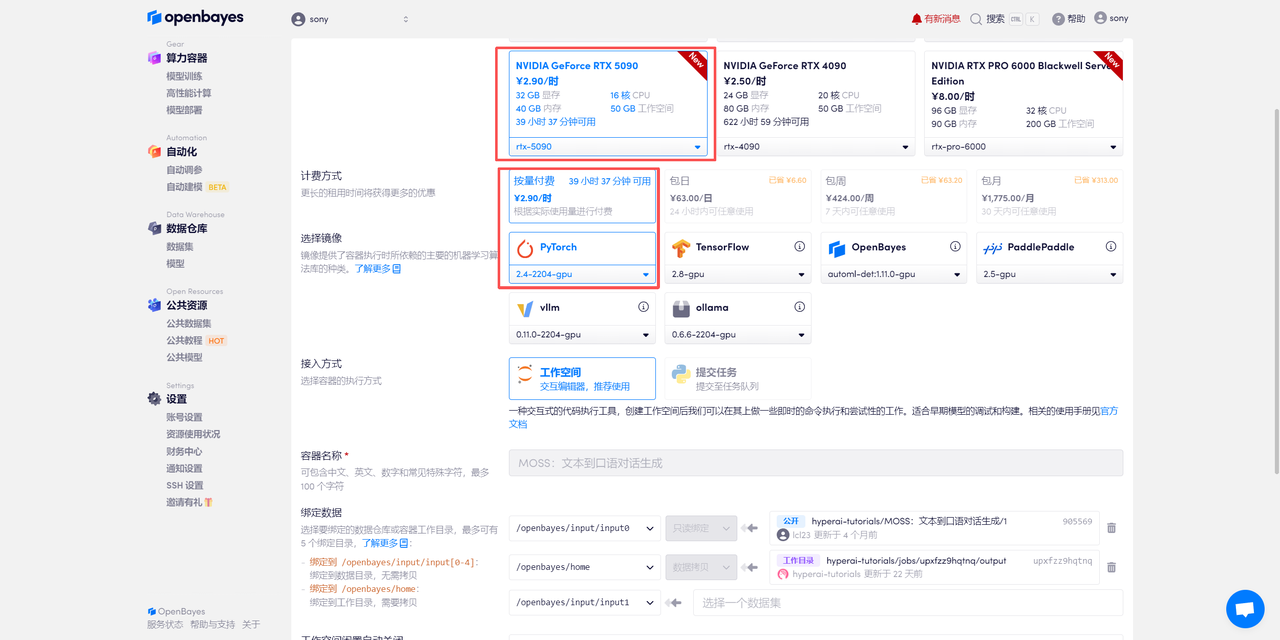
在当前页面中看到的算力资源均可以在平台一键选择使用。平台会默认选配好原教程所使用的算力资源、镜像版本,不需要再进行手动选择。点击「继续执行」,等待分配资源。
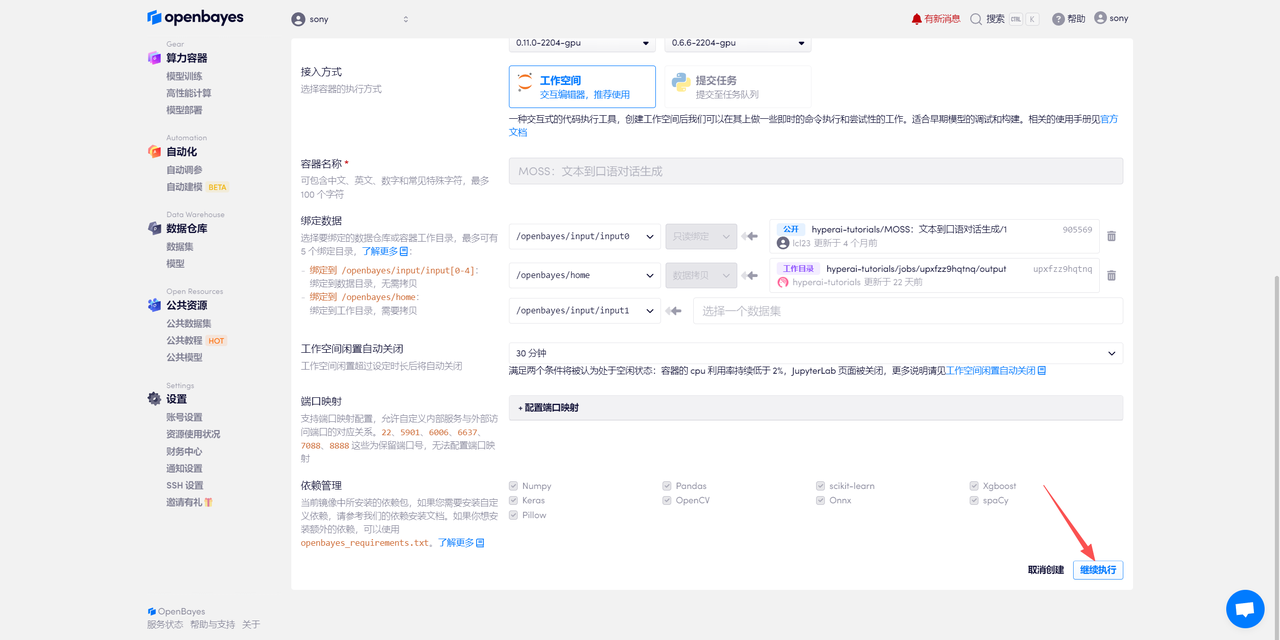
待系统分配好资源,当状态变为「运行中」后,点击「API 地址」边上的跳转箭头,即可跳转至 Demo 页面。
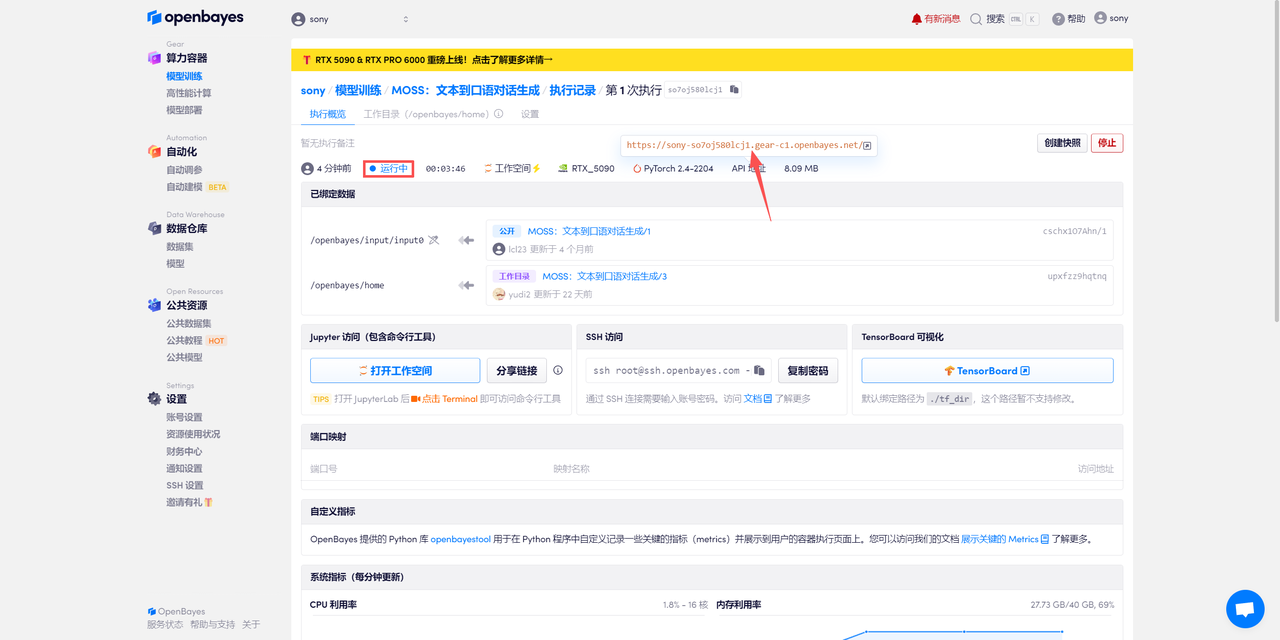
该教程可在「音频输入模式」处选择单人音频生成(Single)和双人对话音频生成(Role)。进入 Demo 界面后,首先选择界面语言,然后输入要合成的文本,输入模式选择「Single」则需上传包含一个角色的音频;选择「Role」则需上传两个角色的音频。
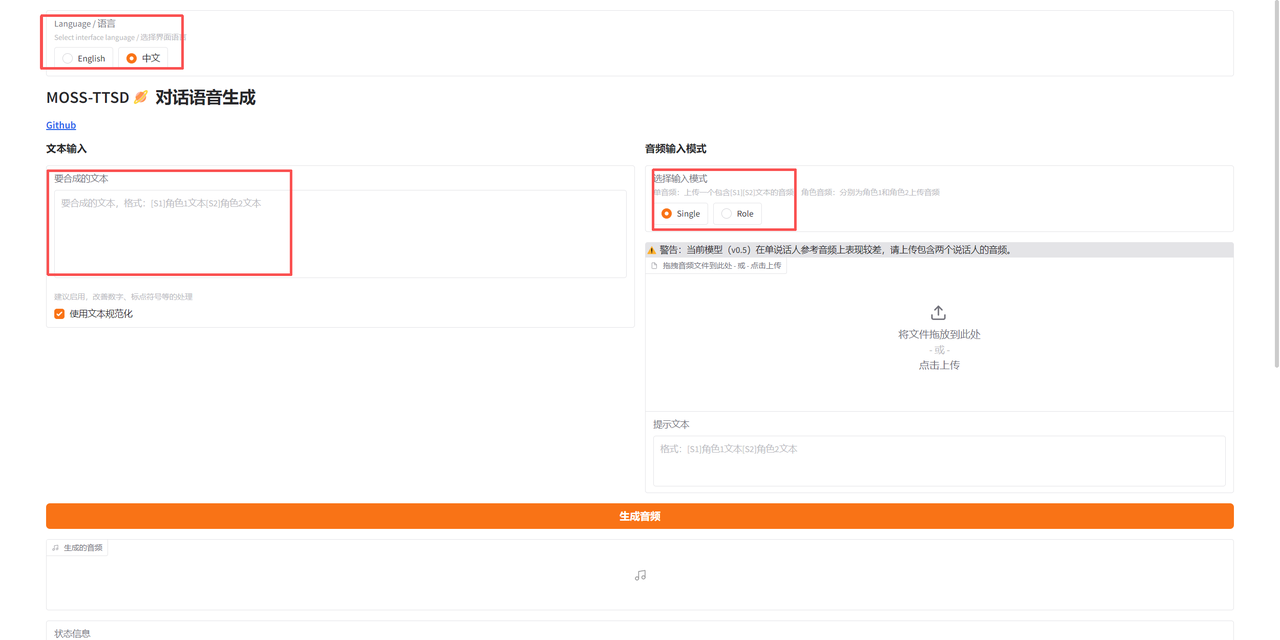
单人音频示例:
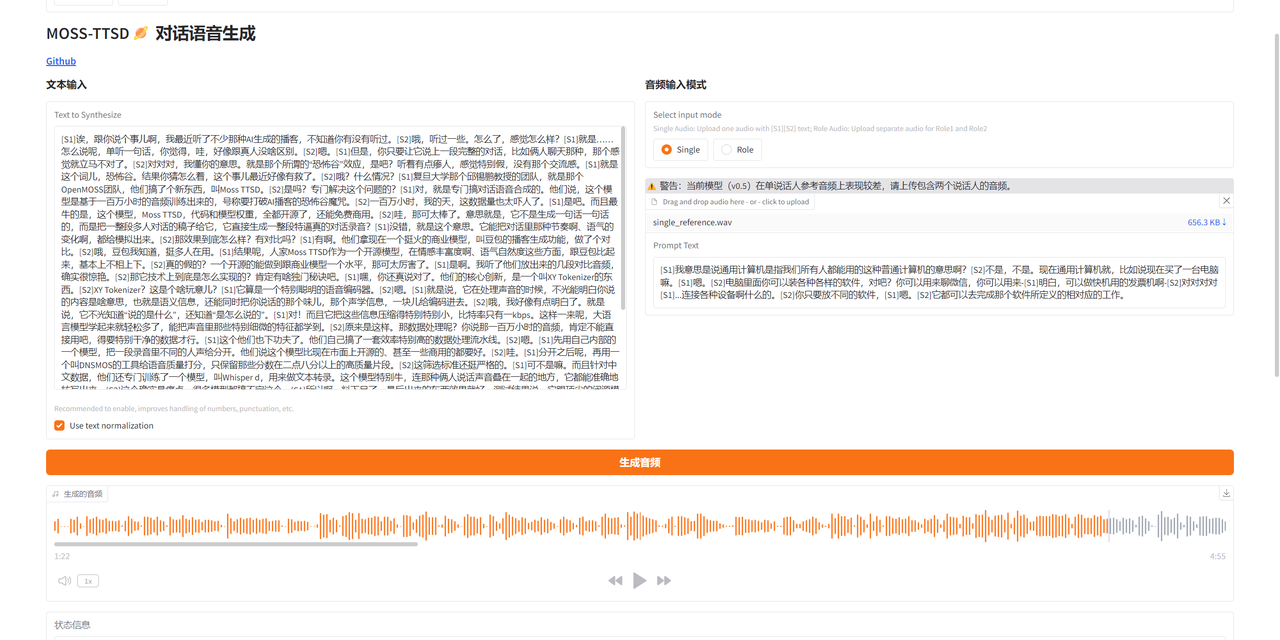
(由于平台限制,音频大家可以到「知乎-技术小白狮」同名文章内查看~)
双人对话音频示例:
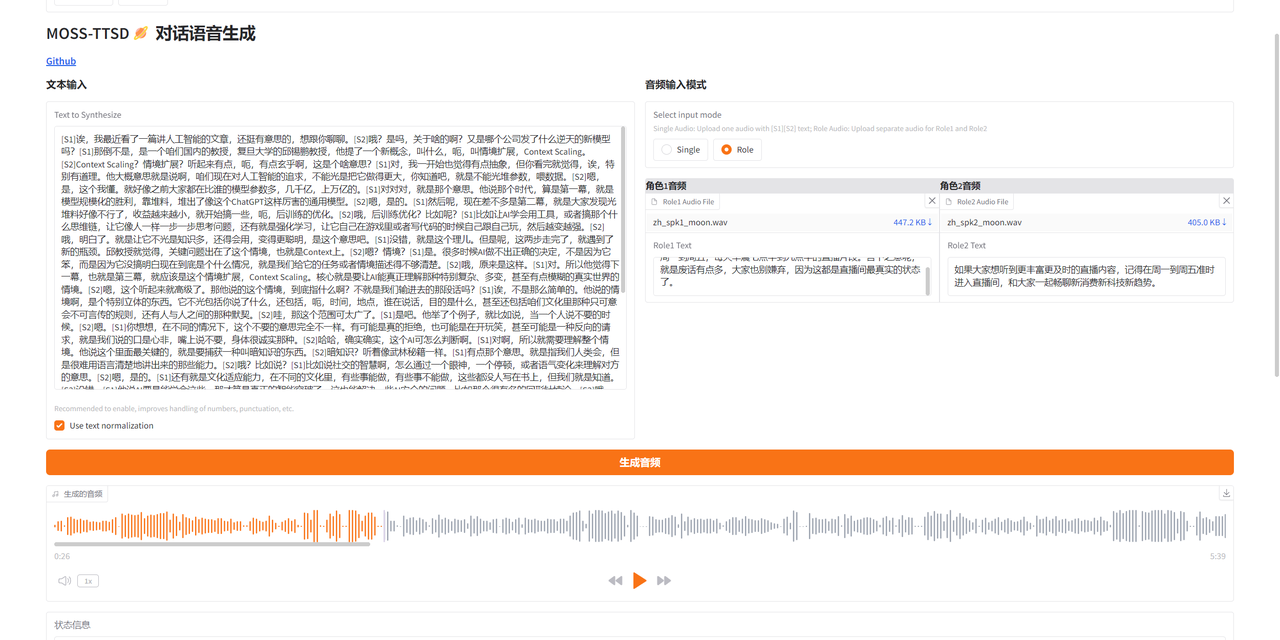
(由于平台限制,音频大家可以到「知乎-技术小白狮」同名文章内查看~)